最近阅读了Ulrich Drepper大牛的论文《What Every Programmer Should Know About Memory》,全文114页,尽管2007年出版,但如今看过来,仍干货满满。接来下对文中提及的知识,结合自己对内存知识的理解,对程序员需要了解的内存知识做一次总结。
内存概述
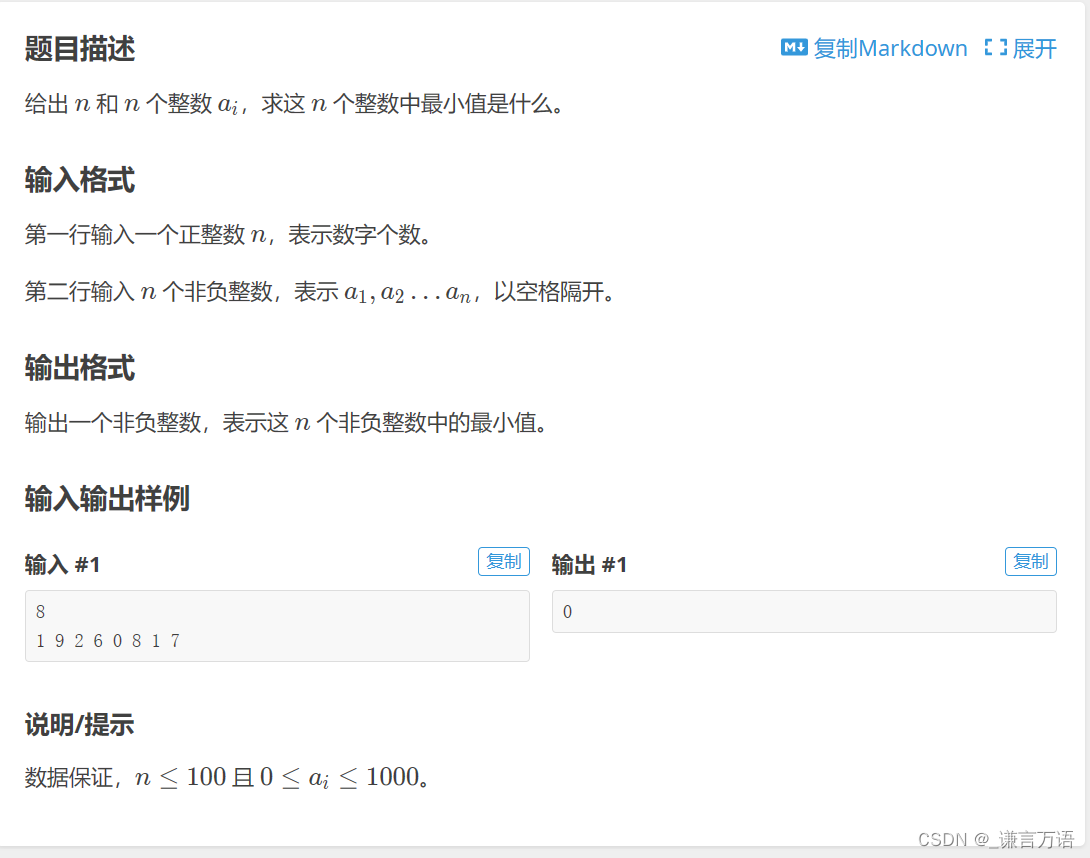
简单来说,计算机由CPU、内存、块设备、网络组成,这几部分子系统独立发展,但是内存、块设备相对于CPU、网络的发展速度来说是比较慢的,块设备发展缓慢通过软件来解决,即page cache。内存的发展主要包括4个方面:
1、RAM硬件设计(速度和并行化)
2、内存控制器
3、CPU cache
4、DMA
硬件架构发展
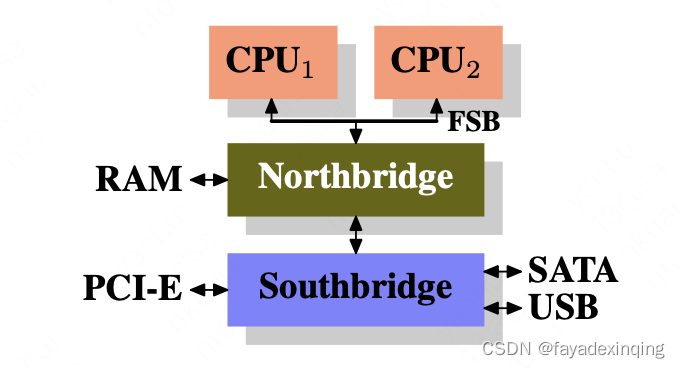
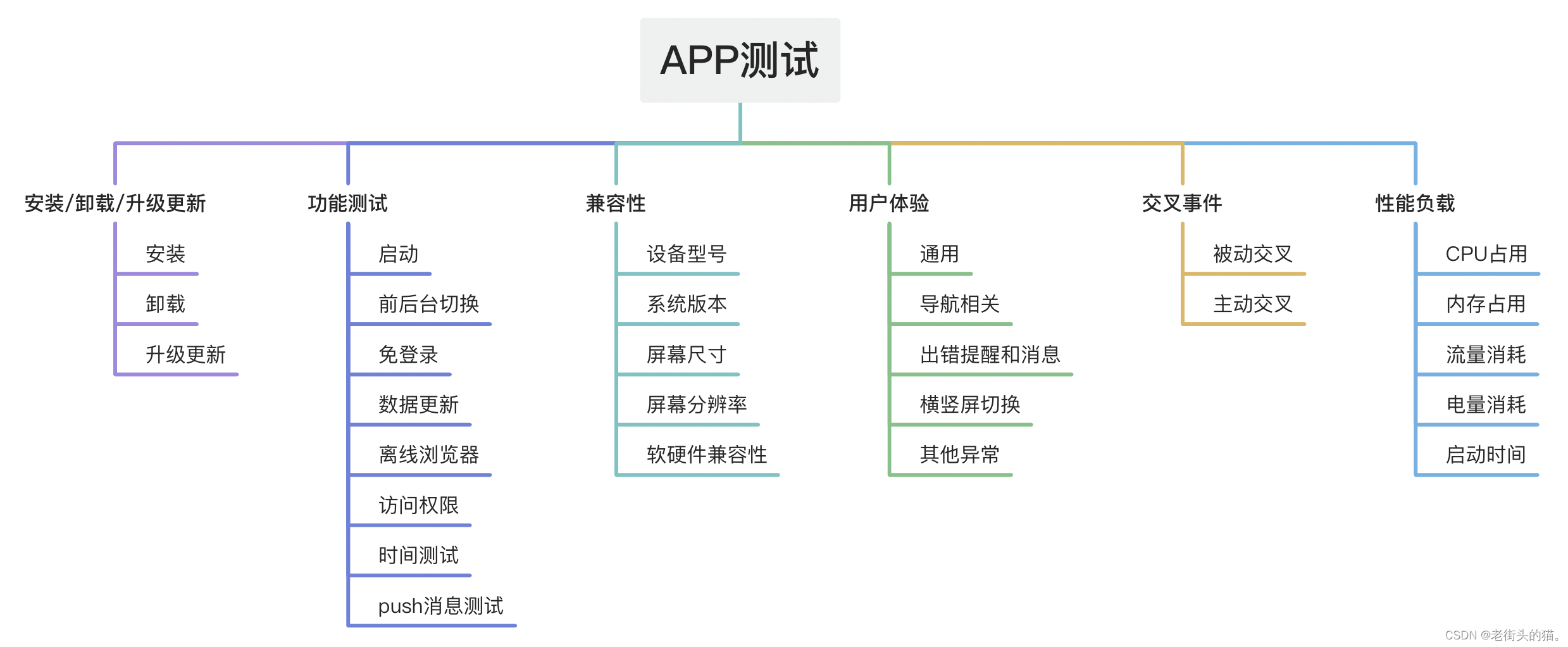
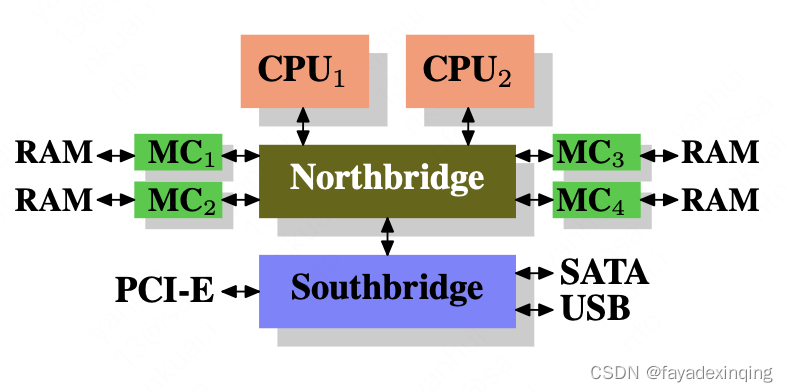
计算机早期架构:CPU通过FSB(the Front Side Bus)与北桥相连,北桥中包含内存控制器,内存控制器决定了内存的类型,比如DRAM、SDRAM等。北桥与南桥相连,南桥通常也被称为I/O桥,通过丰富的协议连接其他外设,包括PCI、USB、SATA。
