“隐语”是开源的可信隐私计算框架,内置 MPC、TEE、同态等多种密态计算虚拟设备供灵活选择,提供丰富的联邦学习算法和差分隐私机制
开源项目
github.com/secretflow
gitee.com/secretflow

11月25日,「隐语开源社区 Meetup·西安站」顺利举办,本文根据蚂蚁集团隐私计算技术专家、隐语开源 TEE Maintainer 周爱辉在「隐语开源社区 Meetup · 西安站」分享整理。
👉 戳我查看现场视频:直播视频
本次活动更多分享实录可点击这里查看。
感谢杨主任给我们介绍了数字广告数据要素流通中遇到的挑战及提出了一个可行的解决方案,其中他提到了可信执行环境和数据跨域管控。刚好,我接着杨主任的分享,介绍隐语在 TEE 方面做的一些实现,与大家分享《隐语 TEE 技术解读与跨越管控实践》。
我叫周爱辉,目前就职于蚂蚁集团,也是 SecretFlow 开源 Maintainer。今天我的演讲分三个部分:
- 简单介绍可信执行环境
- 隐语在可信执行环境的工作
- 未来规划
可信执行环境简介
可信执行环境的核心概念
可信执行环境英文是 TEE,是 Trusted Execution Environment 的缩写。怎么理解呢?我用了一句话尝试解释它:TEE 是计算系统中运行在隔离环境的一块区域。这里最关键的字就是隔离环境,隔离环境是什么意思?可以简单理解为:在隔离环境里面,计算系统的其他区域,例如其他应用、操作系统,甚至虚拟机管理程序,都没有办法去访问这块区域。
可信执行环境可以保护你的代码和数据,以及运行时状态的机密性和完整性。机密性和完整性怎么理解呢?这里举个例子,以 Intel SGX 为例,简单介绍一下它的原理,方便大家有一个更深的认知。Intel SGX 是一个非常有名的 TEE 实现,可以看下图:
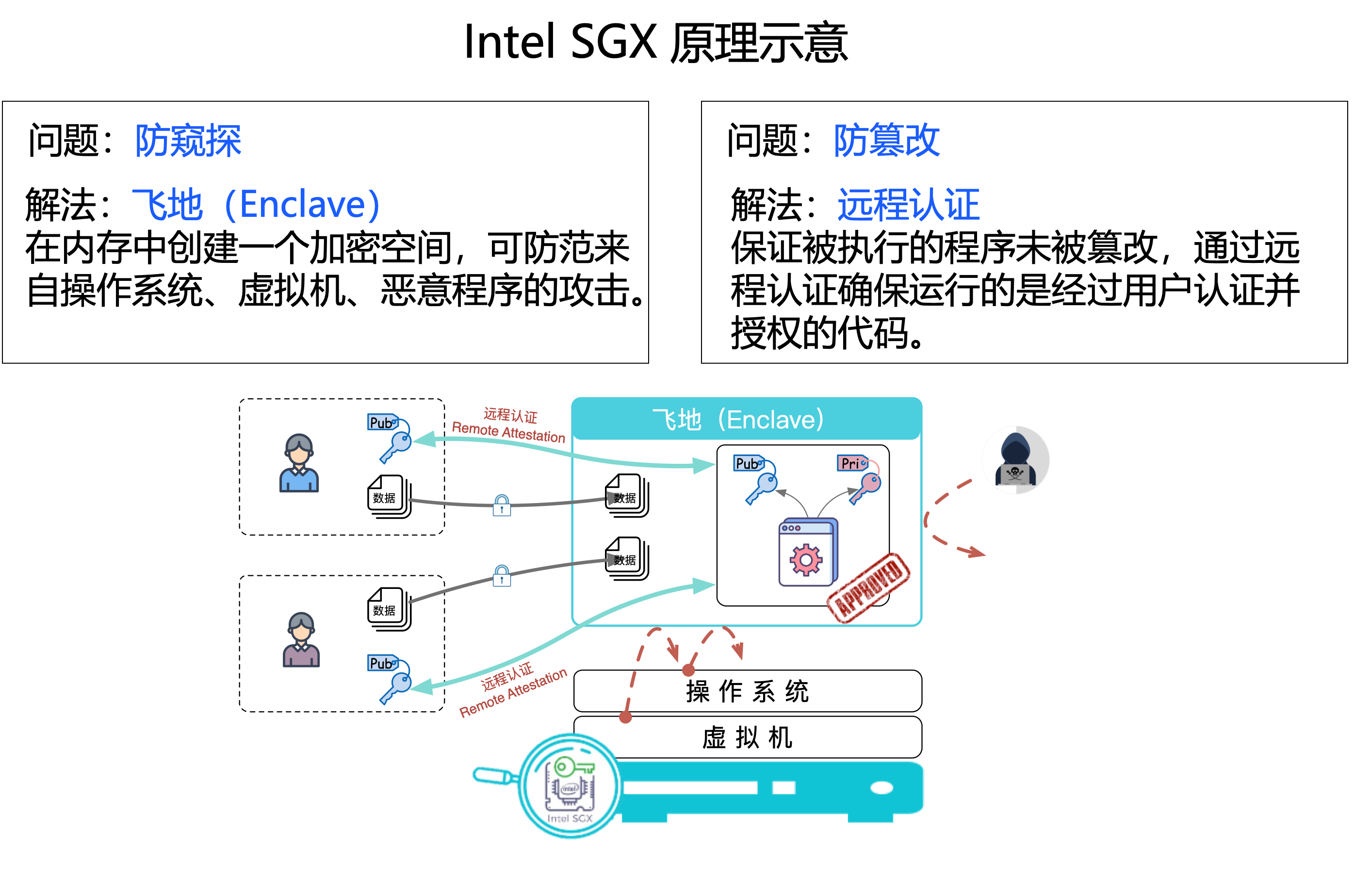
SGX 有一个非常核心的概念叫飞地(Enclave),它解决的问题:
- 第一个是防窥探。Enclave 可以理解为对应前面讲的隔离环境,在这个隔离环境里创建了一块隔离的区域。跑在 Enclave 里的代码和数据,其他的应用程序、操作系统,包括虚拟机管理程序都拿不到。
