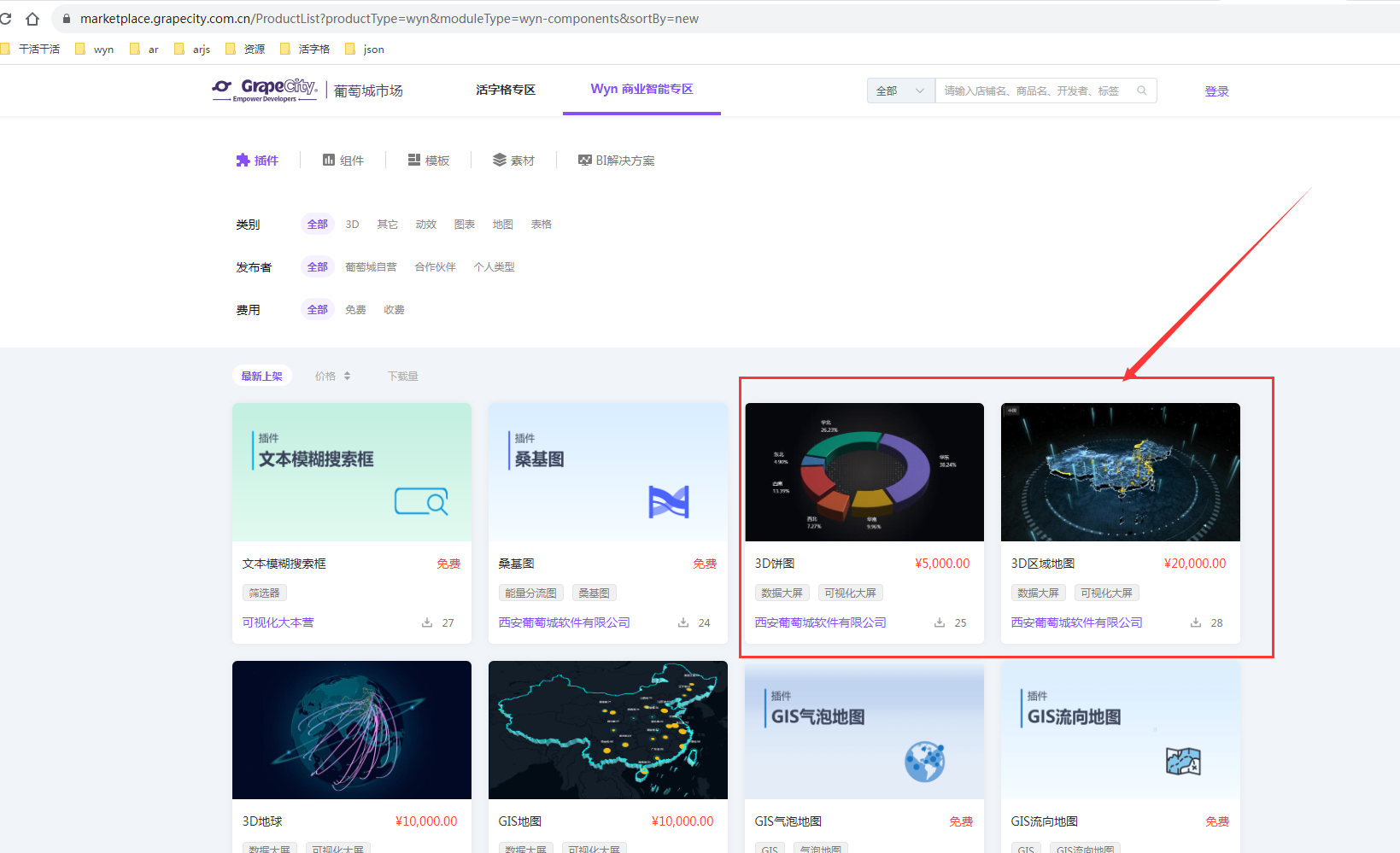
为了增强CLIP在图像理解和编辑方面的能力,上海交通大学、复旦大学、香港中文大学、上海人工智能实验室、澳门大学以及MThreads Inc.等知名机构共同合作推出了Alpha-CLIP。这一创新性的突破旨在克服CLIP的局限性,通过赋予其识别特定区域(由点、笔画或掩码定义)的能力。Alpha-CLIP不仅保留了CLIP的视觉识别能力,而且实现了对图像内容强调的精确控制,使其在各种下游任务中表现出色。

Alpha-CLIP在精确的图像理解和编辑方面取得了显著的进展,能够在不改变图像内容的情况下识别特定区域。引入alpha通道的概念,该通道保留了上下文信息,使得Alpha-CLIP相对于其他区域感知方法更具优势,提高了图像识别的能力。
在注入区域感知到CLIP的过程中,论文探索了多种策略,如MaskCLIP、SAN、MaskAdaptedCLIP以及MaskQCLIP等,这些策略为Alpha-CLIP的发展做出了贡献。ReCLIP和OvarNet通过裁剪或遮罩改变输入图像,提供了独特的视角。Red-Circle和FGVP通过巧妙地使用圆圈或掩模轮廓引导CLIP的注意力。然而,这些方法有时会过于依赖CLIP的预训练数据集,可能引入潜在的域差异。
Alpha-CLIP的独特之处在于引入了额外的alpha通道,使其能够在不改变图像内容的情况下专注于指定区域。这一创新性的特征不仅保留了模型的泛化性能,还增强了模型的区域聚焦能力。这些特性的整合使得Alpha-CLIP在多个任务中表现卓越,包括图像识别、多模态语言模型以及2D/3D生成。
alpha通道的引入确保了上下文信息的完整性,数据预处理涉及创建rgba区域文本对,这是训练模型所必需的细致过程。论文还深入研究了分类数据对区域文本理解的深远影响,并比较了单独使用基础数据预训练的模型与使用分类和基础数据联合训练的模型。消融研究进一步检验了数据量对模型稳健性的影响。在零样本实验中,Alpha-CLIP取代了CLIP,取得了在区域文本理解方面具有竞争力的结果。
Alpha-CLIP通过集中注意力于涉及点、掩码的任务,不仅优于仅基于有监督的预训练,而且将区域感知能力推向了新的高度。但是有监督的训练仍然是必要的,因为像ImageNet这样的大规模分类数据集对于Alpha-CLIP的卓越性能做出了重要贡献。
论文地址:Alpha-CLIP: A CLIP Model Focusing on Wherever You Want
https://avoid.overfit.cn/post/c9ff16d4e2c4443c9ebf44363dfc50ab