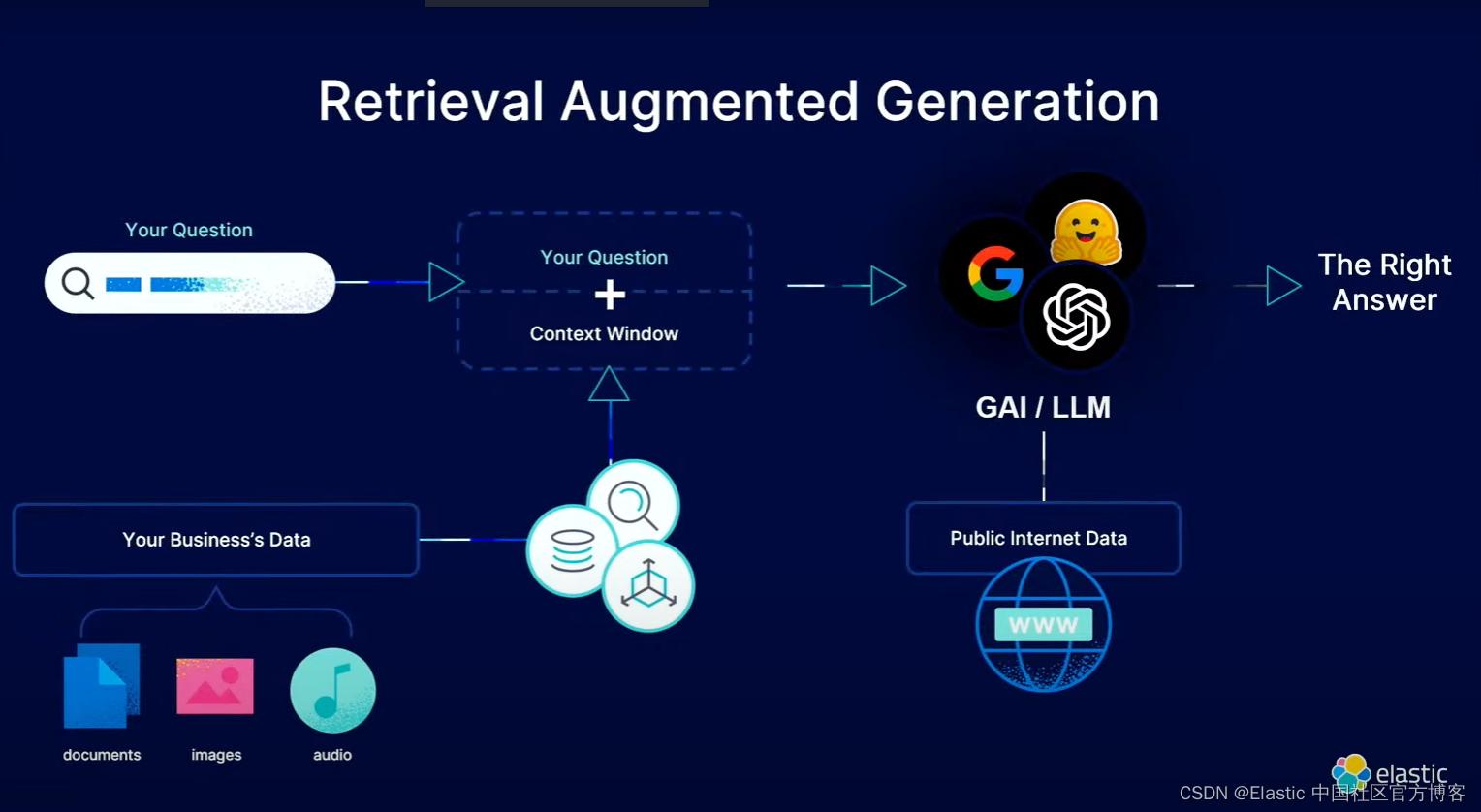
Elasticsearch 的向量搜索为我们的语义搜索提供了可能。而在人工智能的动态格局中,检索增强生成(Retrieval Augmented Generation - RAG)已经成为游戏规则的改变者,彻底改变了我们生成文本和与文本交互的方式。 RAG 使用大型语言模型 (LLMs) 等工具将信息检索的能力与自然语言生成无缝结合起来,为内容创建提供了一种变革性的方法。在本文中,我们将使用 Elasticsearch 的向量搜索并结合 OpenAI 大模型来实现 RAG。有关更多关于 RAG 的描述,请参阅文章 “Elasticsearch:什么是检索增强生成 - RAG?”。
安装 Elasticsearch 及 Kibana
如果你还没有安装好自己的 Elasticsearch 及 Kibana,那么请参考一下的文章来进行安装:
-
如何在 Linux,MacOS 及 Windows 上进行安装 Elasticsearch
-
Kibana:如何在 Linux,MacOS 及 Windows 上安装 Elastic 栈中的 Kibana
在安装的时候,请选择 Elastic Stack 8.11 进行安装。这个也是在 Github 中代码的要求。你可以在如下的地址下载源码:
git clone https://github.com/liu-xiao-guo/elasticsearch-labs运行应用
在进行之前,我们选择 OpenAI 来进行展示。本演示的代码是下面的这个项目:
$ pwd
/Users/liuxg/python/elasticsearch-labs/example-apps
$ ls
README.md openai-embeddings workplace-search
chatbot-rag-app relevance-workbench