- 另一个很重要的机制是远程认证。远程认证要解决的问题是防篡改。你的代码、数据跑在 Enclave 中,可以通过远程认证机制确定跑的代码一定是你看过的那个代码,假如这个代码不符合你的预期,你可以检测得到的,从而防止被篡改。
以上就是 TEE 的主要核心概念。
工业级 TEE 的发展
我简单列了目前一些工业级的 TEE,不是全部的。
- 比较早的工业级TEE是ARM 在 2004 年推出来的 TrustZone。
- 后面有很长一段时间的空窗期,直到 2015 年的时候推出 Intel 推出了 SGX。
- 再到 2017 年 AMD 推出 SEV 的 TEE,这里加了一个标注,把它叫做 VM TEE,VM 就是虚拟机的英文,它跟之前 SGX 的思维有些不一样。之前的 SGX 是指把进程的一部分跑在隔离环境里面,这种用法的问题是:把整个应用放进去跑会比较困难,就可能要对应用做一个切分,有些放进去,有些不放进去。从 AMD SEV 后大家就换了一个思路,大家把它做成一个可信的机密虚拟机,在虚拟机里面跑任何代码、任何应用,迁移应用的成本顿时变得很低。这一条技术路线后面也得到了很多厂商的认可。

- 到 2020 年海光推出了 CSV,CSV 跟 AMD SEV 其实是同一个技术架构,它们都是基于 AMD Zen实现的。
- 同时 2020 年蚂蚁推出了 HyperEnclave,是蚂蚁隐私计算部门团队自主研发的。
- 到 2021 年 ARM 推出一个叫 CCA TEE 的技术,CCA 也是属于 VM TEE路线。
- 到 2022 年 Intel 推出了 TDX,也是 VM TEE路线。
- 今年也就是 2023 年华为推出了 virtCCA,它也是在 ARM TrustZone 的基础上研发的,其实跟 ARM 的 CCA 是对标的技术。
这是我们目前看到的一些工业级的 TEE 实现。
可信执行环境可以做哪些事情
前天的全球数字贸易博览会上,国家数据局党组书记、局长刘烈宏提出来一个概念:数据基础设施。数据基础设施包含一体化的数据汇聚、处理、流通,应用、运营、安全保障等。其中他也指出隐私计算是数据基础设施的一个非常重要的技术,TEE 作为隐私计算一条重要的技术路线,可以说它是数据基础设施的一个重要组成部分。
隐语在 TEE 上的实现:SecretPad x TrustedFlow
下面,分享一下隐语在 TEE 这方面做了什么实现。
使用 TEE 就意味着安全吗?
