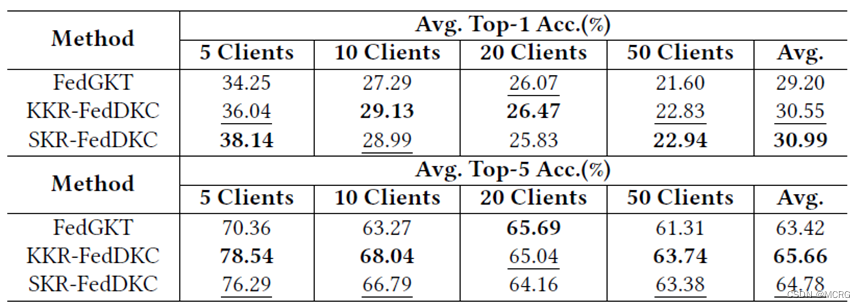
Pytorch 使用不同版本的 cuda
由于课题的原因,笔者主要通过 Pytorch 框架进行深度学习相关的学习和实验。在运行和学习网络上的 Pytorch 应用代码的过程中,不少项目会标注作者在运行和实验时所使用的 Pytorch 和 cuda 版本信息。由于 Pytorch 和 cuda 版本的更新较快,可能出现程序的编译和运行需要之前版本的 Pytorch 和 cuda 进行运行环境支持的情况。比如笔者遇到的某个项目中编写了 CUDAExtension 拓展,而其中使用的 cuda 接口函数在新版本的 cuda 中做了修改,使得直接使用系统上已有的新版本 cuda 时会无法编译使用。
为了满足应用程序和框架本身对不同版本的 cuda 的需求,(如上面遇到的问题中,即需要 Pytorch 能够切换使用系统上不同版本的 cuda ,进而编译对应的 CUDAExtension),这里即记录笔者了解到的 Ubuntu 环境下 Pytorch 在编辑 cpp 和 cuda 拓展时确定所使用 cuda 版本的基本流程以及 Pytorch 使用不同版本的 cuda 进行运行的方法。
cuda 与 cudatoolkit 的区别
在使用 Anaconda 安装 Pytorch 深度学习框架时,可以发现 Anaconda 会自动为我们安装 cudatoolkit,如下图所示。

上述安装的 cudatoolkit 与通过 Nvidia 官方提供的 CUDA Toolkit 是不一样的。具体而言,Nvidia 官方提供的 CUDA Toolkit 是一个完整的工具安装包,其中提供了 Nvidia 驱动程序、开发 CUDA 程序相关的开发工具包等可供安装的选项。使用 Nvidia 官网提供的 CUDA Toolkit 可以安装开发 CUDA 程序所需的工具,包括 CUDA 程序的编译器、IDE、调试器等,CUDA 程序所对应的各式库文件以及它们的头文件。上述 CUDA Toolkit 的具体组成可参考 CUDA Toolkit Major Components![]() https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html#major-components 实际上,Nvidia 官方提供安装的 CUDA Toolkit 包含了进行 CUDA 相关程序开发的编译、调试等过程相关的所有组件。但对于 Pytorch 之类的深度学习框架而言,其在大多数需要使用 GPU 的情况中只需要使用 CUDA 的动态链接库支持程序的运行( Pytorch 本身与 CUDA 相关的部分是提前编译好的 ),就像常见的可执行程序一样,不需要重新进行编译过程,只需要其所依赖的动态链接库存在即可正常运行。故而,Anaconda 在安装 Pytorch 等会使用到 CUDA 的框架时,会自动为用户安装 cudatoolkit,其主要包含应用程序在使用 CUDA 相关的功能时所依赖的动态链接库。在安装了 cudatoolkit 后,只要系统上存在与当前的 cudatoolkit 所兼容的 Nvidia 驱动,则已经编译好的 CUDA 相关的程序就可以直接运行,而不需要安装完整的 Nvidia 官方提供的 CUDA Toolkit .
https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html#major-components 实际上,Nvidia 官方提供安装的 CUDA Toolkit 包含了进行 CUDA 相关程序开发的编译、调试等过程相关的所有组件。但对于 Pytorch 之类的深度学习框架而言,其在大多数需要使用 GPU 的情况中只需要使用 CUDA 的动态链接库支持程序的运行( Pytorch 本身与 CUDA 相关的部分是提前编译好的 ),就像常见的可执行程序一样,不需要重新进行编译过程,只需要其所依赖的动态链接库存在即可正常运行。故而,Anaconda 在安装 Pytorch 等会使用到 CUDA 的框架时,会自动为用户安装 cudatoolkit,其主要包含应用程序在使用 CUDA 相关的功能时所依赖的动态链接库。在安装了 cudatoolkit 后,只要系统上存在与当前的 cudatoolkit 所兼容的 Nvidia 驱动,则已经编译好的 CUDA 相关的程序就可以直接运行,而不需要安装完整的 Nvidia 官方提供的 CUDA Toolkit .
通过 Anaconda 安装的应用程序包位于安装目录下的 /pkg 文件夹中,如笔者的目录即为 /home/xxx/anaconda3/pkgs/ ,用户可以在其中查看 conda 安装的 cudatoolkit 的内容,如下图所示。可以看到 conda 安装的 cudatoolkit 中主要包含的是支持已经编译好的 CUDA 程序运行的相关的动态链接库。( Ubuntu 环境下 )

在大多数情况下,上述 cudatoolkit 是可以满足 Pytorch 等框架的使用需求的。但对于一些特殊需求,如需要为 Pytorch 框架添加 CUDA 相关的拓展时( Custom C++ and CUDA Extensions ),需要对编写的 CUDA 相关的程序进行编译等操作,则需安装完整的 Nvidia 官方提供的 CUDA Toolkit.
本文的后续内容,即对应的是当 Pytorch 等框架需要编译对应的 CUDA 相关拓展程序时,如何设置使用不同版本的 cuda toolkit( 完整的包含有编译器的安装包 )对程序进行编译,进而满足特定的 CUDA 版本依赖。
Pytorch 确定所使用的 cuda 版本
实际使用过程中,Pytorch 检测运行时使用的 cuda 版本的代码位于 torch/utils/cpp_extension.py 的_find_cuda_home 函数 ( Pytorch 1.1.0, Line 24 )中.这里主要介绍 Linux 环境下的 cuda 版本的确认过程,关于 Windows 环境下多版本 cuda 的使用可以参考上述文件中的具体实现.
确定 cuda 路径
若在运行时需要使用 cuda 进行程序的编译或其他 cuda 相关的操作,Pytorch 会首先定位一个 cuda 安装目录( 来获取所需的特定版本 cuda 提供的可执行程序、库文件和头文件等文件 )。具体而言,Pytorch 首先尝试获取环境变量 CUDA_HOME/CUDA_PATH 的值作为运行时使用的 cuda 目录。若直接设置了 CUDA_HOME/CUDA_PATH 变量,则 Pytorch 使用 CUDA_HOME/CUDA_PATH 指定的路径作为运行时使用的 cuda 版本的目录。
若上述环境变量不存在,则 Pytorch 会检查系统是否存在固定路径 /usr/local/cuda 。默认情况下,系统并不存在对环境变量 CUDA_HOME 设置,故而 Pytorch 运行时默认检查的是 Linux 环境中固定路径 /usr/local/cuda 所指向的 cuda 目录。 /usr/local/cuda 实际上是一个软连接文件,当其存在时一般被设置为指向系统中某一个版本的 cuda 文件夹。使用一个固定路径的软链接的好处在于,当系统中存在多个安装的 cuda 版本时,只需要修改上述软连接实际指向的 cuda 目录,而不需要修改任何其他的路径接口,即可方便的通过唯一的路径使用不同版本的 cuda. 如笔者使用的服务器中,上述固定的 /usr/local/cuda 路径即指向一个较老的 cuda-8.0 版本的目录。 
需要注意的是, /usr/local/cuda 并不是一个 Linux 系统上默认存在的路径,其一般在安装 cuda 时创建( 为可选项,不强制创建 )。故而 Pytorch 检测上述路径时也可能会失败。
若 CUDA_HOME 变量指定的路径和默认路径 /usr/local/cuda 均不存在安装好的 cuda 目录,则 Pytorch 通过运行命令 which nvcc 来找到一个包含有 nvcc 命令的 cuda 安装目录,并将其作为运行时使用的 cuda 版本。具体而言,系统会根据环境变量 PATH 中的目录去依次搜索可用的 nvcc 可执行文件,若环境变量 PATH 中包含多个安装好的 cuda 版本的可执行文件目录( 形如/home/test/cuda-10.1/bin ),则排在 PATH 中的第一个 cuda 的可执行文件目录中的 nvcc 命令会被选中,其所对应的路径被选为 Pytorch 使用的 cuda 路径。同样的,若 PATH 中不存在安装好的 cuda 版本的可执行目录,则上述过程会失败,Pytorch 最终会由于找不到可用的 cuda 目录而无法使用 cuda.比较推荐的做法是保持 PATH 路径中存在唯一一个对应所需使用的 cuda 版本的可执行目录的路径。
在确定好使用的 cuda 路径后,基于 cuda 的 Pytorch 拓展即会使用确定好的 cuda 目录中的可执行文件( /bin )、头文件( /include )和库文件( /lib64 )完成所需的编译过程。
Pytorch 使用特定的 cuda 版本
从 Pytorch 确定使用的 cuda 版本的流程来看,想要指定 Pytorch 使用的 cuda 版本,主要有两种方法,第一种是修改软链接 /usr/local/cuda 所指向的 cuda 安装目录( 若不存在则新建 ),第二种是通过设置环境变量 CUDA_HOME 指向所需使用的 cuda 版本的安装目录。除此之外,还建议将对应 cuda 目录中的可执行文件目录( 形如/home/test/cuda-10.1/bin )加入环境变量 PATH 中。
对于第一种方法,由于 /usr/ 和 /usr/local/ 目录下的文件均为 root 用户所管理,故而普通用户无法对其进行修改。对于具备了 root 权限的用户而言,在安装有多版本 cuda 的 Linux 系统上,只需切换 /usr/local/cuda 所指向的 cuda 目录,让其指向所需的 cuda 版本的安装位置,即可让 Pytorch 在运行时使用指定版本的 cuda 运行程序。修改软链接的方法如下命令所示,命令删除原有的软链接,并新建指向新路径的软链接。
sudo rm -rf /usr/local/cuda //删除软链接,注意是 /usr/local/cuda 而不是 /usr/local/cuda/,前者仅删除软链接,而后者会删除软链接所指向的目录的所有内容,操作请小心 sudo ln -s cuda_path /usr/local/cuda //创建名为 /usr/local/cuda 的软链接,其指向 cuda_path 所指定的 cuda 安装目录
或者直接强制修改原始的软链接
sudo ln -sf cuda_path /usr/local/cuda //修改或创建软链接 /usr/local/cuda 使其指向指定版本的 cuda 目录
对于非 root 用户而言,主要通过第二种方法进行设置。若想要指定 Pytorch 使用的 cuda 版本,则首先需要设置 CUDA_HOME 环境变量,之后在 PATH 中加入指定 cuda 版本的可执行目录,也就时 cuda_path/bin/ 目录。完成设置后,运行 Pytorch 时所使用的即为对应的 cuda 版本。
实例
以笔者的服务器账户为例,笔者在 /home/test/cuda-10.1 目录中安装了 cuda-10.1 ,而服务器上的 /usr/local/cuda 目录指向的是之前安装的老版本的 cuda-8.0,直接运行 Pytorch 时,其会基于上面的确认流程直接使用老版本的 cuda .若想要临时设置 Pytorch 使用新安装的 cuda ,则可以通过 export 命令修改全局变量。这种设置方式在当前终端退出后即失效。
export CUDA_HOME=/home/test/cuda-10.1/ //设置全局变量 CUDA_HOME
export PATH=$PATH:/home/test/cuda-10.1/bin/ //在 PATH 变量中加入需要使用的 cuda 版本的路径,使得系统可以使用 cuda 提供的可执行文件,包括 nvcc
想要永久设置上述 cuda 设置,用户可以直接在自己的 bash 设置文件 ~/.bashrc 文件尾部加入上述命令,保存后再通过 source ~/.bashrc 执行文件,即可完成当前终端的环境变量修改。如果需要使用新的 cuda 来编译文件,还可以通过 LD_LIBRARY_PATH 变量指定进行链接的 cuda 库文件的路径。

位于 ~/.bashrc 文件中的指令在每次终端启动时均会自动运行,后续本用户所打开的终端中的环境变量均会首先执行上述文件中的命令,从而获得对应的 cuda 变量。
其他
获取 Pytorch 使用的 cuda 版本
目前,网络上比较多的资源会讨论如何获得 Pytorch 使用的 cuda 的版本的方法。比较主流的一种方法是使用 Pytorch 提供的方法 torch.version.cuda .
>>>import torch
>>>torch.version.cuda #输出一个 cuda 版本
如笔者环境下上述命令的输出如下图所示。

事实上,上述输出的 cuda 的版本并不一定是 Pytorch 在实际系统上运行时使用的 cuda 版本,而是编译该 Pytorch release 版本时使用的 cuda 版本。
torch.version.cuda 是位于 torch/version.py 中的一个变量, Pytorch 在基于源码进行编译时,通过 tools/setup_helpers/cuda.py 来确定编译 Pytorch 所使用的 cuda 的安装目录和版本号,确定的具体流程与 Pytorch 运行时确定运行时所使用的 cuda 版本的流程较为相似,具体可以见其源码( Pytorch 1.1.0, Line 66 ).在进行 Pytorch 源码编译时,根目录下的 setup.py 会调用上述代码,确定编译 Pytorch 所使用的 cuda 目录和版本号,并使用获得的信息修改 torch/version.py 中的 cuda 信息( Pytorch, Line 286 )。上述 torch.version.cuda 输出的信息即为编译该发行版 Pytorch 时所使用的 cuda 信息。若系统上的 Pytorch 通过 conda 安装,用户也可以直接通过 conda list | grep pytorch 命令查看安装的 Pytorch 的部分信息。
conda list | grep pytorch //查看安装的 Pytorch 的信息
笔者环境下上述命令的结果如图所示,可以看到显示的 cuda 信息与 torch.version.cuda 保持一致。

想要查看 Pytorch 实际使用的运行时的 cuda 目录,可以直接输出之前介绍的 cpp_extension.py 中的 CUDA_HOME 变量。
>>> import torch
>>> import torch.utils
>>> import torch.utils.cpp_extension
>>> torch.utils.cpp_extension.CUDA_HOME #输出 Pytorch 运行时使用的 cuda