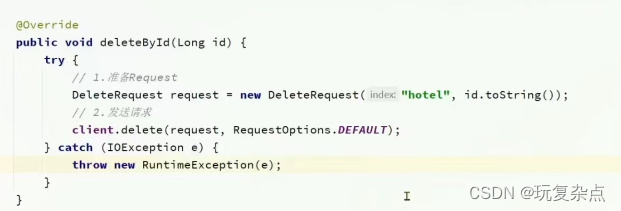
Go json 差异比较 json-diff(RFC 6902)
毕业设计中过程中为了比较矢量图的差异而依据 RFC 6902 编写的一个包,现已开源: Json-diff
使用
go get -u github.com/520MianXiangDuiXiang520/json-diff
序列化与反序列化
与官方 json 包的序列化和反序列化不同,官方包序列化需要指定一个 interface{}, 像:
package main
import "json"
func main() {
jsonStr := "{}"
var jsonObj interface{}
node := json.Unmarshal(&jsonObj, []byte(jsonStr))
// ...
}
json-diff 可以将任意的 json 串转换成统一的 JsonNode 类型,并且提供一系列的增删查改方法,方便操作对象:
func ExampleUnmarshal() {
json := `{
"A": 2,
"B": [1, 2, 4],
"C": {
"CA": {"CAA": 1}
}
}`
jsonNode := Unmarshal([]byte(json))
fmt.Println(jsonNode)
}
差异比较
通过对比两个 Json 串,输出他们的差异或者通过差异串得到修改后的 json 串
func ExampleAsDiffs() {
json1 := `{
"A": 1,
"B": [1, 2, 3],
"C": {
"CA": 1
}
}`
json2 := `{
"A": 2,
"B": [1, 2, 4],
"C": {
"CA": {"CAA": 1}
}
}`
res, _ := AsDiffs([]byte(json1), []byte(json2), UseMoveOption, UseCopyOption, UseFullRemoveOption)
fmt.Println(res)
}
func ExampleMergeDiff() {
json2 := `{
"A": 1,
"B": [1, 2, 3, {"BA": 1}],
"C": {
"CA": 1,
"CB": 2
}
}`
diffs := `[
{"op": "move", "from": "/A", "path": "/D"},
{"op": "move", "from": "/B/0", "path": "/B/1"},
{"op": "move", "from": "/B/2", "path": "/C/CB"}
]`
res, _ := MergeDiff([]byte(json2), []byte(diffs))
fmt.Println(res)
}
输出格式
输出一个 json 格式的字节数组,类似于:
[
{ "op": "test", "path": "/a/b/c", "value": "foo" },
{ "op": "remove", "path": "/a/b/c" },
{ "op": "add", "path": "/a/b/c", "value": [ "foo", "bar" ] },
{ "op": "replace", "path": "/a/b/c", "value": 42 },
{ "op": "move", "from": "/a/b/c", "path": "/a/b/d" },
{ "op": "copy", "from": "/a/b/d", "path": "/a/b/e" }
]
其中数组中的每一项代表一个差异点,格式由 RFC 6092 定义,op 表示差异类型,有六种:
add: 新增replace: 替换remove: 删除move: 移动copy: 复制test: 测试
其中 move 和 copy 可以减少差异串的体积,但会增加差异比较的时间, 可以通过修改 AsDiff() 的 options 指定是否开启,options 的选项和用法如下:
// 返回差异时使用 Copy, 当发现新增的子串出现在原串中时,使用该选项可以将 Add 行为替换为 Copy 行为
// 以减少差异串的大小,但这需要额外的计算,默认不开启
UseCopyOption JsonDiffOption = 1 << iota
// 仅在 UseCopyOption 选项开启时有效,替换前会添加 Test 行为,以确保 Copy 的路径存在
UseCheckCopyOption
// 返回差异时使用 Copy, 当发现差异串中两个 Add 和 Remove 的值相等时,会将他们合并为一个 Move 行为
// 以此减少差异串的大小,默认不开启
UseMoveOption
// Remove 时除了返回 path, 还返回删除了的值,默认不开启
UseFullRemoveOption
相等的依据
对于一个对象,其内部元素的顺序不作为相等判断的依据,如
{
"a": 1,
"b": 2,
}
和
{
"b": 2,
"a": 1,
}
被认为是相等的。
对于一个列表,元素顺序则作为判断相等的依据,如:
{
"a": [1, 2]
}
和
{
"a": [2, 1]
}
被认为不相等。
只有一个元素的所有子元素全部相等,他们才相等
原子性
根据 RFC 6092,差异合并应该具有原子性,即列表中有一个差异合并失败,之前的合并全部作废,而 test 类型就用来在合并差异之前检查路径和值是否正确,你可以通过选项开启它,但即便不使用 test,合并也是原子性的。
json-diff 在合并差异前会深拷贝源数据,并使用拷贝的数据做差异合并,一旦发生错误,将会返回 nil, 任何情况下都不会修改原来的数据。
实现
本章节主要介绍Json-Diff 算法以及完整实现过程,该算法包含三部分内容,分别是用来序列化和反序列化Json 字符串的格式化模块;用于比较两个Json字符串差异的差异比较模块,用于合并差异的差异合并模块,三个模块的关系如下图4.1所示:
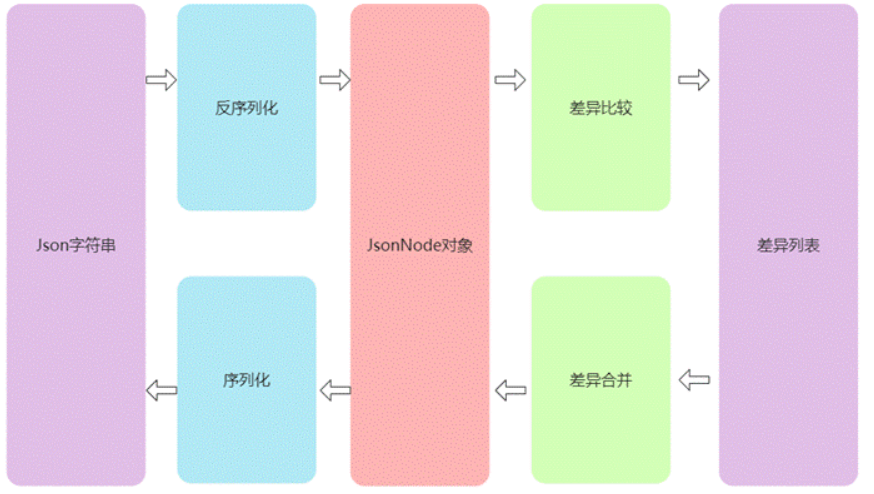
格式化
Json 的特点
Json 全称JavaScript Object Notation[12](JavaScript对象标记法)是一种轻量级的数据交换格式,一般以文本的形式存储或传输,具有较高的可读性,它有构造字符,值,空白符组成,其中,构造字符有六个,分别是:“{”, “}”, “[”, “]”, “,”和“:”.Json中值也有六种,分别是数字,布尔,字符串,列表,对象和null, 此外构造字符前后允许多个空白符,他们没有任何意义,主要用于提高可读性,这些空白符包括回车,换行,空格,制表。
Json的六种值中,数字,字符串,布尔和null是四个基本类型,列表和对象由这些基本类型组合而成,其中,数字类型可以包括正数,负数,虚数,小数等,也可以使用科学计数法表示,如“2e3”;字符串类型由一对英文引号包围,可以是单引号也可以是双引号,但不能使用反引号 “`”;布尔包括两个值true和false,区分大小写;null 类似于布尔,属于内建类型,表示空。
Json中对象由“{}”表示,对象中的每一项由键,值和构造字符“:”组成,其中键必须是字符串类型,而值可以是六种值中的任意一种,键值之间使用构造字符“:”连接,同一对象中的多个键值对之间使用构造字符“,”分隔,如果某键值对是该对象中的最后一项,值后面则不允许使用“,”一个典型的“对象”如下所示:
{
"a": 1e2,
"b": "1e2",
"c": false,
"d": null,
"e": {},
"f": []
}
值得注意的是对象中的键值对是无序的,如{"a":1, "b":2}和{"b":2, "a":1}被认为是相等的。
Json中列表由[]表示,列表中的元素同样可以是六种值中的任意一种,值与值之间使用构造字符,分隔,最后一个值不允许携带,一个典型的列表如下所示:
[1e2, "1e2", false, null, {}, []]
列表中的元素是有序的,也就是说“[1, 2]”和“[2, 1]”是不相等的。
反序列化
Json本质上来说就是一种特殊格式的字符串,要想得到两个Json串的差异,最简单的办法就是一一对比两个字符串每一位上的字符,但这种算法无法利用Json的有序性,可能导致得到的差异列表过大,甚至可能超过原Json串,适得其反,并且逐一比较也会导致过高的时间复杂度,浪费大量时间。因此需要将Json字符串转换为特定的数据结构,再递归比较对象的每个键值对。
根据上面的介绍,不难发现,Json是一个树型结构,对象({})和列表([])构成了这棵树的非叶子节点,他们可以包含一个和多个子节点,每个子节点由键和值组成(列表的键可以看作是下标);而字符串,数值,布尔,null等无法包含子节点的对象构成了这棵树的叶子节点(空的列表或对象也可以作为叶子节点)。
因此,本系统Json对象分成三类:Object,Slice和Value,分别用来表示对象,列表及其他类型的值,这三类都由JsonNode类派生而来,他们的公共属性包括:
-
Type: uint8类型,用来标识该节点的类型。
-
Hash: 该节点的哈希值,第一次比较到该节点时,会递归计算该节点包括其所有子节点的哈希值,到第二次需要比较该节点时,只需要比较其哈希值即可。
-
Value: 该节点的值,类型是interface{},因此可以用来存储六种值类型中的任意一种。
-
Level: 该节点在整颗Json树中所处的层级。
-
Key: 用来保存该值对应的Key,可为空。
除此之外,Object类型的节点还包含ChildrenMap字段,它的类型为map[string]interface{},用来存储该节点的所有子节点,其中,Object的Key作为ChildrenMap的Key, Object的Value作为ChildrenMap的Value,由于Go中的map本身是无序的,正好对应Json的Object无序的特点,且map底层使用的是开放地址的哈希表,因此其查询效率是O(1), 这将大大提高比较的速度。:
类似的,Slice类型的节点也包含Children字段,其类型为[]interface{}, 用来表示列表中的所有子元素,由于Go中的切片([]interface{})是有序的,正好可以满足Json数组有序的要求。
为了方便后续的差异比较和差异合并,JsonNode还提供了一系列增删查改的方法,如下:
-
Find: 用来根据路径找到对应的节点,它接收一个字符串类型的路径,并返回一个JsonNode对象的引用,如果找不到,返回nil.
-
Add: 如果该节点是Object或Slice类型,Add将一个新的节点作为其子节点。
-
Replace: 接收一组key和value, 用来将该节点下key对应的值替换为value并返回旧值,如果当前节点是Object类型,key应该是string类型,如果当前节点是Slice类型,key应该是int类型,用来表示要替换的值的下标,如果没找到对应的值,返回一个Not Find异常。
-
Remove: 删除当前 JsonNode 中 key 对应的节点并返回被删除的值,该方法只能删除父节点的某个子节点,节点不能删除它自己,因此,Value类型的节点不能使用 Remove 方法。
-
Equal: 用来判断给定的JsonNode是否与当前节点相等。
除了上面这五个JsonNode的方法外,为了方便对JsonNode进行操作,还提供了下面几个公共函数:
-
CopyPath: 接受两个string类型的path1和path2,用来将path1对应的值复制到path2.
-
MovePath: 接受两个string类型的path1和path2,用来将path1对应的值移动到path2.
-
ATestPath: 用来判断给定路径处的值是否等于给定的值。
-
AddPath: 用来给某个路径对应的值添加一个新节点。
-
ReplacePath: 用一个新值替换源路径对应的值。
-
RemovePath: 用来删除某路径对应的值。
以上六个函数实质上是对JsonNode五个基本方法的进一步封装,但在减少后续工作代码量,提高代码可读性和降低系统复杂度上,他们起了重要作用。
反序列化具体实现
Go语言官方本身提供了一个Json序列化和反序列化的包json, 但它只能将Json字符串反序列化为一个已知的对象或map,且无法对序列化好的对象进行操作,由于本系统的Json都是动态生成的,无法用确定的数据结构来表示,同时本系统需要对反序列化后的对象进行大量操作,因此官方的json包不能满足要求,本系统的反序列是在使用官方包将json字符串转换为map后,对该map对象进行遍历得到的,首先介绍官方json包反序列化的规则:
-
对象会被转换为map[string]interface{}
-
数组会被转换为[]interface{}
-
数值会根据具体值转化为int或float
-
布尔会转换为bool
-
Null会转换为nil
-
字符串会转换为string
由于每个Json都是一个对象,所以最终的转换结果就是一个map,如下面这个json字符串:
{
"a": 1e2,
"d": null,
"c": {
"ca": false,
"cb": {},
"cc": [1, "e", {}]
},
}
就会被转换为:
map[a:100 b:<nil> c:map[ca:false cb:map[] cc:[1 e map[]]]]
然后通过遍历该map内的所有元素,就可以将其转换为我们需要的JsonNode对象,具体parse方法如下:
如果遍历到map类型的元素,就建立一个Object类型的节点root,并再遍历该map内的所有元素,对每一个遍历到的元素递归调用parse方法,将得到的的JsonNode作为root的一个子节点。
如果遍历到slice类型的元素,就建立一个Slice类型的节点root,同样对切片内的每一个元素递归调用parse, 将得到的节点追加到root的Children里。
否则,如果遍历到的元素不属于上面两种,就建立一个Value类型的节点,将值保存到该节点的Value中,并将该节点添加到其父节点的ChildrenMap中。
如上面的例子经过parse就会转化成如图4.2的树:
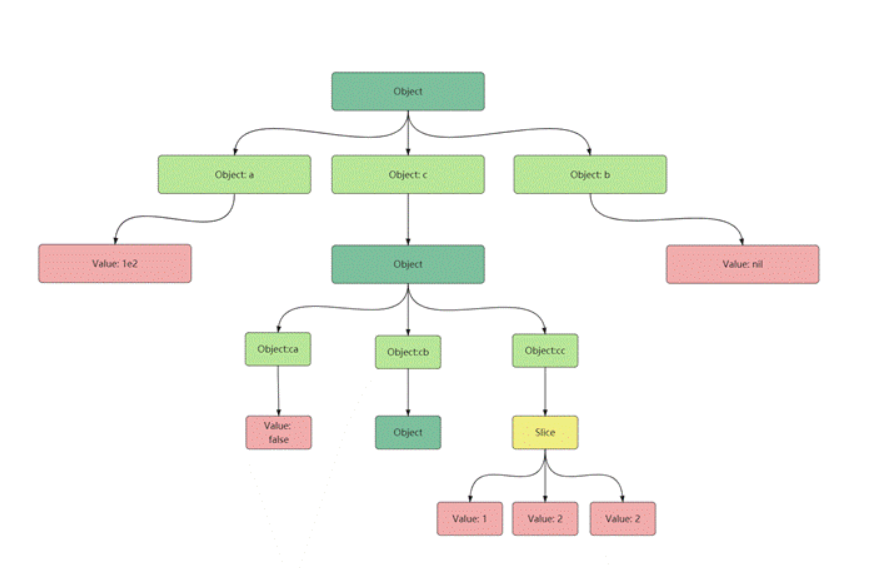
序列化
序列化相比反序列简单的多,它的目的是将JsonNode对象转换为Json字符串,实现的具体思路是先将JsonNode对象转换为map,再使用官方的json包实现序列化,JsonNode转map主要还是使用递归的思想,主要由三个函数实现,其中前两个是递归函数:
-
marshalObject:用来将一个Object类型的节点序列化成map,他会先创建一个新map,然后遍历该节点的ChildrenMap,然后根据子节点的类型调用对应的序列化函数,比如遍历到Object类型的节点,就递归调用 marshalObject,如果遍历到Slice类型,就调用marshalSlice得到序列化后的结果,并将其保存在新创建的map中。
-
marshalSlice:与marshalObject类似,它会新创建一个slice, 然后遍历该节点的Children, 对其中的每一个子节点根据节点类型调用不同的方法得到序列化后的结果并将之保存在slice中。
-
marshalValue: 用于将Value类型的节点序列化,由于Value类型没有子节点,只需要返回JsonNode.Value即可。
路径转义
在本系统设计中,使用斜杠“/”作为路径分隔符,如“/a/b/1”表示从根节点出发,找到其key为a的子节点,再找到子节点的key为b的子节点,再找到该孙子节点的key(或下标,取决于孙子节点是Object类型还是Slice类型)为1的节点。但Json自身没有限制key中的特殊字符,也就是 { " a/b":1}是完全合法的,为了避免原来key中包含斜杠导致分隔错误,需要对原Json字符串中的Key做转移,具体做法如下:
将原来Key中包含的所有斜杠转义为~1,将原来Key中包含的~1全部转义为~01,原来的~01转义为~001……每次转义都添加一个0,比如原来有一个Key为a/~01b就会被转义为a~1~001b,在最后差异合并时,只需要去掉0即可得到原来的Key,具体实现比较简单,可以使用正则匹配加字符串替换实现。
格式化总结
本系统的格式化模块包含序列化和反序列化两个子模块,提供了两个公共方法:Unmarshal和Marshal,分别用于将Json字符串转换为JsonNode对象和将JsonNode对象转换回Json字符串,JsonNode对象提供了许多方法以实现对Json的动态修改,方便后续操作。
差异比较
差异比较是基于上一章节的反序列化实现的,其核心工作是比较两个JsonNode对象src(表示原Json串)和tar(表示改变后的Json串)的差异,并输出一个Json格式的差异报告告诉用户tar可以在src的基础上进行了些操作后得到。,本章节将从输出格式以及比较算法两个方面介绍差异对比模块的具体实现。
输出格式
首先为了降低Diff算法的可移植性,该系统同样使用Json作为最终的输出格式,由于每次比较会有多个差异,所以输出结果应该是一个列表,列表中的每一项表示一处差异,类似于下面这样 [{}, {}, {}, {}, {}] 表示比较后得到了五处差异, 每一项中应该包含以下内容:
-
Op: 表示差异类型;可选值有add, remove, replace, copy, move, test六种;对一个数据的操作无非增、删、查、改四种,而对于差异比较来说,定义增、删、改三种操作即可,在此基础上,添加拷贝和移动两种复合操作,但他们可以使用增和先增后删表示,但使用复合操作可以进一步减少最终输出的数据量。除此之外 test 用于保证后面差异合并时的原子性,会在下一章节介绍。
-
Path:表示差异发生的位置,Path是针对src而言的。
-
Value:主要用于增加和修改操作,用来表示新增的值和要修改的新值,Test也会携带该字段,主要用来比较,保证原子性;另外,删除操作如果携带该参数表示被删除的值。
-
From:用于拷贝和移动操作,表示被拷贝或移动的数据来自哪个路径。
所以,差异比较后的输出应该类似于下面这样:
[
{ "op": "add", "path": "/a/b/c", "value": "{}" },
{ "op": "remove", "path": "/a/b/c" },
{ "op": "raplace", "path": "/a/b/c", "value": {} },
{ "op": "move", "from": "/a/b/c", "path": "/a/b/d" },
{ "op": "copy", "from": "/a/b/d", "path": "/a/b/e" }
{ "op": "test", "path": "/a/b/c", "value": {"d": 1} }
]
实现概述
本系统提供一个公共函数AsDiff,他接受src和tar两个Json比特串和一组控制选项,并且返回两个值res和error 分别表示差异比较结果和过程中发生的错误,正常情况下,error应该是空的(nil),一旦比较过程出现异常,就会将异常作为返回值返回,而res会被置为nil.
能够传入的控制参数有四个,分别是:
-
UseCopyOption:启用Copy,如果传入该参数,差异比较后会遍历整个结果集中的add操作,如果该操作对应的值能在src中找到,就使用copy替代该add操作,启用该选项会减少结果集大小但也会增加差异比较的时间,默认不开启。
-
UseCheckCopyOption:仅在Copy选项开启时有效,他会在Copy操作前插入一条Test操作,表示合并时检查值是否相等,只有值相等才继续合并。
-
UseMoveOption:启用Move,如果传入该选项,差异比较结束后会遍历所有的add和remove操作,如果找到add的值和remove的值相等,则使用move替换add操作,并删除remove操作,该选项同样是以时间换空间,开启后会减少结果集大小,但同样会增加比较时间,默认不开启。
-
UseFullRemoveOption:开启该选项后,remove操作将携带value,表示被删除的值,开启后会增加结果集大小,默认不开启。
使用者可以权衡业务数据的特点选择是否开启这四个选项。
AsDiff会对接收到的src和tar做反序列化,然后调用GetDiffNode对两个JsonNode对象做差异比较,GetDiffNode方法调用了diff做差异比较,并根据可选选项对结果集做进一步处理,所以diff方法是差异比较的核心,diff首先会进行边界条件的判断,如src和tar中src为空对象,但tar不为空,就可以直接得出并返回add操作,反之,如果src不为空,tar为空,也可以直接得出并返回remove操作,如果两者都为空,也可以断言未发生任何修改,应该返回空的结果集;如果二者都不为空,则使用下面的策略具体比较二者差异:
-
如果二者都是Object类型,调用diffObject方法比较差异。
-
如果二者都是Slice类型,调用diffSlice方法比较差异。
-
如果二者都是Value类型,判断值是否相等,如果不相等,则产生一个replace操作,并将其追加到结果集中。
-
如果二者类型不相等,直接生成一个replace操作,值为tar的值。
diffObject和diffSlice是两个递归函数,他们会根据不同的策略递归调用diff来比较其中的子节点,直到得出最终的结果。
而对可选选项的处理会在doOption函数中完成,后续章节会介绍这三个主要函数的具体实现。
Object差异比较
两个Object类型节点的差异比较由递归函数diffObject实现,diffObject首先会遍历src中的每一组键值对,然后根据遍历到的键去tar的ChildrenMap中找tar中该键对应的值,如果没找到,则说明tar之于src删除了该键值对;如果找到,则判断两个节点是否相等,不相等再根据值得类型递归调用diff比较值的差异,遍历完src之后,会同样遍历一遍tar的ChildrenMap, 如果src的子节点中没有找到该Key, 则说明tar之于src通过add操作增加了值。不同的是,遍历tar时不需要判断两个节点是否相等,也不需要递归调用diff进行比较。也就是说,通过遍历src,可以找到关于这个节点的所有删除和更新操作,而遍历tar可以找到关于这个节点的所有添加操作。
Slice差异比较
Slice类型的节点比较需要考虑顺序,考虑到会出现下面这种情况:
Src: [1, 2, 3, 4, 5]
Tar: [1, 3, 4, 5]
如果继续按照Object类型比较的思路,从左到右逐一遍历比较,那么得到的差异结果就是第一位由2变成了3,第二位由3变成了4,第三位由4变成了5,删除了第五位。即便是开启move选项,差异结果也会包含四条记录,但实际上,上面的例子可以直接看作删除了第一位,这样差异结果只包含一条记录,可以大大减少结果集的大小。除此之外,Slice的子节点使用列表存储,列表查询时间复杂度为O(n), 如果继续采用Object的比较方法,总复杂度会达到O(n2),为此,本系统在比较Slice类型的节点时,会先使用动态规划[16]求出两个节点Children的最长公共子序列[17][18]lcsNodes, 然后根据该序列再与src和tar对比得到最终差异数据,具体方法如下:
一个序列的子序列是指在不改变原序列中元素顺序的情况下从原序列中删除零个或多个元素所得到的子序列,如有原序列S1={1, 2, 3, 4},在不改变顺序的情况下从中删除第一号元素后得到新的序列S2={1, 3, 4},那么就说S2是S1的一个子序列,而S3={2, 1, 4}由于改变了元素顺序,所以S3不是S1的子序列;最长公共子序列是指给定两个序列L1,L2,分别设他们的全部子序列集合为S1和S2,那么L1,L2的最长公共子序列LCS就是S1和S2的交集中元素个数最多的那个,记为:
KaTeX parse error: Undefined control sequence: \and at position 15: LCS = Max(S1 \̲a̲n̲d̲ ̲S2)
求两个序列最长公共子序列一般使用动态和规划法,之所以可以使用动态规划,是基于该问题的以下特征:
设给定两个序列A={a1, a2, …, an}和B={b1, b2, …, bm},他们的最长公共子序列为S={s1, s2, …, sk}那么:
-
若an=bm 则an=sk=bm且必定存在S2={s1, …, sk-1} 是序列A2={a1, …, an-1}和序列B2={b1, …, bm-1}的最长公共子序列。
-
若an!=bm且an!=sk则S必然是序列A2={s1, …, sk-1}和序列B={b1, b2, …, bm}的最长公共子序列。
-
若an!=bm且bm!=sk则S必然是序列A={a1, a2, …, an}和序列B2={b1, …, bm-1}的最长公共子序列。
根据上面三条特征,可以发现两个序列的最长公共子序列实质上是他们子串的最长公共子序列再加上剩余的公共元素组成的,因此该问题可以转换为求两个序列子串的最长公共子序列的子问题,这使得该问题具备了动态规划的重叠子问题和最优子结构的性质[16],其状态转移方程如下所示:
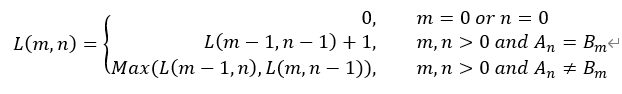
其中,AB表示要求解的两个序列,m, n表示两个序列的长度,An (Bm)表示序列A (B) 中从第0位到第n (m)位的子串;L(m, n)表示An和Bm的最长公共子序列的长度。
假设序列A, B 分别为{1, 2, 3, 4, 5, 9}和{1, 3, 5, 7, 8},根据以上状态转移方程,可得如表4.1所示的DP数组:
表4.1 DP数组
| 1 | 2 | 3 | 4 | 5 | 9 | |
|---|---|---|---|---|---|---|
| 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 3 | 1 | 1 | 2 | 2 | 2 | 2 |
| 5 | 1 | 1 | 2 | 2 | 3 | 3 |
| 7 | 1 | 1 | 2 | 2 | 3 | 3 |
| 8 | 1 | 1 | 2 | 2 | 3 | 3 |
数组中的元素DP[i][j]就表示L[i][j], 最后一个元素表示的就是要求的两个序列的最长公共子序列的长度,根据DP数组中每一位都表示其对应两个子串的最长公共子序列,所以,设右下角的坐标为只需要从DP数组的右下角按以下规则寻找即可找到原序列的最长公共子序列:
-
若DP[x] [y]等于DP[x-1] [y]且DP[x] [y]等于DP[x] [y-1],如上例中的(4, 5)位置,说明8和9都不属于最终的公共子序列,则沿对角线向上移动(x和y都减1)。
-
若DP[x] [y]等于DP[x-1] [y]但DP[x] [y]不等于DP[x] [y-1],则向上移动(x减1)
-
若DP[x] [y]不等于DP[x-1] [y]但DP[x] [y]等于DP[x] [y-1],则向左移动(y减1)
-
若DP[x] [y]不等于DP[x-1] [y]且DP[x] [y]不等于DP[x] [y-1],如上例(0, 1), (1, 2)和(2, 3)位置,说明他们对应的1,3,5是最终的公共子序列,只不过这样得到结果的顺序正好是反着的,需要在返回时反转一遍。
找出最长公共子序列后,就可以对比src, tar以及lcs得出两个Slice类型节点的差异了:
把节点Children中的子节点抽象为简单的数字,假设比较的两个节点的值分别为src=[1, 2, 3, 4, 5]和tar=[1, 3, 4, 5, 6],那这两者计算得到的lcs=[1, 3, 4, 5], 使用三个指针同时从头遍历src, tar和lcs如果三个指针对应的值都相等,则说明该对象未发生改变,三个指针同时向后移动一位,如果lcs指针与src指针对应的值相等,但与tar对应的值不相等,说明tar在src的基础上插入了一个新值,就往结果集中添加一条add操作,同时lcs和src指针保持不变,tar指针向后移动一位;如果lcs指针对应的值和tar指针对应的值相等但与src对应的不相等,说明tar在src的基础上删除了一个值,就往结果集中插入一条删除操作,同时src指针向后移动一位,直到lcs遍历结束。由于lcs的长度一定小于或等于src或tar的长度,lcs遍历完后src和tar中可能还有未被遍历到的子节点,如果src和tar中都有没被遍历的值,那就可以看作是修改操作,如果src中没遍历的节点数多于tar中的,那多出来就可以看作是被删除的,反之少的就可以看作是新添加的
Value差异比较
前面的diffObject和diffSlice对比的只是子节点的差异,但子节点的比较最终会落在具体值的比较上,Value的差异比较只涉及修改,不涉及增删,只需要判断二者值是否相等,不相等即是产生了修改操作,在diff函数中实现。
Copy和Move合并
如果在执行AsDiff时传入了Copy和Move选项,差异比较结束后还要遍历整个结果集,看是否有操作可以合并成Copy或Move。
Copy合并是看结果集中add操作的value是否可以使用一个路径替换,为此必须找到两个Json串中未被修改的部分,然后看每一个add操作的value是否可以在这个未被修改的序列中找到,寻找未修改部分的过程与Object差异比较的过程类似,寻找Slice中未改变的节点时,必须考虑后续操作对路径的影响,因此不能像Slice差异比较那样使用最长公共子序列,只能按下标一一对比。找到未修改的序列后,遍历结果集中的add操作就可以找到可以使用Copy替换的操作了。
Move合并是看结果集中是否有删除操作的值和添加操作的值相等,只需要两重循环遍历两种操作类型的值即可,在这过程中,可以对一方的值做哈希,然后以哈希值为key建立缓存,比较前先查询缓存,判断是否能找到,命中后再去比较具体的值,以此降低时间复杂度。
差异比较总结
差异比较主要用于找到两个Json串之间的差异,并输出一个标准的比较结果,主要由差异比较和结果集合并两部分组成,前者用来找到两个Json串中基本的增删改操作,后者根据可选选项将可能的增删合并为Copy和Move。
差异合并
差异合并主要是根据原Json串和通过差异比较得到的差异列表还原出修改后的串,他需要满足顺序性、准确性和原子性的要求,所谓顺序性和准确性是指合并的过程应该严格按照差异列表中的操作顺序执行,保证结果的正确性,而原子性是要求合并过程中一旦有一个操作出错,那整个合并过程应该立刻停止并将原串还原到执行合并前的状态。
由于输入的差异列表本来就是一个有序列表,所以顺序性和准确性很容易保证,这部分功能实现主要依赖于JsonNode对象的一系列怎删改查方法,这些方法在本章第一节已经有所介绍,不再赘述。而为了保证原子性,就不能直接对原串进行修改,需要复制一份原串的副本,然后对该副本进行修改,一旦发生错误,就返回原串丢弃副本,而如果一帆风顺,也只需要使用副本覆盖原串即可。
深拷贝的母的是得到与原来JsonNode完全一致的一份副本,一般深拷贝都使用序列化再反序列实现,具体就是先将对象序列化成json或其他中间格式,再将中间格式反序列化出一个新对象,这种做法的优点是实现简单,代码量少且适用性强,缺点是速度慢,考虑到本项目中深拷贝只用于拷贝JsonNode对象,不需要很强的适用性,为了更好的性能,本系统通过深度优先遍历逐一复制每一个子节点,为JsonNode对象实现了一个专用的深拷贝方法,
总结
Json-Diff主要由格式化,差异比较,差异合并三个模块组成:
格式化模块按照Json的特点将其中的对象分为Object, Slice和Value三种,前两者包含子对象,Object中的子对象无序,Slice中的子对象有序,并且将这三种对象都抽象为统一的JsonNode对象;在官方json包的基础上,格式化模块提供了序列化和反序列化方法,用于实现Json字符串和JsonNode对象之间的互相转换。
差异比较模块根据节点类型的不同,使用不同的比较策略,针对Object和Slice类型,只比较他们的子节点,由于Object无序,可以使用哈希表存储,比较时根据key获取value比较即可,Slice是有序的,暴力比较会导致很高的时间复杂度和很庞大的输出,因此先通过动态规划求出LCS,再遍历LCS得到最后的差异列表。
差异合并主要使用JsonNode的增删查改方法,为了保证原子性,实现了一个基于DFS的深拷贝方法,合并差异时先合并到拷贝的副本上,中途一旦出错,就丢弃副本返回原Json串,如果全部合并成功,再使用副本覆盖原串。
参考
https://github.com/flipkart-incubator/zjsonpatch