先分享一下隐语为什么要做 TEE解决方案。首先要澄清一个事情:不是把应用直接跑在 TEE 里面就安全了。很多人在刚接触 TEE 的时候可能都会有这个误解。
前面介绍了 TEE,好像提供了一个非常强有力的武器,把你的代码数据放进去跑,好像别人就偷不走了。其实不是这样的,实际上会出现一些问题,比如:最基础的系统安全,应用跑在 TEE 可能会有通信、存储,这些系统安全是否能做好本身就是基础。在这个基础之上,把数据放在 TEE 里面跑,计算时会涉及到对数据做加工和使用,这些行为是否做了足够的管控。如果没有做好,其实依然会发生数据泄露、数据滥用等问题。这些问题就涉及到了另一个概念:数据使用权的跨域管控。

数据使用权跨域管控
在介绍数据使用权跨域管控前,先简单说一下数据三权的概念。《数据二十条》里提出数据三权分置的思想。数据三权就是:
- 数据资源特有权:指谁持有这份数据
- 数据加工使用权:指谁在什么场景下对这个数据做什么操作
- 数据产品经营权:指谁能够把这个数据的什么权利授权给谁,并获得收益。数据最终一定要通过其本身获得收益才能促进数据的流转,大家才有这个动力去做这个事情。

数据三权之间是可以互相流转的。《数据二十条》中提出来数据三权分置,主要是为了解决数据要素流通过程中数据产权的问题。
我们再分享一下数据流通过程中会遇到的一些问题。举个例子,比如机构 1 有数据 A,他可以通过合同约定的方式把他的经营权授权给另外一个机构 2,机构 2 拿到这个数据后可以对它做加工使用。大家可以看到随着数据的流通就伴随着数据三权的诞生和流转。但是,在这个过程中如果没有对它做严格的限制,只靠合同去约定,就可能会发生数据泄露和数据滥用的风险。
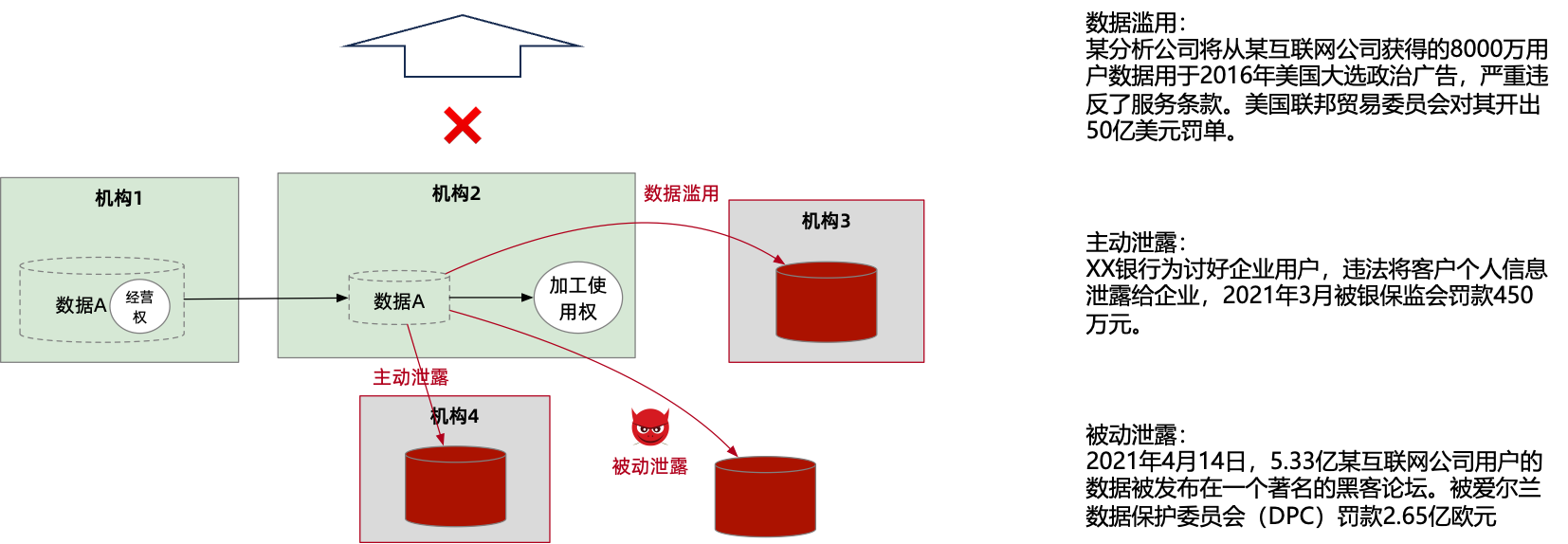
