import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns
1.数据导入
In [2]:
train_data = pd.read_csv(r'../老师文件/train.csv') test_data = pd.read_csv(r'../老师文件/test.csv') labels = pd.read_csv(r'../老师文件/label.csv')['Survived'].tolist()
In [3]:
train_data.head()
Out[3]:
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S |
2.数据预处理
In [4]:
train_data.info()
<class 'pandas.core.frame.DataFrame'> RangeIndex: 891 entries, 0 to 890 Data columns (total 12 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 PassengerId 891 non-null int64 1 Survived 891 non-null int64 2 Pclass 891 non-null int64 3 Name 891 non-null object 4 Sex 891 non-null object 5 Age 714 non-null float64 6 SibSp 891 non-null int64 7 Parch 891 non-null int64 8 Ticket 891 non-null object 9 Fare 891 non-null float64 10 Cabin 204 non-null object 11 Embarked 889 non-null object dtypes: float64(2), int64(5), object(5) memory usage: 83.7+ KB
In [5]:
test_data['Survived'] = 0 concat_data = train_data.append(test_data)
C:\Users\Administrator\AppData\Local\Temp\ipykernel_5876\2851212731.py:2: FutureWarning: The frame.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead. concat_data = train_data.append(test_data)
In [6]:
#1) replace the missing value with 'U0'
train_data['Cabin'] = train_data.Cabin.fillna('U0')
#2) replace the missing value with '0' and the existing value with '1'
train_data.loc[train_data.Cabin.notnull(),'Cabin'] = '1'
train_data.loc[train_data.Cabin.isnull(),'Cabin'] = '0'
In [7]:
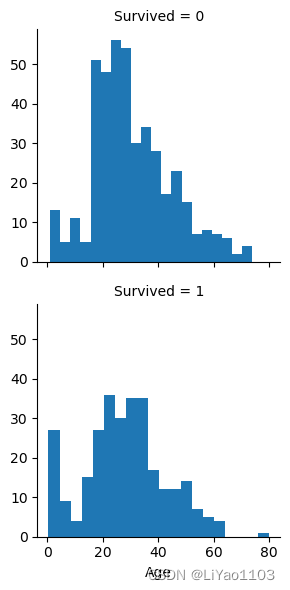
grid = sns.FacetGrid(train_data[['Age','Survived']],'Survived' ) grid.map(plt.hist, 'Age', bins = 20) plt.show( )
C:\Users\Administrator\anaconda3\lib\site-packages\seaborn\_decorators.py:36: FutureWarning: Pass the following variable as a keyword arg: row. From version 0.12, the only valid positional argument will be `data`, and passing other arguments without an explicit keyword will result in an error or misinterpretation. warnings.warn(
In [8]:
from sklearn.ensemble import RandomForestRegressor concat_data['Fare'] = concat_data.Fare.fillna(50) concat_df = concat_data[['Age', 'Fare', 'Pclass','Survived']] train_df_age = concat_df.loc[concat_data['Age'].notnull()] predict_df_age = concat_df.loc[concat_data['Age'].isnull()] X=train_df_age.values[:,1:] Y= train_df_age.values[:,0] RFR = RandomForestRegressor(n_estimators=1000,n_jobs=-1) RFR.fit(X,Y) predict_ages = RFR.predict(predict_df_age.values[:,1:]) concat_data.loc[concat_data.Age.isnull(),'Age'] = predict_ages
In [9]:
sex_dummies = pd.get_dummies(concat_data.Sex)
concat_data.drop('Sex',axis=1,inplace=True)
concat_data = concat_data.join(sex_dummies)
In [10]:
from sklearn.preprocessing import StandardScaler concat_data['Age'] = StandardScaler().fit_transform(concat_data.Age.values.reshape(-1,1))
In [11]:
concat_data['Fare'] = pd.qcut(concat_data.Fare,5) concat_data['Fare'] = pd.factorize(concat_data.Fare)[0]
In [12]:
concat_data.drop(['PassengerId'],axis = 1,inplace = True)