文章目录
前言
一、运行环境
二、环境配置
三、yolov5网络结构图介绍
四、 损失函数
五、数据集
六、实验内容
1.实验框架
2.实验环境
3.实验结果
前言
佩戴口罩可以有效降低在和感染者有接触时可能被感染者感染的风险。目前,在一些公共场所,比如商场、超市、车站等地方的疫情防控主要依靠人工管理和监督。这样不仅管理效率低下而且造成大量的人力资源的浪费。可以在商场、超市等出入口安装人脸口罩自动检测系统来协助管理,这样可以大大提高效率,避免资源浪费,因此基于深度学习的人脸口罩检测项目的研究就有重要的研究意义。
运行环境
1.解释器:Python 3.8 版本, anconda4
2.开发环境: Pycharm
3.开发框架:pytorch
环境配置
1.anconda Python 解释器的配置
①win+r , 输入cmd,
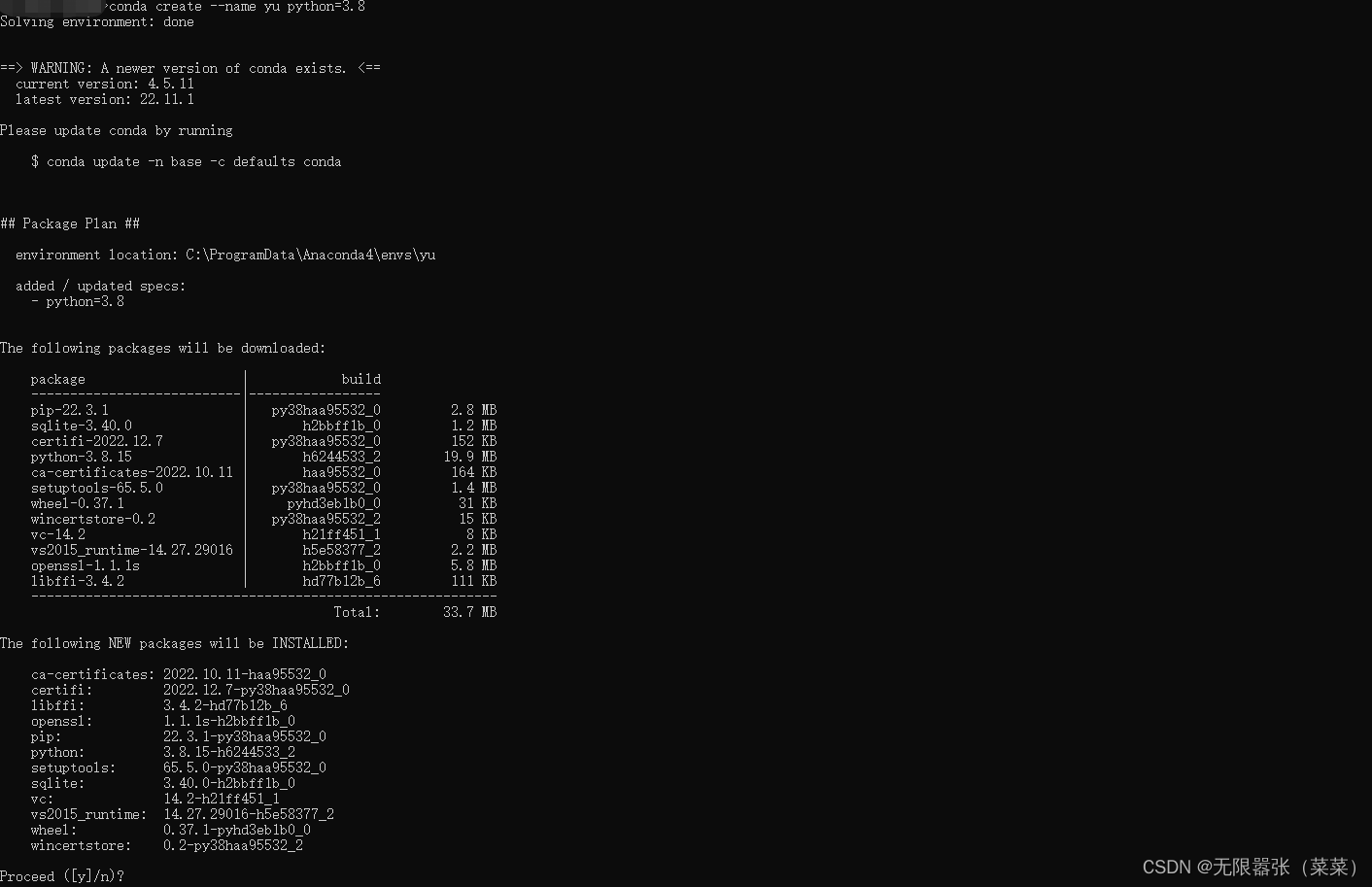
②输入conda create --name yu python=3.8,yu就是我们安装过程的一个名字,后边我们也要找这个名字,自己定义就好,并且在安装途中,问yes or no 我们都选 yes,安装过程如下图:
③点文件+设置+项目+Python解释器
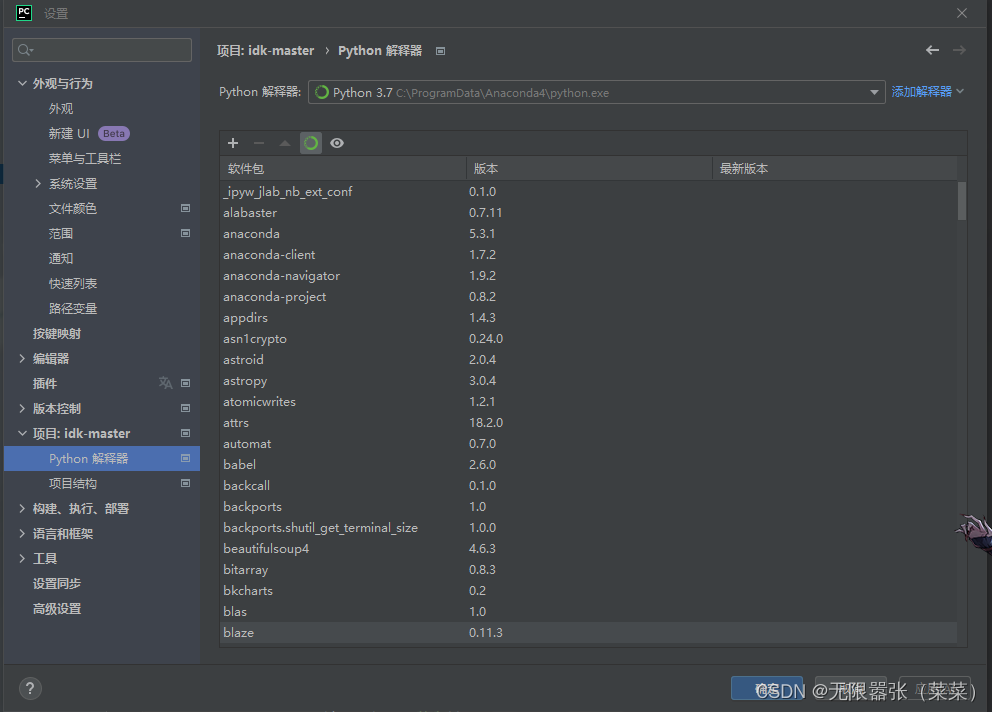 ④点击添加解释器
④点击添加解释器
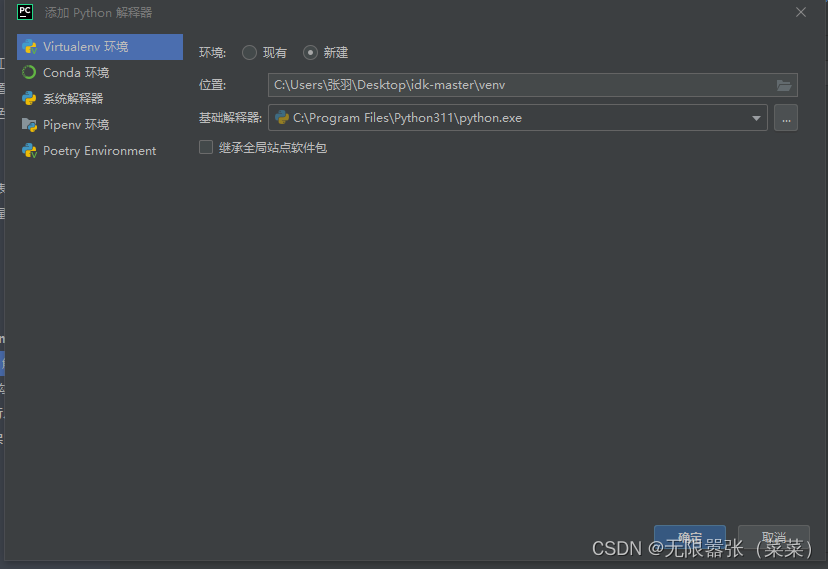
⑤找到anconda 安装位置,并且找到Python 解释器的位置
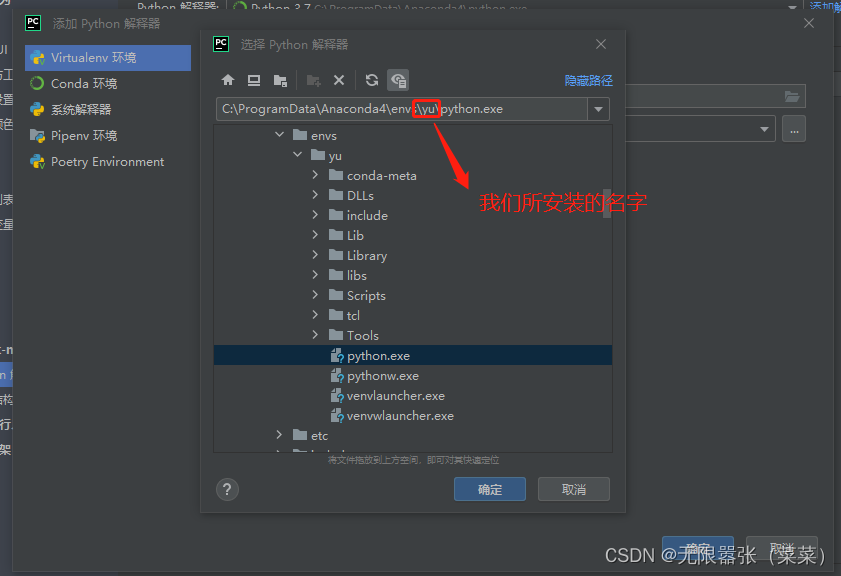
⑥ 以管理员身份运行anconda,来激活虚拟环境,找到anconda Prompt,以管理员身份运行,conda activate yu是用来激活虚拟环境,并且利用 pip install pyqt5 来安装 pyqts这个包,接下来稍等片刻。

⑦ 如果出现如下界面,表示已经安装成功
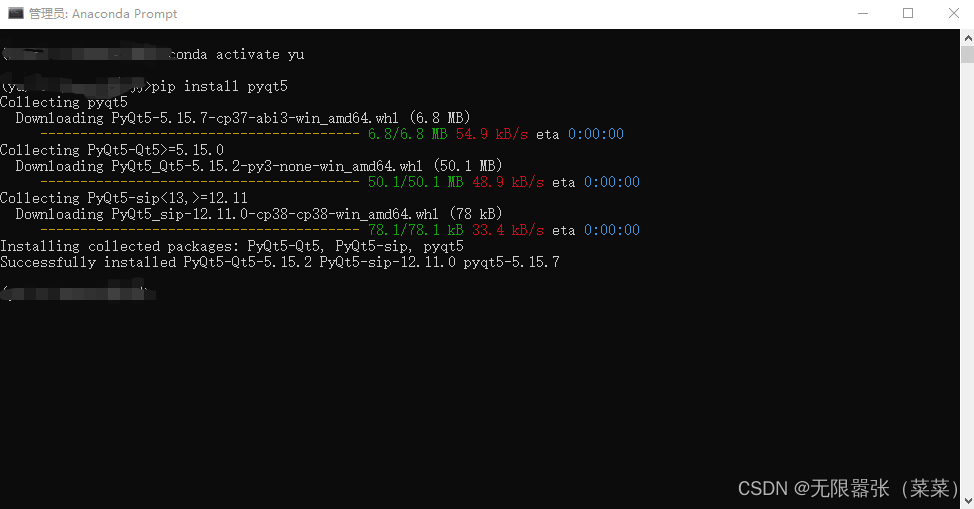
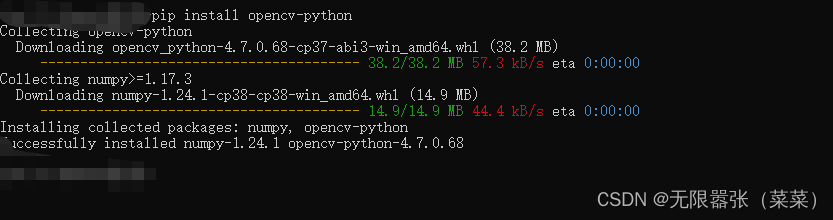
⑧再安装opencv的包,用以下命令:pip install opencv-python ,如下图正在安装中,我们稍等片刻

⑨如果出现如下界面,表示已经安装成功
2.安装 torch,如果你电脑有GPU,想要用GPU训练模型,需要下载两个软件cuda_10.2.89_441.22_win10.exe+cudnn-windows-x86_64-8.7.0.84_cuda10-archive.zip,具体需要什么版本,看自己电脑显卡配置,具体查看是否安装成功,我这里就不详细讲解了,有需要的,私信我即可。
① 以管理员身份运行 ancoda Prompt
②打开pytorch 官网 pytorch.org/get-started/locally
③如果是30系显卡选择CUDA 11.3,如果是之前的显卡选择CUDA10.2,将官网给的指令复制下来:
conda install pytorch torchvision torchaudio cudatoolkit=10.2 -c pytorch
如下图正在安装中,这个安装利用的是电脑源,下载比较慢,可以尝试用镜像源安装。

下面我教大家用镜像源安装pytorch,因为电脑源太慢了,中间还卡顿,人麻了。。。
(1)进入官网,https://download.pytorch.org/whl/torch_stable.html,下载需要的镜像源文件
(2)需要下载三个①torchaudio-0.9.0-cp38-cp38-win_amd64.whl ② torchvision-0.10.0+cu102-cp38-cp38-win_amd64.whl ③torch-1.9.0+cu102-cp38-cp38-win_amd64.whl
(3)用 cd 打开所在的目录,例如我的目录:cd C:\Users\**\Downloads
(4) pip install + 文件名,安装即可,小技巧:输入前几个单词,按 Tab 键,电脑自动补全。
yolov5网络结构图介绍
yolov5是一种单阶段目标检测算法,它在YOLOv4的基础上增加了focus结构,构建了两个CSP结构。YOLOv5网络包含四个通用模块以及六个基本组件,其中四个通用模块的网络结构图如下:

图1
其中,四个大模块具体包括:①输入端:输入图像,输入图像的大小为608*608,在这个阶段有一个图像预处理过程,如图1a所示。②基准网络:该模块用于提取一些通用的特征表示,它是一个性能优良的分类器网络,如图1b所示。③Neck网络:该网络位于基准网络和头部网络的中间,它可以用来进一步提高特征的多样性和稳健性,如图1c所示。④头部输出:这里用于完成目标检测结果的输出。如图1c所示
六个基本组件如图2所示:
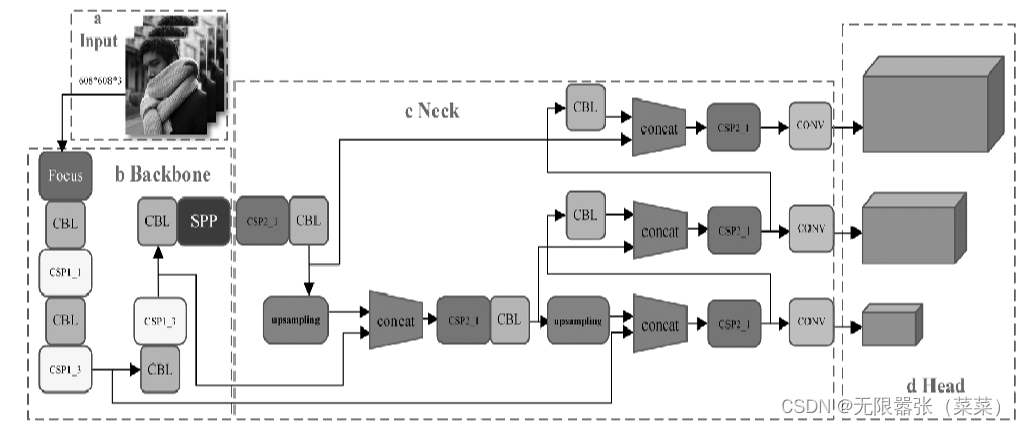
六个基本组件包括:①CBL:CBL模块由conv+bn+leakyrelu激活函数组成,如图2a所示。②Res单元:借用Res网络中的残差结构,用于构建深度网络,CBM是残差模块中的一个子模块,如图2b。③CSP1_x:借用CSP网络结构,该模块由CBL模块、Res单元模块和卷积层组成,如图2c。④CSP2_x:借用CSP网络结构,该模块由卷积层和x个Res单元模块组成,如图2d。⑤Focus:该结构首先2连接多个分片结果,然后将其发送到CBL模块,如图2e。⑥SPP:采用1*1、5*5、9*9和13*13的最大集合进行多尺度特征融合,如图2f。
损失函数
YOLOv5模型中使用了GIoU损失函数。GIoU的提出是为了缓解IoU损失函数不与检测框重叠时的梯度问题,惩罚项被加入到原始IoU中,如下式:
![]()
其中A是预测框,B是真实框,C是AB的最小包围框。这里GIoU首先试图增加预测框的大小,使其能够与真实框重叠 。
注:进行IoU计算,这将消耗大量的时间来尝试将预测框与真实框接触,影响收敛速度,大家可以改进损失函数。
数据集
没有自己打标签,上网盗用别人的数据集,
实验内容
实验框架
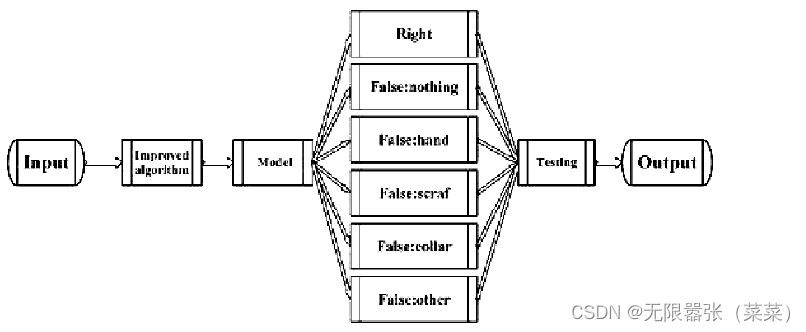
本文实验基本流程框架为:①输入数据集图片。②使用YOLOv5算法。③通过对各类标签的训练得到检测模型。④对测试集进行测试。⑤输出结果完成目标检测。具体流程如下:
实验环境
| 软硬件平台 | 名称 |
| CPU | Intel(R) Core(TM) i5-7300HQ CPU @ 2.50GHz |
| GPU | NVIDIA GeForce GTX 1050 |
| 辅助工具 | matplotlib,opencv,tensorboard |
| 框架 | PyTorch |
实验结果
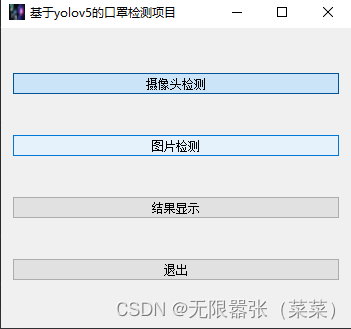
(1)实验总共分摄像头检测、图片检测、还有结果保存显示,最后退出按钮,其中GUI显示界面如下图所示:
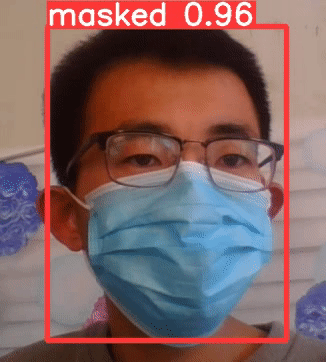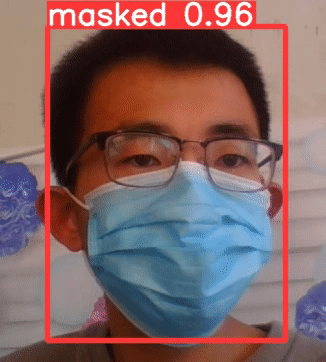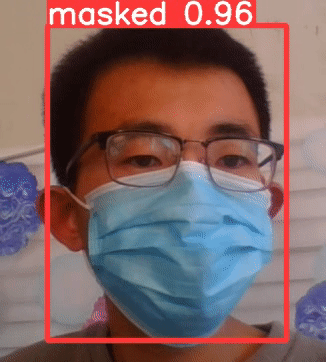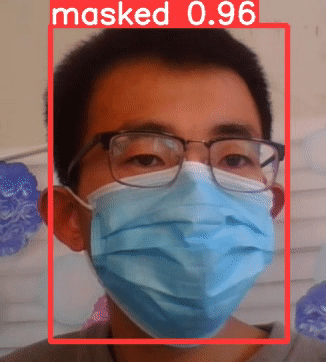
(2)摄像头检测结果显示
①可知已经佩戴口罩,masked
②没有戴口罩,检测结果为,no_mask

2.图片检测(测试集)
(1)如下是没有戴口罩的图像检测,no_mask, 希望各位伙伴出门记得戴口罩哦,做好自我防护

(2)如下是佩戴口罩的图像检测,显示已经佩戴口罩,masked

主函数代码:main.py
import os
import sys
import torch
from PyQt5.QtWidgets import QPushButton, QVBoxLayout, QWidget, QApplication
from detect import run
from PyQt5.QtGui import QIcon
if torch.cuda.is_available():
dev = '0'
else:
dev = 'cpu'
run_dict = {
'weights': 'kid.pt',
'source': 0,
'imgsz': [640, 640],
'conf_thres': 0.60,
'iou_thres': 0.40,
'max_det': 10,
'device': dev,
'view_img': False,
'save_txt': False,
'save_conf': False,
'save_crop': False,
'nosave': True,
'classes': None,
'agnostic_nms': False,
'augment': False,
'visualize': False,
'update': False,
'project': 'runs/detect',
'name': 'exp',
'exist_ok': False,
'line_thickness': 3,
'hide_labels': False,
'hide_conf': False,
'half': False,
}
run_dict_file = {
'weights': 'kid.pt',
'source': 'C:/',
'imgsz': [640, 640],
'conf_thres': 0.60,
'iou_thres': 0.40,
'max_det': 10,
'device': dev,
'view_img': False,
'save_txt': False,
'save_conf': False,
'save_crop': False,
'nosave': False,
'classes': None,
'agnostic_nms': False,
'augment': False,
'visualize': False,
'update': False,
'project': 'runs/detect',
'name': 'exp',
'exist_ok': False,
'line_thickness': 3,
'hide_labels': False,
'hide_conf': False,
'half': False,
}
class WindowClass(QWidget):
def __init__(self,parent=None):
super(WindowClass, self).__init__(parent)
self.setWindowTitle('基于yolov5的口罩检测项目')
self.setWindowIcon(QIcon('master.jpg'))
self.btn_1 = QPushButton("摄像头检测")
self.btn_2 = QPushButton("图片检测")
self.btn_3 = QPushButton("结果显示")
self.btn_4 = QPushButton("退出")
self.btn_1.setCheckable(True)
self.btn_1.toggle()
self.btn_1.clicked.connect(lambda :self.wichBtn(self.btn_1))
self.btn_2.clicked.connect(lambda :self.wichBtn(self.btn_2))
self.btn_3.clicked.connect(lambda :self.wichBtn(self.btn_3))
self.btn_4.clicked.connect(lambda :self.wichBtn(self.btn_4))
self.resize(350,300)
layout=QVBoxLayout()
layout.addWidget(self.btn_1)
layout.addWidget(self.btn_2)
layout.addWidget(self.btn_3)
layout.addWidget(self.btn_4)
self.setLayout(layout)
def wichBtn(self,btn):
print("点击的按钮是:" , btn.text())
if btn.text() == '退出':
sys.exit()
if btn.text() == '摄像头检测':
run(**run_dict)
if btn.text() == '结果显示':
path = os.getcwd() + r'\runs\detect'
os.system("start explorer %s" %path)
if btn.text() == '图片检测':
run(**run_dict_file)
if __name__ == "__main__":
app = QApplication(sys.argv)
win = WindowClass()
win.show()
sys.exit(app.exec_())


![[极客大挑战 2019]Havefun1、EasySQL(BUUCTF)](https://img-blog.csdnimg.cn/4c391d7e82fc404a8c6fa074f9c9e3b0.png)