文章目录
- 上一节内容:LangChain学习二:提示-实战(上半部分)
- 学习目标:提示词中的示例选择器和输出解释器
- 学习内容一:示例选择器
- 1.1 LangChain自定义示例选择器
- 1.2 实现自定义示例选择器
- 1.2.1实战:定义一个类继BaseExampleSelector并且承实现方法
- 1.2.2实战:使用示例选择器
- 1.3 实现基于长度的选择器
- 1.4 最大边际相关性示例选择器
- 1.5 gram重叠
- 1.5.1 创建示例集
- 1.5.2 选择示例
- 1.5.2.1 threshold=-1.0,示例排序、不排除任何示例
- 1.5.2.2 threshold=0.0,`排除`具有与输入无ngram重叠的示例
- 1.5.2.3 threshold大于0小于1意味着只有相似度大于 设置值的示例才会被选择
- 1.5.2.4 threshold大于1,不会选择任何
- 1.6 相似度
- 学习内容二:输出解析器
上一节内容:LangChain学习二:提示-实战(上半部分)
LangChain学习二:提示-实战(上半部分)
学习目标:提示词中的示例选择器和输出解释器
- 示例选择器:在写提示词的时候给与少量的示例在前面,在上一节的最后提到,这一节细化说一下
- 输出解释器:语言模型输出文本。但是很多时候,你可能想要获得比文本更结构化的信息。这就是输出解析器的作用。
学习内容一:示例选择器
1.1 LangChain自定义示例选择器
自定义示例选择器它的英文名叫做few shot examples:就像我们教小朋友一样,比如教小朋友分类水果,先给他演示一下水果怎么分类的,红色的放哪一个框框,白色的放哪一个框框,然后在给它一个新的水果,小朋友根据你教的示范,就会自己去分类了
具体在上一节的2.5有介绍
1.2 实现自定义示例选择器
具体步骤如下
- 定义一个类,继承BaseExampleSelector
- 实现add_example方法,它接受一个示例并将其添加到该ExampleSelector中。
- 实现select_examples方法,它接受输入变量(这些变量应为用户输入),并返回要在few-shot提示中使用的示例列表。
1.2.1实战:定义一个类继BaseExampleSelector并且承实现方法
from langchain.prompts.example_selector.base import BaseExampleSelector
from typing import Dict, List
import numpy as np
class CustomExampleSelector(BaseExampleSelector):
def __init__(self, examples: List[Dict[str, str]]):
self.examples = examples
def add_example(self, example: Dict[str, str]) -> None:
"""为密钥添加要存储的新示例。"""
self.examples.append(example)
def select_examples(self, input_variables: Dict[str, str]) -> List[dict]:
"""根据输入选择要使用的示例。 你可以在这里写你自己的算法,我这里就表示随机从examples里拿两个示例,replace表示不会重复"""
return np.random.choice(self.examples, size=2, replace=False)
1.2.2实战:使用示例选择器
examples = [
{"foo": "1"},
{"foo": "2"},
{"foo": "3"}
]
# 初始化示例选择器。
example_selector = CustomExampleSelector(examples)
#选择示例
example_selector.select_examples({"foo": "foo"})
# -> array([{'foo': '2'}, {'foo': '3'}], dtype=object)
# 将新示例添加到示例集
example_selector.add_example({"foo": "4"})
print(f"======查看现在有哪些示例\n{example_selector.examples}\n")
# -> [{'foo': '1'}, {'foo': '2'}, {'foo': '3'}, {'foo': '4'}]
# 选择示例
llm_example=example_selector.select_examples({"foo": "foo"})
print(f"======选择示例\n{llm_example}\n")


因为这里选择写的是随机的,所以这里就是随机的找两条
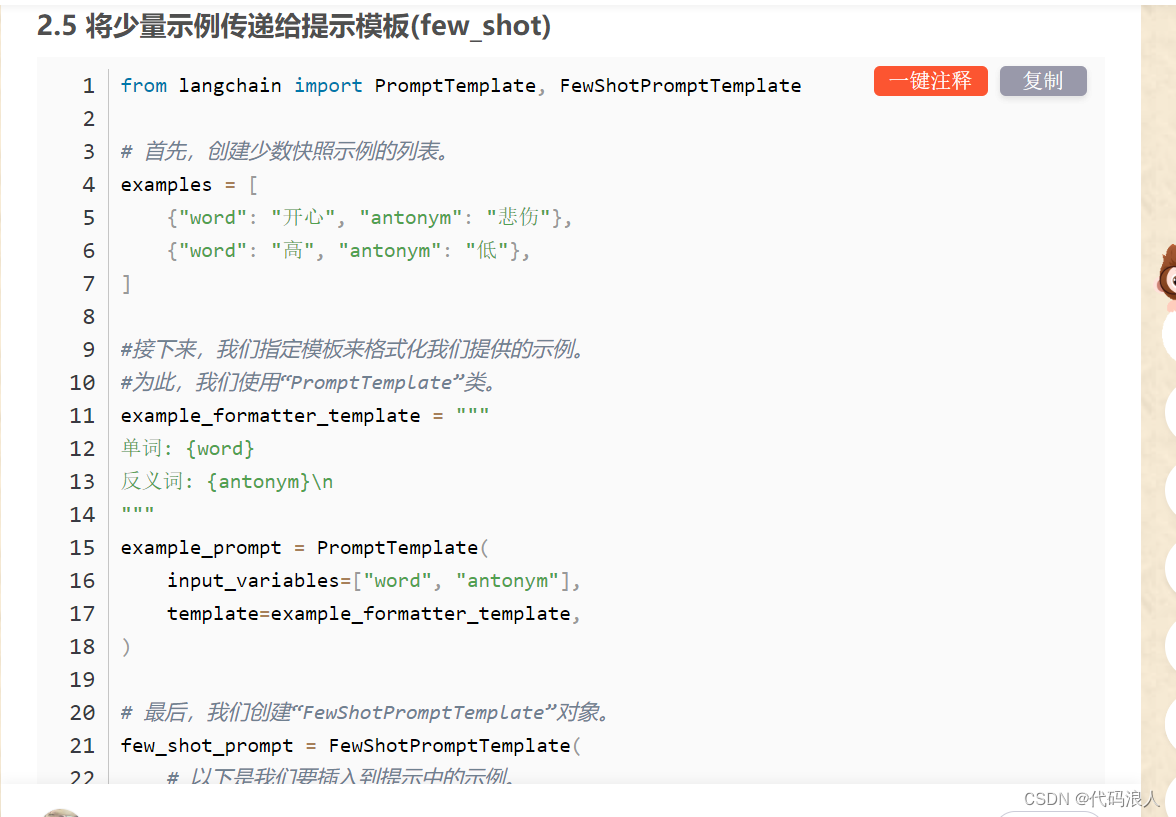
1.3 实现基于长度的选择器
总长度是由max_length控制的,如果我们输入的长一些,就会少从examples 拿一些,输入短,则反之
from langchain import PromptTemplate, FewShotPromptTemplate
# 首先,创建少数快照示例的列表。
from langchain.prompts import LengthBasedExampleSelector
examples = [
{"word": "开心", "antonym": "悲伤"},
{"word": "高", "antonym": "低"},
]
# 接下来,我们指定模板来格式化我们提供的示例。
# 为此,我们使用“PromptTemplate”类。
example_formatter_template = """
单词: {word}
反义词: {antonym}\n
"""
example_prompt = PromptTemplate(
input_variables=["word", "antonym"],
template=example_formatter_template,
)
#我们将使用' LengthBasedExampleSelector '来选择示例。
example_selector = LengthBasedExampleSelector(
# 这些是可供选择的例子。
examples=examples,
#这是用于格式化示例的PromptTemplate。
example_prompt=example_prompt,
# 这是格式化示例的最大长度。
# 长度由下面的get_text_length函数测量。
max_length=25,
)
# 我们现在可以使用' example_selector '来创建' FewShotPromptTemplate '。
dynamic_prompt = FewShotPromptTemplate(
# We provide an ExampleSelector instead of examples.
example_selector=example_selector,
example_prompt=example_prompt,
prefix="给出每个输入的反义词",
suffix="单词: {input}\n反义词:",
input_variables=["input"],
example_separator="",
)