上图右侧举了一些例子,都是可以在互联网上查询得到。所以我们需要对数据使用行为进行管控,也就是刚才提到的数据使用权跨域管控的概念。
通过数据使用权跨域管控才能保障数据三权的权益。这里我们给了数据使用权跨域管控的定义:数据使用权跨域管控是指数据持有者在数据离开其运维管控域后,依然能够决策这个数据怎么用。
我们回到之前讲到的 TEE,机构 1 把数据 A 给到机构 2,让它在 TEE 里面跑,是不是也就是安全的了呢。如果只是直接这么跑在 TEE 上,也不能保证安全。因为机构 2 怎么用这个加密数据,跑的什么代码,做的什么事,如果没有一套机制去约束它、去管控它,那它依然会发生数据泄露、数据滥用这件事情。所以,即使我们把计算跑在 TEE 里,也依然需要做好数据使用权的跨域管控。

到此,我们就回答了隐语 TEE 为什么要做。我们可以一起看一下现有的一些 TEE 解决方案。像国外比较有名的 scone,也是基于 TEE 做解决方案的,还有 UC 伯克利出身的创业公司 opaque,还有国内的一些公司。但是他们是商业化的,也就是纯闭源的,闭源意味着我们无法对它的实现进行检查,也就是它到底安不安全这件事情我们是无法去确认的。也有一些开源的方案,比如 Intel 的开源解决方案BigDL PPML,可以在上面跑一些机器学习的应用,但是它没有白屏化界面。有过 TEE 使用经验的同学就发现如果没有白屏化界面,用起来还是很难的,上手难度较高。另一方面,我们发现如果去探究这些已有开源解决方案的使用权管控细节是缺失的,当我们去细究它时会发现它是不完善的。
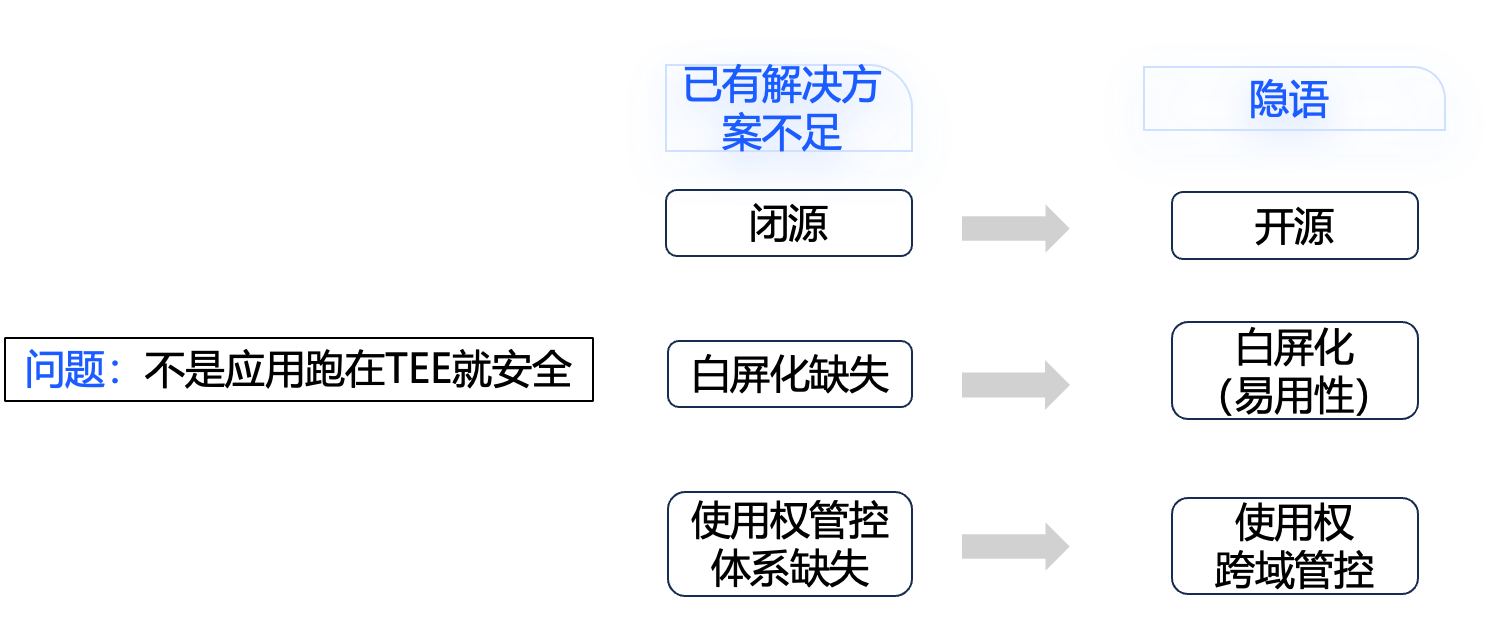
基于前面讲的这些不足,隐语要解决哪些问题?
