参考文章:rnn循环神经网络介绍
循环神经网络 (RNN) 是一种专门处理序列的神经网络。它们通常用于自然语言处理 (NLP) 任务,因为它们在处理文本方面很有效。在这篇文章中,我们将探讨什么是 RNN,了解它们是如何工作的,并在 Python 中从头开始(仅使用 numpy)构建一个真正的 RNN。
这篇文章假设你对神经网络有基本的了解。
我的另一篇文章(从零开始实现神经网络(一)_NN神经网络)涵盖了你需要知道的一切,所以我建议先阅读它。
让我们开始吧!
一. 使用rnn的原因
普通神经网络(以及CNN)的一个问题是,它们只在预定大小的情况下工作:它们接受固定大小的输入并产生固定大小的输出。RNN 很有用,因为它们让我们可以将可变长度的序列作为输入和输出。以下是 RNN 的几个示例:
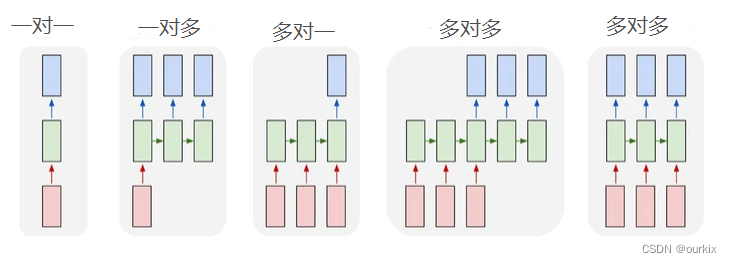
输入为红色,RNN 本身为绿色,输出为蓝色
这种处理序列的能力使得RNN非常有用。例如:
- 机器翻译(例如谷歌翻译)是用“多对多”RNN完成的。原始文本序列被输入到 RNN 中,然后生成翻译后的文本作为输出。
- 情感分析(例如,这是正面评论还是负面评论?)通常使用“多对一”RNN来完成。要分析的文本被输入到RNN中,然后生成单个输出分类(例如,这是一个正面评论)。
在本文的后面,我们将从头开始构建一个“多对一”的 RNN 来执行基本的情感分析。
二. 如何实现rnn
让我们考虑一个带有输入的“多对多”RNN ,输入是x0,x1,x2.......xn,想要产生输出y0,y1,y2......yn.这些xi和yi是向量,可以具有任意维度。
RNN 通过迭代更新隐藏状态(h)来工作,这也是一个可以具有任意维度的向量。在任何给定步数(t)时
- 下一个隐藏状态 ( ht )使用先前的隐藏状态( ht-1)和下一个输入xt进行计算。举例:如果要求h2的值,那么就是h1和x2的值进行计算得出。
- 下一个输出yt是由ht计算得来.
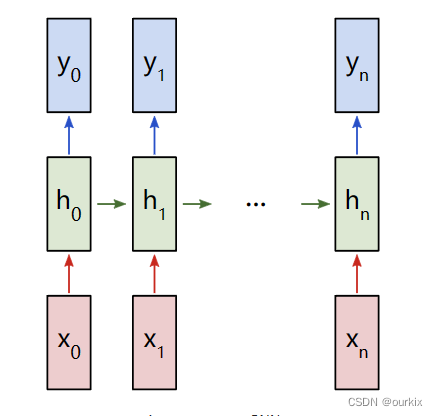
这就是 RNN 循环的原因:它对每个步骤使用相同的权重。更具体地说,一个典型的 vanilla RNN 只使用 3 组权重来执行其计算:
,权重用于所有
→
之间的运算。
,权重用于所有
→
,权重用于所有
之间的运算。
我们还将对 RNN 使用两种偏差:
,在计算
,在计算
我们将权重表示为矩阵,将偏差表示为向量。这 3 个权重和 2 个偏差构成了整个 RNN!
以下是将所有内容组合在一起的方程式:
不要略过这些方程式。停下来盯着它看一分钟。另外,请记住,权重是矩阵,其他变量是向量
使用矩阵乘法应用所有权重,并将偏差添加到所得产品中。然后我们使用 tanh 作为第一个方程的激活函数(但也可以使用其他激活,如 sigmoid)。
三. rnn要解决的问题
让我们亲自动手!我们将从头开始实现一个 RNN 来执行一个简单的情感分析任务:确定给定的文本字符串是正向情感的还是负向情感。
以下是我为这篇文章整理的小型数据集中的一些示例:
| 文本字符串 | 正向? |
|---|---|
| i am good | ✓ |
| i am bad | ❌ |
| this is very good | ✓ |
| this is not bad | ✓ |
| i am bad not good | ❌ |
| i am not at all happy | ❌ |
| this was good earlier | ✓ |
| i am not at all bad or sad right now | ✓ |
四. 使用方案
由于这是一个分类问题,我们将使用“多对一”RNN。这类似于我们之前讨论的“多对多”RNN,但它只使用最终的隐藏状态来产生一个输出y:
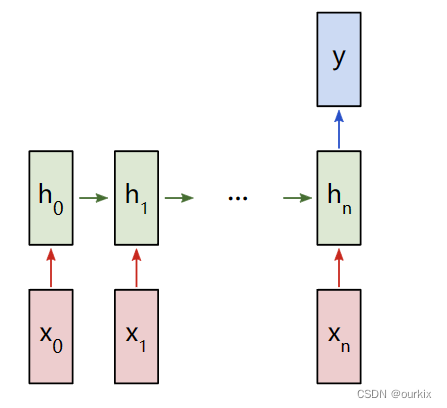
每个将是一个向量,表示文本中的单词。输出 y 将是一个包含两个数字的向量,一个表示正数,另一个表示负数。我们将应用 Softmax 将这些值转换为概率,并最终在正/负之间做出决定。
让我们开始构建我们的 RNN!
五. 预处理
我前面提到的数据集由两个 Python 字典组成,True = 正,False = 负
#this file is data.py
train_data = {
'good': True,
'bad': False,
# ... more data
}
test_data = {
'this is happy': True,
'i am good': True,
# ... more data
}我们必须进行一些预处理,以将数据转换为可用的格式。首先,我们将构建数据中存在的所有单词的词汇表:
#this file is main.py
from data import train_data, test_data
# Create the vocabulary.
vocab = list(set([w for text in train_data.keys() for w in text.split(' ')]))
vocab_size = len(vocab)
print('%d unique words found' % vocab_size) # 18 unique words foundvocab现在包含至少一个训练文本中出现的所有单词的列表。接下来,我们将分配一个整数索引来表示词汇中的每个单词。
#this file is main.py
# Assign indices to each word.
word_to_idx = { w: i for i, w in enumerate(vocab) }
idx_to_word = { i: w for i, w in enumerate(vocab) }
print(word_to_idx['good']) # 16 (this may change)
print(idx_to_word[0]) # sad (this may change)现在,我们可以用其相应的整数索引来表示任何给定的单词!这是必要的,因为 RNN 无法理解单词——我们必须给它们数字。
最后,回想一下每个输入 我们的RNN是一个向量。我们将使用 one-hot (独热)向量,它包含除了一个是 1 之外其他都为零的向量。每个 one-hot 向量中的“one”将位于单词的相应整数索引处。
由于我们的词汇表中有 18 个独特的单词,因此每个单词将是一个 18 维的独热向量。
#this file is main.py
import numpy as np
def createInputs(text):
'''
Returns an array of one-hot vectors representing the words
in the input text string.
- text is a string
- Each one-hot vector has shape (vocab_size, 1)
'''
inputs = []
for w in text.split(' '):
v = np.zeros((vocab_size, 1))
v[word_to_idx[w]] = 1
inputs.append(v)
return inputs我们稍后将使用向量输入来传递到我们的 RNN。createInputs()
六. 前向传播
是时候开始实现我们的 RNN 了!我们将首先初始化我们的 RNN 需要的 3 个权重和 2 个偏差:
#this file is rnn.py
import numpy as np
from numpy.random import randn
class RNN:
# A Vanilla Recurrent Neural Network.
def __init__(self, input_size, output_size, hidden_size=64):
# Weights
self.Whh = randn(hidden_size, hidden_size) / 1000
self.Wxh = randn(hidden_size, input_size) / 1000
self.Why = randn(output_size, hidden_size) / 1000
# Biases
self.bh = np.zeros((hidden_size, 1))
self.by = np.zeros((output_size, 1))注意:我们将除以 1000 以减少权重的初始方差。这不是初始化权重的最佳方法,但它很简单,适用于这篇文章。
我们使用 np.random.randn() 从标准正态分布初始化我们的权重。
接下来,让我们实现 RNN 的前向传播。还记得我们之前看到的这两个方程式吗?
以下是代码实现这个方程式:
#this file is rnn.py
class RNN:
# ...
def forward(self, inputs):
'''
Perform a forward pass of the RNN using the given inputs.
Returns the final output and hidden state.
- inputs is an array of one-hot vectors with shape (input_size, 1).
'''
h = np.zeros((self.Whh.shape[0], 1))
# Perform each step of the RNN
for i, x in enumerate(inputs):
h = np.tanh(self.Wxh @ x + self.Whh @ h + self.bh)
# Compute the output
y = self.Why @ h + self.by
return y, h很简单,对吧?请注意,我们初始化了 h 到第一步的零向量,因为没有上一步 h 我们可以在当前节点上使用。
#this file is main.py
# ...
def softmax(xs):
# Applies the Softmax Function to the input array.
return np.exp(xs) / sum(np.exp(xs))
# Initialize our RNN!
rnn = RNN(vocab_size, 2)
inputs = createInputs('i am very good')
out, h = rnn.forward(inputs)
probs = softmax(out)
print(probs) # [[0.50000095], [0.49999905]]如果您需要复习 Softmax,请阅读我当前系列的cnn文章,里面有详细介绍。
我们的 RNN 有效,但还不是很有用。让我们改变一下......
七. 反向传播
为了训练我们的RNN,我们首先需要一个损失函数。我们将使用交叉熵损失,它通常与 Softmax 配对。以下是我们的计算方式:
pc是我们的 RNN 对正确类别(正或负)的预测概率。例如,如果我们的 RNN 预测一个正文本为 90%,则损失为:
想要更长的解释吗?阅读我的CNN中的交叉熵损失部分。
现在我们有一个损失,我们将使用梯度下降来训练我们的 RNN,以尽量减少损失。这意味着是时候推导出一些梯度了!
⚠️ 以下部分假定您具备多变量微积分的基本知识。如果你愿意,你可以跳过它,但我建议你略读一下,即使你不太了解。在得出结果时,我们将逐步编写代码,即使是表面的理解也会有所帮助。
7.1 定义
首先,定义一些变量:
- 让 y 表示 RNN 的原始输出。
- 让 p 表示最终概率:
- 让 c 引用某个文本样本的真实标签,也称为“正确”类。
- 让 L 是交叉熵损失:
- 让
- 让
7.2 设置
接下来,我们需要修改我们的正向传播,以缓存一些数据以在反向传播使用。与此同时,我们还将为反向传播搭建骨架。
rnn.py
class RNN:
# ...
def forward(self, inputs):
'''
Perform a forward pass of the RNN using the given inputs.
Returns the final output and hidden state.
- inputs is an array of one-hot vectors with shape (input_size, 1).
'''
h = np.zeros((self.Whh.shape[0], 1))
self.last_inputs = inputs
self.last_hs = { 0: h }
# Perform each step of the RNN
for i, x in enumerate(inputs):
h = np.tanh(self.Wxh @ x + self.Whh @ h + self.bh)
self.last_hs[i + 1] = h
# Compute the output
y = self.Why @ h + self.by
return y, h
def backprop(self, d_y, learn_rate=2e-2):
'''
Perform a backward pass of the RNN.
- d_y (dL/dy) has shape (output_size, 1).
- learn_rate is a float.
'''
pass是不是好奇我们为什么要做这个缓存?在前面cnn的章节中有相关解释
7.3 梯度(求偏导)
现在是数学时间!我们将从计算开始.
我们知道:
我将留下使用链式法则:
这里假设当前要计算的索引值的i,那么当i是正确的类c时,有:
例如,如果我们有p=[0. 2,0. 2,0.6],正确的类是c=0,那么我们会得到=[−0.8,0.2,0.6]。这也很容易转化为代码:
# Loop over each training example
for x, y in train_data.items():
inputs = createInputs(x)
target = int(y)
# Forward
out, _ = rnn.forward(inputs)
probs = softmax(out)
# Build dL/dy
d_L_d_y = probs
d_L_d_y[target] -= 1
# Backward
rnn.backprop(d_L_d_y) 好。接下来,让我们来看看偏导和
,仅用于将最终的隐藏状态转换为 RNN 的输出。我们有
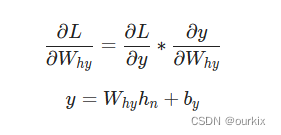
是最终的隐藏状态。因此

同样地

我们现在可以开始实现反向传播了!backprop()
class RNN:
# ...
def backprop(self, d_y, learn_rate=2e-2):
'''
Perform a backward pass of the RNN.
- d_y (dL/dy) has shape (output_size, 1).
- learn_rate is a float.
'''
n = len(self.last_inputs)
# Calculate dL/dWhy and dL/dby.
d_Why = d_y @ self.last_hs[n].T d_by = d_y
提醒:我们之前创建过。
self.last_hsforward()
最后,我们需要偏导,
,
,在 RNN 期间的每一步都会使用。我们有:
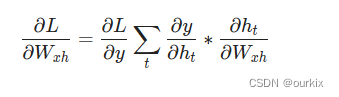
因为改变影响每一个
,这些都会影响y,并最终影响L。为了充分计算
,我们需要通过所有时间步进反向传播,这称为时间反向传播 (BPTT):
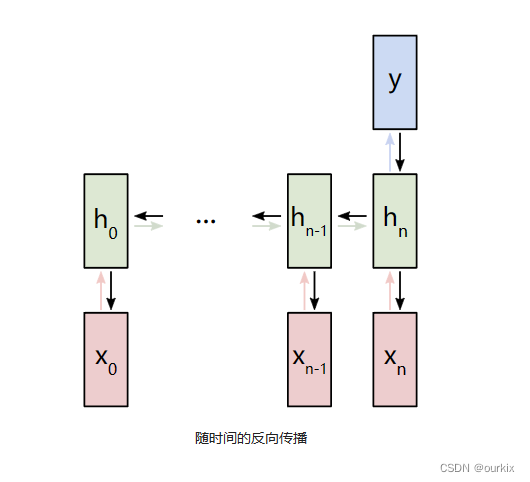
用于所有xt → ht前向链接,因此我们必须向反传播回每个链接。
一旦我们到达给定的步骤t,我们需要计算:
我们所知道的tanh求导:
我们像之前那样使用链式法则:
同理:
最后一步,我们需要,我们可以递归计算:
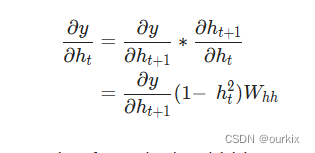
我们将从最后一个隐藏状态开始实现 BPTT 并反向传播,因此我们已经有了到我们要计算
的时候!最后一个隐藏状态是例外,
:
我们现在拥有最终实现 BPTT 并完成了所需的一切:backprop()
class RNN:
# ...
def backprop(self, d_y, learn_rate=2e-2):
'''
Perform a backward pass of the RNN.
- d_y (dL/dy) has shape (output_size, 1).
- learn_rate is a float.
'''
n = len(self.last_inputs)
# Calculate dL/dWhy and dL/dby.
d_Why = d_y @ self.last_hs[n].T
d_by = d_y
# Initialize dL/dWhh, dL/dWxh, and dL/dbh to zero.
d_Whh = np.zeros(self.Whh.shape)
d_Wxh = np.zeros(self.Wxh.shape)
d_bh = np.zeros(self.bh.shape)
# Calculate dL/dh for the last h.
d_h = self.Why.T @ d_y
# Backpropagate through time.
for t in reversed(range(n)):
# An intermediate value: dL/dh * (1 - h^2)
temp = ((1 - self.last_hs[t + 1] ** 2) * d_h)
# dL/db = dL/dh * (1 - h^2)
d_bh += temp
# dL/dWhh = dL/dh * (1 - h^2) * h_{t-1}
d_Whh += temp @ self.last_hs[t].T
# dL/dWxh = dL/dh * (1 - h^2) * x
d_Wxh += temp @ self.last_inputs[t].T
# Next dL/dh = dL/dh * (1 - h^2) * Whh
d_h = self.Whh @ temp
# Clip to prevent exploding gradients.
for d in [d_Wxh, d_Whh, d_Why, d_bh, d_by]:
np.clip(d, -1, 1, out=d)
# Update weights and biases using gradient descent.
self.Whh -= learn_rate * d_Whh
self.Wxh -= learn_rate * d_Wxh
self.Why -= learn_rate * d_Why
self.bh -= learn_rate * d_bh
self.by -= learn_rate * d_by需要注意的几点:
- 我们已经合并了
到
- 我们会不断更新一个包含最新变量的变量
d_h,,我们需要计算
.
- 完成 BPTT 后,我们 np.clip() 限制低于 -1 或高于 1 的梯度值。这有助于缓解梯度爆炸问题,即梯度由于具有大量相乘项而变得非常大。对于普通 RNN 来说,梯度的爆炸或消失是相当成问题的——更复杂的 RNN(如 LSTM)通常更有能力处理它们。
- 计算完所有梯度后,我们使用梯度下降更新权重和偏差。
我们做到了!我们的 RNN 已经完成了。
八. 进行预测
终于到了我们期待的时刻——让我们测试一下我们的 RNN!
首先,我们将编写一个辅助函数来使用 RNN 处理数据:
import random
def processData(data, backprop=True):
'''
Returns the RNN's loss and accuracy for the given data.
- data is a dictionary mapping text to True or False.
- backprop determines if the backward phase should be run.
'''
items = list(data.items())
random.shuffle(items)
loss = 0
num_correct = 0
for x, y in items:
inputs = createInputs(x)
target = int(y)
# Forward
out, _ = rnn.forward(inputs)
probs = softmax(out)
# Calculate loss / accuracy
loss -= np.log(probs[target])
num_correct += int(np.argmax(probs) == target)
if backprop:
# Build dL/dy
d_L_d_y = probs
d_L_d_y[target] -= 1
# Backward
rnn.backprop(d_L_d_y)
return loss / len(data), num_correct / len(data)现在,我们可以编写训练循环:
# Training loop
for epoch in range(1000):
train_loss, train_acc = processData(train_data)
if epoch % 100 == 99:
print('--- Epoch %d' % (epoch + 1))
print('Train:\tLoss %.3f | Accuracy: %.3f' % (train_loss, train_acc))
test_loss, test_acc = processData(test_data, backprop=False)
print('Test:\tLoss %.3f | Accuracy: %.3f' % (test_loss, test_acc)) 运行应该输出如下内容:main.py
--- Epoch 100
Train: Loss 0.688 | Accuracy: 0.517
Test: Loss 0.700 | Accuracy: 0.500
--- Epoch 200
Train: Loss 0.680 | Accuracy: 0.552
Test: Loss 0.717 | Accuracy: 0.450
--- Epoch 300
Train: Loss 0.593 | Accuracy: 0.655
Test: Loss 0.657 | Accuracy: 0.650
--- Epoch 400
Train: Loss 0.401 | Accuracy: 0.810
Test: Loss 0.689 | Accuracy: 0.650
--- Epoch 500
Train: Loss 0.312 | Accuracy: 0.862
Test: Loss 0.693 | Accuracy: 0.550
--- Epoch 600
Train: Loss 0.148 | Accuracy: 0.914
Test: Loss 0.404 | Accuracy: 0.800
--- Epoch 700
Train: Loss 0.008 | Accuracy: 1.000
Test: Loss 0.016 | Accuracy: 1.000
--- Epoch 800
Train: Loss 0.004 | Accuracy: 1.000
Test: Loss 0.007 | Accuracy: 1.000
--- Epoch 900
Train: Loss 0.002 | Accuracy: 1.000
Test: Loss 0.004 | Accuracy: 1.000
--- Epoch 1000
Train: Loss 0.002 | Accuracy: 1.000
Test: Loss 0.003 | Accuracy: 1.000
九. 结束
就是这样!在这篇文章中,我们完成了循环神经网络的演练,包括它们是什么、它们是如何工作的、为什么它们有用、如何训练它们以及如何实现它们。