internal-knowledge-search search-tutorial如上所示,chatbot-rag-app 目录含有我们所需要运行的代码。在运行代码之前,我们需要在 terminal 中打入如下的命令:
export ELASTICSEARCH_URL=https://elastic:o6G_pvRL=8P*7on+o6XH@192.168.0.3:9200
export ES_INDEX=workplace-app-docs
export ES_INDEX_CHAT_HISTORY=workplace-app-docs-chat-history
export LLM_TYPE=openai
export OPENAI_API_KEY=YourOpenAiKey在我的设置中,我使用自签名证书的 Elasticsearch 集群。在上面,你需要根据自己的 Elasticsearch 超级用户及密码进行配置。你也需要在 OpenAI 的网站中申请开发者 key。你可以在地址 https://platform.openai.com/api-keys 进行申请。
构建 docker 镜像
我们使用如下的命令来构建镜像:
docker run --rm --env-file .env chatbot-rag-app flask create-index
摄入数据
我们把 Elasticsearch 的证书拷贝到 chatbot-rag-app 的根目录下:
$ pwd
/Users/liuxg/python/elasticsearch-labs/example-apps/chatbot-rag-app
$ cp ~/elastic/elasticsearch-8.11.0/config/certs/http_ca.crt .我们在当前的目录下创建 .env 文件,它的内容如下:
.env
ELASTICSEARCH_URL=https://elastic:o6G_pvRL=8P*7on+o6XH@192.168.0.3:9200
ES_INDEX=workplace-app-docs