- 首先,隐语是开源的,大家可以去 GitHub 上检查代码实现到底是否安全,是否有问题。
- 第二,会提供白屏化的产品,让大家变得更易用。
- 第三,会在使用权跨域这方面做的比较完善。
隐语 TEE 解决方案
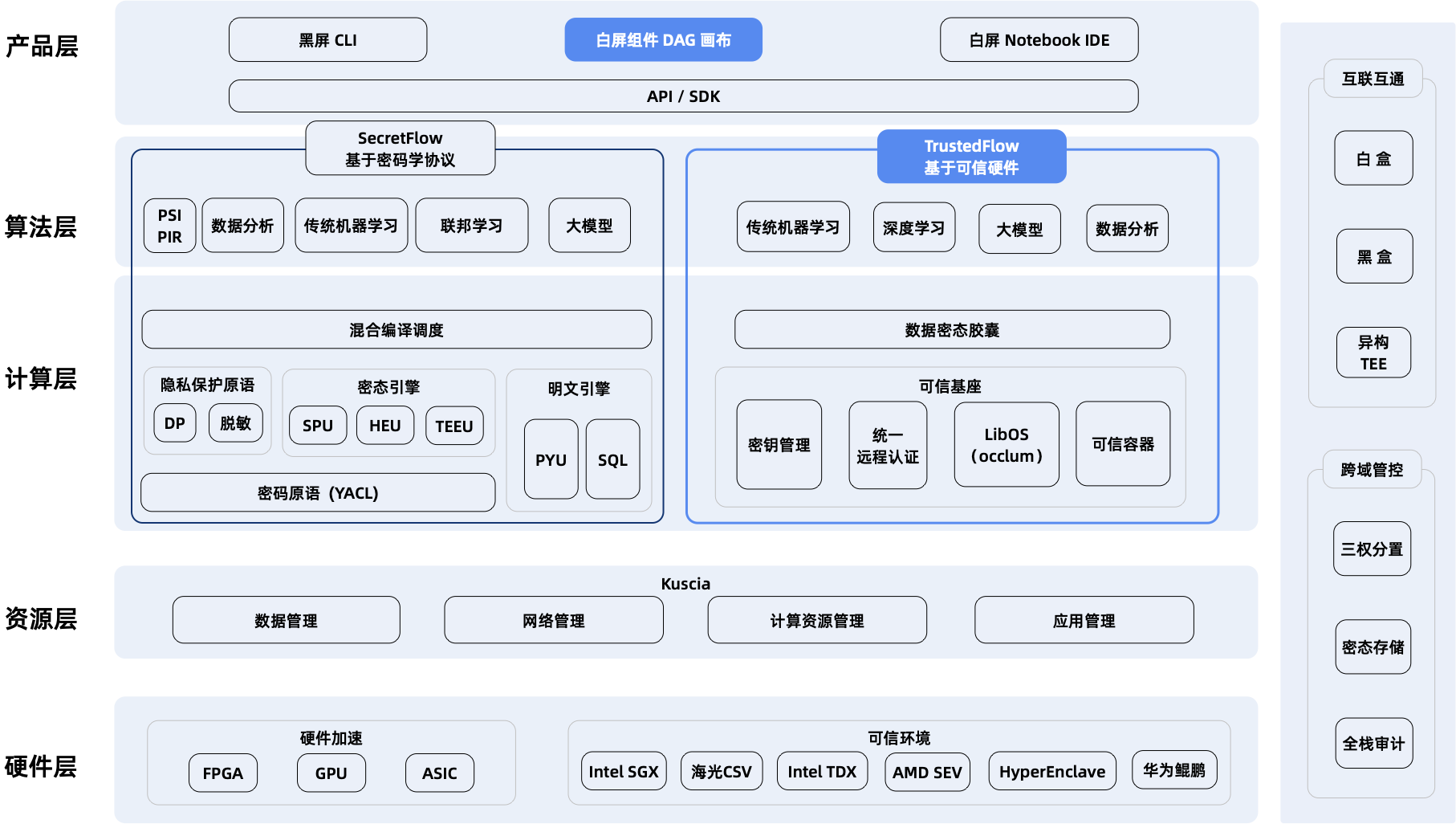
接下来,就分享一下隐语 TEE 的解决方案。这个是隐语的架构图,相比现在官网稍微有点更新。我们主要做了两块:
- 第一部分在产品层:隐语白屏化产品 SecretPad。
- 第二部分是 TEE 可信硬件,在算法层和计算层。也就是用蓝框标起来的部分是 TEE可信硬件 TrustedFlow。我们把基于密码学的部分,例如 MPC、联邦、同态等叫做 SecretFlow,另一块就是基于可信硬件的计算引擎TrustedFlow。
先简单介绍一下 TEE 的白屏化产品,其实就在 SecretPad 上。SecretPad 不仅仅支持 TEE,也支持 SecretFlow 本身的很多功能。下图的流程图是 SecretPad 的使用流程,有两个关键概念:
- 第一是数据一定要通过授权后才能被别人使用。
- 另一个核心点是计算出来的结果一定是要所有的数据持有者审批后才能拿到。
SecretPad:隐语 SecretFlow
在后面分享引擎部分的时候,我们再聊这两个原理。

后面重点介绍隐语 TEE 的计算引擎 TrustedFlow,这个也开源了,可以访问下方链接进行查看:
TrustedFlow:隐语 SecretFlow
下图是 TrustedFlow 的架构图,主要包括两个核心板块:
- 数据使用权的跨域管控
- 系统安全加固

接下来,展开讲一下数据使用权跨域管控。
