在商超等人流量较为密集的场景下经常会报道出现一些行人在扶梯上摔倒、受伤等问题,随着AI技术的快速发展与不断普及,越来越多的商超、地铁等场景开始加装专用的安全检测预警系统,核心工作原理即使AI模型与摄像头图像视频流的实时计算,通过对行为扶梯上的行为进行实时检测识别来对出现的危险行为进行快速预警响应避免后续出现严重的后果。本文的主要目的就是想要基于商超扶梯场景来开发构建行人安全行为检测识别系统,探索分析基于AI科技提升安全保障的可行性,本文是AI助力商超扶梯等场景安全提升的第五篇文章,前文系列如下:
《科技提升安全,基于SSD开发构建商超扶梯场景下行人安全行为姿态检测识别系统》
https://blog.csdn.net/Together_CZ/article/details/134892776
《科技提升安全,基于YOLOv3开发构建商超扶梯场景下行人安全行为姿态检测识别系统》
https://blog.csdn.net/Together_CZ/article/details/134892866
《科技提升安全,基于YOLOv4开发构建商超扶梯场景下行人安全行为姿态检测识别系统》
https://blog.csdn.net/Together_CZ/article/details/134893058
《科技提升安全,基于YOLOv5系列模型【n/s/m/l/x】开发构建商超扶梯场景下行人安全行为姿态检测识别系统》
https://blog.csdn.net/Together_CZ/article/details/134918766
本文的核心思想就是基于YOLOv6模型来开发构建智能检测识别模型,首先看下实例效果:
Yolov6是美团开发的轻量级检测算法,截至目前为止该算法已经迭代到了4.0版本,每一个版本都包含了当时最优秀的检测技巧和最最先进的技术,YOLOv6的Backbone不再使用Cspdarknet,而是转为比Rep更高效的EfficientRep;它的Neck也是基于Rep和PAN搭建了Rep-PAN;而Head则和YOLOX一样,进行了解耦,并且加入了更为高效的结构。YOLOv6也是沿用anchor-free的方式,抛弃了以前基于anchor的方法。除了模型的结构之外,它的数据增强和YOLOv5的保持一致;而标签分配上则是和YOLOX一样,采用了simOTA;并且引入了新的边框回归损失:SIOU。
YOLOv5和YOLOX都是采用多分支的残差结构CSPNet,但是这种结构对于硬件来说并不是很友好。所以为了更加适应GPU设备,在backbone上就引入了ReVGG的结构,并且基于硬件又进行了改良,提出了效率更高的EfficientRep。RepVGG为每一个3×3的卷积添加平行了一个1x1的卷积分支和恒等映射的分支。这种结构就构成了构成一个RepVGG Block。和ResNet不同的是,RepVGG是每一层都添加这种结构,而ResNet是每隔两层或者三层才添加。RepVGG介绍称,通过融合而成的3x3卷积结构,对计算密集型的硬件设备很友好。

简单看下实例数据情况:

训练数据配置文件如下所示:
# Please insure that your custom_dataset are put in same parent dir with YOLOv6_DIR
train: ./dataset/images/train # train images
val: ./dataset/images/test # val images
test: ./dataset/images/test # test images (optional)
# whether it is coco dataset, only coco dataset should be set to True.
is_coco: False
# Classes
nc: 4 # number of classes
# class names
names: ['bow', 'down', 'shake', 'up']
默认我先选择的是yolov6s系列的模型,基于finetune来进行模型的开发:
# YOLOv6s model
model = dict(
type='YOLOv6s',
pretrained='weights/yolov6s.pt',
depth_multiple=0.33,
width_multiple=0.50,
backbone=dict(
type='EfficientRep',
num_repeats=[1, 6, 12, 18, 6],
out_channels=[64, 128, 256, 512, 1024],
fuse_P2=True,
cspsppf=True,
),
neck=dict(
type='RepBiFPANNeck',
num_repeats=[12, 12, 12, 12],
out_channels=[256, 128, 128, 256, 256, 512],
),
head=dict(
type='EffiDeHead',
in_channels=[128, 256, 512],
num_layers=3,
begin_indices=24,
anchors=3,
anchors_init=[[10,13, 19,19, 33,23],
[30,61, 59,59, 59,119],
[116,90, 185,185, 373,326]],
out_indices=[17, 20, 23],
strides=[8, 16, 32],
atss_warmup_epoch=0,
iou_type='giou',
use_dfl=False, # set to True if you want to further train with distillation
reg_max=0, # set to 16 if you want to further train with distillation
distill_weight={
'class': 1.0,
'dfl': 1.0,
},
)
)
solver = dict(
optim='SGD',
lr_scheduler='Cosine',
lr0=0.0032,
lrf=0.12,
momentum=0.843,
weight_decay=0.00036,
warmup_epochs=2.0,
warmup_momentum=0.5,
warmup_bias_lr=0.05
)
data_aug = dict(
hsv_h=0.0138,
hsv_s=0.664,
hsv_v=0.464,
degrees=0.373,
translate=0.245,
scale=0.898,
shear=0.602,
flipud=0.00856,
fliplr=0.5,
mosaic=1.0,
mixup=0.243,
)
终端执行:
python tools/train.py --batch-size 16 --conf configs/yolov6s_finetune.py --data data/self.yaml --fuse_ab --device 0 --name yolov6s --epochs 100 --workers 2即可启动训练。
日志输出如下所示:

