1.CAP定理
在一个分布式系统中,CAP三者不可兼得,最多只有两者可以满足,正所谓鱼和熊掌不可兼得
- 一致性 Consistency:所有的节点在同一时间的数据一致
- 可用性 Availability:服务在正常响应时间内可用
- 分区容错性 Partition-tolerance:分区故障仍能对外提供一致性或可用性服务。
1.1 一致性问题的是由于分区(多台服务器),因为当服务器多了以后,要遵循一致性就比较麻烦。
1.2 数据冗余可以提供系统的可用性和分区容错性,但是难以满足强一致性,数据冗余指的就是
把数据副本打散在各个分区,但是这并不能满足强一致性是因为:
假设有一个分布式系统,其中有两个节点 A 和 B,它们存储相同的数据副本。考虑下面的场景:
- 客户端向节点 A 发送一个写请求,要求将某个数据从 X 修改为 Y。
- 节点 A 接收到写请求后,将数据从 X 修改为 Y,并响应客户端写操作成功。
- 同时,客户端向节点 B 发送一个读请求,希望获取最新的数据。
- 由于数据冗余,节点 B 的数据也应该是最新的。然而,在分布式系统中,节点之间可能存在通信延迟或网络分区等问题,导致数据同步需要一些时间。
若要解决一致性问题,达到强一致性,需要把所有请求全部通过单台服务器处理,很难达到可用性。
因此,对于分布式系统,需要在一致性、可用性和分区容错性间中取舍。从经验上看,可用性或一致性往往是被弱化的对象。
对于高可用的系统来说,往往保留强一致性。因此,计算机界通过共识算法来解决此类问题。
共识算法保证所有的参与者都有相同的认知,即强一致性。常见的共识算法有:
- paxos 算法:代表 Zookeeper
- Raft 算法:代表 Etcd
本文主要介绍 Raft 一致性算法。流程演示可参考:Raft 算法流程
2. Raft 基本概念
Raft 算法是主从模型(单 Leader 多 Follower)。所有的请求全部由 Leader 处理。Leader 处理请求时,先追加一条日志,然后把日志同步给 Follower。当写入成功的节点过半后持久化日志,
Raft 节点有三种角色
- Leader(主副本)
- Candidate (候选副本)
- Follower (副副本)
Raft 投票机制
- 节点不能重复投票。Follower 节点记录自己投过的节点,在一个任期内不会重复投票
- 一节点一票。Candidate 节点投给自己,Follower 节点投给向自己拉票的 Candidate
Raft 节点间使用的消息有两种
- RequesetVote:请求其他节点给自己投票,由 Candidate 节点发出
- AppendEntries:附加条目,条目数量 > 0,日志复制;条目数量 > 0 = 0,心跳信息,由 Leader 节点发出
任期 Term:逻辑时钟值,全局递增,描述一个 Leader 的任期
3、Raft 算法核心
Raft 算法核心是
- Leader 选举
- 日志复制
3.1、Leader 选举
Leader 选举流程
集群中的节点刚启动时,所有节点都是 Follower 节点。
当 Leader 发送的心跳超时,Follower 节点自动变成 Candidate 节点,自荐成为选举候选人,并向其他节点发送 RequesetVote 消息
若 Candidate 节点收到过半支持 (n+1)/2 后,变成 Leader 节点。新的 Leader 节点立即向其他节点发送心跳消息 AppendEntries,其他节点重置自己的选举超时时间,并保持 Follower 角色。
当集群节点数是偶数,可能会出现平票的情况,如图所示,两个 Candidate 节点分别得到 2 票,票数均未过半,无法选出 Leader 节点,该现象被称为分割选举 split vote。进入下一轮选举。

为了避免分割选举的现象出现,Raft 算法使用随机选举超时来降低 split vote 出现的概率。这样每个节点成为 Candidate 节点的时间点被错开了,提高了 Leader 节点选举成功的概率。
在选出 Leader 节点后,各个节点需要在最短时间内获取新的 Leader 节点信息,否则选举超时又会进入新一轮选举。因此心跳超时 << 选举超时。
节点的选举时间在收到心跳消息后会重置。如果不重置,节点会频繁发起选举。这样避免了节点频繁发起选举,系统收敛于稳定状态。只要 Leader 持续不断发送心跳信息,Follower 节点就不会成为 Candidate 角色并发起选举。
至此,选举结束,Leader 节点和 Follower 节点间开始日志同步。
任何导致心跳超时的事件,例如:集群启动、Leader 节点宕机、网络分区等,都会导致集群 Leader 选举。
Leader 选举控制
- 心跳超时:Follower 节点在规定时间内没有收到 leader 的心跳消息。
- 选举超时:随机值,Follower 等待变成 Candidate 的时间。定时器到期,Follower 节点自动成为 Candidate 节点,将选举任期 + 1。
可以这样理解:
Leader 节点是君主,Follower 节点是有野心的臣子,蠢蠢欲动,随时密谋造反。只要 Leader 定期发号施令(心跳消息),Follower 收到心跳消息后,忌惮君主实力,不敢造反(重置选举超时)。
倘若一段时间后 Follower 不再收到君主的消息(心跳超时),Follower 准备妥当后(选举超时)成为 Candidate。自立为王,并胁迫其他 Follower 支持自己(RequesetVote 消息)。一旦获得半数以上的 Follower 支持,新王加冕。
新的 Leader 立刻发送心跳消息,迫使其他 Candidate 放弃造反,继续保持 Follower 身份。
3.2、日志复制
Raft 算法中,所有来自客户端的数据变更请求都会被当作一个日志条目追加到节点日志中。
日志条目有以下两种状态:
已追加,但是尚未提交(没有持久化)
已提交(持久化)
Raft 算法中的节点维护已提交日志条目索引 commitIndex,小于等于该值的日志条目被认为是已提交,否则就是尚未持久化的数据。
Raft 日志复制流程
日志追加
日志提交
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-czAthxE1-1678935556629)(云原生.assets/Raft_日志复制.png)]
客户端向 Leader 发送数据变更请求,Leader 节点向自己的日志中追加一条日志,接下来通过 AppendEntries 消息向其他节点同步数据。当超过半数节点(包括 Leader 自己)追加新日志成功后,Leader 节点持久化日志并提交日志,然后再次通过 AppendEntries 消息通知其他节点持久化日志。
一般情况,日志复制需要来回发送两次 AppendEntries 消息(追加日志和提交日志)。需要发送两次的主要原因是需要确保过半追加成功后,系统才能正常提交日志。假设不确认过半追加,当碰到脑裂或者网络分区时,会出现数据严重不一致的问题。
例如:如图所示,Raft 集群中,原 Leader 是 B 节点,其他都是 Follower,任期是 1。在某一时刻出现网络分区,节点 A、B 处在同一分区,A 仍可以接受 B 的心跳信息,保持 Follower。节点 C、D、E 无法收到 B 的心跳消息,选举超时后,选举 C 作为新的 Leader 节点,任期 + 1。
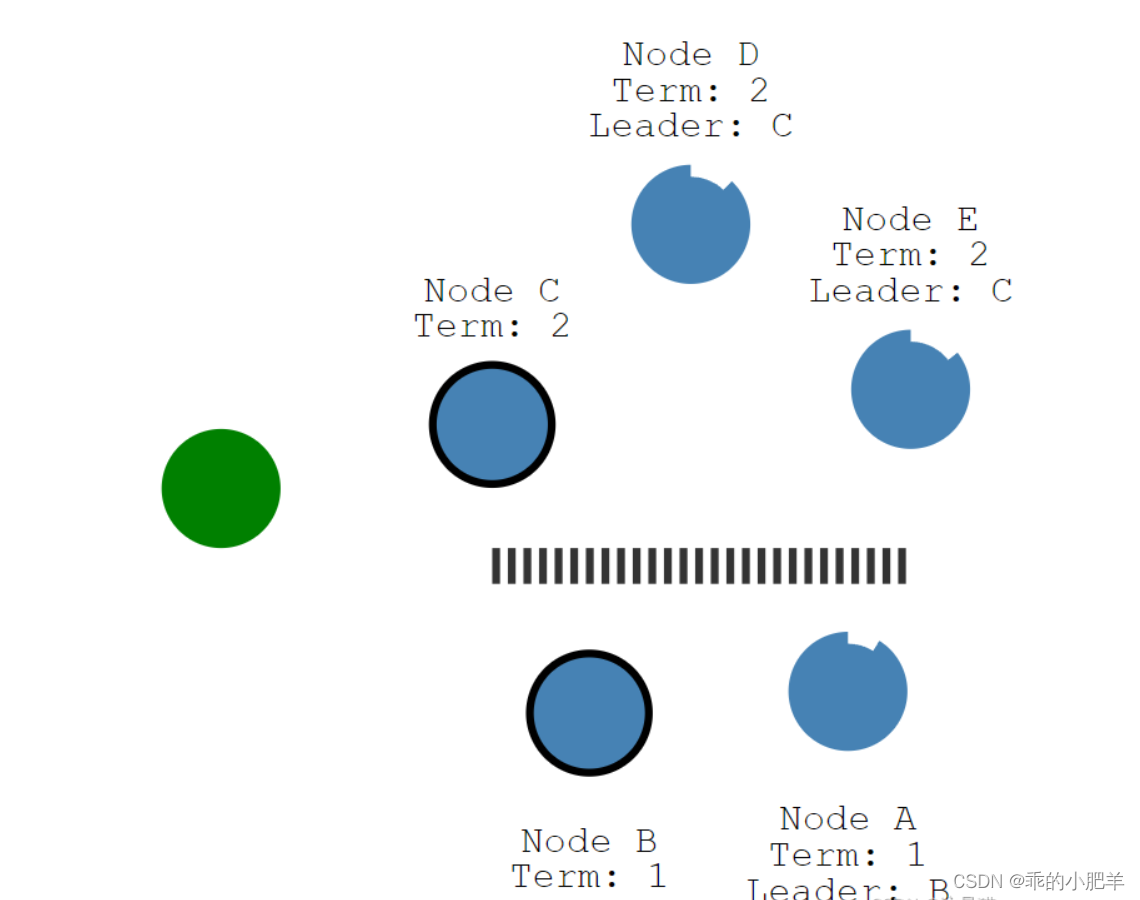
当客户端连接节点 B 和 C 分别写入,对于分区 A,B,追加日志后,没有收到半数以上节点的确认(2 个节点),无法提交日志;对于分区 C,D,E,追加日志后,收到半数以上节点的确认(3 个节点),提交日志成功。此时,Leader B 和 Leader C 日志冲突。
当网络分区恢复后,Leader B 节点发现 Leader C 节点的任期 Term 的值更高, 降级为 Follower。则节点 A 和 B 丢弃自己的日志,同步 Leader C 的日志消息。此时,日志保持一致。
4、总结
Raft 的读写
所有来自客户端的读写请求,全部由 Leader 节点处理。
Raft 节点的三种状态
Follower:随机选举超时,自动成为 Candidate
Candidate:主动给自己投票,向其他节点广播拉票,当自身选票超过半数以上成为 Leader
Leader:定时向其他节点发送心跳消息,并同步变化信息;若 Leader 发现有比自身更高的任期,则自己立刻下台成为 Follower,并接受新的 Leader 的数据变更同步
Raft 节点的状态变化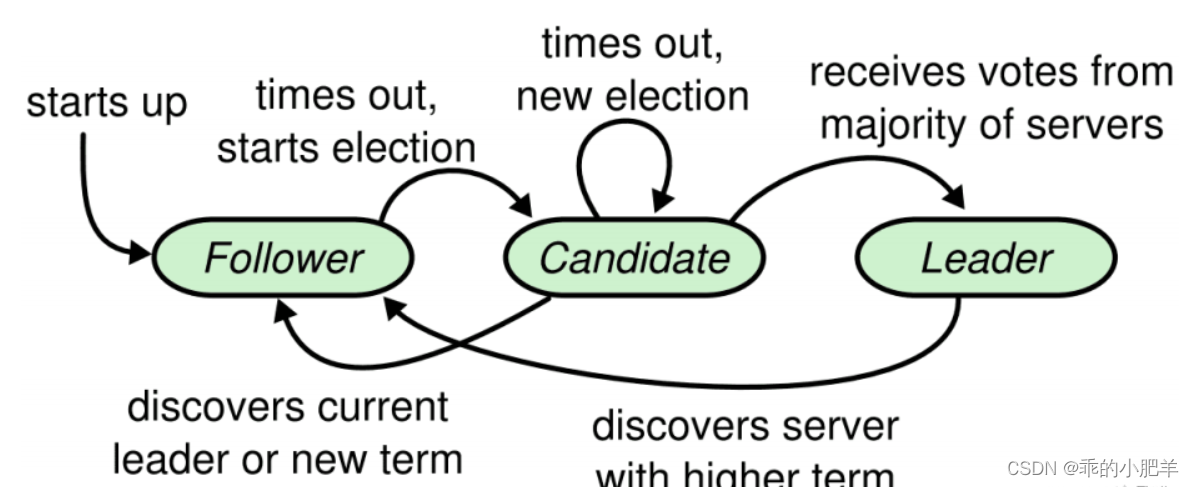
Follower -> Candidate:选举超时,自动成为 Candidate
Candidate -> Candidate:本轮选举,开启新一轮选举
Candidate -> Leader:获得半数以上节点的支持
Leader -> Follower:发现更高的任期
Candidate -> Follower:收到 Leader 的心跳消息
Follower 处理其他节点发送来的消息
candidate:向第一次接收到的拉票所属 candidate 发送投票,并将自己的任期设置为该 candidate 的任期。同时会重置自身选举超时和心跳超时
Leader:重置自身选举超时和心跳超时
平票后,下一轮选举
选举任期 Term + 1
重新随机一个选举超时
重置上轮的选票
日志复制流程
日志追加:收到数据变更请求,Leader 将追加日志到本地,向其他节点同步数据,待半数以上节点追加成功后,开始日志持久化。
日志提交:Leader 将本地日志持久化,并通知其他节点日志持久化。
Raft 修复脑裂后,如何恢复一致性
发生脑裂:无法接收到心跳消息的分区重新选举新的 Leader 节点,分区内所有节点任期 + 1
修复脑裂:若 Leader 节点发现集群中有比自己任期还高的 Leader 节点, 则降级为 Follower,接收 Leader 的数据同步