为什么需要RNN(循环神经网络)
将神经网络模型训练好之后,在输入层给定一个x,通过网络之后就能够在输出层得到特定的y,那么既然有了这么强大的模型,为什么还需要RNN(循环神经网络)呢?他们都只能单独的取处理一个个的输入,前一个输入和后一个输入是完全没有关系的。但是,某些任务需要能够更好的处理序列的信息,即前面的输入和后面的输入是有关系的。
例如,你要预测句子的下一个单词是什么,一般需要用到前面的单词,因为一个句子中前后单词并不是独立的;当我们处理视频的时候,我们也不能只单独的去分析每一帧,而要分析这些帧连接起来的整个序列。
一个句子中,前一个单词其实对于当前单词的词性预测是有很大影响的,比如预测苹果的时候,由于前面的吃是一个动词,那么很显然苹果作为名词的概率就会远大于动词的概率,因为动词后面接名词很常见,而动词后面接动词很少见。
所以为了解决一些这样类似的问题,能够更好的处理序列的信息,RNN就诞生了。
RNN的结构
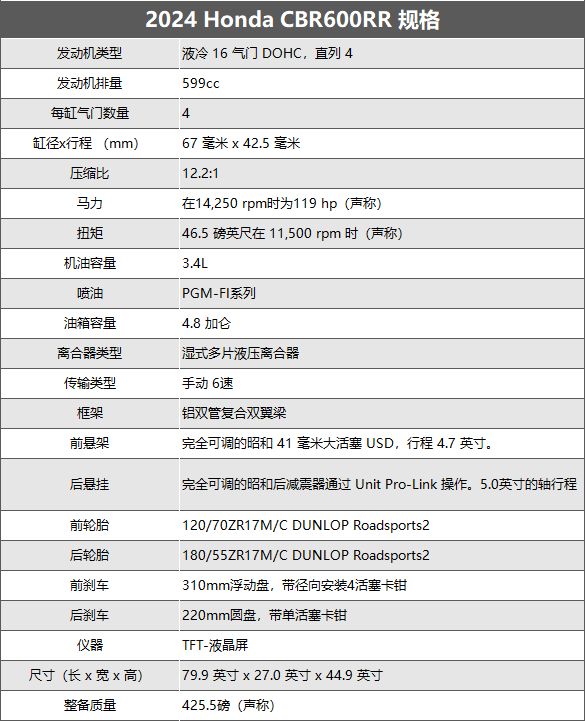
一个简单的循环神经网络如图所示,它由输入层、一个隐藏层和一个输出层组成:
如果把上面有W的那个带箭头的圈去掉,它就变成了最普通的全连接神经网络。x是一个向量,它表示输入层的值(这里面没有画出来表示神经元节点的圆圈);s是一个向量,它表示隐藏层的值(这里隐藏层面画了一个节点,你也可以想象这一层其实是多个节点,节点数与向量s的维度相同);
U是输入层到隐藏层的权重矩阵,o也是一个向量,它表示输出层的值;V是隐藏层到输出层的权重矩阵。
那么,现在我们来看看W是什么。循环神经网络的隐藏层的值s不仅仅取决于当前这次的输入x,还取决于上一次隐藏层的值s。权重矩阵 W就是隐藏层上一次的值作为这一次的输入的权重。
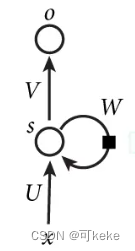
如果我们把上面的图展开,循环神经网络也可以画成下面这个样子:
更细致到向量级的连接图:

现在看上去就比较清楚了,这个网络在t时刻接收到输入
X
t
X_t
Xt之后,隐藏层的值是
S
t
S_t
St,输出值是
o
t
o_t
ot。关键一点是,
S
t
S_t
St的值不仅仅取决于
X
t
X_t
Xt,还取决于
S
t
−
1
S_{t-1}
St−1 。我们可以用下面的公式来表示循环神经网络的计算方法:(为了简单说明问题,偏置都没有包含在公式里面):
O
t
=
g
(
V
⋅
S
t
)
S
t
=
f
(
U
⋅
X
t
+
W
⋅
S
t
−
1
)
O_t = g(V \cdot S_t) \\ S_t = f(U \cdot X_t+W \cdot S_{t-1})
Ot=g(V⋅St)St=f(U⋅Xt+W⋅St−1)
总结来说网络会对前面的信息进行记忆并应用于当前输出的计算中,即隐藏层之间的节点不再无连接而是有连接的,并且隐藏层的输入不仅包括输入层的输出还包括上一时刻隐藏层的输出。理论上,RNN能够对任何长度的序列数据进行处理。但是在实践中,为了降低复杂性往往假设当前的状态只与前面的几个状态相关。
训练算法
RNN 的训练算法为:BPTT
BPTT 的基本原理和 BP(反向传播算法) 算法是一样的,同样是三步:
-
- 前向计算每个神经元的输出值;
-
- 反向计算每个神经元的误差项值,它是误差函数E对神经元j的加权输入的偏导数;
-
- 计算每个权重的梯度。
最后再用随机梯度下降算法更新权重。
BPTT(back-propagation through time)算法是常用的训练RNN的方法,其实本质还是BP算法,只不过RNN处理时间序列数据,所以要基于时间反向传播,故叫随时间反向传播。BPTT的中心思想和BP算法相同,沿着需要优化的参数的负梯度方向不断寻找更优的点直至收敛。
参考:
不会停的蜗牛 https://www.jianshu.com/p/39a99c88a565
https://zhuanlan.zhihu.com/p/30844905
更细致全面的说明可以参考:
https://blog.csdn.net/bestrivern/article/details/90723524