更详细的图:
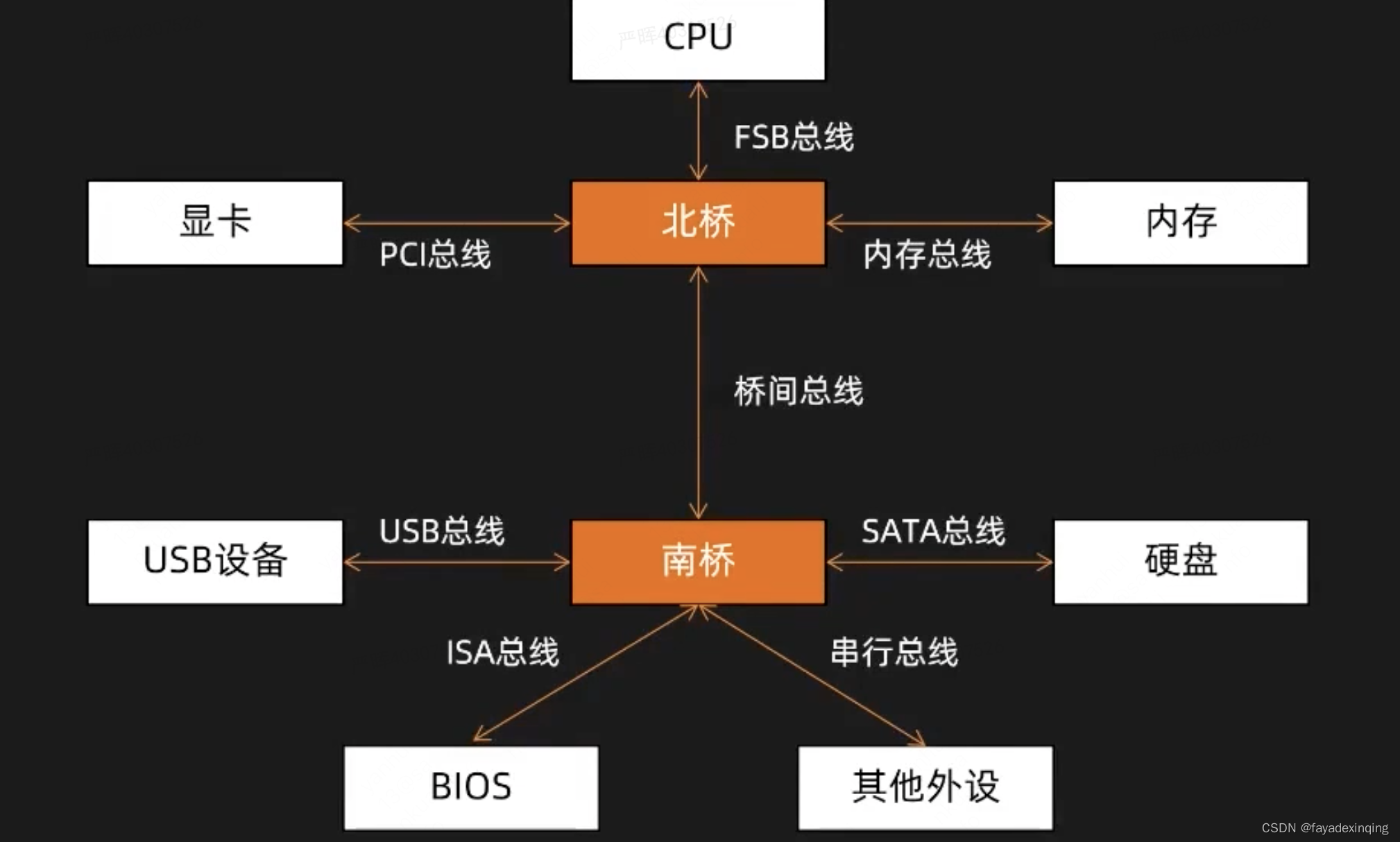
这套架构在性能上有几点瓶颈:
1、RAM与外设之间的数据访问
2、CPU与RAM之间的数据访问
DMA
早期CPU想把数据从外设搬到内存,或者从内存搬到外设时,CPU需要阻塞等待数据搬运完成,由于CPU的速度远大于外设的速度,同时这期间CPU无法做其他事情,效率很低。
比如通过read()把数据从磁盘读到内存中的过程:
1、CPU发送指令给磁盘控制器,然后返回
2、磁盘控制器接收到指令之后,开始从磁盘上读取数据,把数据放到缓冲区之后,产生一个中断
3、CPU接收到中断信号之后,停下手头的工作,开始从磁盘缓冲区中读取数据,这个过程中CPU需要一次一个地址一个地址的读取(32bit or 64bit),把数据读取到自己的寄存器中,再把寄存器中的数据搬运到内存中,整个过程中CPU是无法做其他事情的。
CPU的速度远大于磁盘速度,因此CPU存在很多无意义的等待。
有了DMA之后,数据搬运的工作就由DMA完成,CPU就可以处理其他事情。
1、操作系统受到read()时,将命令发送给DMA,然后CPU做其他事情
2、DMA将指令发送给磁盘控制器,磁盘控制器接收到指令之后,开始从磁盘上读取数据,把数据放到缓冲区之后,产生一个中断
