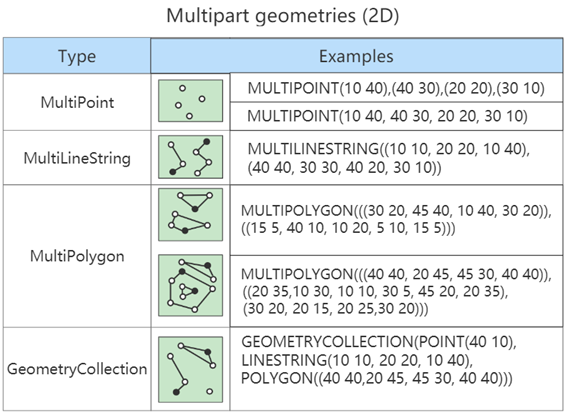
大家好,网络爬虫是一项非常抢手的技能,收集、分析和清洗数据是数据科学项目中最重要的部分。今天介绍如何从链接中爬取高质量文本内容,我们使用迭代,从大约700个链接中进行网络爬取。如果想直接跳转到代码部分,可以在下方链接GitHub仓库中找到,同时还会找到一个包含将爬取的700个链接的.csv数据集。
【GitHub】:https://github.com/StefanSilver3/MediumArticlesCode-byStefanSilver/tree/main/WebScraping
1.从单个链接进行网页抓取
首先导入所需的库:
from bs4 import BeautifulSoup
import requests
from bs4.element import Comment
import urllib.request
如果还没有安装BeautifulSoup库,可以直接在Python中安装:
pip install beautifulsoup4
然后开始编码,这里定义两个函数,一个用于检查要排除的内容,另一个用于从网站上爬取内容。
第一个函数用于查找要排除的元素,代码如下:
# 要从提取的文本中过滤的标签
def tag_visible(element):
if element.parent.name in ['style', 'script', 'head', 'title', 'meta', '[document]']:
return False
if isinstance(element, Comment):
return False
return True
第二个函数将使用这个函数,以确保所有的无用内容都从最终结果中排除,代码如下:
# 从网页文本中过滤前一个函数中提到的所有标签的函数
def text_from_html(body):
soup = BeautifulSoup(body, 'html.parser')
texts = soup.findAll(string=True)
visible_texts = filter(tag_visible, texts)
return u" ".join(t.strip() for t in visible_texts)
进而可以在一个新链接上测试这两个函数,可以放置任意链接,不需要使用下面的链接。
html = urllib.request.urlopen('https://www.artificialintelligence-news.com/2023/11/20/microsoft-recruits-former-openai-ceo-sam-altman-co-founder-greg-brockman/').read()
print(text_from_html(html))
网络爬取的内容将会像下面的文本一样:

爬取的网站——随机链接
注意,一些网站会检测到网络爬取活动,并阻止网络爬取尝试。如果发生这种情况,将收到一个403错误,这是“禁止”的代码。
2.同时爬取多个链接
测试了简单的提取函数,接下来对提供的链接数据集的所有链接进行迭代提取。首先确保获取了在GitHub仓库中找到的数据集,然后读取数据集并将列名更改为Link,原本的列名是max(page)。
df = pd.read_csv("furniture_stores_pages.csv")
df.rename(columns={"max(page)":"Link"}, inplace=1)
创建一个以0为起始值的变量x,它将在列表中的每个链接上进行迭代,也可以使用元素变量。
x=0
df_contents=[]
for element in df.iterrows():
try:
url = df["Link"][x]
scraped_text = urllib.request.urlopen(url).read()
df_contents.append(text_from_html(scraped_text))
x=x+1
except:
print("(",x,")","This website could not be scraped-> ",df["Link"][x])
x=x+1
定义一个名为df_contents的列表,它将包含从每个网页中提取的所有可以爬取的文本。
接下来,遍历每个元素,如果可以访问且包含相关数据,就从中提取信息。这只是对随机链接进行上述测试,但测试的对象是提供的数据集中的所有链接。代码中还使用了try-except对无法提取的链接进行跳过。
检查新列表(df_contents)的长度,查看提取了多少链接。
len(df_contents)
这个函数返回268,这意味着在700多个网站中只有268个爬取成功,可以使用下面的代码访问并打印第一个被爬取的网站。
df_contents[0]
这将打印第一个文本,示例如下所示(简短版本):

从数据集中爬取的网站
如果需要的话,也可以使用下面的代码反复打印。每打印完一个元素后,都需要输入任意字符以继续,这样就可以逐一检查每个提取的网站。
count = 0
for element in df_contents:
print(df_contents[count])
print("\n \n---------------------------------------------------------------------------------------- \n \n")
print("Press any key to continue to print df_contents [",count+1,"]")
input()
count= count+1