欢迎各位数据爱好者!今天,我很高兴与您分享我的最新博客,专注于探索 PySpark DataFrame 的强大功能。无论您是刚入门的数据分析师,还是寻求深入了解大数据技术的专业人士,这里都有丰富的知识和实用的技巧等着您。让我们一起潜入 PySpark 的世界,解锁数据处理和分析的无限可能!
基础操作
基础操作涵盖了数据的创建、加载、查看、选择、过滤、转换、聚合、排序、合并和导出等基本操作。
1.数据创建和加载
# 读取 CSV 文件
df = spark.read.csv("path/to/file.csv", header=True, inferSchema=True)
# 读取 HIVE 表
hive_sql = f"select * from {DATABASE}.{TABLE_NAME} {CONDITION}"
df = spark.sql(hive_sql)
# 读取 Parquet 文件
parquet_file = "path/to/parquet/file"
df = spark.read.parquet(parquet_file)
2.数据查看和检查
df.show(2,truncate=False)
df.printSchema()
3.查看分位数
quantiles = df.approxQuantile("salary", [0.25, 0.5, 0.75], 0)
# col:要计算分位数的列名,为字符串类型。
# probabilities:一个介于 0 和 1 之间的数字列表,表示要计算的分位数。例如,0.5 表示中位数。
# relativeError:相对误差。这是一个非负浮点数,用于控制计算精度。
# 值为 0 表示计算精确的分位数(可能非常耗时)。
# 随着该值的增加,计算速度会提高,但精度会降低。例如,如果 relativeError 为 0.01,则计算结果与真实分位数的差距在真实分位数的 1% 范围内。
4.数据选择和过滤
df.select("column1").show()
df.filter(df["column1"] > 100).show()
# 或者
df.filter(F.col("column1") > 100).show()
5.数据转换和操作
df.withColumn("new_column", F.col("column1").cast("int"))).show()
df.withColumn("new_column", df["column1"] + F.lit(100)).show()
df.withColumn("new_column", F.col("column1") + F.lit(100)).show()
df.drop("column1").show()
6.数据聚合和分组
df.groupBy("column1").count().show()
df.groupBy("column1")agg.(F.count(F.col("id"))).show()
7.排序和排名取TopN
df.orderBy(df["column1"].desc()).show()
df.orderBy(F.col("column1").desc()).show()
8.数据合并和连接
df1.join(df2, df1["column"] == df2["column"]).show()
# 或者
from functools import reduce
from pyspark.sql import DataFrame
dataframes = [df1,df2,df3]
union_df = reduce(DataFrame.union, dataframes)
9.缺失值和异常值处理
df.na.fill({"column1": 0}).show()
10.数据转换和类型转换
df.withColumn("column_casted", df["column1"].cast("int")).show()
11.数据导出和写入
# 存储 DataFrame 为CSV
df.write.csv("path/to/output.csv")
# 存储 DataFrame 为HIVE
df.write.format("orc").mode("overwrite").saveAsTable(f"test.sample")
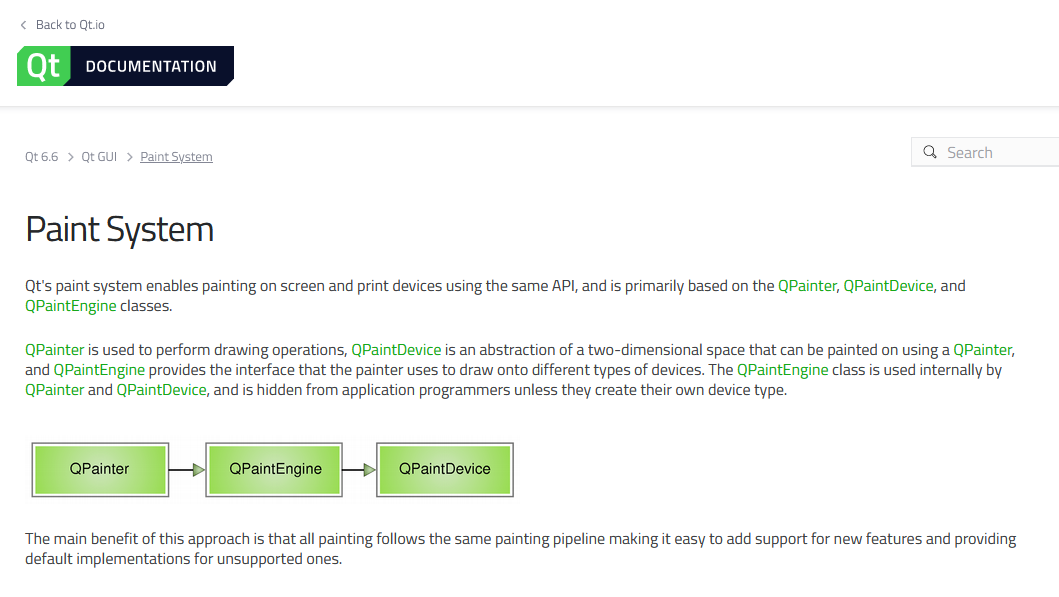
# 存储 DataFrame 为 Parquet 文件
output_path = "path/to/output/directory"
df.write.parquet(output_path)
高级操作
高级操作包括更复杂的数据处理技术、特征工程、文本处理和高级 SQL 查询。
1.数据分区和优化
df.repartition(10).write.parquet("path/to/output")
2.数据探索和分析
df.describe().show()
# 或者
df.summary().show())
3.复杂数据类型处理
from pyspark.sql.functions import explode
df.withColumn("exploded_col", explode(df["array_col"])).show()
4.特征工程
from pyspark.ml.feature import StringIndexer
indexer = StringIndexer(inputCol="category", outputCol="category_index")
df_indexed = indexer.fit(df).transform(df)
5.文本数据处理
from pyspark.ml.feature import Tokenizer
tokenizer = Tokenizer(inputCol="text", outputCol="words")
df_words = tokenizer.transform(df)
6.高级 SQL 查询
df.createOrReplaceTempView("table")
spark.sql("SELECT * FROM table WHERE column1 > 100").show()
进阶操作
进阶操作涵盖了性能调优、与其他数据源的集成和数据流处理,这些通常需要更深入的理解和经验。
1.性能调优和监控
df.explain()
2.与其他数据源集成
df_jdbc = spark.read \
.format("jdbc") \
.option("url", "jdbc:mysql://your-db-url") \
.option("dbtable", "tablename") \
.option("user", "username") \
.option("password", "password") \
.load()
3.数据流处理
df_stream = spark.readStream \
.schema(df_schema) \
.option("maxFilesPerTrigger", 1) \
.json("/path/to/directory/")
4.使用 Structured Streaming
stream_query = df_stream.writeStream \
.outputMode("append") \
.format("console") \
.start()
stream_query.awaitTermination()
这些示例提供了对 PySpark 操作的广泛了解,从基础到进阶,涵盖了数据处理和分析的多个方面。对于更复杂的场景和高级功能,强烈建议查阅 PySpark 的官方文档和相关教程。