3、DMA接受到中断信号之后,就将缓冲区中的数据搬运到内核空间中,这个过程中CPU不需要参与
4、搬运完成之后,DMA给CPU发送一个中断信号,CPU受到中断信号之后,知道数据已经准备好了,就可以把数据从内核空间拷贝到用户空间,给用户返回
多个RAM
为了加快CPU与RAM之间的数据访问,两个方向:
1、用多个内存控制器,加大带宽,提高并行度,这样瓶颈就来到了北桥的总线传输上
2、每个CPU都有一个独立的RAM
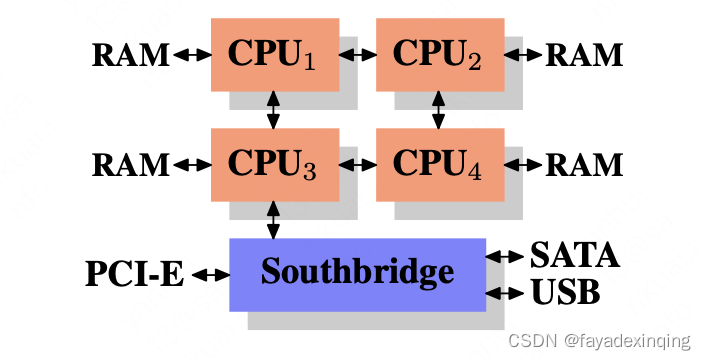
这套架构也有缺点,在介绍NUMA架构时再解释。
内存类型
静态RAM(SRAM)和动态RAM(DRAM),SRAM比DRAM速度更快,但是成本更高,一般在cache中使用,DRAM是我们常说的内存,两者的硬件实现:
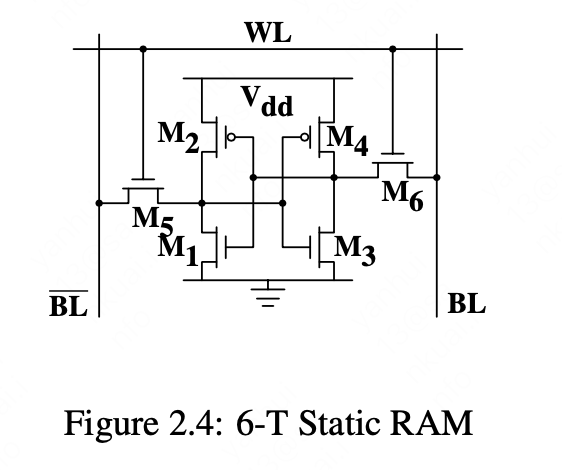
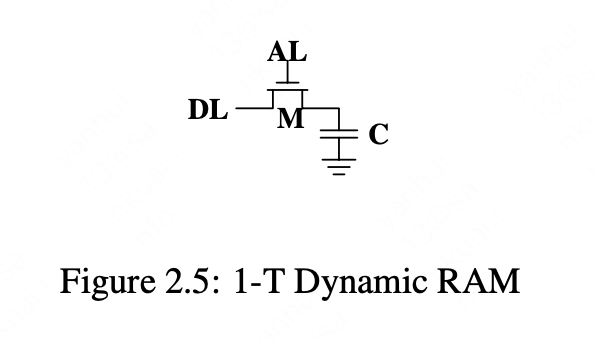
DRAM由电容和MOS管组成,由于电容的漏电特性,DRAM需要周期性的刷新充电
DRAM访问
程序中通过虚拟地址选择一个内存位置,CPU将其翻译成物理地址,最终内存控制器根据物理地址找到这块内存,这步是通过多路选择器完成: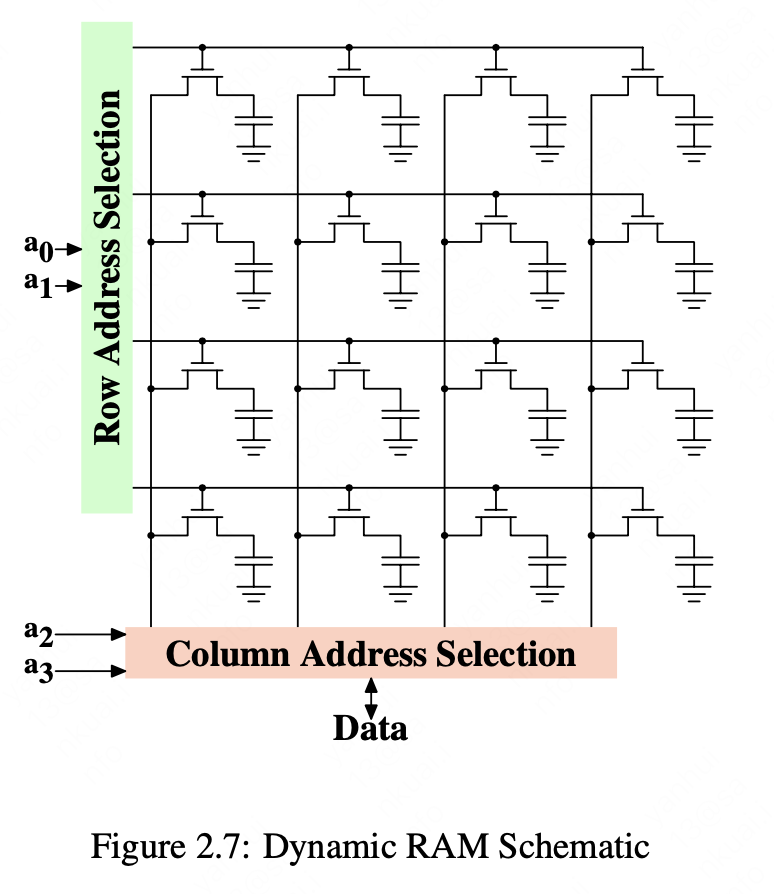
CPU cache
为什么内存不用SRAM呢,主要是因为成本,所以现在主流架构是用一小部分SRAM做cache,主存用DRAM
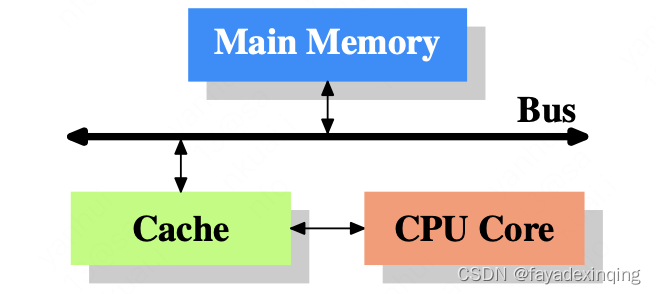
随着cache与主存之间访问速度的增加,可以继续在两者之间加容量更大,但是速度比cache更慢的下一级cache,当今的CPU架构中,一般有3级cache,并且在将来随着CPU核数的增加,cache级数有可能还会增加
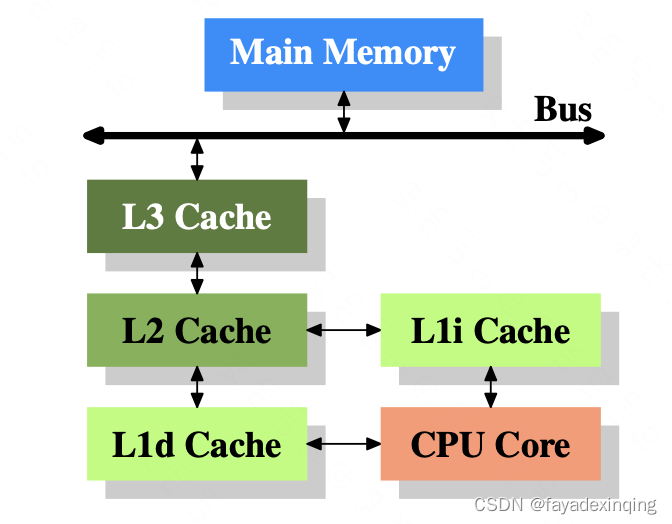
LI cache分成指令cache和数据cache
多处理器、多core的架构如下:
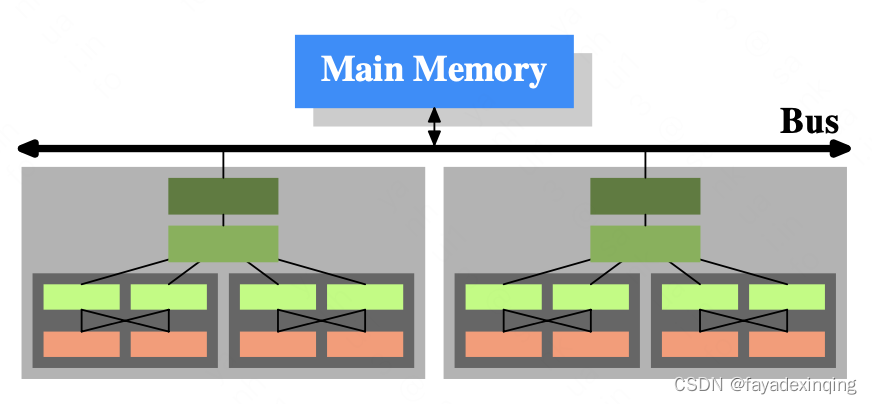
cache访问
cache能够成功应用的前提是局部性原理,包括空间局部性和时间局部性。
CPU每次读写主存都是先通过cache,对于读,先读cache,如果cache中没有对应的word,则从主存中加载对应word到cache中,对于写,直接写cache,然后由后台机制同步到主存中。CPU每次访问cache的大小单位是一个cache line,默认为64byte。
cache的组织形式如下:cache有组数和路数这样一个二维数组组织,二维数据中每个单元就是一个缓存快,总cache大小= 组数* 路数 * cache line,按照组数和路数的不同,分为三种:
1、直接相连映射:只有一路
2、全相连映射:只有一组
3、组组相连映射:多组、多路
从效率和硬件实现上考虑,组组相连映射效率更高、实现最简单,也最常用,其他两种类型也有对应的用途。
每个缓存款由 标志位、tag、数据块组成,标志位有V(是否有效),M(是有被修改)等,tag位(一共Bbit)用来比较缓存块与内存中的地址,数据块是存放cache line的地方。
cache寻址的过程如下:对于32bit地址寻址一个字节,cache line是64byte,假设此时有32组、4路。地址对32取模得到对应的组号,即:(addr >> 6) & ox1F,addr的低6位是在cache line中的偏移,2^6是64。当找到对应的组后,需要再找到对应的路,这就需要对每一路对比addr的高21bit与缓存块的tag位,如果相等,则找到对应的路,然后再根据addr中低6bit的偏移从cache line中找到对应的字节。
缓存替换算法
最近最少使用算法,LRU
缓存对程序性能的影响
1、缓存缺失,需要把内存块从主存中加载到cache中
2、程序局部性,如果操作的数据在同一个cache line中,那么整体性能就好
2、伪共享,由于同处于一个cache line,某个操作只影响了cache line中的某个字节,但是导致cache line失效,就会影响cache line中操作其他字节的线程。
MESI协议
cache与主存的同步策略主要有两种:写回(write back)和写直达(write through)。
写回:cache不会立即将修改同步到主存,而是再被换出时,才会覆盖主存中过时的数据;写直达:cache的修改会立即同步到主存中。
当某个CPU执行写操作时,其他CPU的cache对于保存该数据副本的更新策略有两种:写更新(write update)和写无效(write invalid)
写更新:每次CPU写cache时,都会发起一次总线操作,通知其他CPU更新该数据位置上的值;写无效:每次CPU写cache时,会使得其他CPU上该数据位置上的值无效
缓存一致性
值每个CPU在L1级上的副本是相同的,现在处理器中通过MESI协议来保证缓存一致性
内存屏障
有了MESI协议之后为什么还需要内存屏障:
1、编译器、CPU为了提高执行效率,会对指令乱序执行
2、严格执行MESI协议会进行核间通信和同步,这会给CPU带来性能问题,所以CPU设计人员对每个核的cache增加了store buffer和invalid queue。其中store buffer用来buf cache的写操作,然后批量刷到cache中,再通过MESI协议核间同步,invalid queue是为了buf核间同步传递过来的invalid信息