首先,数据使用权跨域管控管的数据载体是什么,我们给它起名为数据密态胶囊。数据密态胶囊就是跨域管控数据的载体,它包含了:
- 数据密文:数据一定是被加密的,加密密钥是数据持有者生成的
- 数据所有者证明:通过数据密态胶囊能确定这个数据到底是属于谁的
- 数据授权策略:该数据能够被用来做什么事情
这三个概念组装在一起就是数据密态胶囊。有了跨域管控的数据载体之后,我们看一下可以对它做怎样的管控。
计算中管控
首先是计算中管控,对应下图标蓝色的位置。通过使用鉴权的方式来确保数据加工使用是符合预期的。有一个很直观的解法:在做计算前要求数据持有者每次都来审批,但是这个方案是可行的吗?落地时会发现不太可行,这样的操作太烦琐,对于用户的打扰太大了。我们提供的做法是在数据密态胶囊里放置了数据授权策略,然后可以通过预设策略进行检查,若符合策略则进行计算,若不符合就拒绝。

下图描述了使用鉴权的流程。

跟大家分享该流程的几个要点,我们主要在哪些环节设置了卡点:
- 首先不是谁都可以进行计算的,需要得到数据持有者的授权。
- 数据密钥是被管控的,如果要进行计算,则密钥一定是在符合数据持有者设定的策略下才能访问。比如数据持有者仅授权使用该数据进行逻辑回归,但是如果想要对它进行深度学习,那系统会直接拒绝进行计算。
- 最后,这一整套检查机制都是基于 TEE 来设计的,通过TEE来保证无法绕开这套机制。
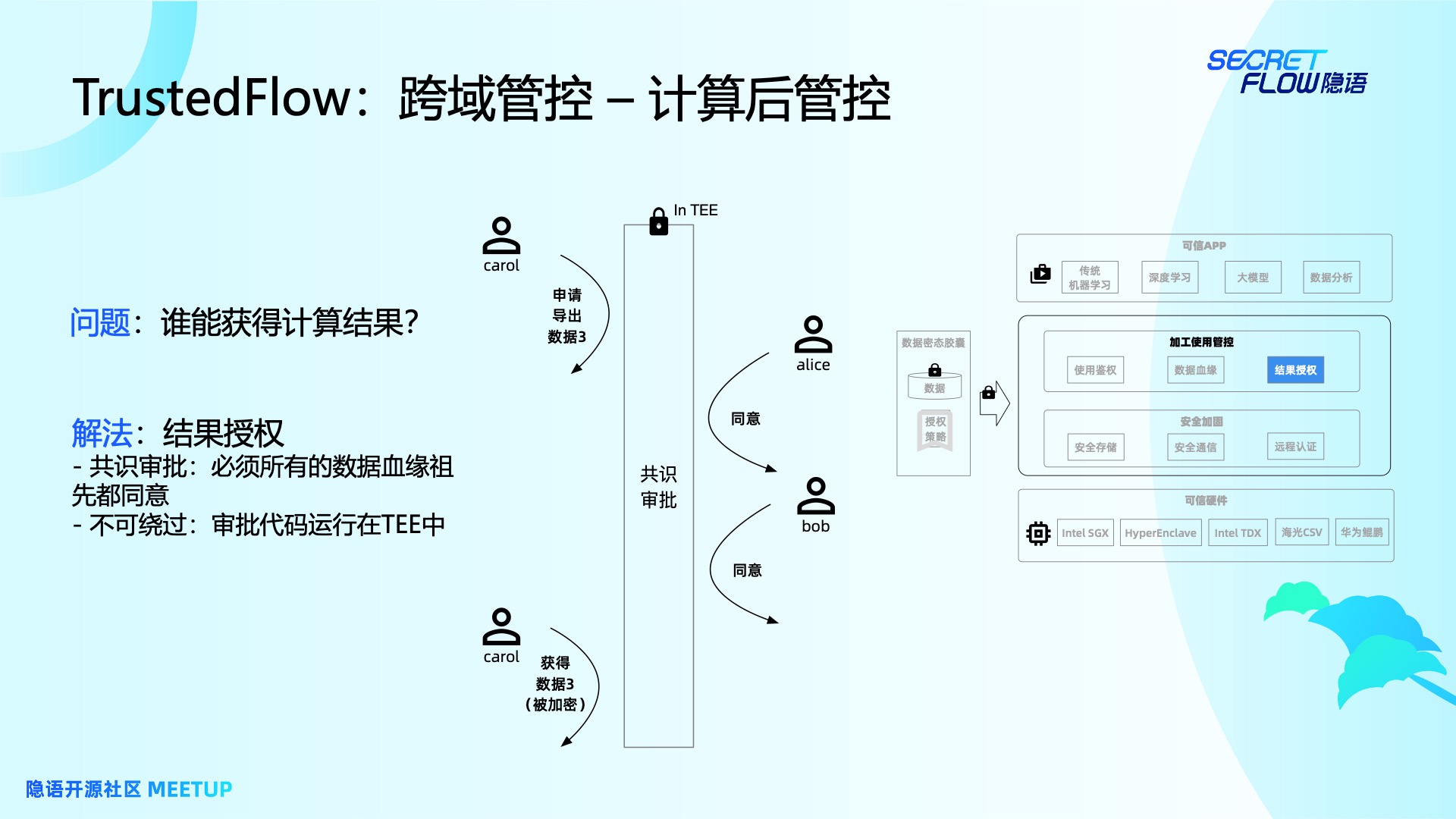
计算后管控
做完了计算中的管控,我们来讲一下计算后管控。计算后管控会有两个问题,第一个问题是要怎么保证计算结果的正确性?例如有两个机构想要做联合查询,跑了一个 SQL 语句拿到了一个结果。但是系统返回的可能不是这个 SQL 语句的结果,它有可能是欺骗我们的,我们怎么确认这件事情,这个是很重要的。

