来源:https://www.bilibili.com/video/BV1Bb4y1L7FT?p=1&vd_source=f66cebc7ed6819c67fca9b4fa3785d39
文章目录
- 引言
- self-attention
- 运作机制
- b1是如何产生的
- 怎么求关联性数值 α \alpha α
- 从矩阵乘法的角度再来一次
- 从A得到Q、K、V
- 从Q、K得到 α \alpha α矩阵
- 由V和A'得到b1-b4
- 总结:从I到O就是在做self-attention
- Muti-head Self-attention
- 位置编码
self-attention要解决的问题:输入的sequence是变长的、长度不等。
引言
如何解决输入同样的saw,第一个输出v.第二个输出n.?
使用FC可以考虑上下文的资讯。
如何考虑一整个sequence的资讯呢?
把Windows开到sequence中最大的长度。
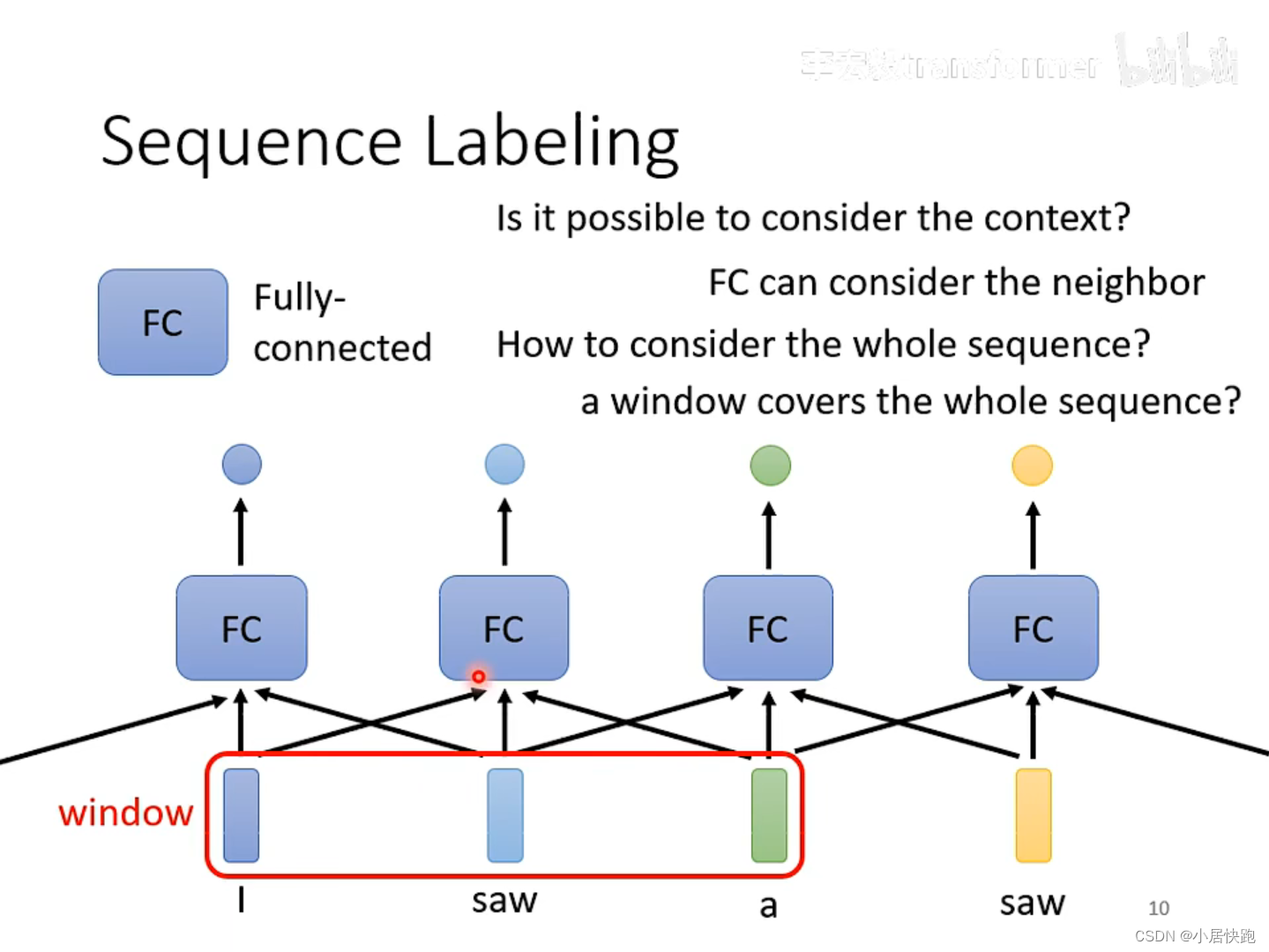
self-attention
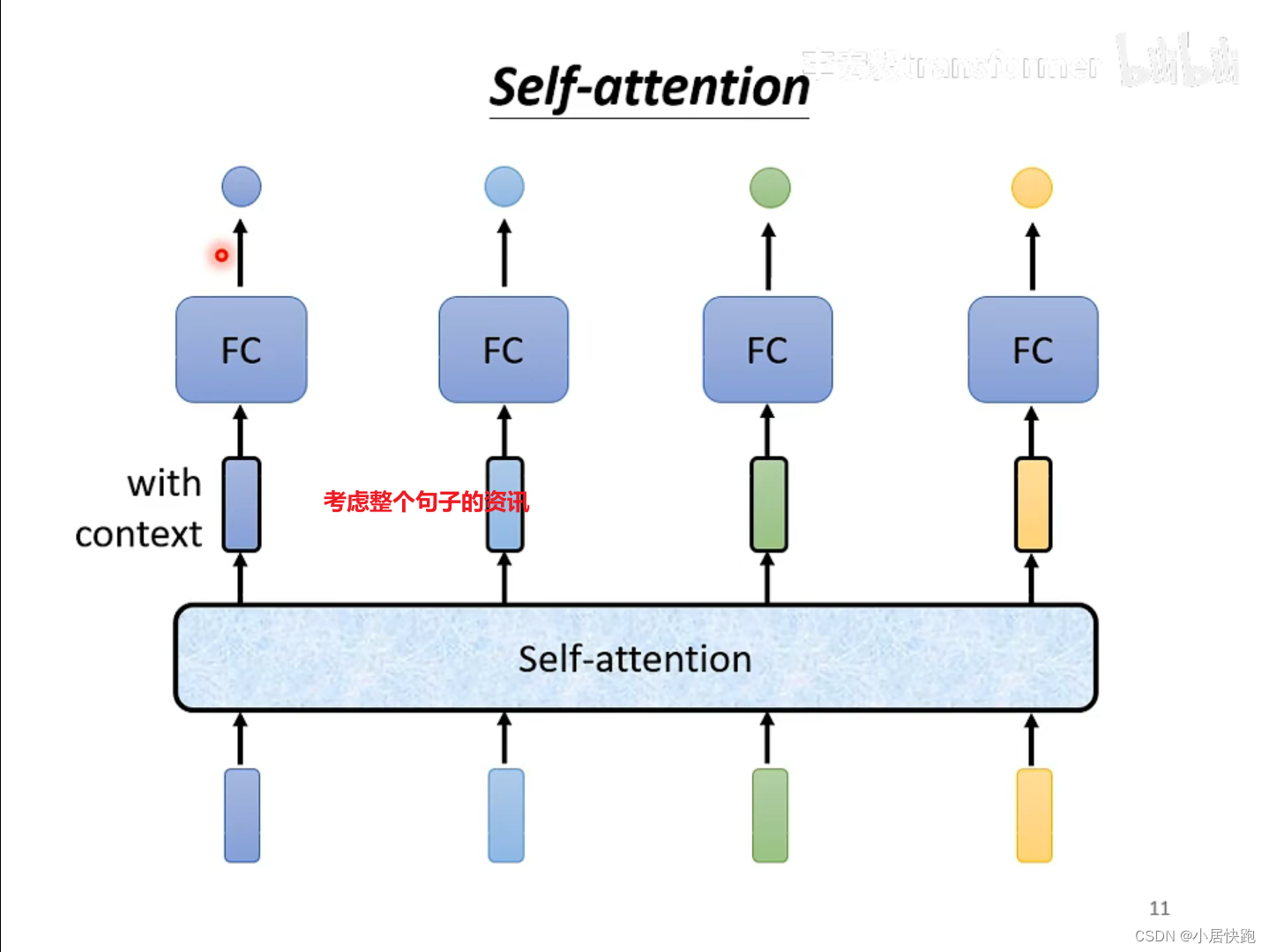
可以将self-attention与FC交替使用:
self-attention处理整个句子的资讯
FC专注于处理某一个位置的资讯、

运作机制
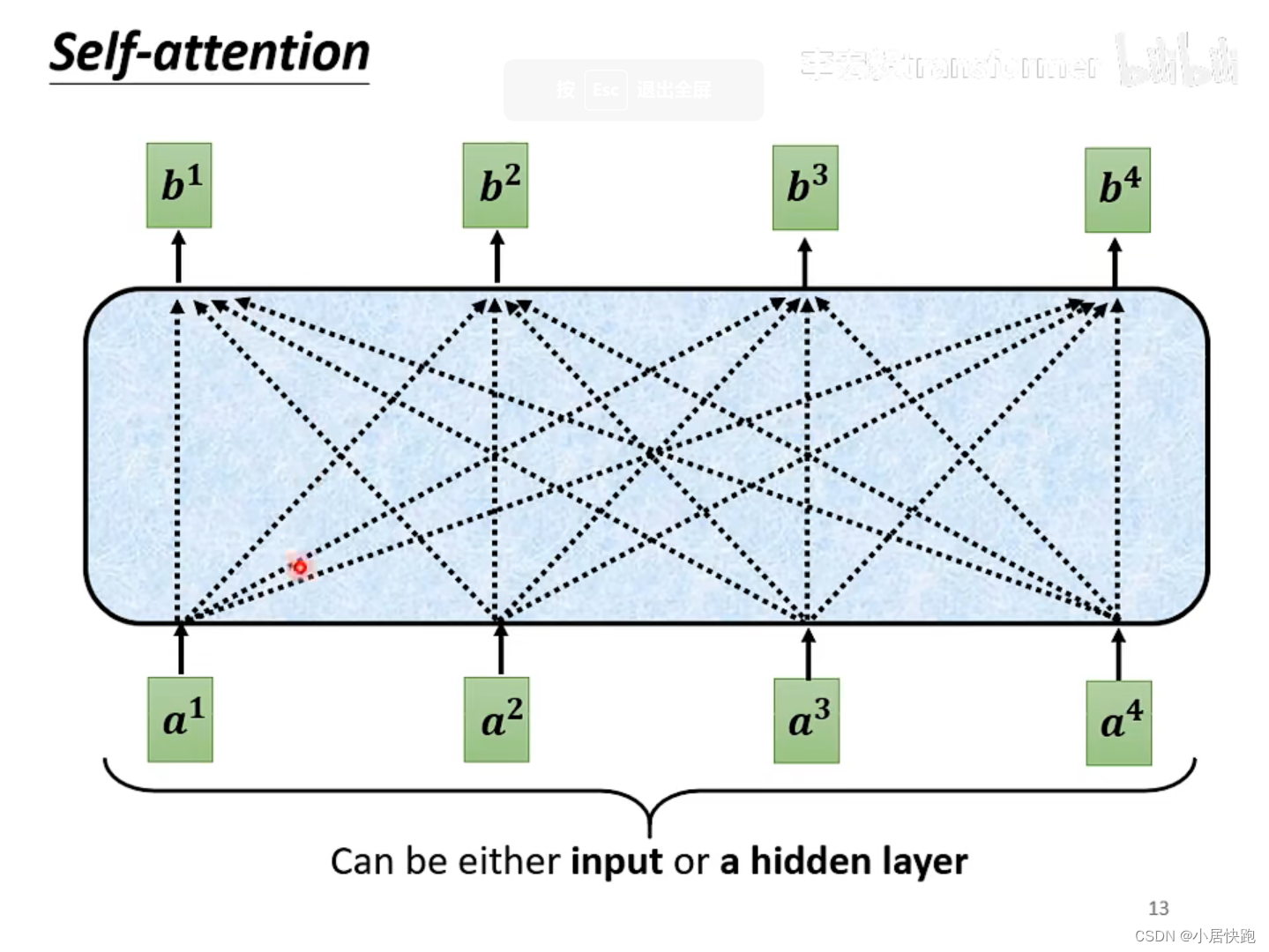
b1是如何产生的
1、计算出attention score
α
\alpha
α:在这个长长的sequence里找出和a1有关联的vector,每个向量与a1的关联性用数值
α
\alpha
α表示。
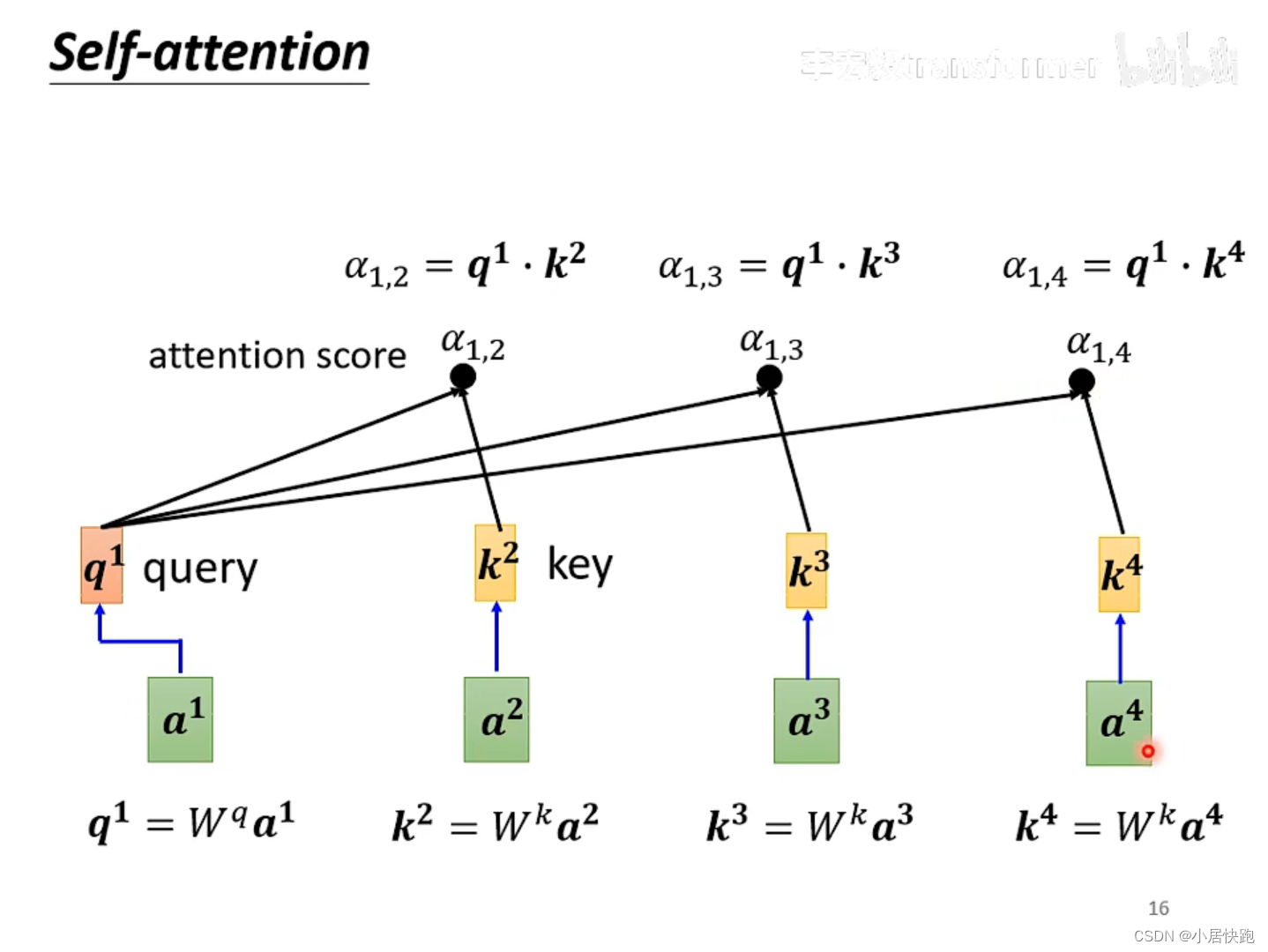
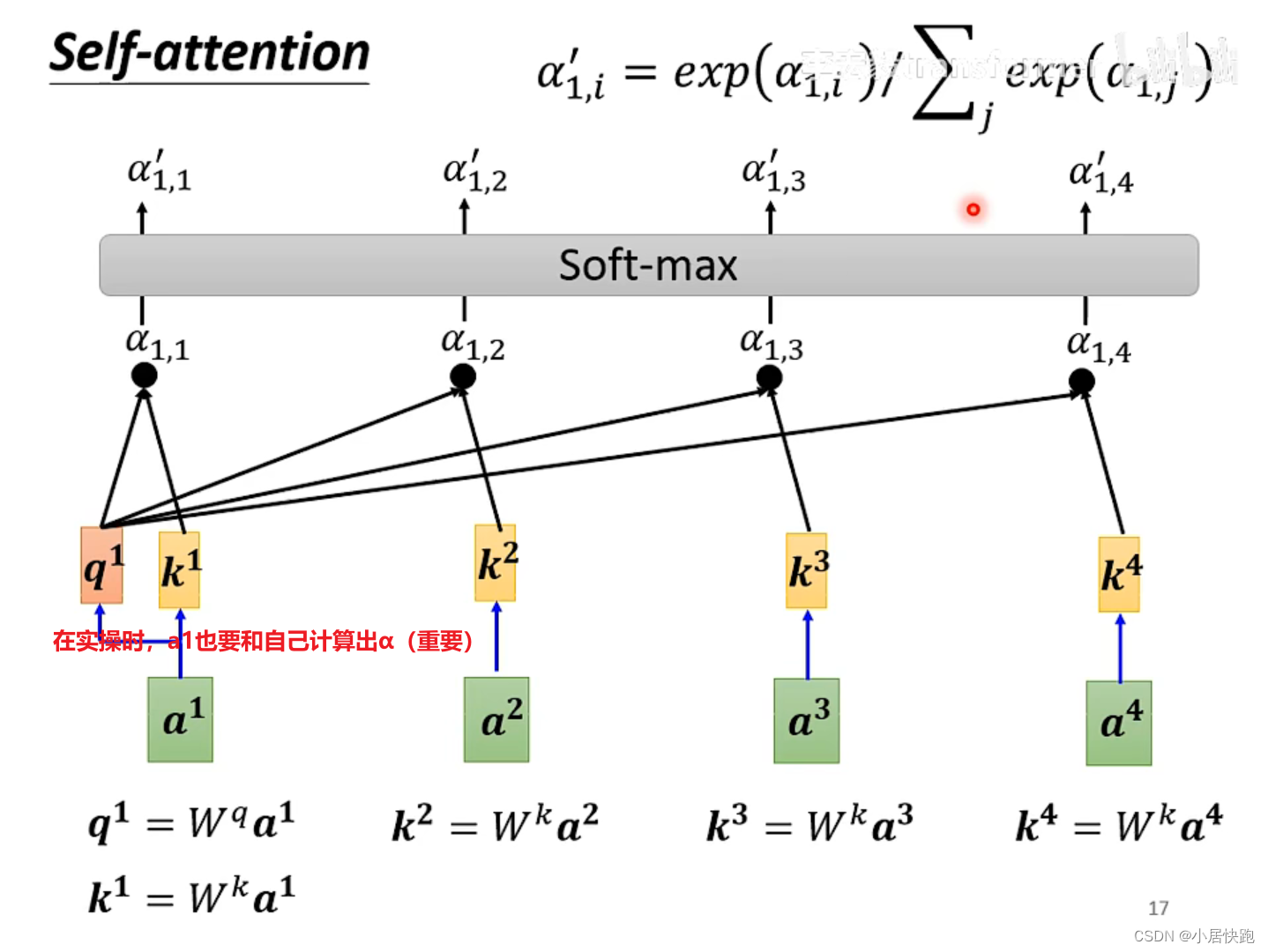
2、根据attention score抽取sequence里的重要资讯,即可计算出b1
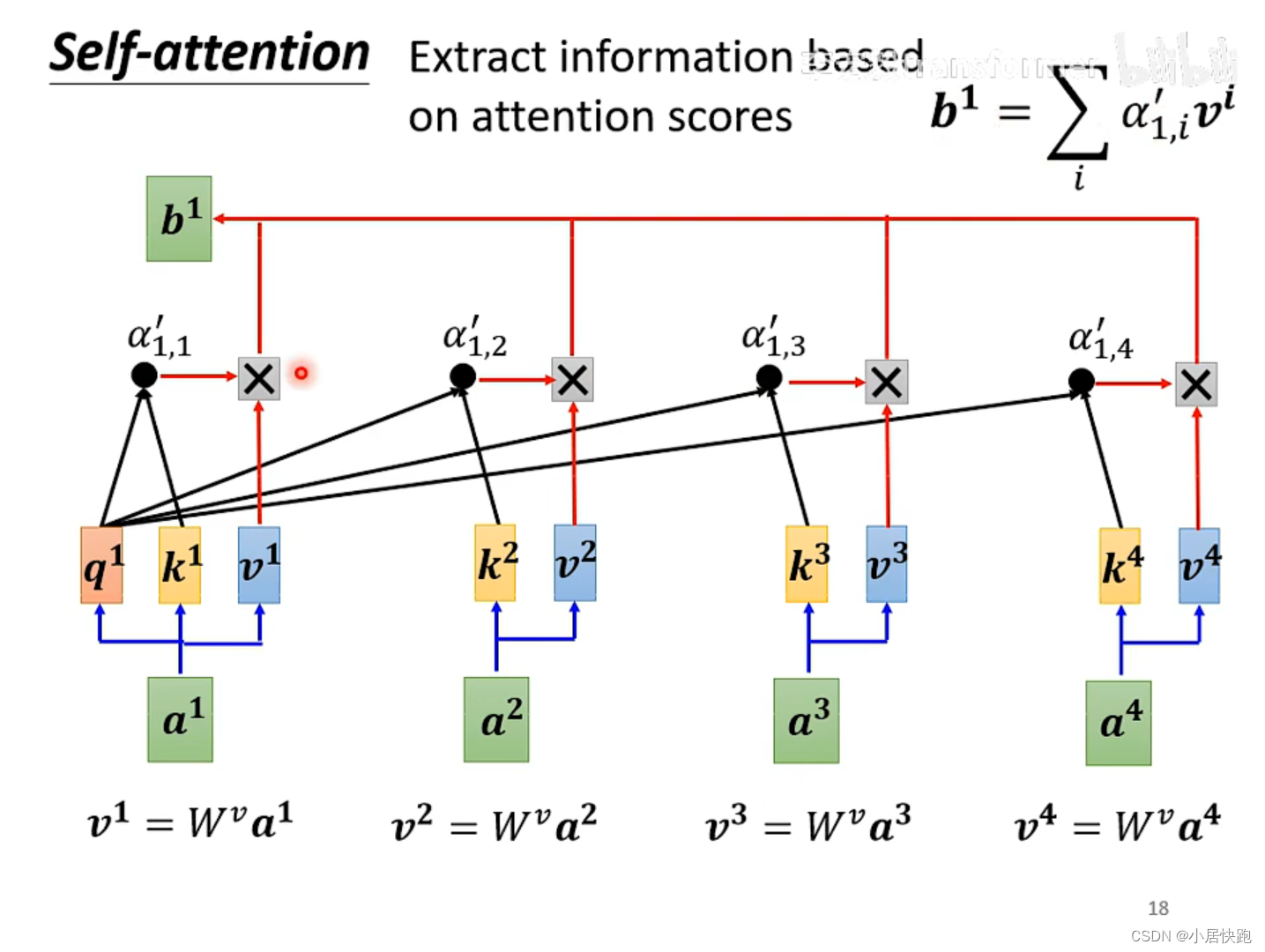
注:b1-b4是同时被产生的
怎么求关联性数值 α \alpha α
两种方法:

最常用的是向量点积法,也是用在transformer里的方法。
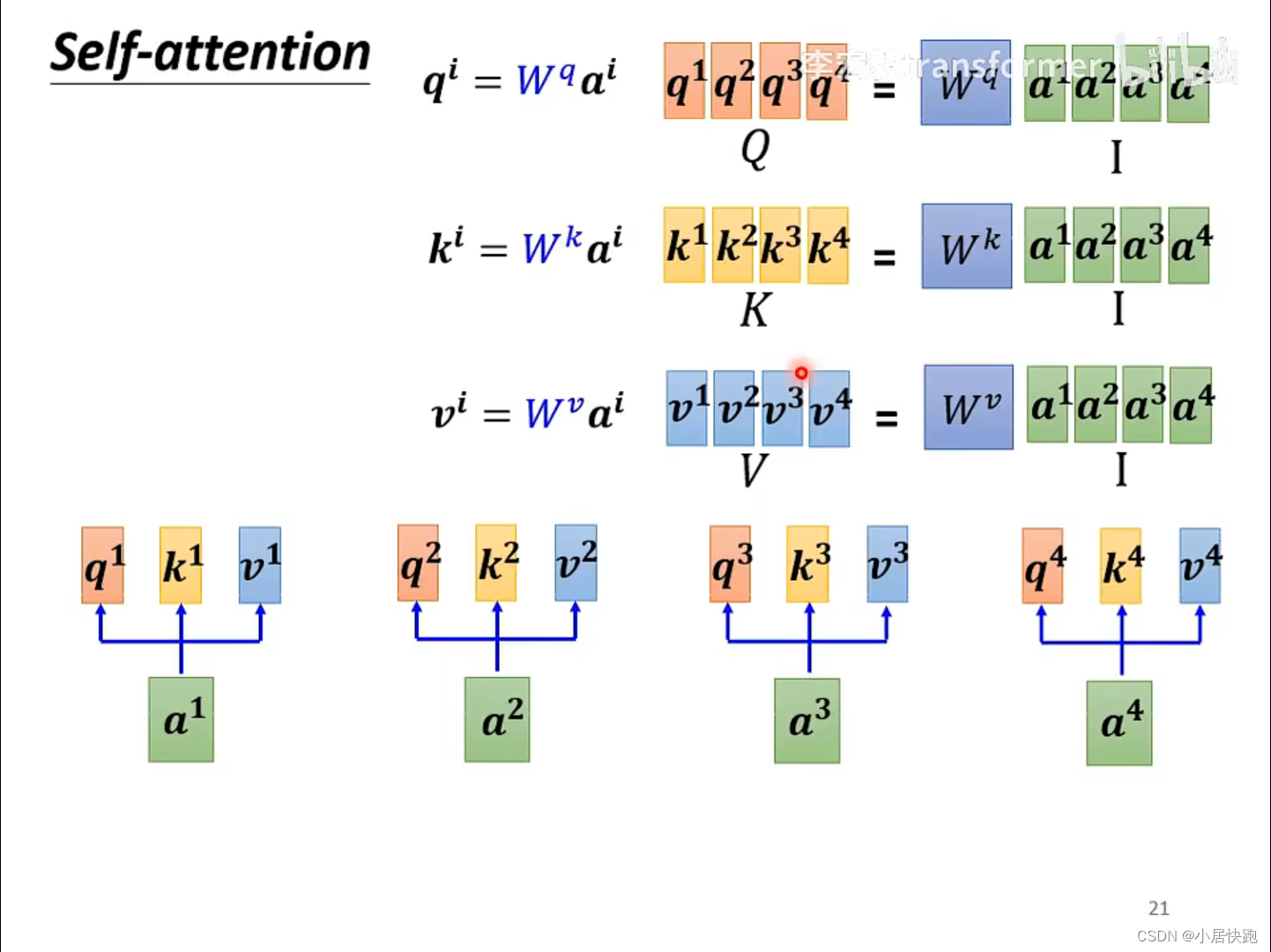
从矩阵乘法的角度再来一次
从A得到Q、K、V
从Q、K得到 α \alpha α矩阵
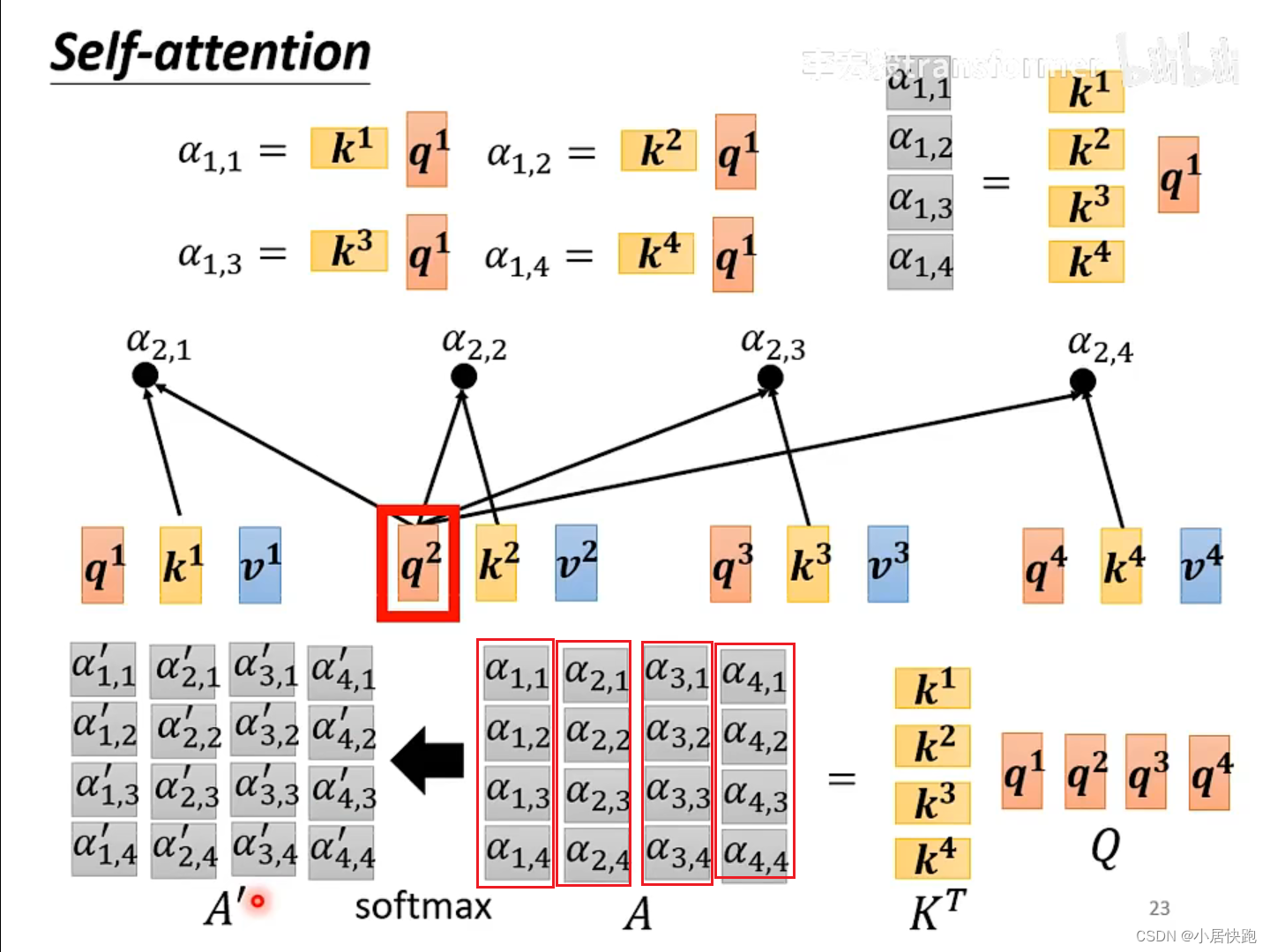
由V和A’得到b1-b4

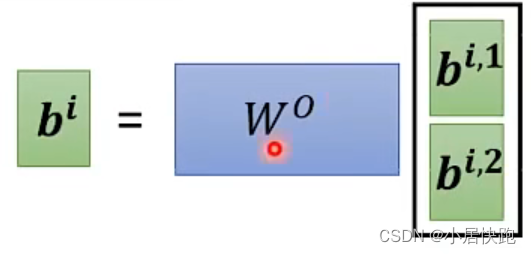
总结:从I到O就是在做self-attention

Muti-head Self-attention
几个head,是一个需要调的超参。
为什么要用Muti-head?
使用不同的q代表不同种类的相关性。

位置编码




![Electron[4] Electron最简单的打包实践](https://img-blog.csdnimg.cn/direct/1af744d223624f0faac86a65b536ef9f.png)