一.自定义函数
1.Hive自带了一些函数,比如:max/min等,但是数量有限,自己可以通过自定义UDF来方便的扩展。
2.当Hive提供的内置函数无法满足你的业务处理需要时,此时就可以考虑使用用户自定义函数。
3.根据用户自定义函数类别分为以下三种:
(1)UDF(User-Defined-Function) 一进一出。
(2)UDAF(User-Defined Aggregation Function) 用户自定义聚合函数,多进一出 。
(3)UDTF(User-Defined Table-Generating Functions) 用户自定义表生成函数,一进多出。
4.编程步骤
(1)继承Hive提供的类
org.apache.hadoop.hive.ql.udf.generic.GenericUDF
org.apache.hadoop.hive.ql.udf.generic.GenericUDTF
org.apache.hadoop.hive.ql.udf.generic.GenericUDAFEvaluator
(2)实现类中的抽象方法
(3)在hive的命令行窗口创建函数
(4) 创建临时函数
需要把jar包上传到服务器上面
添加jar。
add jar linux_jar_path
创建function
create temporary function dbname.function_name AS class_name;
删除函数
drop temporary function if exists dbname.function_name;
(5)创建永久函数
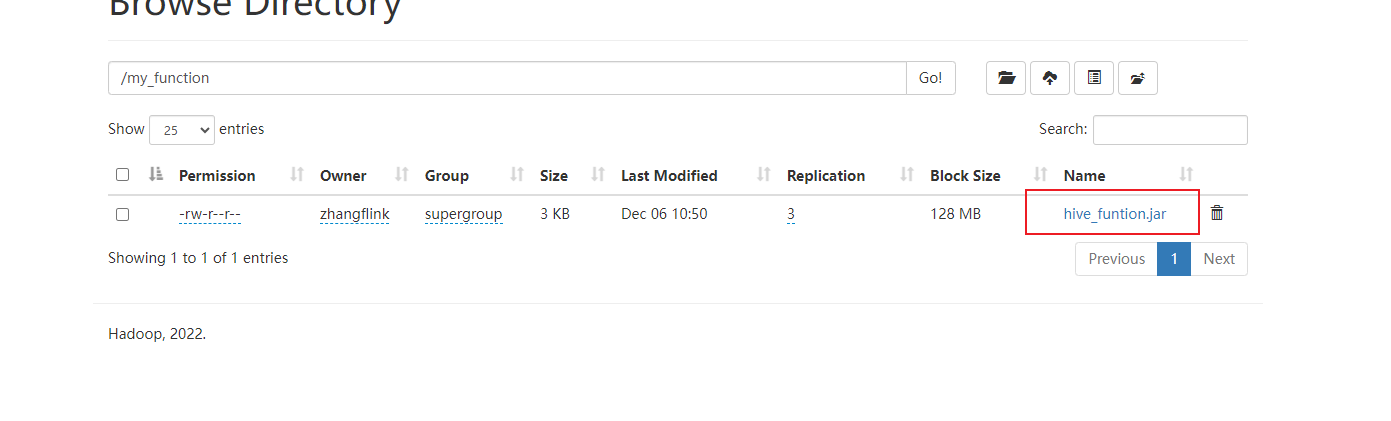
需要把jar包上传到hdfs上面,创建函数时jar包的位置使用hdfs的地址。
创建function
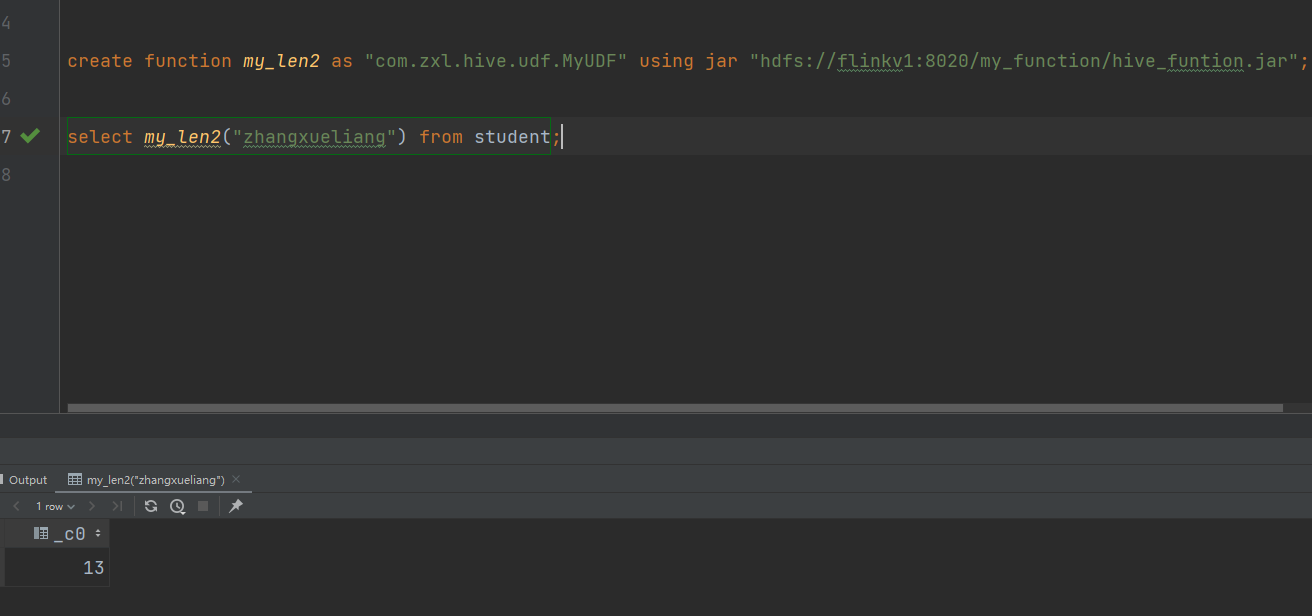
create function if exists my_udtf as "com.zxl.hive.udf.ExplodeJSONArray" using jar "hdfs://flinkv1:8020/my_function/hive_udtf_funtion.jar";
删除函数
drop function if exists my_udtf ;
注意:永久函数跟会话没有关系,创建函数的会话断了以后,其他会话也可以使用。 永久函数创建的时候,在函数名之前需要自己加上库名,如果不指定库名的话,会默认把当前库的库名给加上。 永久函数使用的时候,需要在指定的库里面操作,或者在其他库里面使用的话加上,库名.函数名。
二.UDF
官方案例:https://cwiki.apache.org/confluence/display/Hive/HivePlugins#HivePlugins-CreatingCustomUDFs
计算给定基本数据类型的长度
package com.zxl.hive.udf;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.exec.UDFArgumentLengthException;
import org.apache.hadoop.hive.ql.exec.UDFArgumentTypeException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
public class MyUDF extends GenericUDF {
/*
* 判断传进来的参数的类型和长度
* 约定返回的数据类型
* */
@Override
public ObjectInspector initialize(ObjectInspector[] arguments) throws UDFArgumentException {
//判断传进来的参数的长度
if (arguments.length !=1) {
throw new UDFArgumentLengthException("please give me only one arg");
}
//判断传进来的参数的类型
if (!arguments[0].getCategory().equals(ObjectInspector.Category.PRIMITIVE)){