所以,即使没有1,2也会导致各个CPU间cache更新顺序的不确定,导致多线程执行顺序的不确定
为了兼顾CPU的性能和程序的正确性,开发人员可以用内存屏障来自己保证,内存屏障可以解决上述两个问题。
NUMA
非一致性访存,在多核处理器中,CPU对于不同区域的内存访问速度是不同的,内存从物理上划分为多个节点,CPU也根据内存节点划分为多个组,每个组中都有一个内存控制器用来访问本地内存,CPU访问内存的效率是相同的。各个节点的CPU之间点对点互联,如果CPU想访问其他节点的内存,需要先通过快速互联通过QPI到达节点的内存控制器,再通过内存控制器访问内存。
物理内存管理
物理内存在操作系统中以页为单位进行管理,每页默认为4K,操作系统向内存管理器申请内存,有以下集中:
1、占用一整页,或者直接和虚拟内存空间建立映射管理,比如匿名页
2、分配小块内存,桶slab allocator技术,Linux会先申请一页的内存,然后根据slab大小划分为同等大小的小块,这些小块通过复杂的队列来管理(被分配、被放回池子、应该被回收)。
那么页又是通过什么管理的呢?伙伴系统
把所有的空闲页分为11个页块链表,每个页块链表包含多个大小的页块,有1、2、4、8、16、32、64、128、256、512和1024个地址上连续的页。