ES_INDEX_CHAT_HISTORY=workplace-app-docs-chat-history
LLM_TYPE=openai
OPENAI_API_KEY=YourOpenAiKey$ pwd
/Users/liuxg/python/elasticsearch-labs/example-apps/chatbot-rag-app
$ ls -al
total 960
drwxr-xr-x 17 liuxg staff 544 Dec 11 21:43 .
drwxr-xr-x 10 liuxg staff 320 Dec 11 21:42 ..
-rw-r--r--@ 1 liuxg staff 8196 Dec 11 21:44 .DS_Store
-rw-r--r-- 1 liuxg staff 237 Dec 11 21:10 .env
-rw-r--r-- 1 liuxg staff 55 Dec 8 17:09 .flaskenv
-rw-r--r-- 1 liuxg staff 82 Dec 8 17:09 .gitignore
-rw-r--r-- 1 liuxg staff 807 Dec 8 17:09 Dockerfile
-rw-r--r-- 1 liuxg staff 6085 Dec 8 17:09 README.md
drwxr-xr-x 7 liuxg staff 224 Dec 8 17:09 api
-rw-r--r-- 1 liuxg staff 430277 Dec 8 17:09 app-demo.gif
drwxr-xr-x 4 liuxg staff 128 Dec 8 17:09 data
-rw-r--r-- 1 liuxg staff 860 Dec 8 17:09 env.example
drwxr-xr-x 2 liuxg staff 64 Dec 11 21:38 filebeat.yml