throw new UDFArgumentTypeException(1, "i need primitive type arg");
}
// 约定返回的数据类型
return PrimitiveObjectInspectorFactory.javaIntObjectInspector;
}
/*
* 具体解决逻辑
* */
@Override
public Object evaluate(DeferredObject[] arguments) throws HiveException {
Object o = arguments[0].get();
if(o==null){
return 0;
}
return o.toString().length();
}
/*
* 用于获取解释的字符串
* */
@Override
public String getDisplayString(String[] strings) {
return "";
}
}
(1)创建永久函数
注意:因为add jar本身也是临时生效,所以在创建永久函数的时候,需要制定路径(并且因为元数据的原因,这个路径还得是HDFS上的路径)。
三.UDTF
官网案例:https://cwiki.apache.org/confluence/display/Hive/DeveloperGuide+UDTF
执行步骤
要实现UDTF,我们需要继承org.apache.hadoop.hive.ql.udf.generic.GenericUDTF,实现initialize, process, close三个方法。
UDTF首先会调用initialize方法,此方法返回UDTF的返回行的信息,返回个数,类型;
初始化完成后,会调用process方法,真正的处理过程在process函数中,在process中,每一次forward()调用产生一行;如果产生多列可以将多个列的值放在一个数组中,然后将该数组传入到forward()函数;
最后close()方法调用,对需要清理的方法进行清理。
关于HIVE的UDTF自定义函数使用的更多详细内容请看:
转载原文链接:https://blog.csdn.net/lidongmeng0213/article/details/110877351
下面是json日志解析案例:
package com.zxl.hive.udf;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.exec.UDFArgumentLengthException;
import org.apache.hadoop.hive.ql.exec.UDFArgumentTypeException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDTF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.objectinspector.StructObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
import org.json.JSONArray;
import java.util.ArrayList;
import java.util.List;
public class ExplodeJSONArray extends GenericUDTF {
/**
* 初始化方法,里面要做三件事
* 1.约束函数传入参数的个数
* 2.约束函数传入参数的类型
* 3.约束函数返回值的类型
*/
@Override
public StructObjectInspector initialize(StructObjectInspector argOIs) throws UDFArgumentException {
// TODO: 2023/12/6 返回结构体类型。udtf函数,有可能炸开之后形成多列。所以用返回结构体来封装。属性名:属性值。属性名就是列名;属性值就是列的类型。
//用结构体,来约束函数传入参数的个数
//List<? extends StructField> allStructFieldRefs = argOIs.getAllStructFieldRefs(); --见名知意,获取结构体所有属性的引用 可以看见返回值是个list类型.