等待训练完成之后,我们来整体看下结果详情:
Training completed in 11.585 hours.
loading annotations into memory...
Done (t=0.01s)
creating index...
index created!
Loading and preparing results...
DONE (t=0.21s)
creating index...
index created!
Running per image evaluation...
Evaluate annotation type *bbox*
DONE (t=2.20s).
Accumulating evaluation results...
DONE (t=0.31s).
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.667
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.914
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.769
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.277
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.403
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.727
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.627
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.734
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.798
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.491
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.753
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.818可视化推理实例如下所示:

热力图效果如下所示:
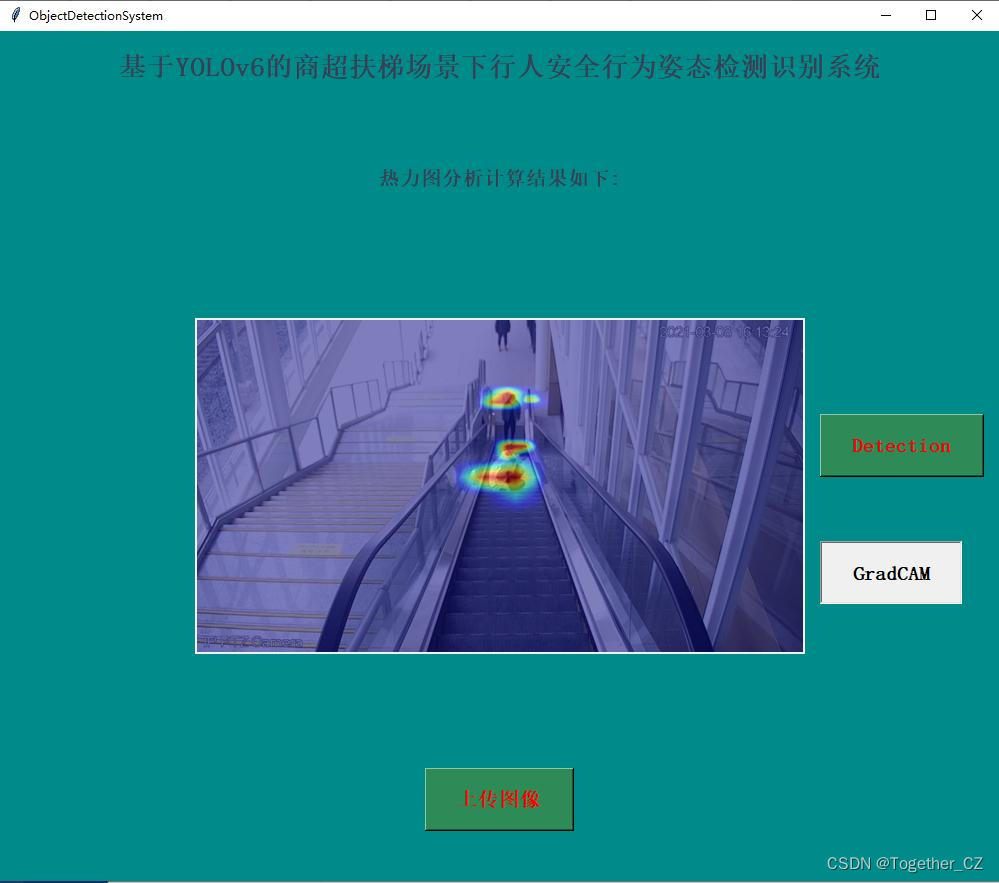
感兴趣的话也都可以自行尝试一下!