单条轨迹的处理:geolife笔记:整理处理单条轨迹-CSDN博客
1 加载数据
import pandas as pd
import numpy as np
import datetime as dt
import os
data_dir = 'Geolife Trajectories 1.3/Data/'1.1 列出所有文件夹
dirlist = os.listdir(data_dir)
dirlist
'''
['133',
'079',
'173',
'020',
'003',
'004',
'014',
'074',
...
'''1.2 拼接出所有绝对路径
folder_dirs = []
for dir in dirlist:
folder_dirs.append(data_dir + '/' + dir+'/'+'Trajectory')
folder_dirs
'''
['data/Geolife Trajectories 1.3/Data//133/Trajectory',
'data/Geolife Trajectories 1.3/Data//079/Trajectory',
'data/Geolife Trajectories 1.3/Data//173/Trajectory',
'data/Geolife Trajectories 1.3/Data//020/Trajectory',
'data/Geolife Trajectories 1.3/Data//003/Trajectory',
...
'''1.3 列出所有文件
file_dirs=[]
for dir in folder_dirs:
for file in os.listdir(dir):
file_dirs.append(dir+'/'+file)
len(file_dirs),file_dirs
'''
(18670,
['data/Geolife Trajectories 1.3/Data//133/Trajectory/20110130143621.plt',
'data/Geolife Trajectories 1.3/Data//133/Trajectory/20110419143237.plt',
'data/Geolife Trajectories 1.3/Data//133/Trajectory/20110421082008.plt',
'data/Geolife Trajectories 1.3/Data//133/Trajectory/20110420024807.plt',
...
'''2 读取所有文件,并拼接到一个DataFrame中
2.1 计算haversine距离的函数
def haversine_distance(lat1, lon1, lat2, lon2):
R = 6371 # Earth radius in kilometers
dlat = np.radians(lat2 - lat1)
dlon = np.radians(lon2 - lon1)
a = np.sin(dlat/2) * np.sin(dlat/2) + np.cos(np.radians(lat1)) * np.cos(np.radians(lat2)) * np.sin(dlon/2) * np.sin(dlon/2)
c = 2 * np.arctan2(np.sqrt(a), np.sqrt(1-a))
return R * c
2.2 读取文件
所有对应的操作都在单条轨迹处理中已经说明
import pandas as pd
import numpy as np
traj=pd.DataFrame()
traj
num=0
for file in file_dirs:
#read data:
data = pd.read_csv(file,
header=None,
skiprows=6,
names=['Latitude', 'Longitude', 'Not_Important1', 'Altitude', 'Not_Important2', 'Date', 'Time'])
'''
merge date and time
'''
data['Datetime'] = pd.to_datetime(data['Date'] + ' ' + data['Time'])
data=data[['Latitude', 'Longitude', 'Altitude', 'Datetime']]
'''
retain positions in Beijing city
'''
data=data[(data['Latitude']>B1[0]) & (data['Latitude']<B2[0]) & (data['Longitude']>B1[1]) & (data['Longitude']<B2[1])]
'''
time gap to 5s, and remain first record every 5s
'''
data['Datetime_5s']=data['Datetime'].dt.floor('5s')
data=data.drop_duplicates(subset=['Datetime_5s'],keep='first')
'''
remove stopping point
'''
data['is_moving'] = (data['Latitude'] != data['Latitude'].shift()) | (data['Longitude'] != data['Longitude'].shift())
data=data[data['is_moving']==True]
data=data[['Latitude','Longitude','Datetime_5s']]
'''
split trajs without records in 10min into 2 trajs (and update id)
'''
data['time_diff']=data['Datetime_5s'].diff()
data['split_id']=0
mask=data['time_diff']>pd.Timedelta(minutes=10)
data.loc[mask,'split_id']=1
data['split_id']=data['split_id'].cumsum()
data['id']=str(num)
num+=1
data['id']=data['id']+'_'+data['split_id'].astype(str)
'''
calc each traj's length, filter out short trajs and truncate long ones
'''
#calculate nearby location's lon and lat gap
lat_lon_diff = data.groupby('id',group_keys=False).apply(lambda group: group[['Latitude', 'Longitude']].diff())
#calc nearby locationn's distance
distance = lat_lon_diff.apply(lambda row: haversine_distance(row['Latitude'], row['Longitude'], 0, 0), axis=1)
data['distance']=distance
#calculate each id's accumulated distance
data['accum_dis']=data.groupby('id')['distance'].cumsum()
#split those trajs longer than 10km into 2 trajs
data['split_traj_id']=data['accum_dis']//10
data['split_traj_id']=data['split_traj_id'].fillna(0)
data['split_traj_id']=data['split_traj_id'].astype(int).astype(str)
#get new id
data['id']=data['id']+'_'+data['split_traj_id']
#remove those shorter than 1km
iid=data.groupby('id')['accum_dis'].max()
iid=iid.reset_index(name='distance')
iid=iid[iid['distance']>1]
data=data[data['id'].isin(iid['id'])]
'''
filter trajs shorter than 10 records
'''
iid=data.groupby('id').size()
iid=iid.reset_index(name='count')
iid=iid[iid['count']>=10]
data=data[data['id'].isin(iid['id'])]
'''
remove 'staypoints'
'''
latlon=pd.DataFrame()
latlon['max_lat']=data.groupby('id')['Latitude'].max()
latlon['min_lat']=data.groupby('id')['Latitude'].min()
latlon['max_lon']=data.groupby('id')['Longitude'].max()
latlon['min_lon']=data.groupby('id')['Longitude'].min()
latlon['max_dis']=latlon.apply(lambda row: haversine_distance(row['max_lat'],row['max_lon'],row['min_lat'],row['min_lon']),axis=1)
latlon=latlon[latlon['max_dis']>=1]
data=data[data['id'].isin(latlon.index)]
data=data[['Latitude','Longitude','Datetime_5s','id']]
#print(data)
traj=pd.concat([traj,data])traj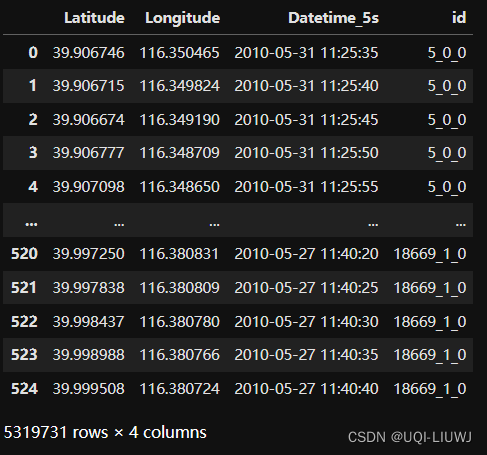
2.3 保存文件
traj.to_csv('geolife_processed.csv')