文章目录
- TiDB简介
- 分布式系统
- CAP 理论
- 一致性
- 可用性
- 分区容错性
- 应用场景
- 关系型模型
- 事务
- ACID 特性
- 原子性
- 一致性
- 隔离性
- 持久性
- 与传统非分布式数据库架构对比
- TiDB 分布式数据库整体架构
TiDB简介
TiDB 是 PingCAP 公司自主设计、研发的开源分布式关系型数据库,是一款同时支持在线事务处理与在线分析处理 (Hybrid Transactional and Analytical Processing, HTAP) 的融合型分布式数据库产品,具备水平扩容或者缩容、金融级高可用、实时HTAP、云原生的分布式数据库、兼容 MySQL 5.7 协议和MySQL 生态等重要特性。目标是为用户提供一站式 OLTP(Online Transactional Processing)、OLAP (Online Analytical Processing)、HTAP 解决方案。TiDB 适合高可用、强一致要求较高、数据规模较大等各种应用场景。
分布式系统
分布式系统是一种其组件位于不同的联网计算机上的系统,然后通过互相传递消息来进行通讯和协调,为了达到共同的目标,这些组件会相互作用;换句话说,分布式系统把需要进行大量计算的工程数据分割成若干个小块,由多台计算机分别进行计算和存储,然后将结果统一合并到数据结论的科学;本质上就是进行数据存储与计算的分治;
CAP 理论
一致性
指所有的节点在同一时间的数据一致性;
all nodes see the same data at the same time;
可用性
服务在正常响应时间内的可用;
reads and writes always succeed;
分区容错性
分布式系统在遇到某节点或网络分区故障的时候仍然能够对外提供满足一致性或可用性的服务;
应用场景
- 对数据一致性及高可靠、系统高可用、可扩展性、容灾要求较高的金融行业属性的场景。
TiDB 采用多副本 + Multi-Raft 协议的方式将数据调度到不同的机房、机架、机器,当部分机器出现故障时系统可自动进行切换,确保系统的 RTO <= 30s 及 RPO = 0。
- 对存储容量、可扩展性、并发要求较高的海量数据及高并发的OLTP 场景。
iDB 采用计算、存储分离的架构,可对计算、存储分别进行扩容和缩容,计算最大支持 512 节点,每个节点最大支持1000 并发,集群容量最大支持 PB 级别。
- Real-time HTAP 场景
TiDB 在 4.0 版本中引入列存储引擎 TiFlash 结合行存储引擎TiKV 构建真正的 HTAP 数据库,在增加少量存储成本的情况下,可以在同一个系统中做联机交易处理、实时数据分析,极大地节省企业的成本。
- 数据汇聚、二次加工处理的场景
业务通过 ETL 工具或者 TiDB 的同步工具将数据同步到
TiDB,在 TiDB 中可通过 SQL 直接生成报表。(ETL 是将业务系统的数据经过抽取、清洗转换之后加载到数据仓库的过程,目的是将企业中的分散、零乱、标准不统一的数据整合到一起,为企业的决策提供分析依据)
关系型模型
在传统的在线交易场景里,关系型模型仍然是标准;关系型数据库的关键在于一定要具备事务;
事务
事务的本质是:并发控制的单元,是用户定义的一个操作序
列;这些操作要么都做,要么都不做,是一个不可分割的工作单位;为了保证系统始终处于一个完整且正确的状态;
ACID 特性
原子性
事务包含的全部操作时一个不可分割的整体;要么全部执行,要么全部不执行;
一致性
事务的前后,所有的数据都保持一个一致的状态;不能违反数据的一致性检测;
隔离性
各个并发事务之间互相影响的程度;主要规定多个并发事务访问同一个数据资源,各个并发事务对该数据资源访问的行为;不同的隔离性是应对不同的现象(脏读、可重读、幻读等);
持久性
事务一旦完成要将数据所做的变更记录下来;包括数据存储和多副本的网络备份;
与传统非分布式数据库架构对比
- 两者都支持 ACID、事务强一致性;
- 分布式架构,组件解耦,拥有良好的扩展性,支持弹性的扩缩容;
- 默认支持高可用,在少数副本失效的情况下,数据库能够自动进行故障转移,对业务透明;
- 采用水平扩展,在大数据量、高吞吐的业务场景中具有先天优势;
- 强项不在于轻量的简单 SQL 的响应速度,而在于大量高并发SQL 的吞吐;
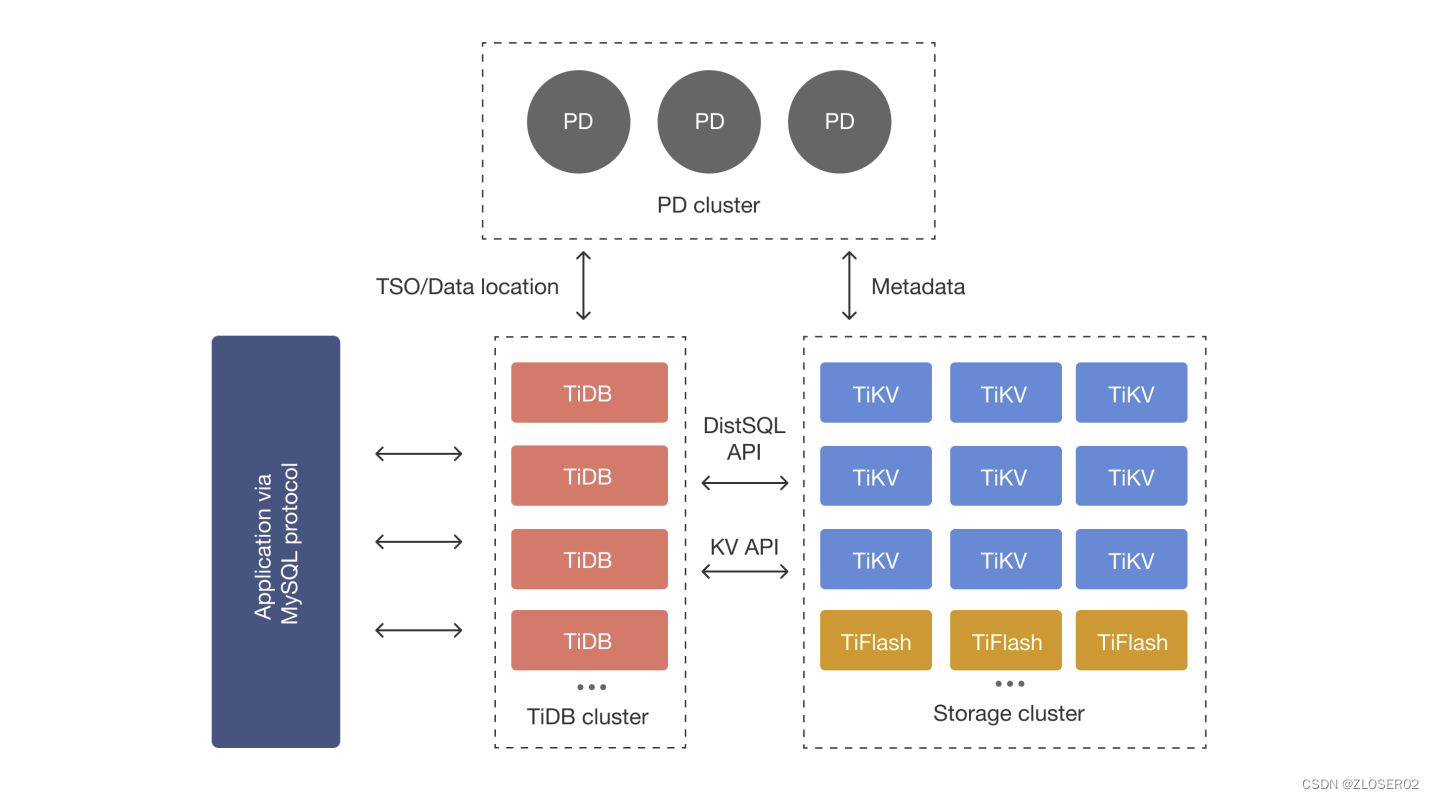
TiDB 分布式数据库整体架构
- 由多模块组成,各模块互相通信,组成完整的 TiDB 系统;
- 前端 stateless、后端 stateful (Raft);
- 兼容 MySQL;