# We can now generate a prompt using the `format` method.
print(dynamic_prompt.format(input="大"))
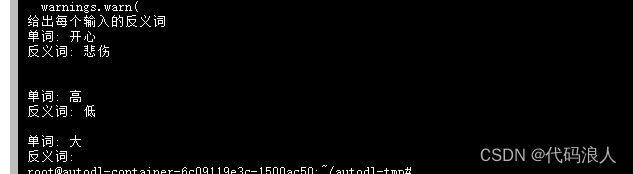
这个是上一节举的例子,当然上一节没有提到现在的示例添加新的示例方法
#您也可以将示例添加到示例选择器中。
new_example = {"word": "大", "antonym": "小"}
dynamic_prompt.example_selector.add_example(new_example)
print(dynamic_prompt.format(input="多"))

1.4 最大边际相关性示例选择器
这种示例选择器基于与输入之间的边际相关性来选择示例。它计算每个示例与输入之间的相关性,并选择具有最高相关性的示例作为回答。
这种方法适用于输入和示例之间有很强相关性的情况,例如问答系统中的问题和答案。
这里我们要借助一个类MaxMarginalRelevanceExampleSelector
MaxMarginalRelevanceExampleSelector:基于哪些示例与输入最相似以及优化多样性的组合选择示例。
这里我们用m3e-base作为向量化引擎
下载
from modelscope.hub.snapshot_download import snapshot_download
local_dir_root = "/root/autodl-tmp/models_from_modelscope"
snapshot_download('Jerry0/m3e-base', cache_dir=local_dir_root)
from langchain.prompts.example_selector import MaxMarginalRelevanceExampleSelector
from langchain.vectorstores import FAISS
from langchain.embeddings import OpenAIEmbeddings
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.prompts import FewShotPromptTemplate, PromptTemplate
embeddings = HuggingFaceEmbeddings(
model_name = "/root/autodl-tmp/models_from_modelscope/Jerry0/m3e-base",
model_kwargs = {'device': 'cuda'})
example_prompt = PromptTemplate(
input_variables=["input", "output"],
template="Input: {input}\nOutput: {output}",
)
#这是许多创建反义词的假装任务的例子。
examples = [
{"input": "开心", "output": "悲伤"},
{"input": "发呆", "output": "兴奋"},
{"input": "高", "output": "底"},
{"input": "精力充沛的", "output": "无精打采"},
{"input": "晴天", "output": "雨天"},
{"input": "天上", "output": "地下"},
]
example_selector = MaxMarginalRelevanceExampleSelector.from_examples(
#这是可供选择的示例列表。
examples,
#这是用于生成用于测量语义相似性的嵌入的嵌入类。
embeddings,
#这是VectorStore类,用于存储嵌入并进行相似性搜索。
FAISS,
#这是要生成的示例数。
k=2
)
mmr_prompt = FewShotPromptTemplate(
#我们提供了ExampleSelector而不是示例。
example_selector=example_selector,
example_prompt=example_prompt,
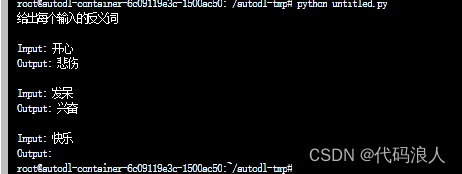
prefix="给出每个输入的反义词",
suffix="Input: {adjective}\nOutput:",
input_variables=["adjective"],
)
# 输入是一种感觉,所以应该选择快乐/悲伤的例子作为第一个
print(mmr_prompt.format(adjective="快乐"))
1.5 gram重叠
其实是对1.4的补充和优化
我们需要借助一个NGramOverlapExampleSelector的类,然后根据ngram重叠得分选择和排序示例.
该得分表示示例与输入的相似程度
ngram重叠得分是一个介于0.0和1.0之间的浮点数。
-
选择器允许设置阈值得分。 ngram重叠得分小于或等于阈值的示例将被排除。默认情况下,阈值设置为
-1.0,因此不会排除任何示例,只会对它们进行重新排序。 -
将阈值设置为0.0将
排除具有与输入无ngram重叠的示例
1.5.1 创建示例集
pip install nltk
from langchain.prompts import PromptTemplate
from langchain.prompts.example_selector.ngram_overlap import NGramOverlapExampleSelector
from langchain.prompts import FewShotPromptTemplate, PromptTemplate
# 创建模板
example_prompt = PromptTemplate(
input_variables=["input", "output"],
template="输入: {input}\n输出: {output}",
)
#示例集合:这些是虚构翻译任务的例子:英语转化为葡萄牙语
examples = [
{"input": "See Spot run.", "output": "Ver correr a Spot."},
{"input": "My dog barks.", "output": "Mi perro ladra."},
{"input": "Spot can run.", "output": "Spot puede correr."},
]
1.5.2 选择示例
1.5.2.1 threshold=-1.0,示例排序、不排除任何示例
example_prompt = PromptTemplate(
input_variables=["input", "output"],
template="Input: {input}\nOutput: {output}",
)
example_selector = NGramOverlapExampleSelector(
# 以下是可供选择的示例。
examples=examples,
# 这是用于格式化示例的PromptTemplate。
example_prompt=example_prompt,
# 这是选择器停止的阈值。
# 默认情况下,它设置为-1.0。
threshold=-1.0,
#对于负阈值:
#Selector按ngram重叠分数对示例进行排序,不排除任何示例。
#对于大于1.0的阈值:
#选择器排除所有示例,并返回一个空列表。
#对于等于0.0的阈值:
#Selector根据ngram重叠分数对示例进行排序,
#并且排除与输入没有ngram重叠的那些。
)
dynamic_prompt = FewShotPromptTemplate(
# We provide an ExampleSelector instead of examples.
example_selector=example_selector,
example_prompt=example_prompt,
prefix="提供每个Input的西班牙语翻译",
suffix="Input: {sentence}\nOutput:",
input_variables=["sentence"],
)
#一个与“Spot can run”有较大ngram重叠的示例输入
#与“我的狗叫”没有重叠
print(dynamic_prompt.format(sentence="Spot can run fast."))

让我们添加示例,再来一次
new_example = {"input": "Spot plays fetch.", "output": "Spot juega a buscar."}
example_selector.add_example(new_example)
print(dynamic_prompt.format(sentence="Spot can run fast."))
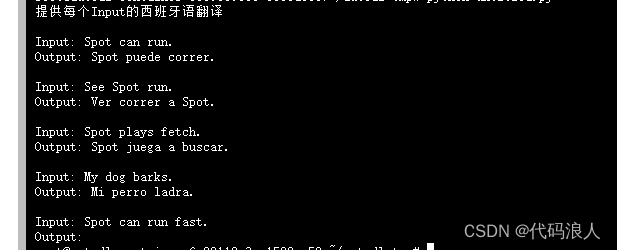
我们可以看到 他确实进行了排序,我们的问题是,Spot跑的飞快
而且第一个是Spot可以跑,第二个看见Spot跑,第三个Spot在玩游戏
第四个:我的狗再叫
第三第四个很明显不符合,所以在最后
1.5.2.2 threshold=0.0,排除具有与输入无ngram重叠的示例
example_selector.threshold=0.0
print(dynamic_prompt.format(sentence="Spot can run fast."))

这里就把第三第四给排除了
1.5.2.3 threshold大于0小于1意味着只有相似度大于 设置值的示例才会被选择
example_selector.threshold=0.09
print(dynamic_prompt.format(sentence="Spot can play fetch."))

1.5.2.4 threshold大于1,不会选择任何
1.0 + 1e-9 的结果是 1.000000001,即在 1.0 的基础上增加了一个非常小的数 1e-9。这种写法通常是为了解决在计算机中浮点数运算可能产生的精度问题。
在这段代码中,将 example_selector.threshold 的值设为 1.0+1e-9,其实就是设置一个非常接近于 1.0,但又比它略大一点点的阈值。这样做可能会使得更多的示例被选择,因为在相似度计算中可能存在一些舍入误差或计算误差,导致某些本来应该被选择的示例未能被选中。
example_selector.threshold=1.0+1e-9
print(dynamic_prompt.format(sentence="Spot can play fetch."))

这里只会显示我们输入的,不会选择任何示例
1.6 相似度
最大边际相关性 ExampleSelector 和 相似度 ExampleSelector 都是示例选择器,它们的区别在于选择示例的方法不同。
相似度 ExampleSelector 则使用文本相似度度量来选择最相关的示例。它不仅考虑了输入和示例之间的相关性,还考虑了它们之间的相似度。具体而言,它计算输入和示例之间的相似度,然后选择与输入最相似的示例作为回答。这种方法适用于输入和示例之间没有直接的相关性,但它们在语义或形式上非常相似的情况,例如聊天机器人对话中的语句。
最大边际相关性 ExampleSelector:
- 基于输入与示例之间的边际相关性来选择示例。
- 计算每个示例与输入之间的相关性,并选择具有最高相关性的示例作为回答。
- 适用于输入和示例之间有明显相关性的情况,例如问答系统中的问题和答案。
相似度 ExampleSelector:
- 使用文本相似度度量来选择最相关的示例。
- 不仅考虑输入和示例之间的相关性,还考虑它们之间的相似度。
- 计算输入和示例之间的相似度,然后选择与输入最相似的示例作为回答。
- 适用于输入和示例之间没有直接的相关性,但在语义或形式上非常相似的情况,例如聊天机器人对话中的语句。
总结:
最大边际相关性 ExampleSelector 关注输入与示例之间的相关性,而相似度 ExampleSelector 则重点考虑它们之间的相似度。两种选择器在选择示例时的侧重点不同,适用于不同的应用场景和数据特征。
说白了就是通过找到嵌入与输入具有最大余弦相似度的示例,然后迭代地添加它们,同时筛选它们与已选择示例的接近程度来实现这一目的。
其实这里《LangChain学习一:模型-实战》中文本嵌入有介绍,这里我们在复习一下
就是说从很多的示例集中,我们通过向量的方式去找到示例里和我们提的问题语义相近的内容作为示例,然后在给大模型,这里就不啰嗦介绍了,那一节里介绍的比较全
学习内容二:输出解析器
未完成待续,明晚继续,睡觉