我们设计了一套数据血缘机制,中间蓝色的图是他的大概原理。比如 Alice 的数据 1 与 Bob 的数据 2 通过了一个代码计算得到了数据 3,那么这个数据 3 就会在它的数据meta中记录他的祖先是数据 1 和数据 2,同时会记录它经过的计算代码是代码 A,且整个记录是由 TEE 模块进行签名的,保证它的完整性,无法对它进行篡改。通过数据血缘就可以找到这个数据到底是用什么数据经过了什么计算的来的。
在跨域管控中,计算后的下一步就是谁能拿到这个结果呢?现在的设计方式是一定要通过共识审批。接刚刚的例子,Carol 想要申请导出刚刚计算得到的数据 3。我们可以通过上一页介绍的数据血缘,找到它的数据祖先是 Alice 和 Bob,由他们的数据进行计算得到的。在我们的系统中,一定要经过 Alice 和 Bob 签名同意,这个数据才会发出来给 Carol。该过程的两个要点是:
- 一定要控制审批,需要流程中所有的人都同意。
- 这套审批机制也是跑在 TEE 中的,所以绕不开这套管控机制。
再稍微提一下系统安全加固,其主要对存储和通信做了安全。这个和常规的安全有一点差别,
- 安全存储的密钥是存储在 TEE 中的,用户是拿不到的,所以安全性会更高。
- 在安全通信中,应用跟应用之间或者用户与 TruestedFlow 交互的通信链路之间都会先做远程认证,确保代码一定是符合预期的情况下才会进行通信。
这是和正常的加密通信、加密存储的主要差别。

总结
最后,做一个简单的总结。前面最开始我们提出了问题:不是应用直接跑在 TEE 上就是安全的,我们要关注加工使用安全、系统安全,需要做好使用权跨域管控来解决这个问题,包括其包含的数据密态胶囊、加工使用管控、系统安全加固等。最后达到的效果是用户只需要专注于将 APP 迁移到 TEE 上,或者自己开发自己的 APP。
隐语也提供了一些开箱即用的 APP,蓝色点亮的板块就是已经开源的部分。现在也内置了一些传统机器学习,例如逻辑回归、XGBoost建模。

未来规划
最后简单介绍一下后续的规划。
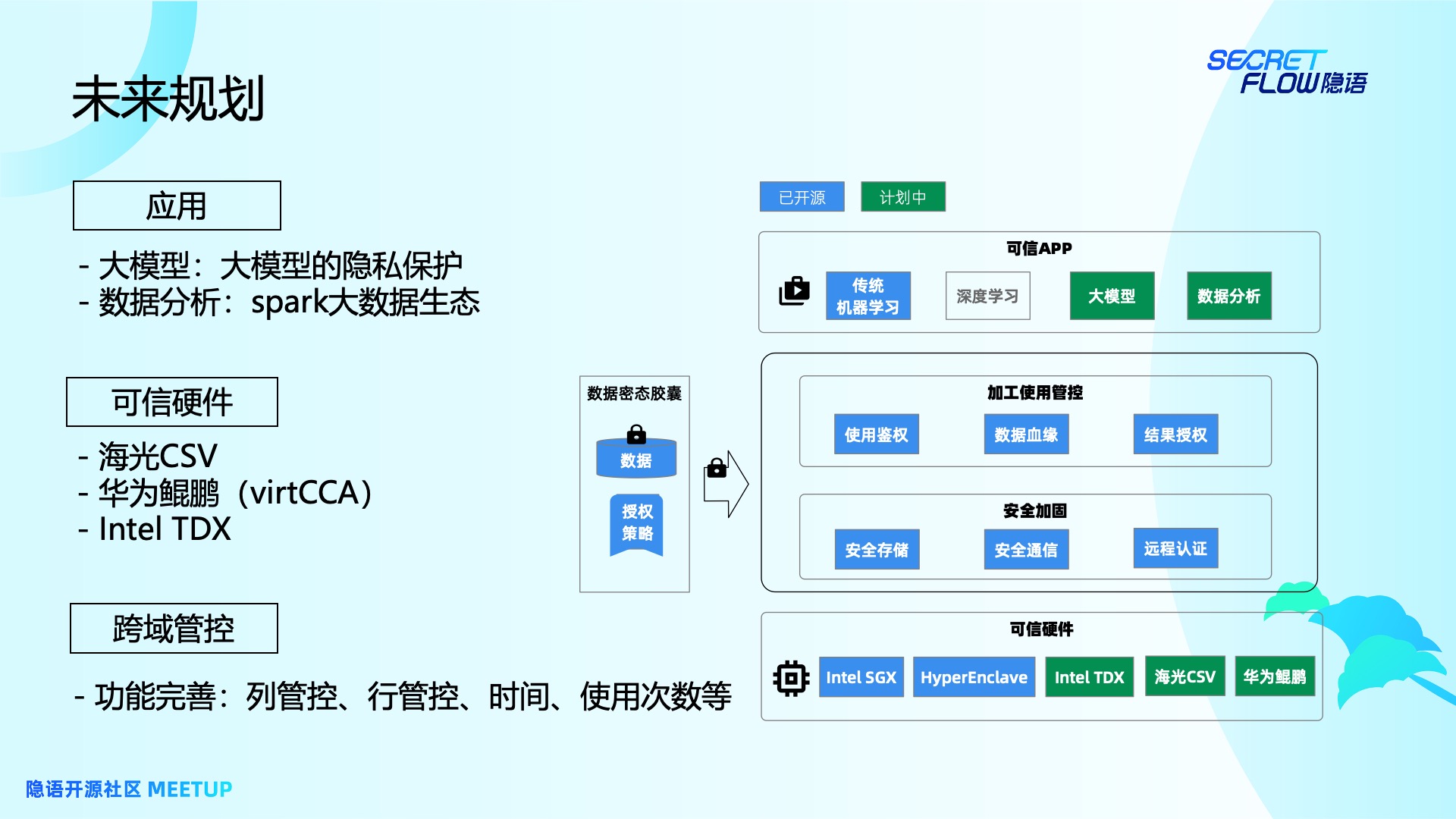
在应用层面上,目前TrustedFlow已经打好了基础,我们会提供更多开箱即用的应用。除了已经开源的传统机器学习之外,绿色板块就是在我们计划中的。在可信应用方面会计划做大模型的隐私保护。同时,我们也正在做 Spark 大数据生态。
在可信硬件上,我们已经支持 Intel SGX 以及蚂蚁开源的 HyperEnclave,现在正在集成的包括 英特尔 TDX、海光 CSV 以及华为鲲鹏(virtCCA)。
在跨域管控上,也会对其功能进行完善。例如列管控,隐语有一个比较创新的技术叫 CCL,可以对列做一些管控,减轻大家使用 SCQL 的负担。我们希望这个技术不仅使用在SCQL 上,它其实可以作为一个更通用的数据分析利器。另外还有行管控,例如用户希望这个计算只能使用数据的某些行,甚至是希望这个计算只能限定在某个时间段内。或者只能使用该数据多少次,例如在使用了两次或者三次后就不能再使用这份数据等。我们会在这些细节上做一些完善。
我今天的分享就到这,谢谢大家!
🌟 关注「隐语Secretflow」B 站, 获取更多演讲回顾及相关资讯
🏠 隐语社区:
github.com/secretflow
gitee.com/secretflow
www.secretflow.org.cn (官网)
👇 欢迎关注:
公众号:隐语小剧场
B站:隐语secretflow
邮箱:secretflow-contact@service.alipay.com