第1关:创建表
题目
任务描述
本关任务:使用Java代码在HBase中创建表。
相关知识
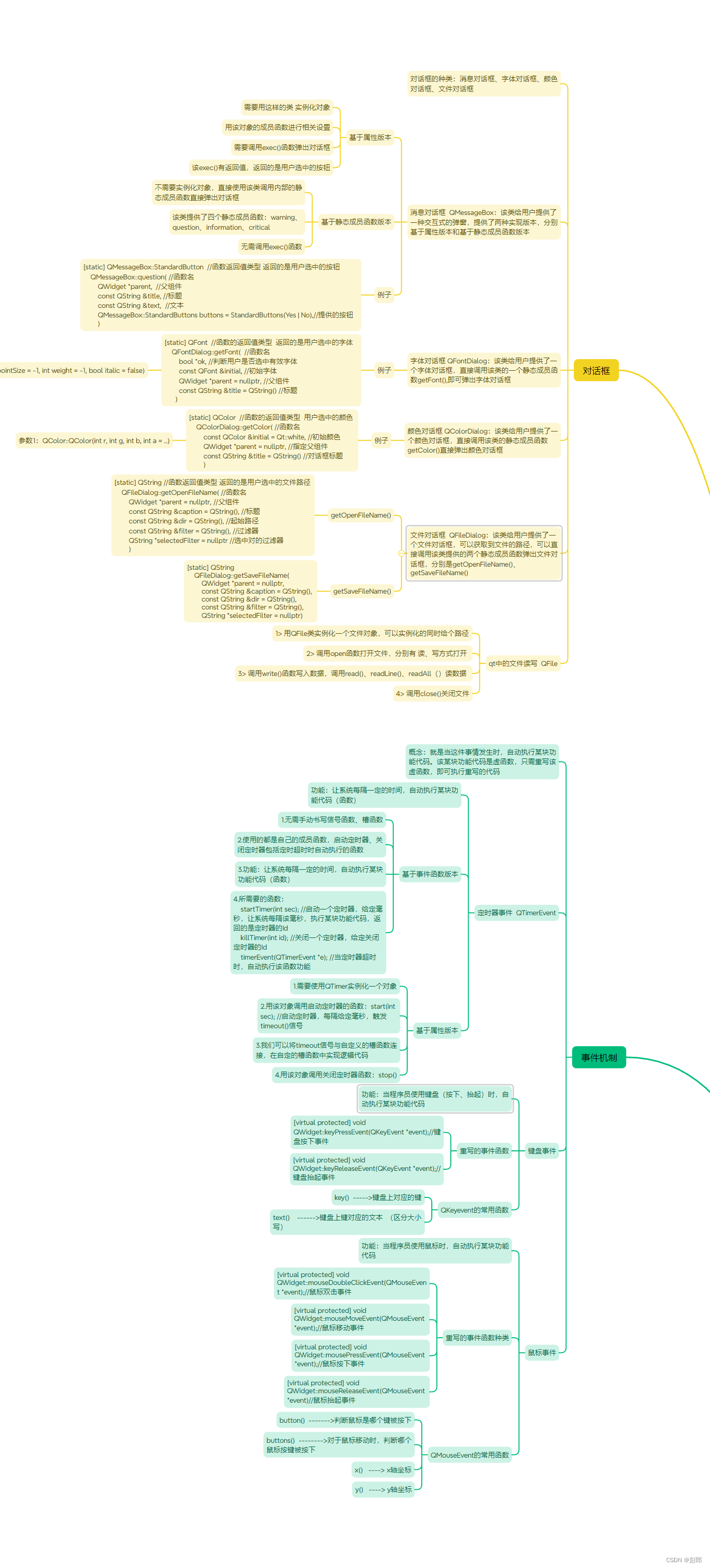
为了完成本关任务,你需要掌握:1.如何使用Java连接HBase数据库,2.如何使用Java代码在HBase中创建表。
如何使用Java连接HBase数据库
Java连接HBase需要两个类:
HBaseConfigurationConnectionFactory
HBaseConfiguration
要连接HBase我们首先需要创建Configuration对象,这个对象我们需要通过HBaseConfiguration(HBase配置)对象来进行创建,HBaseConfiguration看名字我们就能猜到它的用途:读取指定路径下hbase-site.xml和hbase-default.xml的配置信息。
具体用法:
Configuration config = HBaseConfiguration.create(); //使用create()静态方法就可以得到Configuration对象
ConnectionFactory
获取到连接对象Connextion我们就算连接上了HBase了,怎么获取呢?
通过ConnectionFactory(连接工厂)的方法我们就能获取到Connection(连接对象)了。
具体用法:
Connection connection = ConnectionFactory.createConnection(config); //config为前文的配置对象
使用这两个步骤就能完成连接HBase了。
注意:在1.0之前的版本
HBase是使用HBaseAdmin和HTable等来操作HBase的,但是在1.0之后的版本中这些被弃用了,新的客户端API更加干净简洁,本文使用的HBase是2.1.1版本(18年10月发布)的,
创建表
要创建表我们需要首先创建一个Admin对象,然后让它来创建一张表:
Admin admin = connection.getAdmin(); //使用连接对象获取Admin对象TableName tableName = TableName.valueOf("test");//定义表名HTableDescriptor htd = new HTableDescriptor(tableName);//定义表对象HColumnDescriptor hcd = new HColumnDescriptor("data");//定义列族对象htd.addFamily(hcd); //添加admin.createTable(htd);//创建表
HBase2.X创建表
上述创建表的方法是HBase1.X版本的方式,而在HBase2.X的版本中创建表使用了新的API,创建表关键代码如下:
TableName tableName = TableName.valueOf("test");//定义表名//TableDescriptor对象通过TableDescriptorBuilder构建;TableDescriptorBuilder tableDescriptor = TableDescriptorBuilder.newBuilder(tableName);ColumnFamilyDescriptor family = ColumnFamilyDescriptorBuilder.newBuilder(Bytes.toBytes("data")).build();//构建列族对象tableDescriptor.setColumnFamily(family);//设置列族admin.createTable(tableDescriptor.build());//创建表
在2.X版本中主要是HTableDescriptor对象被弃用,取而代之的是TableDescriptor对象,TableDescriptor对象通过TableDescriptorBuilder构建;
TableName tableName = TableName.valueOf("test");TableDescriptorBuilder tableDescriptor = TableDescriptorBuilder.newBuilder(tableName);
然后添加列簇方法变更:
ColumnFamilyDescriptor family = ColumnFamilyDescriptorBuilder.newBuilder(Bytes.toBytes("data")).build();//构建列族对象tableDescriptor.setColumnFamily(family); //设置列族
最后由Admin对象进行创建表操作:
admin.createTable(tableDescriptor.build());
值得咱们注意的是,如果你的HBase环境是1.X的那么你只能使用第一种方式来创建表,如果是2.X的版本,那么两种方式你都可以使用(本实训使用的 HBase是2.1.1版本,所以两种都可用)。
编程要求
好了,到你啦,使用本关知识,在右侧编辑器begin-end处补充代码,请你编写一个Java程序,在HBase中创建表dept,emp,列都为:data。
测试说明
注意:
点击测评之前,请先开启Hadoop(start-dfs.sh)和HBase(start-hbase.sh),并且需要等待HBase初始化完成(20秒左右),否则无法在HBase中创建表。
怎么查看HBase初始化成功了呢?
输入hadoop fs -ls /hbase有如下结果即可:

如果启动过程中出现: datanode running as process 214. Stop it first.说明Hadoop的进程还没有被杀死。
需要我们重新stop-dfs.sh 和stop-hbase.sh,然后在重启。
代码
命令行
start-dfs.sh
start-hbase.sh
package step1;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Admin;
import org.apache.hadoop.hbase.client.ColumnFamilyDescriptor;
import org.apache.hadoop.hbase.client.ColumnFamilyDescriptorBuilder;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.Get;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.ResultScanner;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.client.Table;
import org.apache.hadoop.hbase.client.TableDescriptor;
import org.apache.hadoop.hbase.client.TableDescriptorBuilder;
import org.apache.hadoop.hbase.util.Bytes;
public class Task{
public void createTable()throws Exception{
/********* Begin *********/
Configuration config = HBaseConfiguration.create(); //使用create()静态方法就可以得到Configuration对象
Connection connection = ConnectionFactory.createConnection(config); //config为前文的配置对象
Admin admin = connection.getAdmin(); //使用连接对象获取Admin对象
TableName tableName = TableName.valueOf("dept");//定义表名
//TableDescriptor对象通过TableDescriptorBuilder构建;
TableDescriptorBuilder tableDescriptor = TableDescriptorBuilder.newBuilder(tableName);
ColumnFamilyDescriptor family = ColumnFamilyDescriptorBuilder.newBuilder(Bytes.toBytes("data")).build();//构建列族对象
tableDescriptor.setColumnFamily(family);//设置列族
admin.createTable(tableDescriptor.build());//创建表
tableName = TableName.valueOf("emp");//定义表名
//TableDescriptor对象通过TableDescriptorBuilder构建;
tableDescriptor = TableDescriptorBuilder.newBuilder(tableName);
family = ColumnFamilyDescriptorBuilder.newBuilder(Bytes.toBytes("data")).build();//构建列族对象
tableDescriptor.setColumnFamily(family);//设置列族
admin.createTable(tableDescriptor.build());//创建表
/********* End *********/
}
}
第2关:添加数据
题目
任务描述
本关任务:使用Java代码向HBase集群中创建表并添加数据。
相关知识
为了完成本关任务,你需要掌握:Put、Table对象如何使用。
添加数据
要对一个表添加数据,我们需要一个Put对象,在定义Put对象之前我们需要获取到Table对象,这样才能对指定的表进行操作:
Table table = connection.getTable(tableName);//获取Table对象
try {
byte[] row = Bytes.toBytes("row1"); //定义行
Put put = new Put(row); //创建Put对象
byte[] columnFamily = Bytes.toBytes("data"); //列簇
byte[] qualifier = Bytes.toBytes(String.valueOf(1)); //列
byte[] value = Bytes.toBytes("张三丰"); //值
put.addColumn(columnFamily, qualifier, value);
table.put(put); //向表中添加数据
} finally {
//使用完了要释放资源
table.close();
}
编程要求
好了,到你啦,使用本关知识,在右侧编辑器begin-end处补充代码,请你编写一个Java程序,在HBase中创建表tb_step2,列簇都为:data,添加数据:
- 行号分别为:
row1,row2; - 列名分别为:
1,2; - 值分别为:
张三丰,张无忌。
测试说明
注意事项与上一关相同;
平台会执行你的代码,获取你向表中添加的数据;
预期输出:
row1:张三丰
row2:张无忌
代码
命令行
start-dfs.sh
start-hbase.sh
package step2;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Admin;
import org.apache.hadoop.hbase.client.ColumnFamilyDescriptor;
import org.apache.hadoop.hbase.client.ColumnFamilyDescriptorBuilder;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.Get;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.ResultScanner;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.client.Table;
import org.apache.hadoop.hbase.client.TableDescriptor;
import org.apache.hadoop.hbase.client.TableDescriptorBuilder;
import org.apache.hadoop.hbase.util.Bytes;
public class Task {
public void insertInfo()throws Exception{
/********* Begin *********/
Configuration config = HBaseConfiguration.create(); //使用create()静态方法就可以得到Configuration对象
Connection connection = ConnectionFactory.createConnection(config); //config为前文的配置对象
Admin admin = connection.getAdmin(); //使用连接对象获取Admin对象
TableName tableName = TableName.valueOf("tb_step2");//定义表名
//TableDescriptor对象通过TableDescriptorBuilder构建;
TableDescriptorBuilder tableDescriptor = TableDescriptorBuilder.newBuilder(tableName);
ColumnFamilyDescriptor family = ColumnFamilyDescriptorBuilder.newBuilder(Bytes.toBytes("data")).build();//构建列族对象
tableDescriptor.setColumnFamily(family);//设置列族
admin.createTable(tableDescriptor.build());//创建表
Table table = connection.getTable(tableName);//获取Table对象
try {
byte[] row = Bytes.toBytes("row1"); //定义行
Put put = new Put(row); //创建Put对象
byte[] columnFamily = Bytes.toBytes("data"); //列簇
byte[] qualifier = Bytes.toBytes(String.valueOf(1)); //列
byte[] value = Bytes.toBytes("张三丰"); //值
put.addColumn(columnFamily, qualifier, value);
table.put(put); //向表中添加数据
row = Bytes.toBytes("row2"); //定义行
put = new Put(row); //创建Put对象
columnFamily = Bytes.toBytes("data"); //列簇
qualifier = Bytes.toBytes(String.valueOf(2)); //列
value = Bytes.toBytes("张无忌"); //值
put.addColumn(columnFamily, qualifier, value);
table.put(put); //向表中添加数据
} finally {
//使用完了要释放资源
table.close();
}
/********* End *********/
}
}
第3关:获取数据
题目
任务描述
本关任务:获取HBase中已存在表的数据并输出。
相关知识
为了完成本关任务,你需要掌握:1.如何使用Get对象获取数据,2.如何使用Scan批量输出表中的数据。
获取指定行的数据
我们使用Get对象与Table对象就可以获取到表中的数据了。
//获取数据
Get get = new Get(Bytes.toBytes("row1")); //定义get对象
Result result = table.get(get); //通过table对象获取数据
System.out.println("Result: " + result);
//很多时候我们只需要获取“值” 这里表示获取 data:1 列族的值
byte[] valueBytes = result.getValue(Bytes.toBytes("data"), Bytes.toBytes("1")); //获取到的是字节数组
//将字节转成字符串
String valueStr = new String(valueBytes,"utf-8");
System.out.println("value:" + valueStr);
上述代码就可以查到table对象中行row1的数据了,亲自试试验证一下结果吧。
扫描表中的数据
只获取一行数据显然不能满足我们全部的需求,我们想要获取表中所有的数据应该怎么操作呢?
Scan、ResultScanner对象就派上用场了,接下来我们看个示例你应该就明白这两个对象的用法了:
Scan scan = new Scan();
ResultScanner scanner = table.getScanner(scan);
try {
for (Result scannerResult: scanner) {
System.out.println("Scan: " + scannerResult);
byte[] row = scannerResult.getRow();
System.out.println("rowName:" + new String(row,"utf-8"));
}
} finally {
scanner.close();
}
这样就能将指定表中的数据全部输出到控制台了。
运行上述代码你会看到类似这样的结果:
Scan: keyvalues={row1/data:1/1542657887632/Put/vlen=6/seqid=0}
rowName:row1
Scan: keyvalues={row2/data:2/1542657887634/Put/vlen=6/seqid=0}
rowName:row2
将表的数据和行以及列都展示了。
编程要求
使用本关知识,在右侧编辑器begin-end处补充代码,输出t_step3表中行号为row1,列族为data:1的值(以utf-8编码),输出table_step3表中所有行的行名称(因为直接输出scannerResult会带有时间戳,所以输出行名方便测评)。
测试说明
预期输出:
value:Educoder
rowName:row1
rowName:row2
rowName:row3
rowName:row4
代码
命令行
start-dfs.sh
start-hbase.sh
package step3;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Admin;
import org.apache.hadoop.hbase.client.ColumnFamilyDescriptor;
import org.apache.hadoop.hbase.client.ColumnFamilyDescriptorBuilder;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.Get;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.ResultScanner;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.client.Table;
import org.apache.hadoop.hbase.client.TableDescriptor;
import org.apache.hadoop.hbase.client.TableDescriptorBuilder;
import org.apache.hadoop.hbase.util.Bytes;
public class Task {
public void queryTableInfo()throws Exception{
/********* Begin *********/
Configuration config = HBaseConfiguration.create(); //使用create()静态方法就可以得到Configuration对象
Connection connection = ConnectionFactory.createConnection(config); //config为前文的配置对象
Admin admin = connection.getAdmin(); //使用连接对象获取Admin对象
TableName tableName = TableName.valueOf("t_step3");//定义表名
Table table = connection.getTable(tableName);//获取Table对象
//获取数据
Get get = new Get(Bytes.toBytes("row1")); //定义get对象
Result result = table.get(get); //通过table对象获取数据
// System.out.println("Result: " + result);
//很多时候我们只需要获取“值” 这里表示获取 data:1 列族的值
byte[] valueBytes = result.getValue(Bytes.toBytes("data"), Bytes.toBytes("1")); //获取到的是字节数组
//将字节转成字符串
String valueStr = new String(valueBytes,"utf-8");
System.out.println("value:" + valueStr);
/**
这里是批量显示,换表了
*/
tableName = TableName.valueOf("table_step3");//定义表名
table = connection.getTable(tableName);//获取Table对象
Scan scan = new Scan();
ResultScanner scanner = table.getScanner(scan);
try {
for (Result scannerResult: scanner) {
// System.out.println("Scan: " + scannerResult);
byte[] row = scannerResult.getRow();
System.out.println("rowName:" + new String(row,"utf-8"));
}
} finally {
scanner.close();
}
/********* End *********/
}
}
第4关:删除表
题目
任务描述
本关任务:删除表。
相关知识
本次关卡我们来学习本次实训最后一个内容,删除表。
和HBase shell的操作一样,在Java中我们要删除表,需要先禁用他,然后在删除它。
代码很简单:
TableName tableName = TableName.valueOf("test");
admin.disableTable(tableName); //禁用表
admin.deleteTable(tableName); //删除表
编程要求
好了,到你啦,使用本关知识,在右侧编辑器begin-end处补充代码,编写代码删除t_step4表。
代码
命令行
start-dfs.sh
start-hbase.sh
package step4;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Admin;
import org.apache.hadoop.hbase.client.ColumnFamilyDescriptor;
import org.apache.hadoop.hbase.client.ColumnFamilyDescriptorBuilder;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.Get;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.ResultScanner;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.client.Table;
import org.apache.hadoop.hbase.client.TableDescriptor;
import org.apache.hadoop.hbase.client.TableDescriptorBuilder;
import org.apache.hadoop.hbase.util.Bytes;
public class Task {
public void deleteTable()throws Exception{
/********* Begin *********/
Configuration config = HBaseConfiguration.create(); //使用create()静态方法就可以得到Configuration对象
Connection connection = ConnectionFactory.createConnection(config); //config为前文的配置对象
Admin admin = connection.getAdmin(); //使用连接对象获取Admin对象
TableName tableName = TableName.valueOf("t_step4");
admin.disableTable(tableName); //禁用表
admin.deleteTable(tableName); //删除表
/********* End *********/
}
}