本文主要集中于图片到三维重建的算法模型,其中包含人体重建,人脸重建等
1.三维人体重建
1.1.2015_SMPL: A Skinned Multi-Person Linear Model
论文地址:SMPL2015.pdf (mpg.de)
代码地址:CalciferZh/SMPL: NumPy, TensorFlow and PyTorch implementation of human body SMPL model and infant body SMIL model. (github.com)
gulvarol/smplpytorch: SMPL body model layer for PyTorch (github.com)
autocyz/smpl_understand: understand about SMPLmodel(http://smpl.is.tue.mpg.de/downloads) (github.com)
2019_SMPL-X: Expressive Body Capture: 3D Hands, Face, and Body from a Single Image
论文地址:SMPL-X (mpg.de)
论文代码:vchoutas/smplx: SMPL-X (github.com)
论文摘要
为了便于分析人类行为、互动和情绪,论文从单个单眼图像中计算出人体姿势、手部姿势和面部表情的 3D 模型。为了实现这一目标,论文使用数千次 3D 扫描来训练一种新的、统一的人体 3D 模型 SMPL-X,该模型通过完全关节的手和富有表现力的面部扩展 SMPL。在没有配对图像和 3D 地面实况的情况下,学习直接从图像回归 SMPL-X 的参数具有挑战性。因此,论文遵循 SMPLify 的方法,该方法估计 2D 特征,然后优化模型参数以拟合特征。在几个重要方面改进了 SMPLify:
- 检测与面部、手和脚相对应的 2D 特征,并将完整的 SMPL-X 模型拟合到这些特征上;
- 先使用大型MoCap数据集训练一种新的神经网络姿势;
- 定义了一种既快速又准确的新的相互渗透惩罚;
- 自动检测性别和适当的身体模型(男性、女性或中性);
- 在 PyTorch 实现比 Chumpy 加速了 8 倍以上。
使用新方法SMPLify-X将SMPL-X拟合到受控图像和野外图像中。在一个新的精选数据集上评估 3D 准确性,该数据集包含 100 张具有伪地面实况的图像。这是从单目RGB数据中自动进行富有表现力的人体捕获的一步。这些模型、代码和数据可在 https://smpl-x.is.tue.mpg.de 上用于研究目的。

2020_Deep reconstruction of 3D human poses from video
论文地址:JIAN_TAI.pdf (uwa.edu.au)
代码地址:暂无
[ CVPR 2020].PIFuHD: Multi-Level Pixel-Aligned Implicit Function for High-Resolution 3D Human Digitization
论文地址:arxiv.org/pdf/2004.00452.pdf
代码地址:facebookresearch/pifuhd: High-Resolution 3D Human Digitization from A Single Image. (github.com)
Demo:PIFuHD: Multi-Level Pixel-Aligned Implicit Function for High-Resolution 3D Human Digitization (shunsukesaito.github.io)
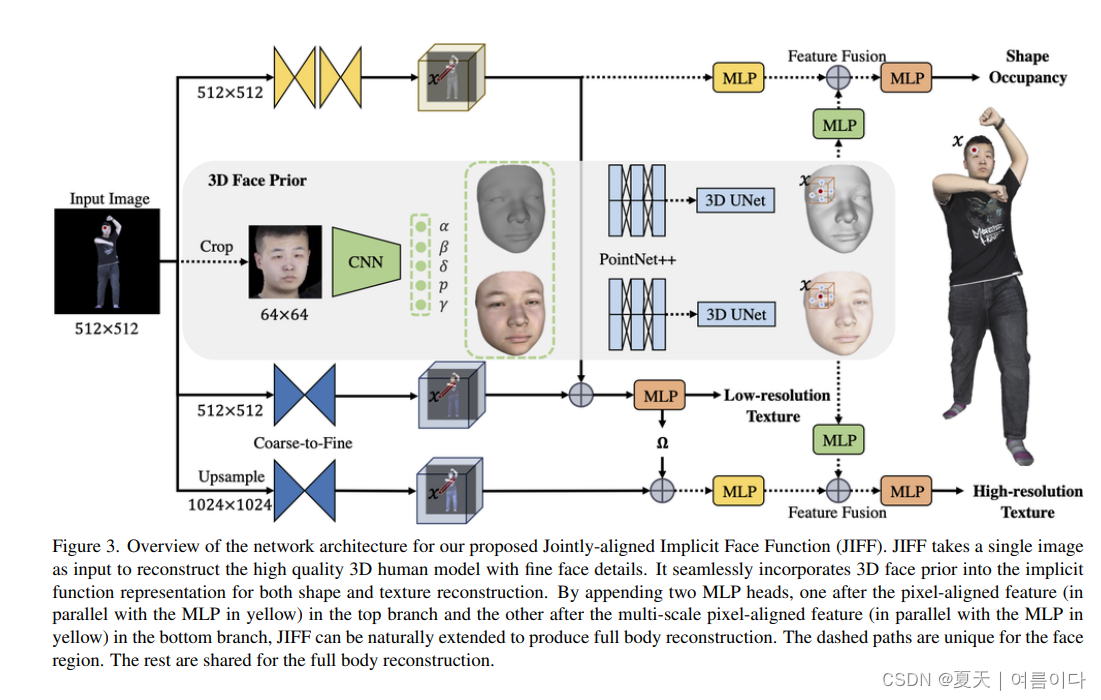
2022_JIFF: Jointly-aligned Implicit Face Function for High Quality Single View Clothed Human Reconstruction
论文地址:2204.10549.pdf (arxiv.org)
论文代码:暂未开源
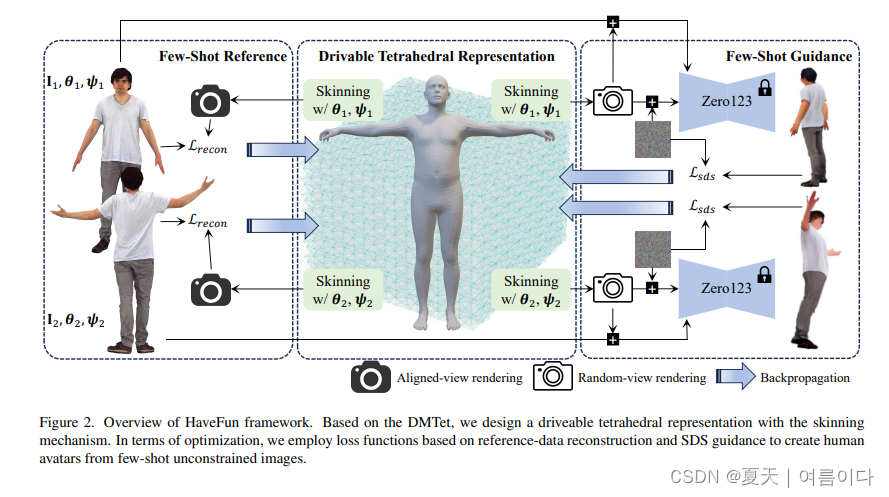
2023.11.27_HAVE-FUN: Human Avatar Reconstruction from Few-Shot Unconstrained Images
论文地址:2311.15672.pdf (arxiv.org)
代码地址:暂未开源
Demo:HAVE-FUN (seanchenxy.github.io)
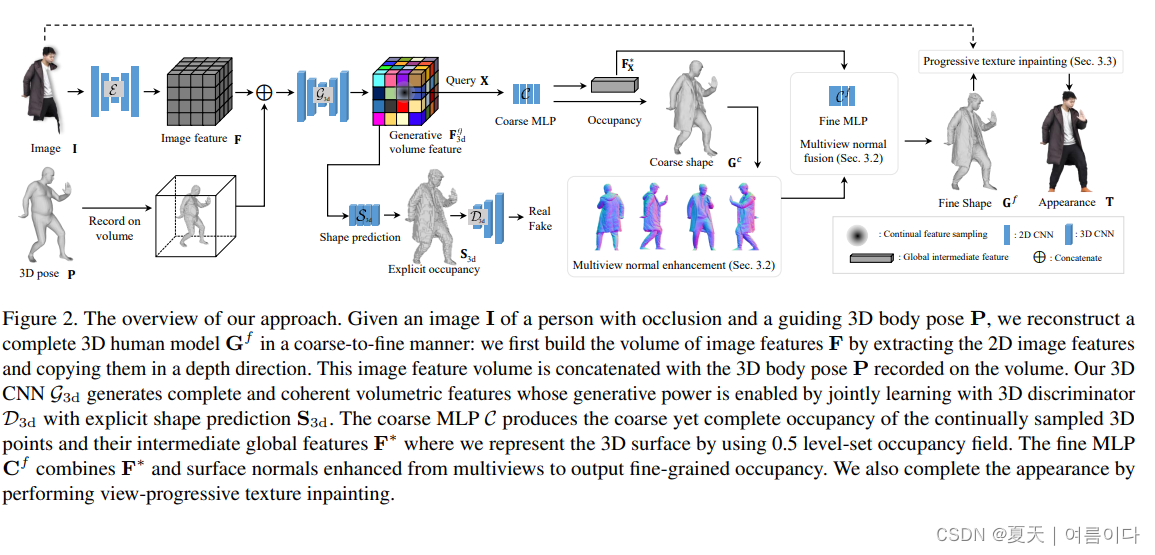
[ CVPR 2023].Complete 3D Human Reconstruction from a Single Incomplete Image
论文地址:Complete 3D Human Reconstruction From a Single Incomplete Image (thecvf.com)
代码地址:
2.三维人脸重建
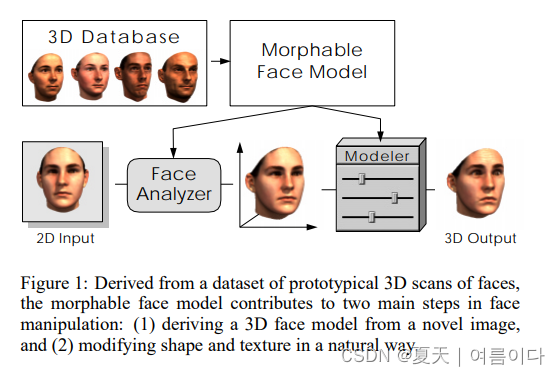
2.1.3DMM:A Morphable Model For The Synthesis Of 3D Faces
论文地址:SIG99.dvi (ucsd.edu)
代码地址:ascust/3DMM-Fitting-Pytorch: A 3DMM fitting framework using Pytorch. (github.com)(非官方版)
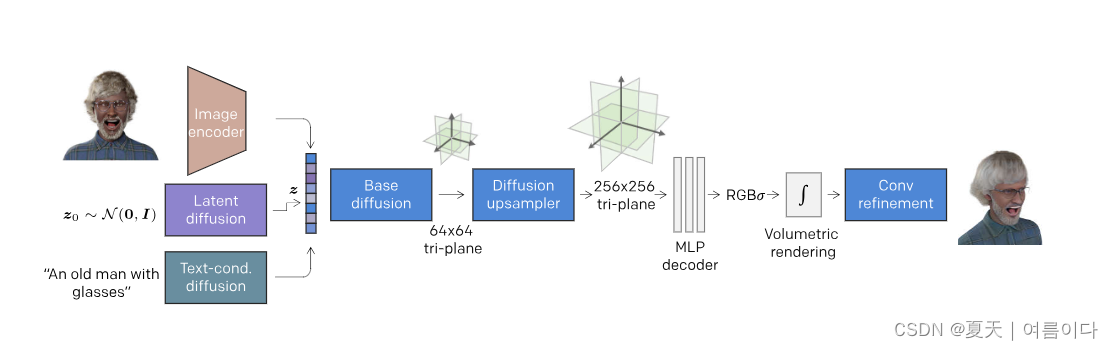
2.2.2022_Rodin: A Generative Model for Sculpting 3D Digital Avatars Using Diffusion
论文地址:2212.06135.pdf (arxiv.org)
论文代码:cbritopacheco/rodin: Modern C++17 finite element method and shape optimization framework. (github.com)
论文Demo:RODIN Diffusion (microsoft.com)Rodin Diffusion: A Generative Model for Sculpting 3D Digital Avatars - Microsoft Research
该 3D 化身扩散模型经过训练,可生成表示为神经辐射场的 3D 数字头像。以最先进的生成技术(扩散模型)为基础进行3D建模。使用三平面表示来分解化身的神经辐射场,可以通过扩散模型显式建模,并通过体积渲染渲染到图像中。所提出的3D感知卷积带来了急需的计算效率,同时保持了3D扩散建模的完整性。整个生成是一个分层过程,具有用于多尺度建模的级联扩散模型。一旦生成模型被训练,就可以根据从输入图像、文本提示或随机噪声派生的潜在代码来控制头像的生成。
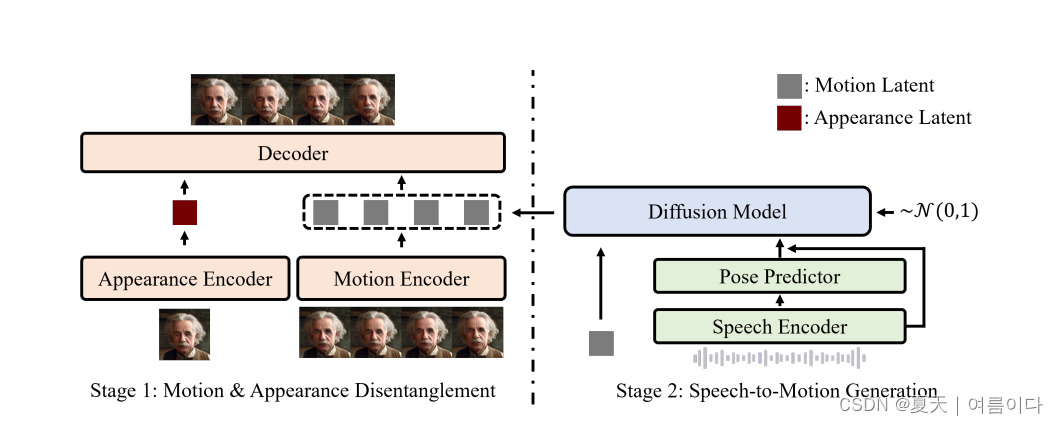
2.3.2023.11.26_GAIA: ZERO-SHOT TALKING AVATAR GENERATION
论文题目:2023.11.26GAIA: ZERO-SHOT TALKING AVATAR GENERATION
论文地址:2311.15230.pdf (arxiv.org)
论文代码:20231205暂未发布
论文摘要
零样本说话头像生成旨在从语音和单个肖像图像中合成自然的说话视频。以前的方法依赖于特定领域的启发式方法,例如基于变形的运动表示和 3D 可变形模型,这限制了生成的化身的自然性和多样性。在这项工作中,引入了 GAIA(Generative AI for Avatar),它消除了说话头像生成中的领域先验。鉴于语音仅驱动化身的运动,而化身的外观和背景在整个视频中通常保持不变,将方法分为两个阶段:1)将每一帧解开为运动和外观表示;2)生成以语音和参考人像图像为条件的运动序列。我们收集了一个大规模的高质量会说话的头像数据集,并在其上用不同的尺度(最多 2B 参数)训练模型。实验结果验证了GAIA的优越性、可扩展性和灵活性,1)所得模型在自然性、多样性、口型同步质量和视觉质量方面优于以前的基线模型;2)该框架是可扩展的,因为更大的模型会产生更好的结果;3)它是通用的,可以支持不同的应用,如可控的说话头像生成和文本指示的头像生成。
参考文献
【1】3D human reconstruction人体重建论文小合集 - 知乎 (zhihu.com)
【2】【精选】2022 CVPR 三维人体重建相关论文汇总(3D Human Reconstruction)_3d人体重建_BTWBB的博客-CSDN博客 【3】【技术综述】基于3DMM的三维人脸重建技术总结 - 知乎 (zhihu.com)
【4】 imbinwang/awesome-nerf-3d-reconstruction (github.com)
【5】PIFuHD: Multi-Level Pixel-Aligned Implicit Function for High-Resolution 3D Human Digitization (shunsukesaito.github.io)