目录
一、定义
二、模拟实现
1、无参初始化
2、size&capacity
3、reserve
4、push_back
5、迭代器
6、empty
7、pop_back
8、operator[ ]
9、resize
10、insert
迭代器失效问题
11、erase
12、带参初始化
13、迭代器初始化
14、析构函数
完整版代码
一、定义
本次参考SGI版本STL中的vector模拟实现。
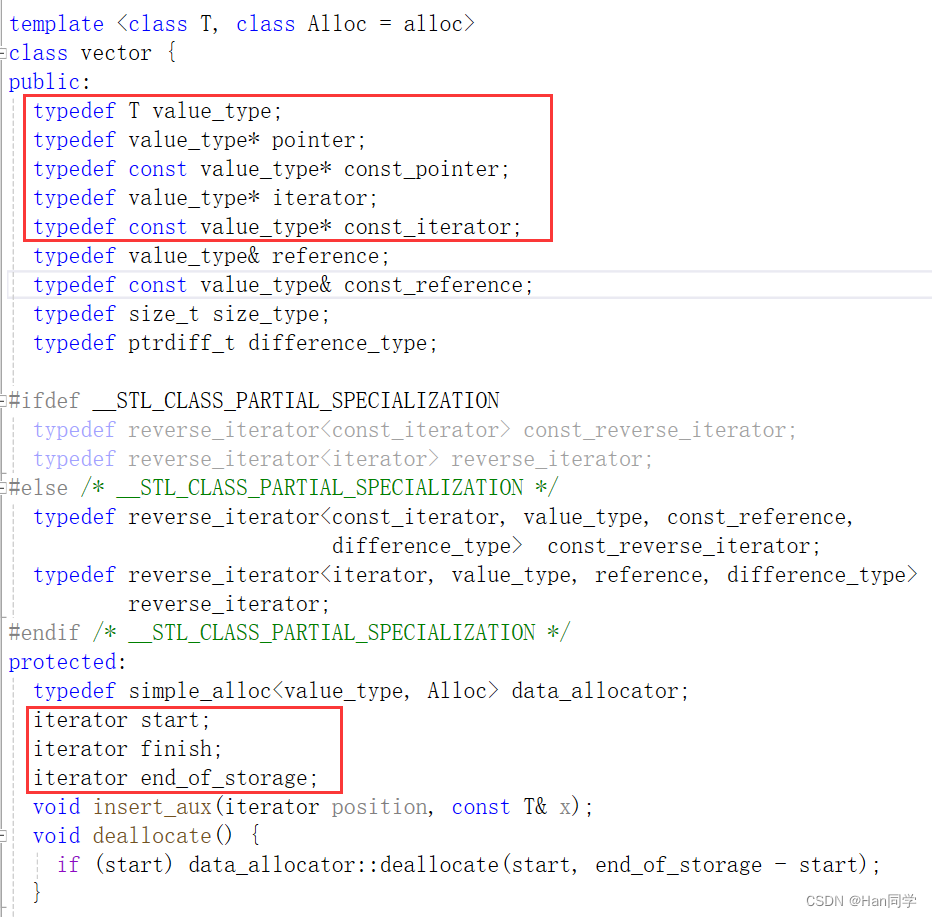
我们可以看到上述源代码中,SGI版本vector是借助指针实现的,元素的处理是通过两个指针来实现的,而不是三个迭代器。这两个指针分别是_start和_finish。
- _start指针指向vector中的第一个元素。
- _finish指针指向vector中最后一个元素的下一个位置。
通过_start和_finish指针,可以确定vector中存储的元素范围。

此外,SGI版本的vector还使用了一个指针_end_of_storage来表示vector分配的内存空间的末尾位置。
这些指针的使用使得SGI版本的vector能够高效地进行元素的插入、删除和访问操作。
为了不影响VS中STL库已有的vector,我们选择将模拟实现的vector放在自定义命名空间中。
namespace byte
{
template<class T>
class vector
{
public:
private:
iterator _start;
iterator _finish;
iterator _end_of_storage;
};
}二、模拟实现
1、无参初始化
vector()
:_start(nullptr)
, _finish(nullptr)
, _end_of_storage(nullptr)
{}2、size&capacity
size_t capacity() const
{
return _end_of_storage - _start;
}
size_t size() const
{
return _finish - _start;
}3、reserve
void reserve(size_t n)
{
if (n > capacity())
{
size_t sz = size();
T* tmp = new T[n];
if (_start)
{
memcpy(tmp, _start, sizeof(T) * size());
delete[] _start;
}
_start = tmp;
_finish = _start + sz;
_end_of_storage = _start + n;
}
}-
if (n > capacity()):检查传入的n是否大于当前vector的容量。如果是,则需要进行内存重新分配。 -
size_t sz = size();:保存当前vector的大小(元素个数)。 -
T* tmp = new T[n];:创建一个新的大小为n的动态数组tmp,用于存储重新分配后的元素。 -
if (_start):检查_start指针判断旧空间是否为非空。如果_start指针不为空,说明vector中已经有元素存储在旧的内存空间中。 -
memcpy(tmp, _start, sizeof(T) * size());:使用memcpy函数将旧的内存空间中的元素复制到新的内存空间tmp中。这样可以保留元素的值。 -
delete[] _start;:释放旧的内存空间。 -
_start = tmp;:将_start指针指向新的内存空间tmp。 -
_finish = _start + sz;:更新_finish指针,使其指向新的内存空间中的最后一个元素的下一个位置。 -
_end_of_storage = _start + n;:更新_end_of_storage指针,使其指向新的内存空间的末尾位置。
4、push_back
void push_back(const T& x)
{
if (_finish == _end_of_storage)
{
reserve(capacity() == 0 ? 4 : capacity() * 2);
}
*_finish = x;
++_finish;
}-
使用
const T& x作为参数类型可以避免不必要的拷贝操作,因为传入的实参可以直接通过引用访问,而不需要进行拷贝构造。这可以提高性能和效率,特别是当处理大型对象时。另外,使用
const T& x还可以确保传入的元素不会被修改,因为const关键字表示传入的引用是只读的,函数内部不能修改传入的对象。 -
if (_finish == _end_of_storage)这个条件判断用于检查当前vector是否已经达到了内存空间的末尾。如果是,则需要进行内存重新分配。 -
reserve(capacity() == 0 ? 4 : capacity() * 2)在需要进行内存重新分配时,调用reserve函数来预留更多的内存空间。这里使用了三目运算符,如果当前容量为0,则预留4个元素的空间,否则将当前容量乘以2来预留更多的空间。 -
*_finish = x将传入的元素x赋值给_finish指针所指向的位置,即在vector的末尾插入元素。 -
++_finish将_finish指针向后移动一位,指向新插入元素的下一个位置,以便维护vector的边界。
5、迭代器
typedef T* iterator;
typedef const T* const_iterator;
iterator begin()
{
return _start;
}
iterator end()
{
return _finish;
}
const_iterator begin() const
{
return _start;
}
const_iterator end() const
{
return _finish;
}- 首先,通过
typedef关键字,定义了两个迭代器类型:iterator和const_iterator。iterator表示可修改元素的迭代器,而const_iterator表示只读元素的迭代器。 - 然后,定义了
begin()和end()函数的多个重载版本,用于返回不同类型的迭代器。
6、empty
bool empty()
{
return _start == _finish;
}7、pop_back
void pop_back(const T& x)
{
assert(!empty());
--_finish;
}8、operator[ ]
这个类中有两个重载的下标运算符函数,一个是非常量版本的 operator[],另一个是常量版本的 operator[]。这是为了支持对类对象的读写操作和只读操作的区分。
T& operator[](size_t pos)
{
assert(pos < size());
return _start[pos];
}
const T& operator[](size_t pos) const
{
assert(pos < size());
return _start[pos];
}9、resize
void resize(size_t n, T val = T())
{
if (n < size())
{
_finish = _start + n;
}
else {
if (n 》 capacity())
reserve(n);
while (_finish != _start + n)
{
*_finish = val;
++_finish;
}
}
}函数签名为
void resize(size_t n, T val = T()),接受两个参数:n表示新的大小,val表示新元素的默认值(默认为T(),通过匿名对象T()调用类型T的默认构造函数)。
函数的作用是将容器的大小调整为 n。如果 n 小于当前的大小,则将容器的大小缩小为 n,丢弃多余的元素;如果 n 大于当前的大小,则在容器的末尾添加新的元素,直到容器的大小达到 n。
- 首先,函数会检查 n 是否小于当前的大小。如果是,说明需要缩小容器的大小,将 _finish 指针移动到新的位置 _start + n,丢弃多余的元素。
- 如果 n 大于等于当前的大小,则需要添加新的元素。首先,函数会检查 n 是否大于容器的容量 capacity()。如果 n 大于容量,则调用 reserve 函数来增加容器的容量,以确保容器有足够的空间来存放新的元素。
- 然后,使用循环将新的元素 val 添加到容器的末尾,直到容器的大小达到 n。循环中,将 val 赋值给 _finish 指向的位置,然后将 _finish 指针向后移动一位。
匿名对象调用默认构造初始化。
template<class T>
void f()
{
T x = T();
cout << x << endl;
}- 在
resize函数中,T val = T()是一个带有默认值的函数参数。这里T()是对模板参数T类型的值初始化,对于内置类型,它会初始化为零(对于指针类型,初始化为nullptr)。这和f<T>()模板函数中的T x = T()是一样的。 - 当你调用
resize函数时,如果你没有提供第二个参数,那么val就会被初始化为T类型的默认值。然后,resize函数会使用val的值来填充新添加的元素。 - 例如,如果你有一个
byte::vector<int>对象v,并调用v.resize(10),那么resize函数会将v的大小改变为10,并使用int类型的默认值0来填充新添加的元素。这和f<int>()函数打印int类型的默认值0是一样的。
内置类型的默认初始化和直接初始化。
void test_vector2()
{
// 内置类型有没有构造函数
int i = int();
int j = int(1);
f<int>();
f<int*>();
f<double>();
}-
int i = int(); 使用值初始化,将 i 初始化为零。int j = int(1); 使用直接初始化,将 j 初始化为 1。
-
分别使用 int、int* 和 double 作为模板参数调用了 f<T>() 函数。这将分别打印 int、int* 和 double 类型的默认值,即 0、nullptr 和 0。
10、insert
iterator insert(iterator pos, const T& val)
{
assert(pos >= _start);
assert(pos <= _finish);
if (_finish == _end_of_storage)
{
size_t len = pos - _start;
reserve(capacity() == 0 ? 4 : capacity() * 2);
// 扩容后更新pos,解决pos失效的问题
pos = _start + len;
}
iterator end = _finish-1;
while (end >= pos)
{
*(end + 1) = *end;
--end;
}
*pos = val;
++_finish;
return pos;
}函数接受两个参数,第一个参数 pos 是一个迭代器,表示要插入元素的位置,第二个参数 val 是要插入的元素的值。
函数的实现分为以下几个步骤:
-
首先,使用
assert断言来确保pos是一个有效的位置,即pos必须在_start和_finish之间。 -
然后,检查是否有足够的空间来插入新的元素。如果
_finish等于_end_of_storage,表示当前的内存已经用完,需要重新分配内存。这时,会调用reserve函数来重新分配内存,新的容量是当前容量的两倍,如果当前容量为0,则新的容量为4。然后,更新pos的值,因为重新分配内存后,原来的pos可能已经失效。 -
接下来,从
_finish-1开始,将每个元素向后移动一位,直到pos的位置,为插入新的元素腾出空间。 -
然后,将
val的值赋给*pos,即在pos的位置插入新的元素。 -
最后,将
_finish向后移动一位,表示vector的大小增加了一个元素。 -
函数返回插入新元素的位置
pos。
迭代器失效问题
- 在 `byte::vector` 类的 `insert` 函数中,如果需要重新分配内存(即 `_finish+ + == _end_of_storage`),那么所有指向原来内存的迭代器都会失效。这是因为 `reserve` 函数会申请新的内存,复制原来的元素到新的内存,然后释放原来的内存。这个过程会导致原来的内存地址不再有效,因此所有指向原来内存的迭代器都会失效。
- 在这个函数中,`pos` 是一个迭代器,它指向要插入新元素的位置。如果在插入新元素之前需要重新分配内存,那么 `pos` 就会失效。为了解决这个问题,函数在重新分配内存后,会根据 `pos` 原来的位置(即 `len = pos - _start`)来更新 `pos` 的值(即 `pos = _start + len`)。这样,`pos` 就会指向新内存中相同的位置。
- 所以,如果你在调用 `insert` 函数之后还需要使用原来的迭代器,你需要注意迭代器可能已经失效。你可以在插入新元素后,重新获取迭代器的值。例如,如果你在插入新元素后,想要访问新元素,这里不能常量pos使用引用传值,你可以使用 `insert` 函数的返回值,它返回的是插入新元素的位置。这时外部插入元素后 (*pos)++; 可以正常运行了。
11、erase
我们先看这个版本的erase:
void erase(iterator pos)
{
assert(pos >= _start && pos < _finish);
iterator start = pos + 1;
while (start != _finish)
{
*(start - 1) = *start;
++start;
}
--_finish;
}当我们运行以下代码程序VS会报错,linux下g++不会报错。
void test4()
{
std::vector<int> v1;
v1.push_back(1);
v1.push_back(2);
v1.push_back(3);
v1.push_back(4);
for (auto e : v1)
{
cout << e << " ";
}
cout << endl;
auto pos = find(v1.begin(), v1.end(), 2);
if (pos != v1.end())
{
v1.erase(pos);
}
(*pos)++;
for (auto e : v1)
{
cout << e << " ";
}
cout << endl;
}
}VS下:
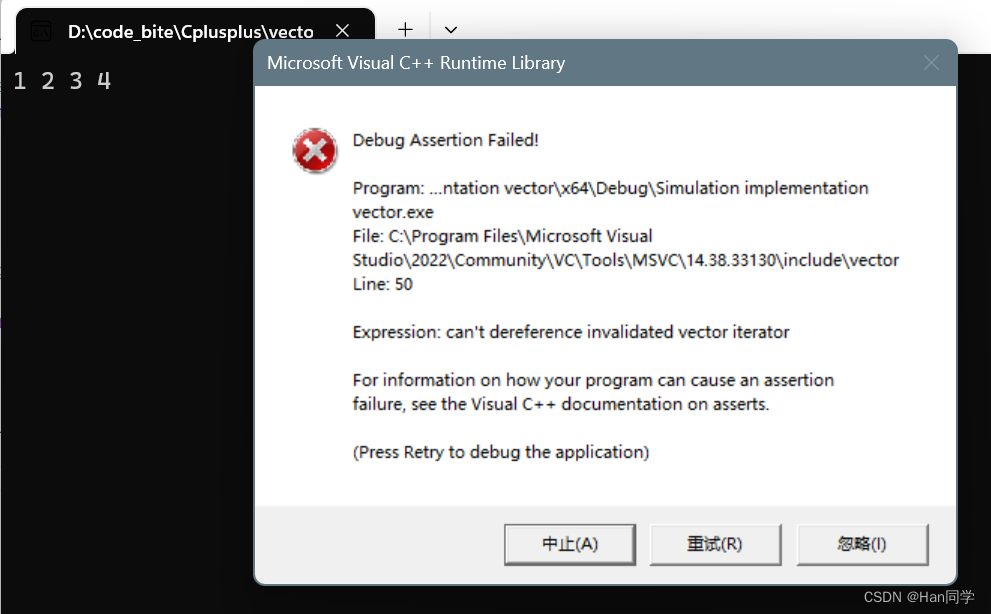
g++下:

这段代码中,v1.erase(pos) 会删除 vector 中的一个元素,这会导致 pos 以及所有在 pos 之后的迭代器失效。然后,代码试图通过 (*pos)++ 访问和修改已经失效的迭代器 pos,这是未定义行为,可能会导致程序崩溃或其他错误。
至于为什么 Visual Studio(VS) 会报错,而 g++ 不会报错,这主要是因为不同的编译器对未定义行为的处理方式不同。VS 的调试模式下对迭代器进行了更严格的检查,当你试图访问失效的迭代器时,它会立即报错。而 g++ 在默认设置下可能不会进行这样的检查,所以它可能不会立即报错,但这并不意味着这段代码是正确的。
下面第一种情况删除非末尾元素时,VS的报错没有意义,但在第二种情况下,VS的报错就非常有意义了。

为了避免这种问题,你应该在删除元素后,不再使用已经失效的迭代器。如果你需要在删除元素后继续访问 vector,你应该在删除元素后重新获取迭代器的值。例如,vector::erase 函数会返回一个指向被删除元素之后的元素的迭代器,你可以使用这个返回值来更新 pos 。
正确版本:
iterator erase(iterator pos)
{
assert(pos >= _start);
assert(pos < _finish);
iterator start = pos + 1;
while (start != _finish)
{
*(start - 1) = *start;
++start;
}
--_finish;
return pos;
}我们来测试一下删除偶数:
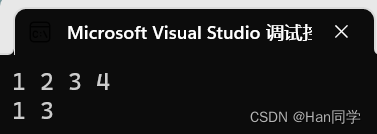
void test5()
{
byte::vector<int> v1;
v1.push_back(1);
v1.push_back(2);
v1.push_back(3);
v1.push_back(4);
for (auto e : v1)
{
cout << e << " ";
}
cout << endl;
//要求删除所有偶数
byte::vector<int>::iterator it = v1.begin();
while (it != v1.end())
{
if (*it % 2 == 0)
{
it=v1.erase(it);
}
else
{
++it;
}
}
for (auto e : v1)
{
cout << e << " ";
}
cout << endl;
} 
12、带参初始化
一定要对_start、_finish、_out_of_storage进行初始化,不初始化默认随机值。
vector(size_t n, const T& value = T())
: _start(nullptr)
, _finish(nullptr)
, _end_of_storage(nullptr)
{
reserve(n);
while (n--)
{
push_back(value);
}
}这个构造函数创建一个包含 n 个元素的 vector,每个元素都初始化为 value。value 参数有一个默认值,即 T(),它是 T 类型的默认构造值。
_start(nullptr), _finish(nullptr), _end_of_storage(nullptr): 这一行初始化三个迭代器,它们分别指向数组的开始、当前最后一个元素之后的位置,和分配的内存末端。初始化为nullptr表示开始时没有分配任何内存。reserve(n): 这个函数调用会分配足够容纳n个元素的内存,但不会创建任何元素。while (n--) { push_back(value); }: 这个循环会不断地添加value到vector中,直到添加了n个元素。push_back函数会在vector的末尾添加一个新元素,并可能会增加vector的容量(如果需要)。
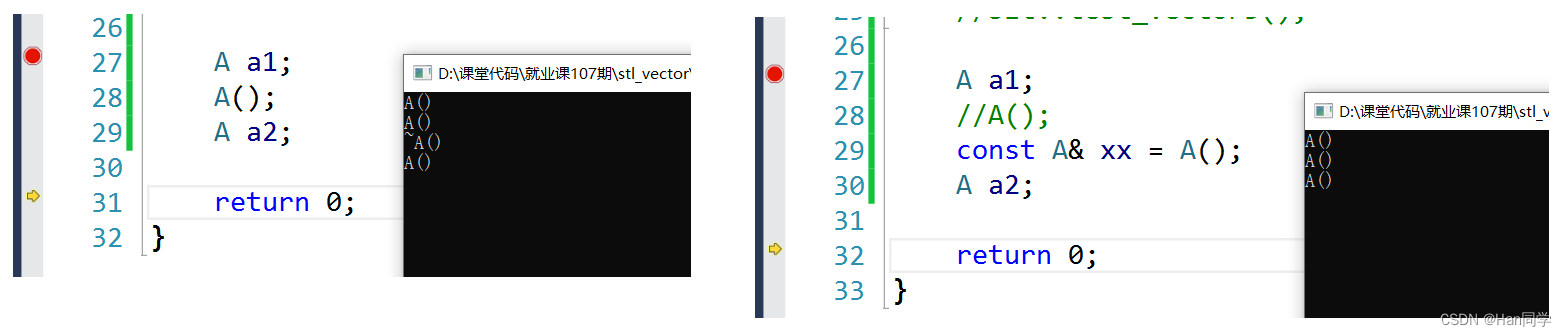
为什么对 T& 前面要加 const ?
- 匿名对象声明周期只在当前一行,因为这行之后没人会用它了。
- const引用会延长匿名对象的声明周期到引用对象域结束,因为以后用xx就是用匿名对象。
13、迭代器初始化
template <class InputIterator>
vector(InputIterator first, InputIterator last)
{
while (first != last)
{
push_back(*first);
++first;
}
}这个构造函数使用两个迭代器 first 和 last,它们分别指向输入序列的开始和结束,来初始化 vector。这个构造函数可以用于从任何可迭代的容器(如另一个 vector、列表、数组等)复制元素。
- 在这个构造函数中,没有显式地调用
reserve来预分配内存。这意味着每次用push_back时,如果当前容量不足以容纳新元素,就会自动进行内存重新分配。 while (first != last) { push_back(*first); ++first; }: 这个循环会遍历输入序列的每个元素,从 first 开始,一直到达 last(但不包括 last),并使用每个元素的值调用 push_back,将其添加到 vector 中。
但是对于这句代码编译之后会报错:
vector<int> v1(10, 5); 这是因为这段代码在vector(InputIterator first, InputIterator last)和vector(size_t n, const T& value = T())同时存在时,会优先调用前者,但调研之后在函数内部first的模板类型为int,而*first为对int类型解引用,所以这样报错了。
这是因为这段代码在vector(InputIterator first, InputIterator last)和vector(size_t n, const T& value = T())同时存在时,会优先调用前者,但调研之后在函数内部first的模板类型为int,而*first为对int类型解引用,所以这样报错了。
我们只要添加一个int类型重载函数即可解决。
vector(int n, const T& val = T())
{
reserve(n);
for (int i = 0; i < n; ++i)
{
push_back(val);
}
}这种情况在不加上上述函数可以正常使用,调用vector(size_t n, const T& value = T())。
vector<int> v1(10u, 5);14、析构函数
~vector()
{
delete[] _start;
_start = _finish = _end_of_storage = nullptr;
}完整版代码&测试代码
#pragma once
#include<assert.h>
namespace byte
{
template<class T>
class vector
{
public:
typedef T* iterator;
typedef const T* const_iterator;
iterator begin()
{
return _start;
}
iterator end()
{
return _finish;
}
const_iterator begin() const
{
return _start;
}
const_iterator end() const
{
return _finish;
}
void resize(size_t n, T val = T())
{
if (n < size())
{
_finish = _start + n;
}
else {
if (n < capacity())
reserve(n);
while (_finish != _start + n)
{
*_finish = val;
++_finish;
}
}
}
vector()
:_start(nullptr)
, _finish(nullptr)
, _end_of_storage(nullptr)
{}
vector(size_t n, const T& value = T())
: _start(nullptr)
, _finish(nullptr)
, _end_of_storage(nullptr)
{
reserve(n);
while (n--)
{
push_back(value);
}
}
vector(int n, const T& val = T())
{
reserve(n);
for (int i = 0; i < n; ++i)
{
push_back(val);
}
}
template<class InputIterator>
vector(InputIterator first, InputIterator last)
{
while (first != last)
{
push_back(*first);
++first;
}
}
~vector()
{
delete[] _start;
_start = _finish = _end_of_storage = nullptr;
}
void reserve(size_t n)
{
if (n > capacity())
{
size_t sz = size();
T* tmp = new T[n];
if (_start)
{
memcpy(tmp, _start, sizeof(T) * size());
delete[] _start;
}
_start = tmp;
_finish = _start + sz;
_end_of_storage = _start + n;
}
}
void push_back(const T& x)
{
if (_finish == _end_of_storage)
{
reserve(capacity() == 0 ? 4 : capacity() * 2);
}
*_finish = x;
++_finish;
}
void pop_back(const T& x)
{
assert(!empty());
--_finish;
}
void insert(iterator pos, const T& val)
{
assert(pos >= _start);
assert(pos <= _finish);
if (_finish == _end_of_storage)
{
size_t len = pos - _start;
reserve(capacity() == 0 ? 4 : capacity() * 2);
pos = _start + len;
}
iterator end = _finish - 1;
while (end >= pos)
{
*(end + 1) = *end;
--end;
}
*pos = val;
++_finish;
}
iterator erase(iterator pos)
{
assert(pos >= _start && pos < _finish);
iterator start = pos + 1;
while (start != _finish)
{
*(start - 1) = *start;
++start;
}
--_finish;
return pos;
}
size_t capacity() const
{
return _end_of_storage - _start;
}
size_t size() const
{
return _finish - _start;
}
bool empty()
{
return _start == _finish;
}
T& operator[](size_t pos)
{
assert(pos < size());
return _start[pos];
}
const T& operator[](size_t pos) const
{
assert(pos < size());
return _start[pos];
}
private:
iterator _start;
iterator _finish;
iterator _end_of_storage;
};
void func(const vector<int>& v)
{
for (size_t i = 0; i < v.size(); ++i)
{
cout << v[i] << " ";
}
cout << endl;
vector<int>::const_iterator it = v.begin();
while (it != v.end())
{
cout << *it << " ";
++it;
}
cout << endl << endl;
}
void test1()
{
vector<int> v1;
v1.push_back(1);
v1.push_back(2);
v1.push_back(3);
for (size_t i = 0; i < v1.size(); i++)
{
cout << v1[i] << " ";
}
cout << endl;
vector<int>::iterator it = v1.begin();
while (it != v1.end())
{
cout << *it << " ";
++it;
}
cout << endl;
for (auto e : v1)
{
cout << e << " ";
}
cout << endl;
}
void test2()
{
vector<int> v1;
v1.push_back(1);
v1.push_back(2);
v1.push_back(3);
v1.push_back(4);
v1.push_back(5);
cout << v1.size() << endl;
cout << v1.capacity() << endl;
v1.resize(10);
cout << v1.size() << endl;
cout << v1.capacity() << endl;
func(v1);
v1.resize(3);
func(v1);
}
void test3()
{
std::vector<int> v1;
v1.push_back(1);
v1.push_back(2);
v1.push_back(3);
v1.push_back(4);
//v1.push_back(5);
for (auto e : v1)
{
cout << e << " ";
}
cout << endl;
/*v1.insert(v1.begin(), 0);
for (auto e : v1)
{
cout << e << " ";
}
cout << endl;*/
auto pos = find(v1.begin(), v1.end(), 3);
if (pos != v1.end())
{
//v1.insert(pos, 30);
pos = v1.insert(pos, 30);
}
for (auto e : v1)
{
cout << e << " ";
}
cout << endl;
// insert以后我们认为pos失效了,不能再使用
(*pos)++;
for (auto e : v1)
{
cout << e << " ";
}
cout << endl;
}
void test4()
{
std::vector<int> v1;
v1.push_back(1);
v1.push_back(2);
v1.push_back(3);
v1.push_back(4);
for (auto e : v1)
{
cout << e << " ";
}
cout << endl;
//auto pos = find(v1.begin(), v1.end(), 2);
auto pos = find(v1.begin(), v1.end(), 4);
if (pos != v1.end())
{
v1.erase(pos);
}
(*pos)++;
for (auto e : v1)
{
cout << e << " ";
}
cout << endl;
}
void test5()
{
byte::vector<int> v1;
v1.push_back(1);
v1.push_back(2);
v1.push_back(3);
v1.push_back(4);
for (auto e : v1)
{
cout << e << " ";
}
cout << endl;
//要求删除所有偶数
byte::vector<int>::iterator it = v1.begin();
while (it != v1.end())
{
if (*it % 2 == 0)
{
it=v1.erase(it);
}
else
{
++it;
}
}
for (auto e : v1)
{
cout << e << " ";
}
cout << endl;
}
void test6()
{
vector<int> v1(10, 5);
for (auto e : v1)
{
cout << e << " ";
}
cout << endl;
vector<int> v2(v1.begin() + 1, v1.end() - 1);
for (auto e : v2)
{
cout << e << " ";
}
cout << endl;
std::string s1("hello");
vector<int> v3(s1.begin(), s1.end());
for (auto e : v3)
{
cout << e << " ";
}
cout << endl;
int a[] = { 100, 10, 2, 20, 30 };
vector<int> v4(a, a + 3);
for (auto e : v4)
{
cout << e << " ";
}
cout << endl;
v1.insert(v1.begin(), 10);
for (auto e : v1)
{
cout << e << " ";
}
cout << endl;
}
}