前言
这一周,LVM在arxiv上刚挂出不久,就被众多自媒体宣传为『视觉大模型的GPT时刻』,笔者抱着强烈的好奇心,在繁忙工作之余对原文进行了拜读,特此笔记并留下读后感,希望对诸位读者有所帮助。如有谬误请见谅并联系指出,本文遵守CC 4.0 BY-SA版权协议,转载请联系作者并注明出处,谢谢。
∇ \nabla ∇ 联系方式:
e-mail: FesianXu@gmail.com
github: https://github.com/FesianXu
知乎专栏: 计算机视觉/计算机图形理论与应用(https://www.zhihu.com/column/c_1265262560611299328)
微信公众号:机器学习杂货铺3号店
LVM(Large Vision Models) [1] 自本月1号挂到arxiv以来,引发了众多自媒体的追捧,不乏称之为『视觉大模型的GPT时刻』的盛赞,也有不少大V对此表示持怀疑态度,这一周一直吃瓜的笔者也非常好奇,想一睹其视觉大模型的GPT风采,于是在工作之余抽空简单翻阅了下,总得来说还是受益匪浅的。
LVM的整体思想比较直白,既然NLP领域中,基于自回归的大模型(如GPT、LLaMA等)已经取得令人瞩目的成功,何不将视觉的预训练任务也统一到自回归中,也许就能产生和GPT一般的『智能』呢?考虑到NLP中,最小处理单元是token(下文翻译为『令牌』,tokenization则翻译为『令牌化』),我们不能以图片的像素级别去进行自回归,何不将图片也进行『令牌化』呢?将图片也转换成一个个令牌吧!那么我们就可以用NLP原生的预训练任务,比如自回归任务进行预训练了,如Fig 1.所示,将图片令牌化到若干个令牌后,就将视觉预训练任务转化为了『文本』预训练任务,作者将这样一个通过视觉令牌构成的句子,称之为Visual Sentence,也蕴含着将视觉任务文本化的意味?

那么如何将图像进行令牌化呢?在之前的一些工作,比如VQ-VAE、VQ-GAN中曾经对图像令牌化有所考虑,读者可在笔者之前的博文[2]中简单参考其思路,同时,在BEiT v2 [3] 中也有对VQ-VAE的一些改进(引入更语义的信息),在本篇工作中,作者采用了VQ-GAN对图片进行令牌化,笔者觉得是由于LVM后续还需要对视觉令牌进行解码,生成图像(见Fig 1的decoder部分),采用VQ-GAN能提供更好的图像生成能力,向量量化的简易示意图可参考Fig 2.所示。
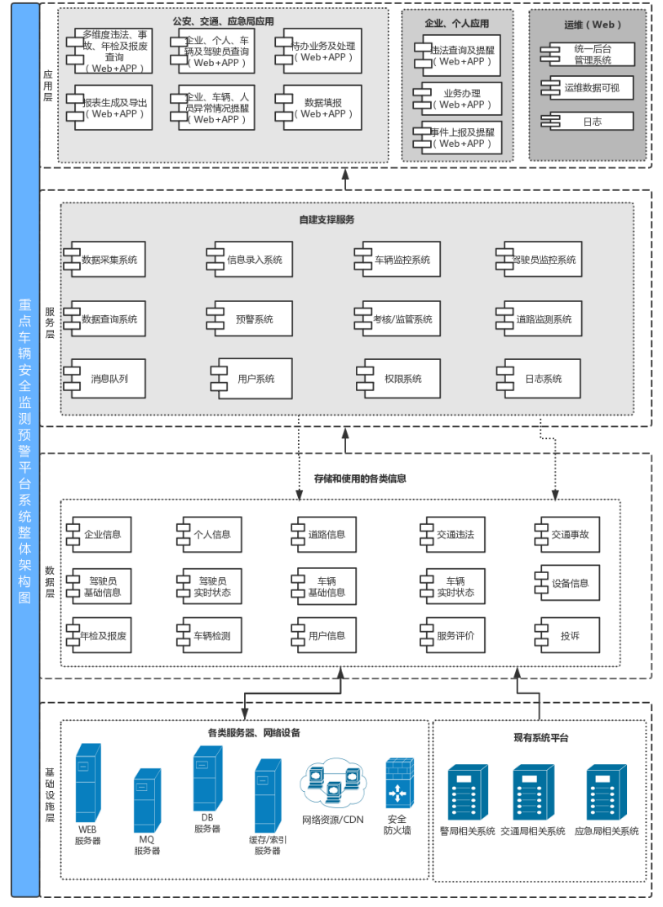
作者在本工作中的一个最大贡献,就是收集了一套大规模的用于LVM预训练的数据集,其中图像数据形式各种各样,来自于各种公开数据集,包括:
- 图片:一般的图片,如LAION数据集。
- 视频序列:将视频抽帧作为图片序列,此处视频类型各种各样,包括一般的视频,3D物体旋转的视频,CAD模型旋转产生不同视角的图片序列等等。
- 带有标注的图片:比如物体识别,语义分割等图片,可能包含有包围框、语义分割、图片风格转换、着色等标注在图片上。
- 带有标注的视频:如带有视频的分割标注等。
该数据集是一个纯图片数据集,没有任何配对的文本数据,具体数据收集的细节请见论文,此处不累述,作者将这个数据集命名为UVD-V1(Unified Vision Dataset),其中包含了50个公开数据集的数据,在将每张图片大小resize到256*256后,通过VQ-GAN将每个图片转化为了256个令牌后(码表大小8192),产生了4200亿个令牌(420B)。此时,每张图片/视频序列都可以描述为一个视觉短句,如
[BOS] V1, V2, V3, …, Vn [EOS]
通过自回归的方式,采用交叉熵损失去建模下一个令牌出现的概率,即是:
L
v
l
m
=
∑
i
log
P
(
V
i
∣
V
1
,
⋯
,
V
i
−
1
;
Θ
)
\mathcal{L}_{vlm} = \sum_{i} \log P(V_{i}|V_{1},\cdots,V_{i-1};\Theta)
Lvlm=i∑logP(Vi∣V1,⋯,Vi−1;Θ)
这就是所谓视觉任务语言模型化,因此作者也采用了LLM的开源模型LLaMA作为底座模型建模,大致的模型建模和数据构建部分就简单介绍到这里,里面很多细节问题也不在此处讨论,笔者主要关注了下论文的实验和效果展示部分。

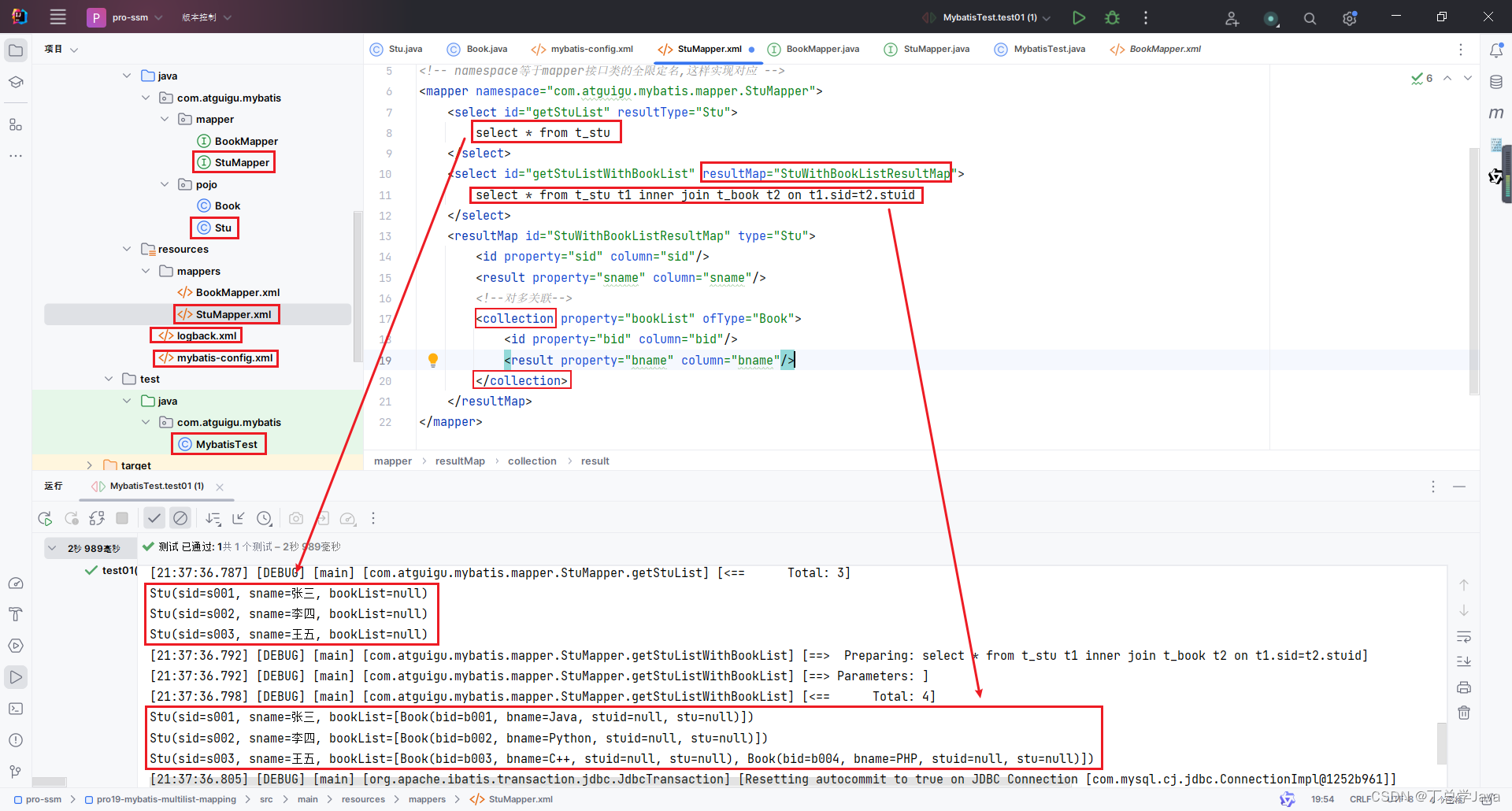
在实验部分,作者通过控制变量法,探讨了一些基础的模型超参数下的模型基础表现,如输入长度、模型大小、数据集消融等等的影响,具体可见原论文,笔者不进行累述,笔者主要想对论文中的图像提示词(prompt)和生成结果进行讨论。作者通过图像提示词的方式,对诸多传统的CV任务,如人体关键点检测、物体检测、视频帧预测、inpainting、去雨乃至是基础推理能力进行了研究,如Fig 3.就展示了通过提供一个视频序列的前15帧,对接续4帧进行预测的能力,能看到预测的接续4帧从视觉上看会较为趋同,但是也有一些模型『推理能力』的痕迹在里面,比如最后一个骑摩托的生成结果,有明显的从近到远离去的变化。

接下来是通过提供few-shot visual prompt,以<原图, 目标图>的形式喂给LVM进行预测的任务,如Fig 4.所示,在多种传统CV任务上都有着不俗的表现。考虑到数据集中有着3D渲染的多视角数据,作者还探索了LVM建模3D旋转的能力(用以证明LVM具有一定的三维视觉理解能力?),如Fig 5.所示,通过提供一系列将同一个3D物体进行某个方向旋转的visual prompt,LVM可以对接续的4帧进行预测。


在Fig 6.中,作者还报告了LVM对多种CV任务的组合能力,比如提供的visual prompt是3D旋转和关键点追踪两个CV任务的复合体,从生成接续的3帧来看也能得到合理的结果,表征了LVM似乎能对多种CV任务进行组合,即便这些组合在原始训练数据中可能不曾出现。



与此同时,想要成为视觉领域的GPT,那么除了基础的CV能力之外,其逻辑推理能力也不能落下,作者提供了几个visual prompt,给读者稍微一些遐想。如Fig 7,LVM对一些规律性的CV问题,比如图片内物体递增、光照变化、尺度放缩等有所感知。如Fig 8.所示,LVM能对一些找规律的题目进行一些感知。GPT有着诸多体现『智能』的表现,如
- 强大的逻辑推理能力
- 代码理解和生成能力
- 分步思考,思维链能力
- 类人的理解能力,包括一些幽默感、反讽、情绪理解等能力
- 世界知识:包括事实性知识 (factual knowledge) 和常识 (commonsense)
- …
其中的逻辑推理能力,可以说是最接近我们通常理解的『智能』的能力,我们之前展示的LVM能力,是否足以证实LVM具有和GPT一般的逻辑推理能力呢?
笔者认为似乎论据仍然不足,首先从论文提供的数据中,能看出推理能力的是Fig 8中展示的几何图形找规律任务,但是我们是从结果上的正确与否确定的,我们是否能『探知』到LVM的思考过程呢?完全没有看到,如下图所示,不像LLM能够通过自我反省的方式,让它吐出推理的过程,进而判断是否具有逻辑推理能力,以及模型推理能力的强弱。在LVM中我们只能通过给定一些具有逻辑性的视觉任务(而且还是人类认为具有逻辑性的题目,也许LVM会通过其他信号去拟合,而不是通过『逻辑推理』的方式?),通过直接输出的结果进行检测,正如笔者所说,这个方式并不是一个合适的探知推理能力的方法。此外,笔者认为推理能力依赖一些世界知识,比如实体识别能力,实体解释能力等,从文章中似乎没有看出明显的体现?LVM是否可以解释什么是苹果?什么是梨子?苹果和梨子之前有什么共同点和差异?这些能力没法从现在的LVM中看到。目前的视觉提示词的方式,似乎不容易从中探知LVM的世界知识能力?
笔者认为单纯的视觉大模型很难建模完整的逻辑推理能力(当然也不是不可能,毕竟人类以视觉识别文本,文本完全可以渲染成图片作为LVM输入,从而LVM变为通用的多模态GPT,但是我们为什么要舍弃文本呢?),逻辑推理能力依赖一些世界知识和语义,脱离了文本很难建模,并且文本作为表达需求和可以作为自我解释的手段,也是一个通用AGI模型不能舍弃的。因此笔者对LVM的评价是:一个很不错和有启发的工作,但是称之为视觉大模型的GPT时刻似乎不妥,称之为AGI更是有捧杀之意了。
当然,对于笔者来说这篇工作还有更多值得思考的,比如作者采用了视觉令牌化作为模型的直接输入进行建模这块,笔者就深表赞同。笔者在工作中也尝试以各种角度落地多模态技术,无论是从工业界遇到的问题,还是学术界研究的角度来看,视觉令牌化都是一个非常值得探索的技术。之前笔者在项目实践中觉得视觉令牌化应该是对视觉语义的提取,会失去不少视觉细节信息,但是从Fig 4来看,似乎LVM对很多偏向low-level的视觉任务都有不错的表现(包括未展示的de-rain任务),这些low-level的任务对视觉的细粒度信息应该还是有所需要的,因此这一点比较刷新作者的认识,笔者猜想可能是由于采用了VQ-GAN技术导致的视觉令牌中可以携带更多细粒度的视觉信息?毕竟在实践中,视觉词表是一个偏向于利用率不充分的存在,也许采用了VQ-GAN技术后可以更加充分利用词表,进而对细粒度有所感知。当然,这些都是笔者的一些随性猜想罢了,希望抛砖引玉得到各位读者的指教。

Reference
[1]. Bai, Yutong, et al. “Sequential Modeling Enables Scalable Learning for Large Vision Models.” arXiv preprint arXiv:2312.00785 (2023).
[2]. https://blog.csdn.net/LoseInVain/article/details/129224424,【论文极速读】VQ-VAE:一种稀疏表征学习方法
[3]. Peng, Zhiliang, Li Dong, Hangbo Bao, Qixiang Ye, and Furu Wei. “Beit v2: Masked image modeling with vector-quantized visual tokenizers.” arXiv preprint arXiv:2208.06366 (2022)