if(argOIs.getAllStructFieldRefs().size()!=1){ //只要个数不等于1,就抛出异常
throw new UDFArgumentLengthException("explode_json_array()函数的参数个数只能为1");
}
//2.约束函数传入参数的类型
// StructField structField = argOIs.getAllStructFieldRefs().get(0);//只能有一个参数,所以index给0 可以看见,是获得结构体的属性
//ObjectInspector fieldObjectInspector = argOIs.getAllStructFieldRefs().get(0).getFieldObjectInspector();//获得属性的对象检测器 。通过检查器我们才能知道是什么类型.
String typeName = argOIs.getAllStructFieldRefs().get(0).getFieldObjectInspector().getTypeName();
//我们要确保传入的类型是string
if(!"string".equals(typeName)){
throw new UDFArgumentTypeException(0,"explode_json_array函数的第1个参数的类型只能为String."); //抛出异常
}
//3.约束函数返回值的类型
List<String> fieldNames = new ArrayList<>(); //② 表示我建立了一个String类型的集合。表示存储的列名
List<ObjectInspector> fieldOIs = new ArrayList<>(); //②
fieldNames.add("item"); //炸裂之后有个列名,如果不重新as,那这个item就是列名
fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector); //表示item这一列是什么类型.基本数据类型工厂类,获取了个string类型的检查器
//用一个工厂类获取StructObjectInspector类型。
return ObjectInspectorFactory.getStandardStructObjectInspector(fieldNames,fieldOIs);//①获取标准结构体检查器。fieldNames,fieldOI是两个变量名
}
//这里是实现主逻辑的方法。首先分析下需求:把json array字符串变成一个json字符串
@Override
public void process(Object[] args) throws HiveException {
//1 获取函数传入的jsonarray字符串
String jsonArrayStr = args[0].toString(); //我要把jsonArrayStr字符串划分为一个一个的json,通过字符串这种类型是不好划分的。不知道如何split切分
//2 将jsonArray字符串转换成jsonArray数组。正常情况下我们要引入依赖,比如fastjson啥的。
JSONArray jsonArray = new JSONArray(jsonArrayStr); //通过JSONArray这种类型,我们就比较容易获得一条条的json字符串
//3 得到jsonArray里面的一个个json,并把他们写出。将actions里面的一个个action写出
for (int i = 0; i < jsonArray.length(); i++) { //普通for循环进行遍历
String jsonStr = jsonArray.getString(i);//前面定义了,要返回String
//forward是最后收集数据返回的方法
forward(jsonStr);
}
}
@Override
public void close() throws HiveException {
}
}
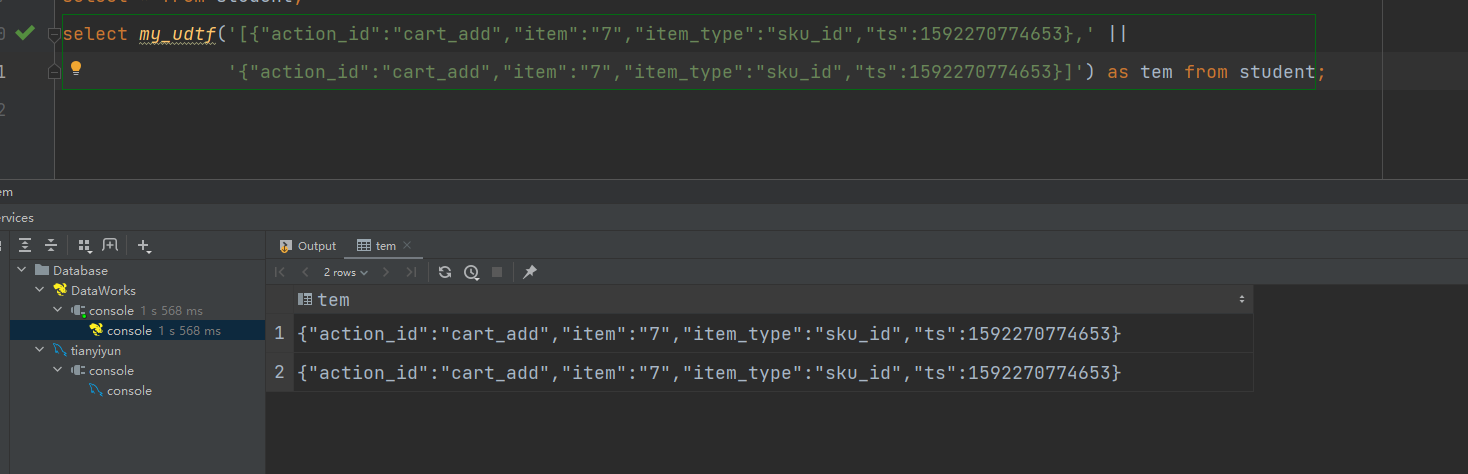
注意:UDTF函数不能和其他字段同时出现在select语句中,负责SQL会执行失败
三.UDAF
官网案例:https://cwiki.apache.org/confluence/display/Hive/GenericUDAFCaseStudy#GenericUDAFCaseStudy-Writingtheresolver
执行步骤:
编写自定义函数需要创建三个类:
1.继承 AbstractGenericUDAFResolver重写 getEvaluator方法,对传入的值进行判断。
2.创建数据缓存区,创建一些变量来进行调用赋值,作为中间值,类似于flink的checkpoints。
3.继承GenericUDAFEvaluator类重写方法即可,实现具体逻辑的类。
参考文章:
UDAF重要的类及原理分析(UDAF继承类的各个方法的用法)
原文链接:https://blog.csdn.net/lidongmeng0213/article/details/110869457
Hive之ObjectInspector详解(UDAF中用到的类型详解)
原文链接:https://blog.csdn.net/weixin_42167895/article/details/108314139
一个类似于SUM的自定义函数:
import org.apache.hadoop.hive.ql.exec.UDFArgumentLengthException;
import org.apache.hadoop.hive.ql.exec.UDFArgumentTypeException;
import org.apache.hadoop.hive.ql.parse.SemanticException;
import org.apache.hadoop.hive.ql.udf.generic.AbstractGenericUDAFResolver;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDAFEvaluator;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDAFParameterInfo;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.PrimitiveObjectInspector;
import org.apache.hadoop.hive.serde2.typeinfo.TypeInfo;
import org.apache.hadoop.hive.serde2.typeinfo.TypeInfoUtils;
// TODO: 2023/12/9 继承 AbstractGenericUDAFResolver重写 getEvaluator方法
public class FieldSum extends AbstractGenericUDAFResolver {
@Override
public GenericUDAFEvaluator getEvaluator(TypeInfo[] info) throws SemanticException {
// TODO: 2023/12/9 判断传入的参数是否为一个
if (info.length != 1) {
throw new UDFArgumentLengthException("只能传入一个参数, 但是现在有 " + info.length + "个参数!");
}
/*TypeInfoUtils是一个Java类,它提供了一些用于处理Hive数据类型的实用方法。以下是TypeInfoUtils类中的一些方法及其功能:
getTypeInfoFromTypeString(String typeString) - 将类型字符串转换为Hive数据类型信息对象。
getStandardJavaObjectInspectorFromTypeInfo(TypeInfo typeInfo) - 从Hive数据类型信息对象中获取标准Java对象检查器。
isExactNumericType(PrimitiveTypeInfo typeInfo) - 检查给定的Hive原始数据类型是否为精确数值类型。
getCategoryFromTypeString(String typeString) - 从类型字符串中获取Hive数据类型的类别。
getPrimitiveTypeInfoFromPrimitiveWritable(Class<? extends Writable> writableClass) -
从Hadoop Writable类中获取Hive原始数据类型信息对象。*/
ObjectInspector objectInspector = TypeInfoUtils.getStandardJavaObjectInspectorFromTypeInfo(info[0]);
// TODO: 2023/12/9 判断是不是标准的java Object的primitive类型
if (objectInspector.getCategory() != ObjectInspector.Category.PRIMITIVE) {
throw new UDFArgumentTypeException(0, "Argument type must be PRIMARY. but " +
objectInspector.getCategory().name() + " was passed!");
}
// 如果是标准的java Object的primitive类型,说明可以进行类型转换
PrimitiveObjectInspector inputOI = (PrimitiveObjectInspector) objectInspector;
// 如果是标准的java Object的primitive类型,判断是不是INT类型,因为参数只接受INT类型
if (inputOI.getPrimitiveCategory() != PrimitiveObjectInspector.PrimitiveCategory.INT) {
throw new UDFArgumentTypeException(0, "Argument type must be INT, but " +
inputOI.getPrimitiveCategory().name() + " was passed!");
}
return new FieldSumUDAFEvaluator();
}
@Override
public GenericUDAFEvaluator getEvaluator(GenericUDAFParameterInfo info) throws SemanticException {
return super.getEvaluator(info);
}
}
import org.apache.hadoop.hive.ql.udf.generic.GenericUDAFEvaluator;
// TODO: 2023/12/9 创建数据缓存区,创建一些变量来进行调用赋值,作为中间值,类似于flink的checkpoints。
public class FieldSumBuffer extends GenericUDAFEvaluator.AbstractAggregationBuffer {
Integer num = 0;
// TODO: 2023/12/9 实现变量的get,set方法方便后面赋值,取值
public Integer getNum() {
return num;
}
public void setNum(int num) {
this.num = num;
}
// TODO: 2023/12/9 创建累加的方法,方便对变量进行累加
public Integer addNum(int aum) {
num += aum;
return num;
}
}
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDAFEvaluator;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.objectinspector.PrimitiveObjectInspector;
// TODO: 2023/12/9 实现具体逻辑的地方 直接继承GenericUDAFEvaluator类重写方法即可
public class FieldSumUDAFEvaluator extends GenericUDAFEvaluator {
// TODO: 2023/12/9 初始输入的变量 PrimitiveObjectInspector是Hadoop里面原始数据类别
PrimitiveObjectInspector inputNum;
PrimitiveObjectInspector middleNum;
// TODO: 2023/12/9 最终输出的变量
ObjectInspector outputNum;
// TODO: 2023/12/9 最终统计值的变量
int sumNum;
// TODO: 2023/12/7 Model代表了UDAF在mapreduce的各个阶段。
//* PARTIAL1: 这个是mapreduce的map阶段:从原始数据到部分数据聚合
//* 将会调用iterate()和terminatePartial()
//* PARTIAL2: 这个是mapreduce的map端的Combiner阶段,负责在map端合并map的数据::从部分数据聚合到部分数据聚合:
//* 将会调用merge() 和 terminatePartial()
//* FINAL: mapreduce的reduce阶段:从部分数据的聚合到完全聚合
//* 将会调用merge()和terminate()
//* COMPLETE: 如果出现了这个阶段,表示mapreduce只有map,没有reduce,所以map端就直接出结果了:从原始数据直接到完全聚合
//* 将会调用 iterate()和terminate()
// TODO: 2023/12/7 确定各个阶段输入输出参数的数据格式ObjectInspectors
@Override
public ObjectInspector init(Mode m, ObjectInspector[] parameters) throws HiveException {
super.init(m, parameters);
// TODO: 2023/12/9 COMPLETE或者PARTIAL1,输入的都是数据库的原始数据所以要确定输入的数据格式
if (m == Mode.PARTIAL1 || m == Mode.COMPLETE) {
inputNum = (PrimitiveObjectInspector) parameters[0];
} else {
middleNum = (PrimitiveObjectInspector) parameters[0];
}
// TODO: 2023/12/9 ObjectInspectorFactory是创建新的ObjectInspector实例的主要方法:一般用于创建集合数据类型。输出的类型是Integer类型,java类型
outputNum = ObjectInspectorFactory.getReflectionObjectInspector(Integer.class,
ObjectInspectorFactory.ObjectInspectorOptions.JAVA);
return outputNum;
}
// TODO: 2023/12/9 保存数据聚集结果的类
@Override
public AggregationBuffer getNewAggregationBuffer() throws HiveException {
return new FieldSumBuffer();
}
// TODO: 2023/12/9 重置聚集结果
@Override
public void reset(AggregationBuffer agg) throws HiveException {
//重新赋值为零
((FieldSumBuffer) agg).setNum(0);
}
// TODO: 2023/12/9 map阶段,迭代处理输入sql传过来的列数据,不断被调用执行的方法,最终数据都保存在agg中,parameters是新传入的数据
@Override
public void iterate(AggregationBuffer agg, Object[] parameters) throws HiveException {
// TODO: 2023/12/9 判断如果传入的值是空的直接返回
if (parameters == null || parameters.length < 1) {
return;
}
Object javaObj = inputNum.getPrimitiveJavaObject(parameters[0]);
((FieldSumBuffer) agg).addNum(Integer.parseInt(javaObj.toString()));
}
// TODO: 2023/12/9 map与combiner结束返回结果,得到部分数据聚集结果
@Override
public Object terminatePartial(AggregationBuffer agg) throws HiveException {
return terminate(agg);
}
// TODO: 2023/12/9 combiner合并map返回的结果,还有reducer合并mapper或combiner返回的结果。
@Override
public void merge(AggregationBuffer agg, Object partial) throws HiveException {
((FieldSumBuffer) agg).addNum((Integer) middleNum.getPrimitiveJavaObject(partial));
}
// TODO: 2023/12/9 map阶段,迭代处理输入sql传过来的列数据
@Override
public Object terminate(AggregationBuffer agg) throws HiveException {
Integer num = ((FieldSumBuffer) agg).getNum();
return num;
}
}
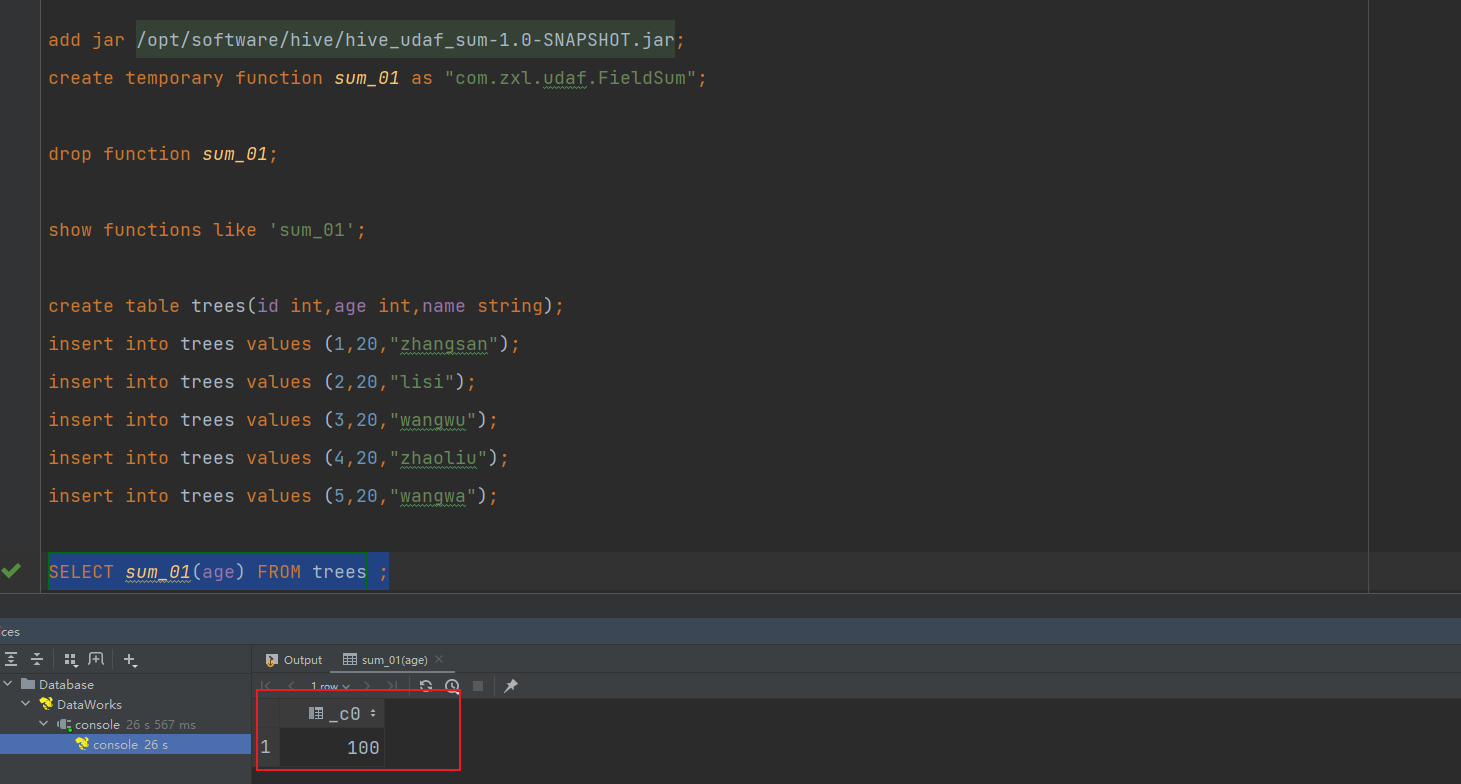
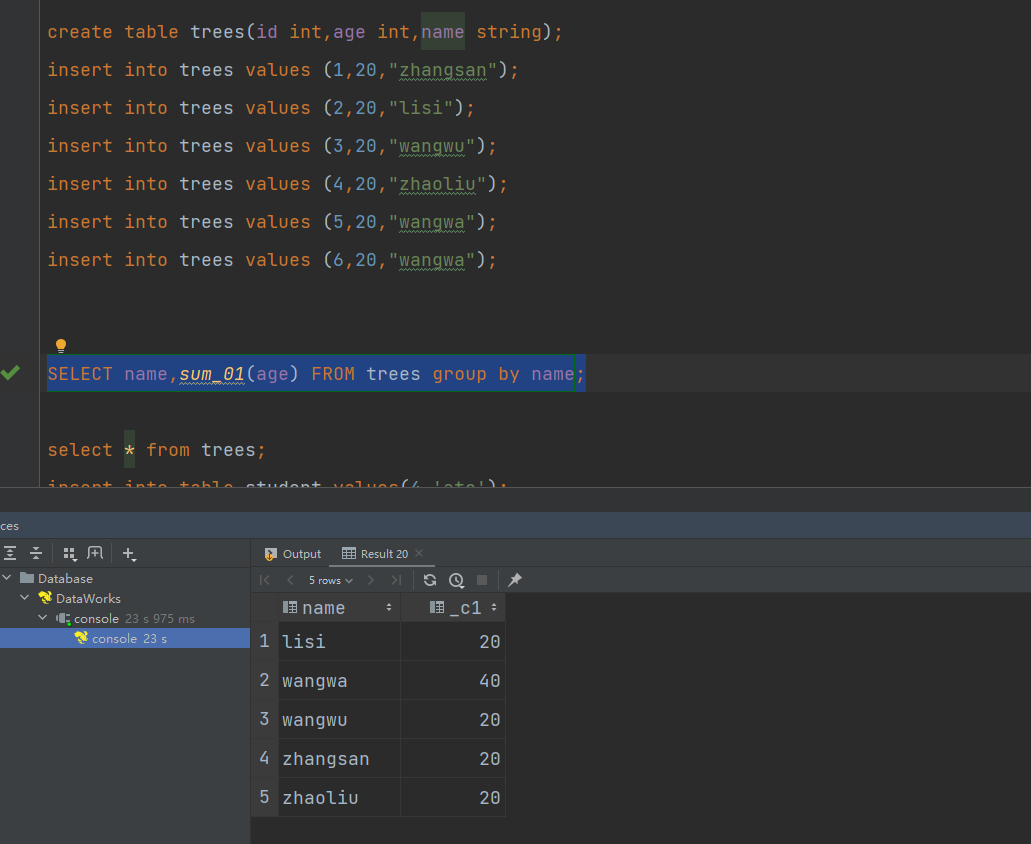
打包上传,注册函数进行测试:
可以看到实现了对参数的判断和参数类型的判断
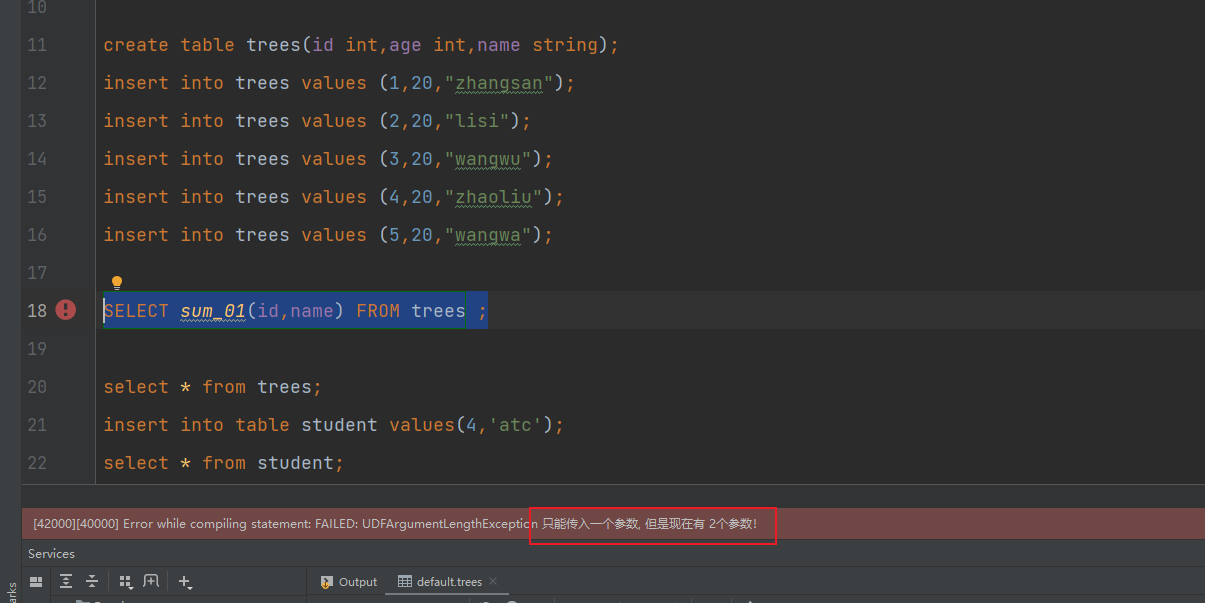
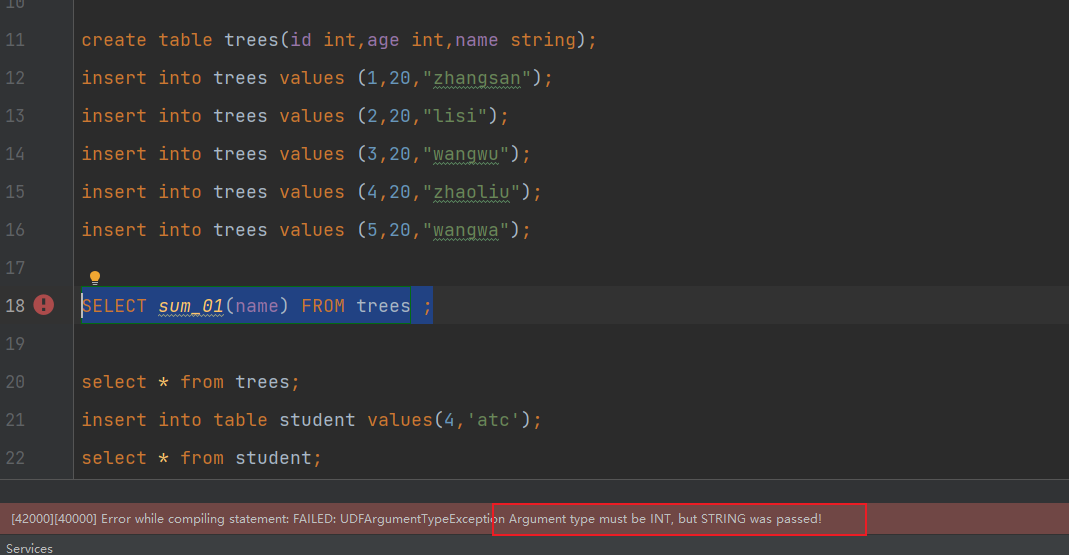
执行查询测试: