生产环境中热 key 处理
热 key 问题就是某一瞬间可能某条内容特别火爆,大量的请求去访问这个数据,那么这样的 key 就是热 key,往往这样的 key 也是存储在了一个 redis 节点中,对该节点压力很大
那么对于热 key 的处理就是通过热 key 探测系统对热 key 进行计数,一旦发现了热 key,就将热 key 在 jvm 本地缓存中再存储一份,那么当再有大量请求来读取时,就直接在应用的 jvm 缓存中读取到直接返回了,不会再将压力给到同一个 redis 节点中了,如下图:
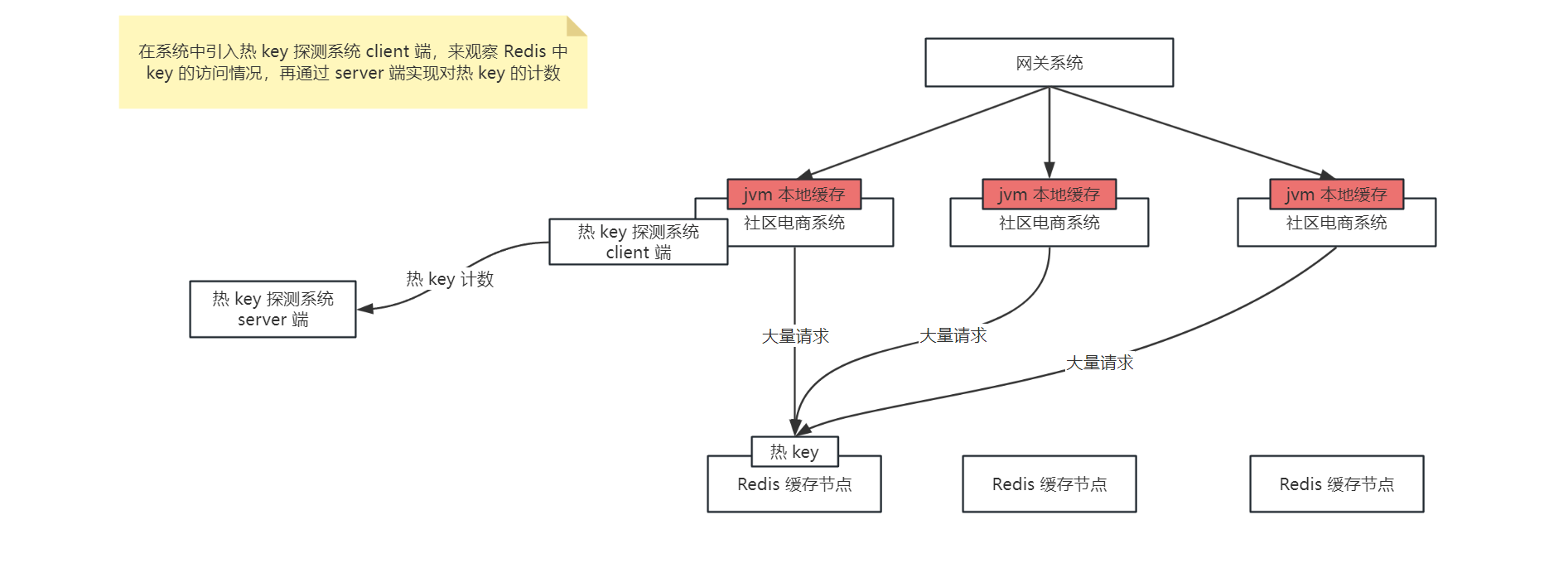
京东开源了高性能热 key 探测中间件:JD-hotkey,可以实时探测出系统的热数据,生产环境中可以基于 JD-hotkey 来解决热 key 的问题
生产环境中大 key 监控和切分处理方案
大 key 问题是指在 Redis 中某一个 key 所存储的 value 值特别大,几个 mb 或者几十 mb,那么如果频繁读取大 key,就会导致大量占用网络带宽,影响其他网络请求
对于大 key 会进行特殊的切片处理,并且要对大 key 进行监控,如果说发现超过 1mb 的大 key,则进行报警,并且自动处理,将这个大 key 拆成多个 k-v 进行存储,比如将 big-key 拆分为 —> big-key01,big-key02 ...,
那么大 key 的解决方案如下:
- 通过 crontab 定时调度 shell 脚本,每天凌晨通过 rdbtools 工具解析 Redis 的 rdb 文件,过滤 rdb 文件中的大 key 导出为 csv 文件,然后使用 SQL 导入 csv 文件存储到 MySQL 中的表
redis_large_key_log中 - 使用 canal 监听 MySQL 的
redis_large_key_log表的 binlog 日志,将增量数据发送到 RocketMQ 中(这里该表的增量数据就是解析出来的大 key,将大 key 的数据发送到 MQ 中,由 MQ 消费者来决定如何对这些大 key 进行处理) - 在 MQ 的消费端可以通过一个大 key 的处理服务来对大 key 进行切分,分为多个 k-v 存储在 Redis 中
那么在读取大 key 的时候,需要判断该 key 是否是大 key,如果是的话,需要对多个 k-v 的结果进行拼接并返回
数据库与缓存最终一致性解决方案
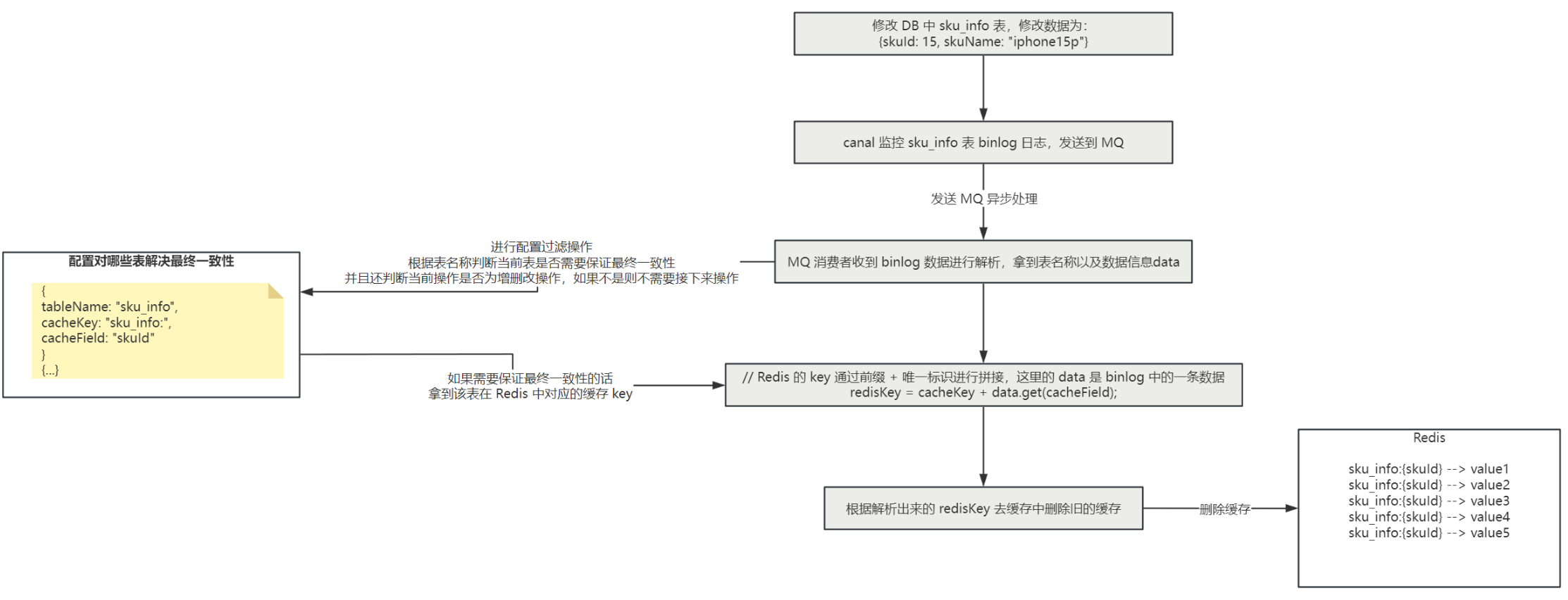
如果不采用更新数据时双写来保证数据库与缓存的一致性的话,可以通过 canal + RocketMQ 来实现数据库与缓存的最终一致性,对于数据直接更新 DB,通过 canal 监控 MySQL 的 binlog 日志,并且发送到 RocketMQ 中,MQ 的消费者对数据进行消费并解析 binlog,过滤掉非增删改的 binlog,那么解析 binlog 数据之后,就可以知道对 MySQL 中的哪张表进行 增删改 操作了,那么接下来我们只需要拿到这张表在 Redis 中存储的 key,再从 Redis 中删除旧的缓存即可,那么怎么取到这张表在 Redis 中存储的 key 呢?
可以我们自己来进行配置,比如说监控 sku_info 表的 binlog,那么在 MQ 的消费端解析 binlog 之后,就知道是对 sku_info 表进行了增删改的操作,那么假如 Redis 中存储了 sku 的详情信息,key 为 sku_info:{skuId},那么我们就可以在一个地方(可以在配置文件中,也可以在枚举类中进行配置)对这个信息进行配置:
// 配置下边这三个信息
tableName = "sku_info"; // 表示对哪个表进行最终一致性
cacheKey = "sku_info:"; // 表示缓存前缀
cacheField = "skuId"; // 缓存前缀后拼接的唯一标识
// data 是解析 binlog 日志后拿到的 key-value 值,data.get("skuId") 就是获取这一条数据的 skuId 属性值
// 如下就是最后拿到的 Redis 的 key
redisKey = cacheKey + data.get(cacheField)
那么整体的流程图如下: