目录
1.Spark 概念
2. Hadoop和Spark的对比
3. Spark特点
3.1 运行速度快
3.2 简单易用
3.3 通用性强
3.4 可以允许运行在很多地方
4. Spark框架模块
4.1 Spark Core
4.2 SparkSQL
4.3 SparkStreaming
4.4 MLlib
4.5 GraphX
5. Spark的运行模式
5.1 本地模式(单机) Local运行模式
5.2 Standalone模式(集群)
5.3 HadoopYARN模式(集群)
5.4 Kubernetes模式(容器集群)
5.5 云服务模式(运行在云平台上)
6. Spark架构
6.1 在Spark中任务运行层面
6.2 在Spark中资源层面
1.Spark 概念
- 定义:Apache Spark 是用于大规模数据处理的统一分析引擎
- 其特点就是对任意类型的数据进行自定义计算。
- Spark可以计算:结构化、半结构化、非结构化等各种类型的数据结构,同时也支持使用Python、Java、Scala、R以及SQL语言去开发应用程序计算数据。
- Spark的适用面非常广泛,所以,被称之为统一的(适用面广)的分析引擎(数据处理)
- Spark最早源于一篇论文 Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing, 该论文是由加州大学柏克莱分校的Matei Zaharia等人发表的。论文中提出了一种弹性分布式数据集(即RDD)的概念。
- RDD是一种分布式内存抽象,其使得程序员能够在大规模集群中做内存运算,并且有一定的容错方式。而这也是整个Spark的核心数据结构,Spark整个平台都围绕着RDD进行。
2. Hadoop和Spark的对比
尽管Spark相对于Hadoop而言具有较大优势,但Spark并不能完全替代Hadoop
- 在计算层面,Spark相比较MR(MapReduce)有巨大的性能优势,但至今仍有许多计算工具基于MR构架,比如非常成熟的Hive
- Spark仅做计算,而Hadoop:生态圈不仅有计算(MR)也有存储(HDFS)和资源管理调度(YARN),HDFS和YARN仍是许多大数据体系的核心架构。
3. Spark特点
3.1 运行速度快
Spark处理数据与MapReduce处理数据相比,有如下两个不同点:
- Spark处理数据时,可以将中间处理结果数据存储到内存中;
- Spark提供了非常丰富的算子(APi),可以做到复杂任务在一个Spark程序中完成.
3.2 简单易用
3.3 通用性强
3.4 可以允许运行在很多地方
4. Spark框架模块
4.1 Spark Core
Spark的核心,Spark核心功能均由SparkCore模块提供,是Spark:运行的基础。
SparkCorel以RDD为数据抽象,提供Python、Java、Scala、R语言的API,可以编程进行海量离线数据批处理计算。
4.2 SparkSQL
基于SparkCore之上,提供结构化数据的处理模块。
SparkSQL支持以sQL语言对数据进行处理,SparkSQL本身针对离线计算场景。
同时基于SparkSQL,Spark提供了StructuredStreaming模块,可以以SparkSQL为基础,进行数据的流式计算。
4.3 SparkStreaming
以SparkCore为基础,提供数据的流式计算功能。
4.4 MLlib
以SparkCore为基础,进行机器学习计算,内置了大量的机器学习库和APi算法等。方便用户以分布式计算的模式进行机器学习计算。
4.5 GraphX
以SparkCore为基础,进行图计算,提供了大量的图计算APl,方便用于以分布式计算模式进行图计算。
5. Spark的运行模式
5.1 本地模式(单机) Local运行模式
本地模式就是以一个独立的进程,通过其内部的多个线程来模拟整个Spark运行时的环境
5.2 Standalone模式(集群)
Spark中的各个角色以独立进程的形式存在,并组成Spark:集群环境
5.3 HadoopYARN模式(集群)
Spark中的各个角色运行在YARN的容器内部,并组成Spark集群环境
5.4 Kubernetes模式(容器集群)
Spark中的各个角色运行在Kubernetesl的容器内部,并组成Spark:集群环境
5.5 云服务模式(运行在云平台上)
6. Spark架构
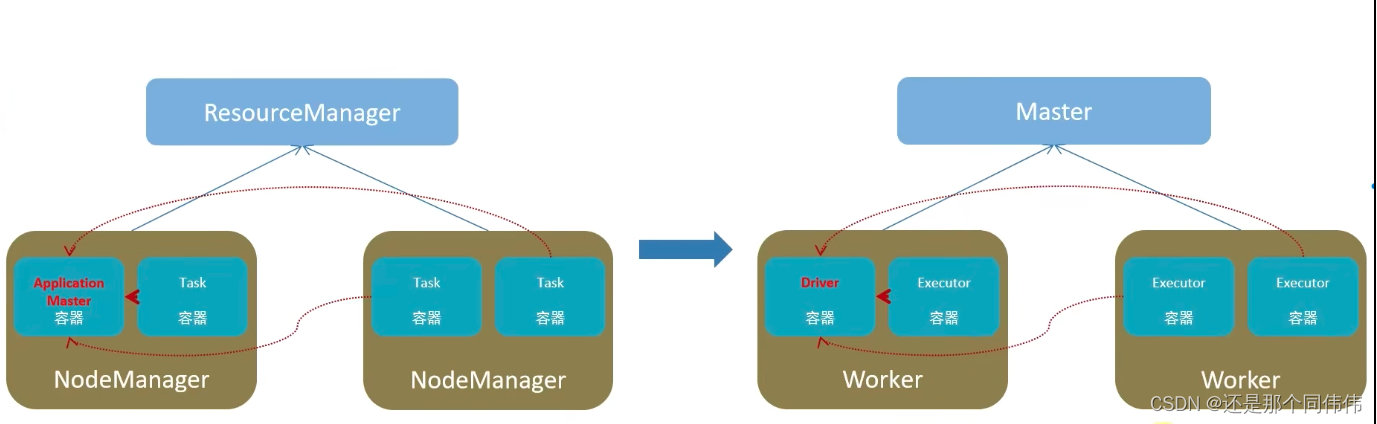
左边是YARN框架,右边是Spark框架
6.1 在Spark中任务运行层面
- Driver, 负责对一个任务的运行进行管理(单个任务的管理)
- Executor,单个任务的计算(干活的)
- 正常情况下Executor是干活的角色,不过特殊场景下,(local模式)Driver可以即管又干活
6.2 在Spark中资源层面:
- Master角色:集群资源管理
- Worker的角色: 单机资源管理
Spark与PySpark(1.概述、框架、模块)
news2026/2/13 14:23:55


本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/1303246.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章

ubuntu18.04配置cuda+cudnn+tensorrt+anconda+pytorch-gpu+pycharm
一、显卡驱动安装 执行nvidia-smi查看安装情况 二、cuda安装 cuda官网下载cuda_11.6.2_510.47.03_linux.run,安装执行
sudo sh cuda_11.6.2_510.47.03_linux.run提升安装项,驱动不用安装,即第一项(Driver)ÿ…
SpringBoot集成swagger2配置权限认证参数
作者简介:大家好,我是撸代码的羊驼,前阿里巴巴架构师,现某互联网公司CTO 联系v:sulny_ann(17362204968),加我进群,大家一起学习,一起进步,一起对抗…

【JavaWeb学习笔记】8 - HTTP
一、常用文档
请求头 响应头
中间件获取的网页协议和返回的内容 这些称为HTTP协议 请求和响应
常见的请求头 响应头 状态码 HTTP状态码 当浏览者访问一个网页时,浏览者的浏览器会向网页所在服务器发出请求。当浏览器接收并显示网页前,此网页所在的服务…

【二者区别】cuda和cudatoolkit
Pytorch 使用不同版本的 cuda 由于课题的原因,笔者主要通过 Pytorch 框架进行深度学习相关的学习和实验。在运行和学习网络上的 Pytorch 应用代码的过程中,不少项目会标注作者在运行和实验时所使用的 Pytorch 和 cuda 版本信息。由于 Pytorch 和 cuda 版…
联邦蒸馏中的分布式知识一致性 | TIST 2024
联邦蒸馏中的分布式知识一致性 | TIST 2024
联邦学习是一种隐私保护的分布式机器学习范式,服务器可以在不汇集客户端私有数据的前提下联合训练机器学习模型。通信约束和系统异构是联邦学习面临的两大严峻挑战。为同时解决上述两个问题,联邦蒸馏技术被提…

vue 中国省市区级联数据 三级联动
vue 中国省市区级联数据 三级联动
安装插件 npm install element-china-area-data5.0.2 -S 当前版本以测试,可用。组件中使用了 element-ui, https://element.eleme.cn/#/zh-CN/component/installation 库 请注意安装。插件文档 https://www.npmjs.com/package/ele…

【Go-自学版】03-即时通信系统1
1. 基础 server 构建
main.go | server.go
// main.go
package mainfunc main() {// http://127.0.0.1:8888/ server : NewServer("127.0.0.1", 8888)server.Start()
}// server.go
package mainimport ("fmt""net"
)type Server struct {IP …

论文阅读《High-frequency Stereo Matching Network》
论文地址:https://openaccess.thecvf.com/content/CVPR2023/papers/Zhao_High-Frequency_Stereo_Matching_Network_CVPR_2023_paper.pdf 源码地址: https://github.com/David-Zhao-1997/High-frequency-Stereo-Matching-Network 概述 在立体匹配研究领域…


Java - Mybatis的缓存机制、集成SpringBoot后缓存相关问题
mybaits提供一级缓存,和二级缓存 一级缓存(默认开启) 一级缓存是SqlSession级别的缓存。在操作数据库时需要构造 sqlSession对象,在对象中有一个(内存区域)数据结构(HashMap)用于存储缓存数据。不同的sqlSe…
秒级监控、精准迅速:全面保障业务可用性 | 开源日报 No.101
louislam/uptime-kuma
Stars: 41.1k License: MIT Uptime Kuma 是一个易于使用的自托管监控工具,主要功能和核心优势包括:
监控 HTTP(s) / TCP / HTTP(s) 关键词 / HTTP(s) Json 查询 / Ping / DNS 记录等服务的可用性提供时尚、响应迅速且良好用户体验…

STM32F407-14.3.1-01 时基单元
时基单元 可编程高级控制定时器的主要模块是一个 16 位计数器及其相关的自动重载寄存器。计数器可递增计数、递减计数或交替进行递增和递减计数。计数器的时钟可通过预分频器进行分频。 计数器、自动重载寄存器和预分频器寄存器可通过软件进行读写。即使在计数器运行时也可执行…

VR串流线方案:实现同时充电传输视频信号
VR(Virtual Reality),俗称虚拟现实技术,是一项具有巨大潜力的技术创新,正在以惊人的速度改变我们的生活方式和体验,利用专门设计的设备,如头戴式显示器(VR头盔)、手柄、定…
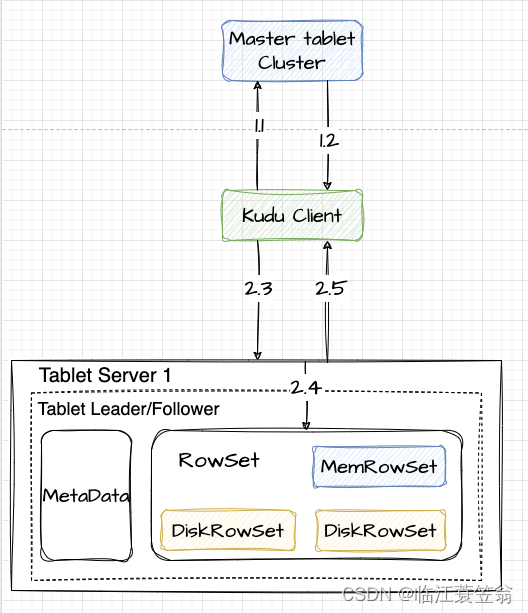
Kudu-架构与设计
Kudu架构与设计 一、背景1.存储组件2.使用场景3.多组件组合缺点3.1 架构复杂3.2 时效性低3.3 应对数据更新 二、Kudu概述1.设计特点2.框架适用场景3.框架不适用场景 三、数据模型与存储1.Table2.Tablet3.MetaData4.RowSet5.MemRowSet6.DiskRowSet6.1 Base Data6.2 Delta Stores…
spring结合设计模式之策略模式
策略模式基本概念:
一个接口或者抽象类,里面两个方法(一个方法匹配类型,一个可替换的逻辑实现方法)不同策略的差异化实现(就是说,不同策略的实现类)
使用策略模式替换判断,使代码更加优雅。
…
从docker镜像提取文件
1. 从Docker镜像提取JAR文件
Docker是一种流行的容器化平台,允许开发人员将应用程序及其所有依赖关系打包到一个容器中。这使得应用程序的部署和迁移变得更加简单和可靠。在某些情况下,我们可能需要从Docker镜像中提取JAR文件,以便进行进一步…
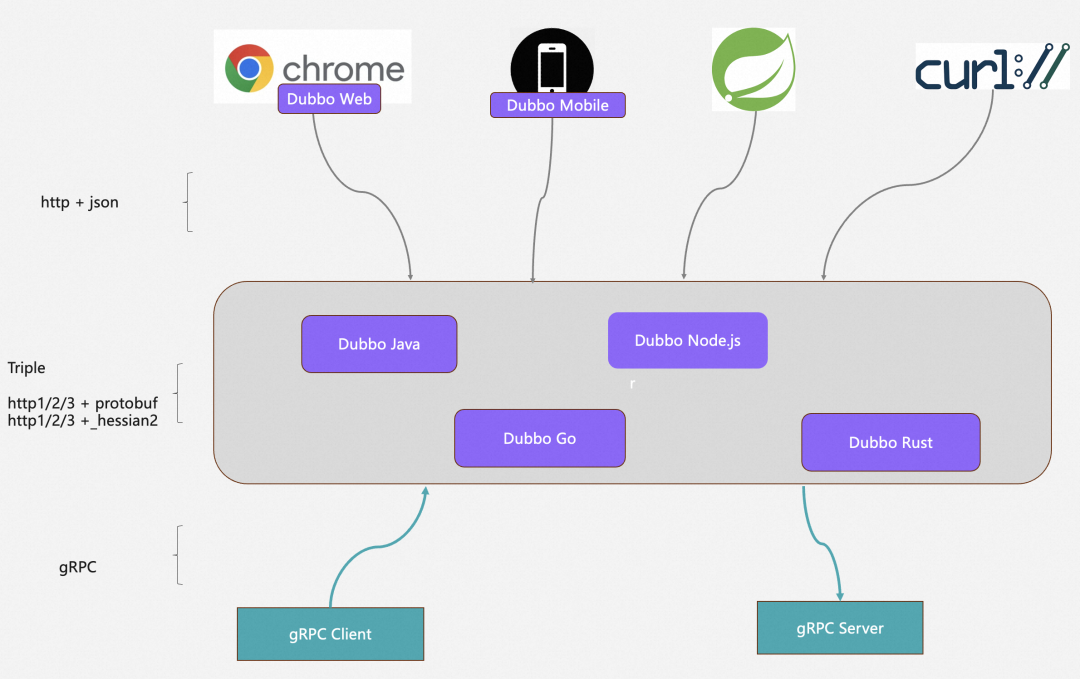
Dubbo 的 go 语言实现迎来了 Dubbo3 版本
新版本的 dubbo-go: 全面升级 Triple 协议,兼容 gRPC、标准 HTTP 客户端,提供简单明了的 API 用于编写 RPC server 与 client,解决组件间的基本通信问题。 针对微服务场景,提供了完善的服务治理能力,这包括配置管理、可观测性、流量管控规则、生态集成与适配等的全面升级…
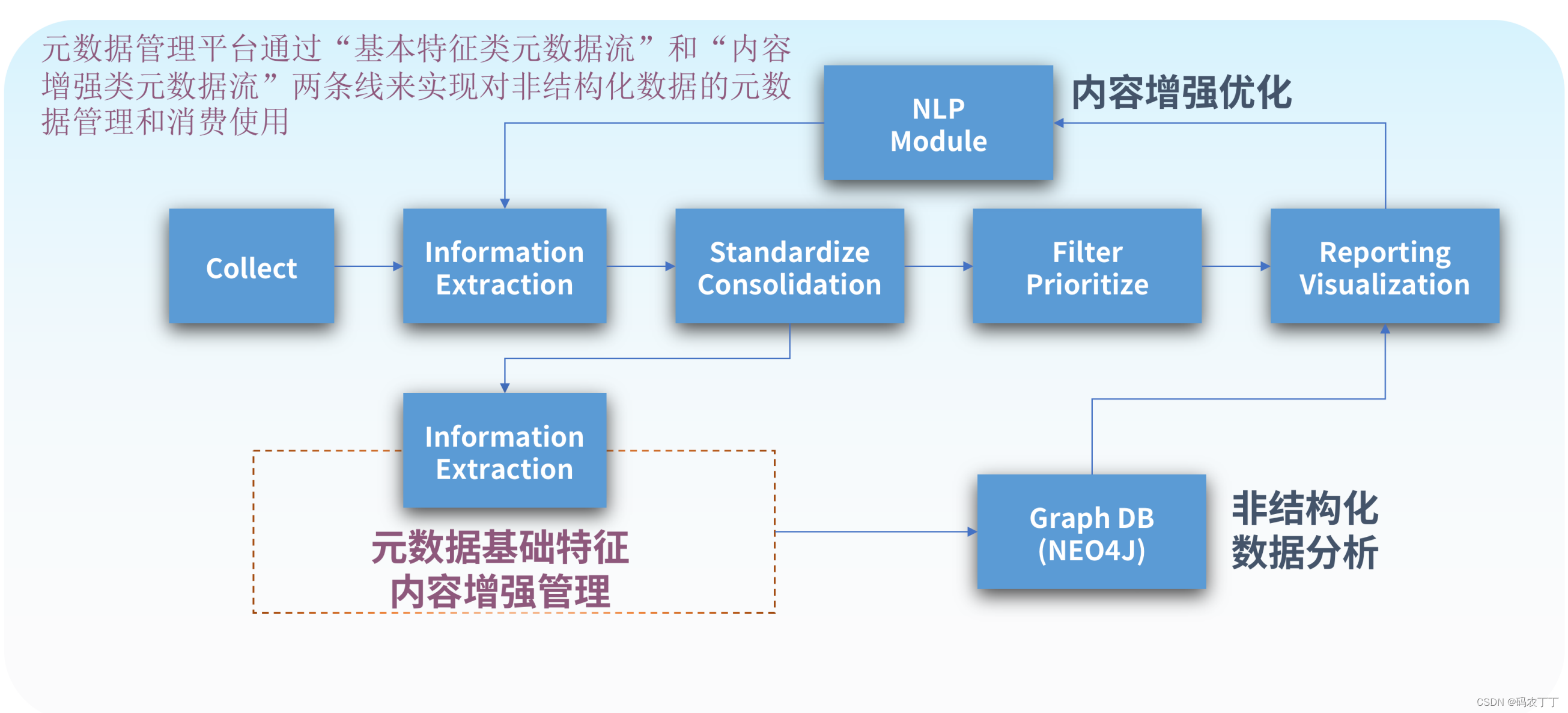
【华为数据之道学习笔记】3-9以特征提取为核心的非结构化数据管理
随着业务对大数据分析的需求日益增长,非结构化数据的管理逐 渐成为数据管理的重要组成部分。非结构化数据包括无格式文本、各类格式文档、图像、音频、视频等多种异构的格式文件,较之结构化数据,其更难标准化和理解,因此在存储、检…

HTML常用表单元素使用?
目录 一、常用表单元素使用的关键字二、常用表单元素使用的效果与作用(1)password : 保护用户的隐私(2) email: 输入邮件(比如QQ邮件)(3)、number : 输入框只能输入数字(4)、tel : 常用于输入电话号&#x…

阿里云国际CDN加速图文和视频类网站操作教程
假设用户A需要加速一个小型的社区网站,加速需求和相关信息如下: 网站域名:c.9he.com。 加速内容:图片和文字为主,同时包含部分视频点播内容。 加速区域:仅中国内地,因为访问该网站的终端用户都…