drwxr-xr-x 9 liuxg staff 288 Dec 8 17:09 frontend
-rw-r----- 1 liuxg staff 1915 Dec 11 21:47 http_ca.crt
-rw-r--r-- 1 liuxg staff 315 Dec 8 17:09 requirements.in
-rw-r--r-- 1 liuxg staff 5259 Dec 8 17:09 requirements.txt我们使用如下的命令来摄入数据:
docker run \
--volume="$PWD/http_ca.crt:/usr/share/certs/http_ca.crt:ro" \
--rm --env-file .env chatbot-rag-app flask create-index$ pwd
/Users/liuxg/python/elasticsearch-labs/example-apps/chatbot-rag-app
$ docker run \
> --volume="$PWD/http_ca.crt:/usr/share/certs/http_ca.crt:ro" \
> --rm --env-file .env chatbot-rag-app flask create-index
".elser_model_2" model is available
Loading data from $/app/api/../data/data.json
Loaded 15 documents
Split 15 documents into 26 chunks
Creating Elasticsearch sparse vector store in Elastic Cloud: None从上面的显示中,我们可以看出来,我们已经写入了15个文档。这些文档的内容,你可以在 data 目录下的 data.json 中看到。我们在 Kibana 中可以使用如下的命令来进行查看:
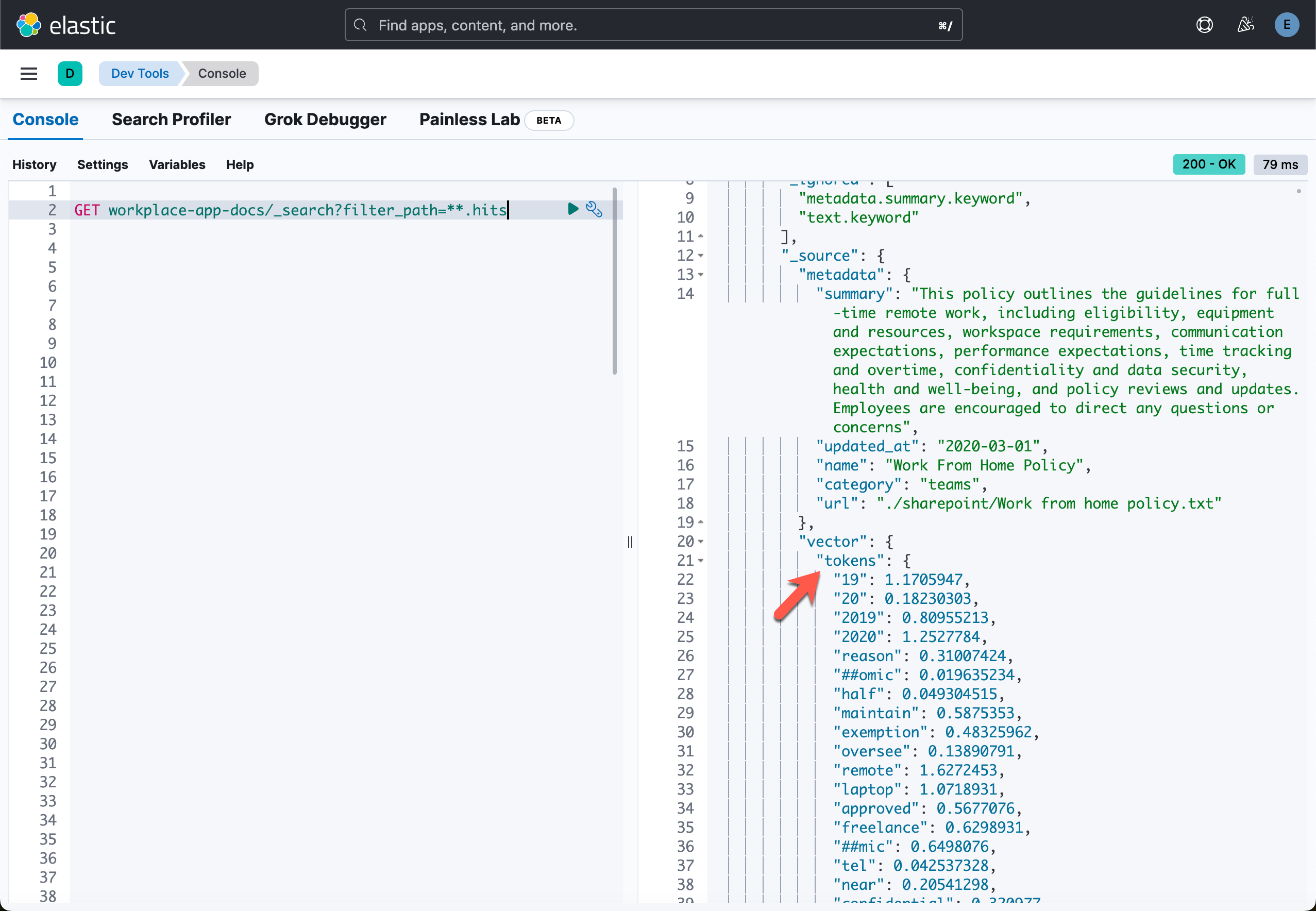
从上面的输出中,我们可以看到它使用了 ELSER 来实现向量搜索。这个在代码中我们可以查看到。

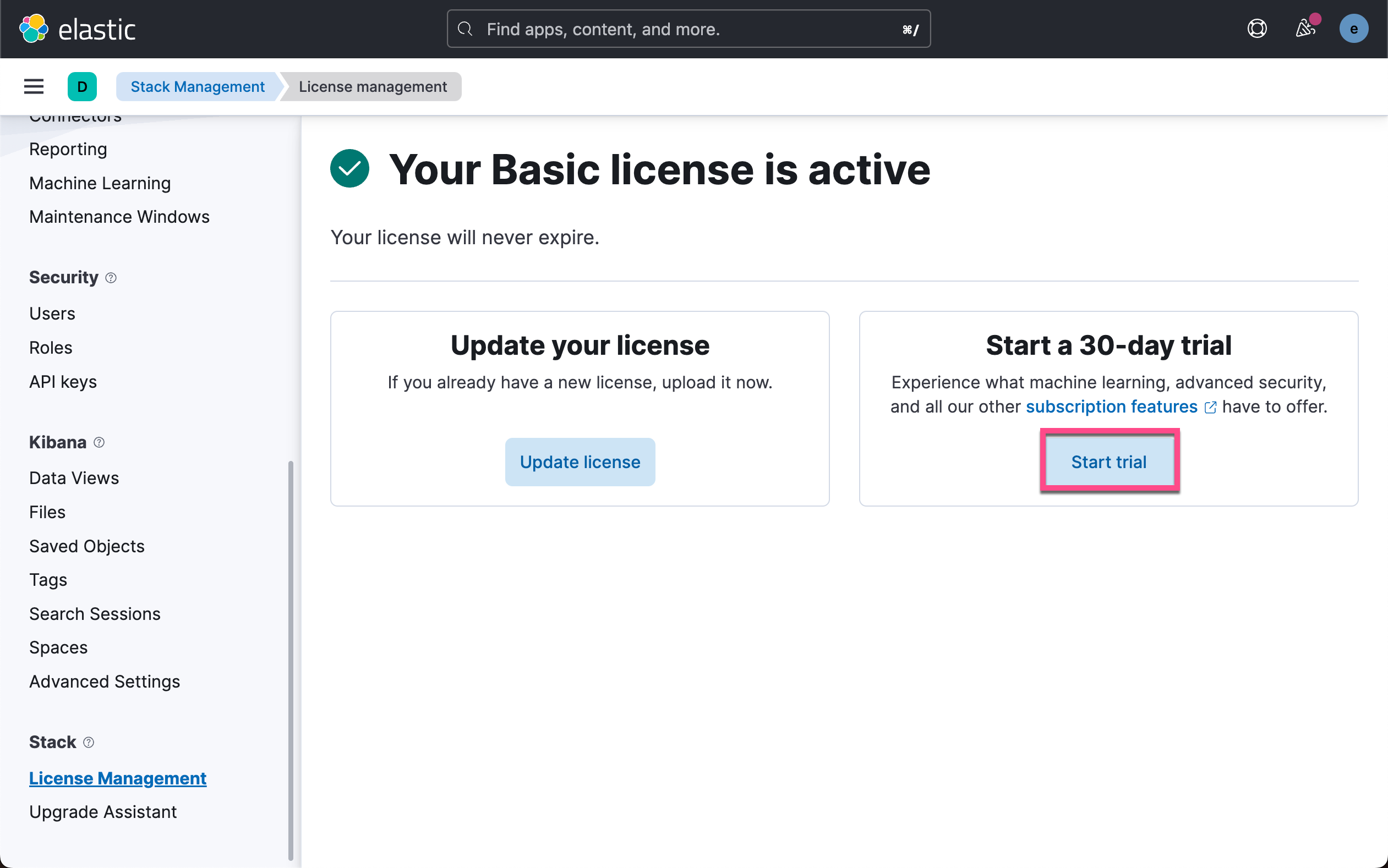
在代码中,它是通过程序来进行安装的,所以我们不必要使用手动来安装 ELSER 模型。如果你之前没有安装过,那么第一次运行时速度会比较慢,因为有个安装的过程。另外,安装 ELSER 需要你具有白金版的授权,你需要启动试用:
更多关于 ELSER 的部署,请参阅文章 “Elasticsearch:部署 ELSER - Elastic Learned Sparse EncoderR”。
启动 API 前端
我们可以使用如下的命令来启动前端应用。请注意在启动之前,我们设置好 .env。有关 .env 的写法,请参考 env.example 文件。我们使用如下的命令来进行启动:
docker run \
--volume="$PWD/http_ca.crt:/usr/share/certs/http_ca.crt:ro" \
--rm -p 4000:4000 --env-file .env -d chatbot-rag-app$ pwd
/Users/liuxg/python/elasticsearch-labs/example-apps/chatbot-rag-app
$ docker run \
> --volume="$PWD/http_ca.crt:/usr/share/certs/http_ca.crt:ro" \
> --rm -p 4000:4000 --env-file .env -d chatbot-rag-app
5955d1ec4b931f4a562330b682367b2c9a511bad20dd4a4033c7c3cac2c505f7如上所示,我们在端口 4000 启动一个 web 应用:
太好了,我们成功地启动了这个 chatbot 应用。
查询展示
在下面,我们来针对我们的数据进行一些查询:
What is our work from home policy?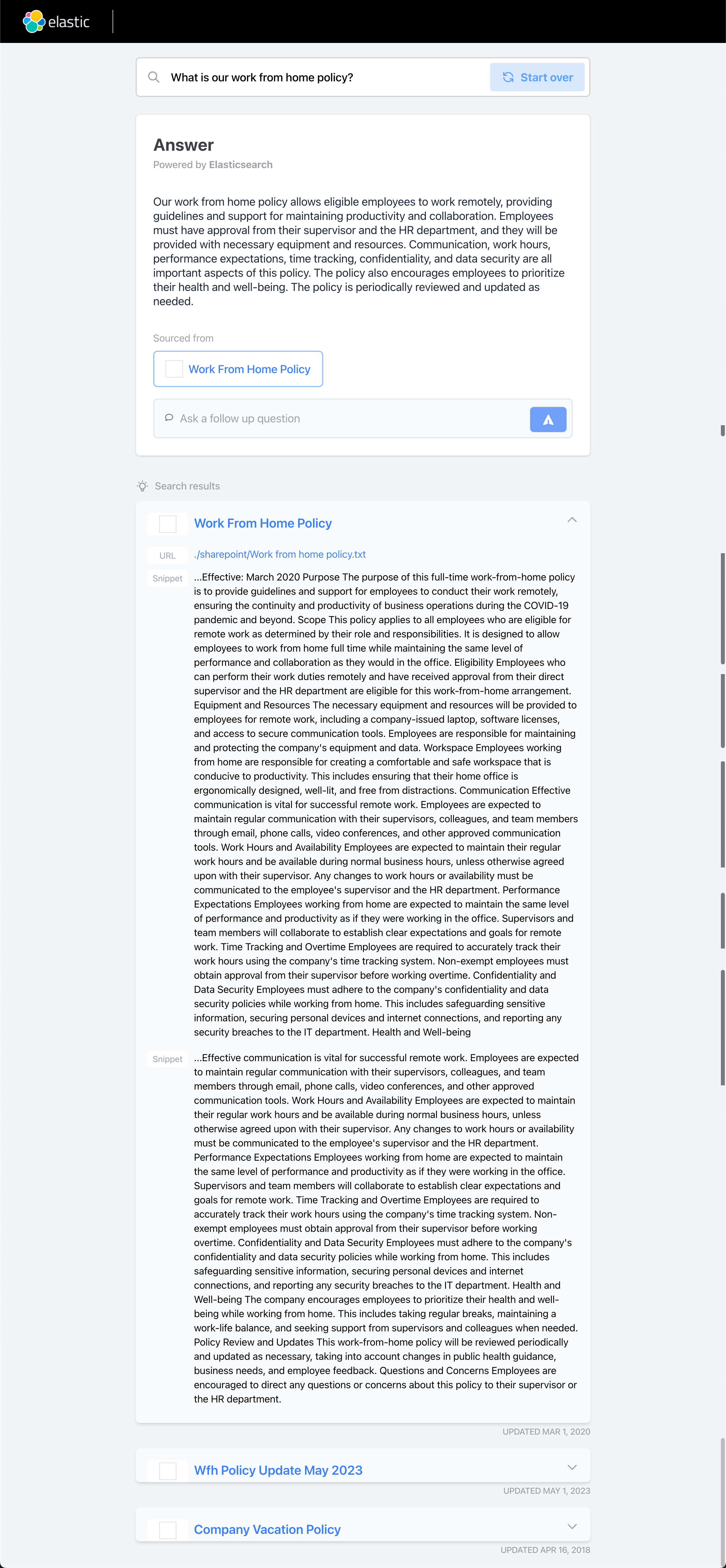
从上面的结果中,我们可以看出来:我们首先使用想要查询的问题让 Elasticsearch 在自己的向量数据库中(稀疏向量)进行搜索,并查到如上所示的几个最相近的文档。很显然查询到的结果非常冗长,而且不易被我们所理解。当然这些结果是从我们的私有数据里查询到的,也是和我们的公司的制度最相关的结果。为了得到更为简洁而精确的回答,我们可以把得到的结果变成为提示,再把原来的问题提交给 OpenAI 大模型,并进行总结。最终我们得到了如上所示的结果。
我们再做一个练习:
What's the NASA sales team?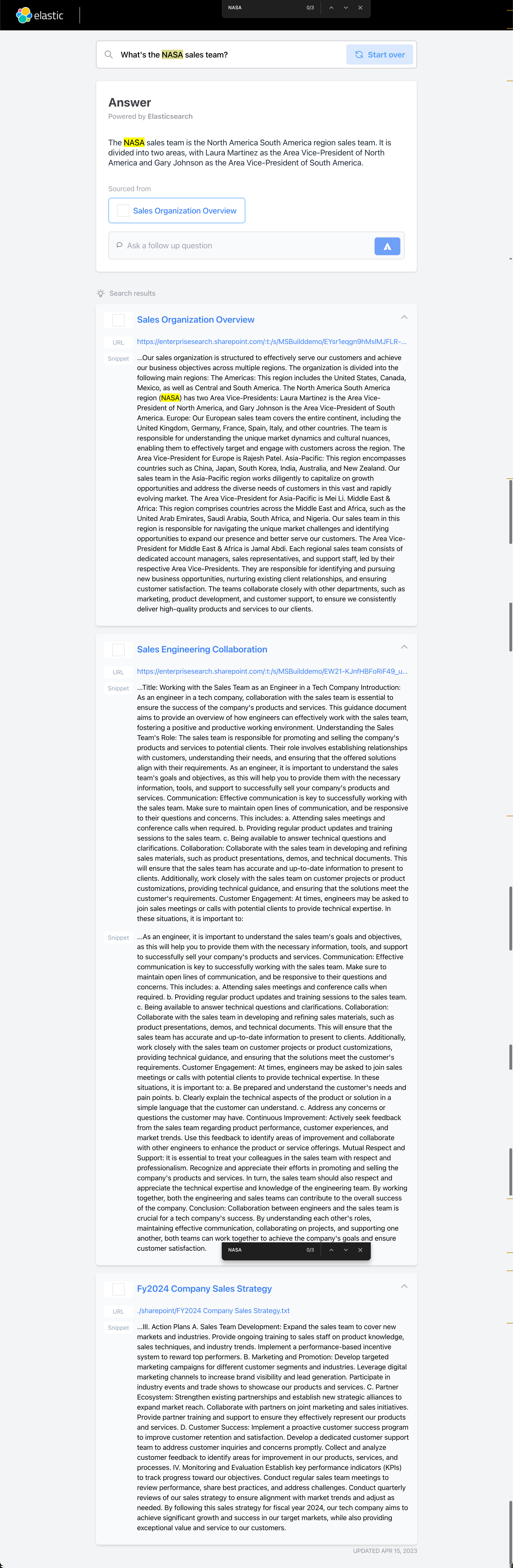
同样地,我们得到三个相关的文档。我们知道 NASA 的真正意思是:

如上所示,在互联网上的 NASA 定义式美国航空航天局。如果我们想搜索和我们自己公司相关的关于 NASA 的内容,那么它就是如上所示的答案:
The NASA sales team is the North America South America region sales team. It is divided into two areas, with Laura Martinez as the Area Vice-President of North America and Gary Johnson as the Area Vice-President of South America.它是指的一个北美南美的销售团队代名词。很显然它和互联网上的数据是不一样的。如果我们只是简单地从 Elasticsearch 来展示结果,那么我们的几个文档堆积在一起,需要更多地阅读。很显然,我们使用 OpenAI 的总结,我们得到一个更为简单明了的结果。
在我们的实例中,有更多的例子。请大家自己尝试。