前言
大家好吖,欢迎来到 YY 滴C++系列 ,热烈欢迎! 本章主要内容面向接触过C++的老铁
主要内容含:
欢迎订阅 YY滴C++专栏!更多干货持续更新!以下是传送门!
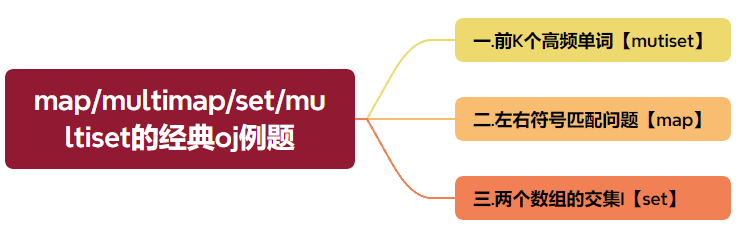
目录
- 一.前K个高频单词【mutiset】
- 二.左右符号匹配问题【map】
- 三.两个数组的交集I【set】
一.前K个高频单词【mutiset】
题目:求一个
vector<string>中出现最高频的前k个单词
分析:
- 本题中需要用到mutiset的性质:可以重复的key
- 由于mutiset默认是从小到大比,所以我们要先设置一个 仿函数Compare实现从大到小排序
- 用<单词,单词出现次数>构建键值对,然后将vector中的单词放进去,统计每个单词出现的次数
- 利用mutiset的存储也是键值对:将单词按照其出现次数进行排序,出现相同次数的单词集中在一块 【count = e.second】
- 分批塞入新的set中,当下一个mutiset的引用的计数小于(即不等于)前者时,将set中的元素压入vector,随后清空set,重复以上
- 最后把mutiset导空后,可能还会剩下一组数据在set中,此时再根据需求进行导入
class Solution {
public:
class Compare
{
public:
// 在set中进行排序时的比较规则
bool operator()(const pair<string, int>& left, const pair<string, int>& right)
{
return left.second > right.second;
}
};
vector<string> topKFrequent(vector<string>& words, int k)
{
// 用<单词,单词出现次数>构建键值对,然后将vector中的单词放进去,统计每个单词出现的次数
map<string, int> m;
for (size_t i = 0; i < words.size(); ++i)
++(m[words[i]]);
// 将单词按照其出现次数进行排序,出现相同次数的单词集中在一块
multiset<pair<string, int>, Compare> ms(m.begin(), m.end());
// 将相同次数的单词放在set中,然后再放到vector中
set<string> s;
size_t count = 0; // 统计相同次数单词的个数
size_t leftCount = k;
vector<string> ret;
for (auto& e : ms)
{
if (!s.empty())
{
// 相同次数的单词已经全部放到set中
if (count != e.second)
{
if (s.size() < leftCount)
{
ret.insert(ret.end(), s.begin(), s.end());
leftCount -= s.size();
s.clear();
}
else
{
break;
}
}
}
count = e.second;
s.insert(e.first);
}
for (auto& e : s)
{
if (0 == leftCount)
break;
ret.push_back(e);
leftCount--;
}
return ret;
}
};
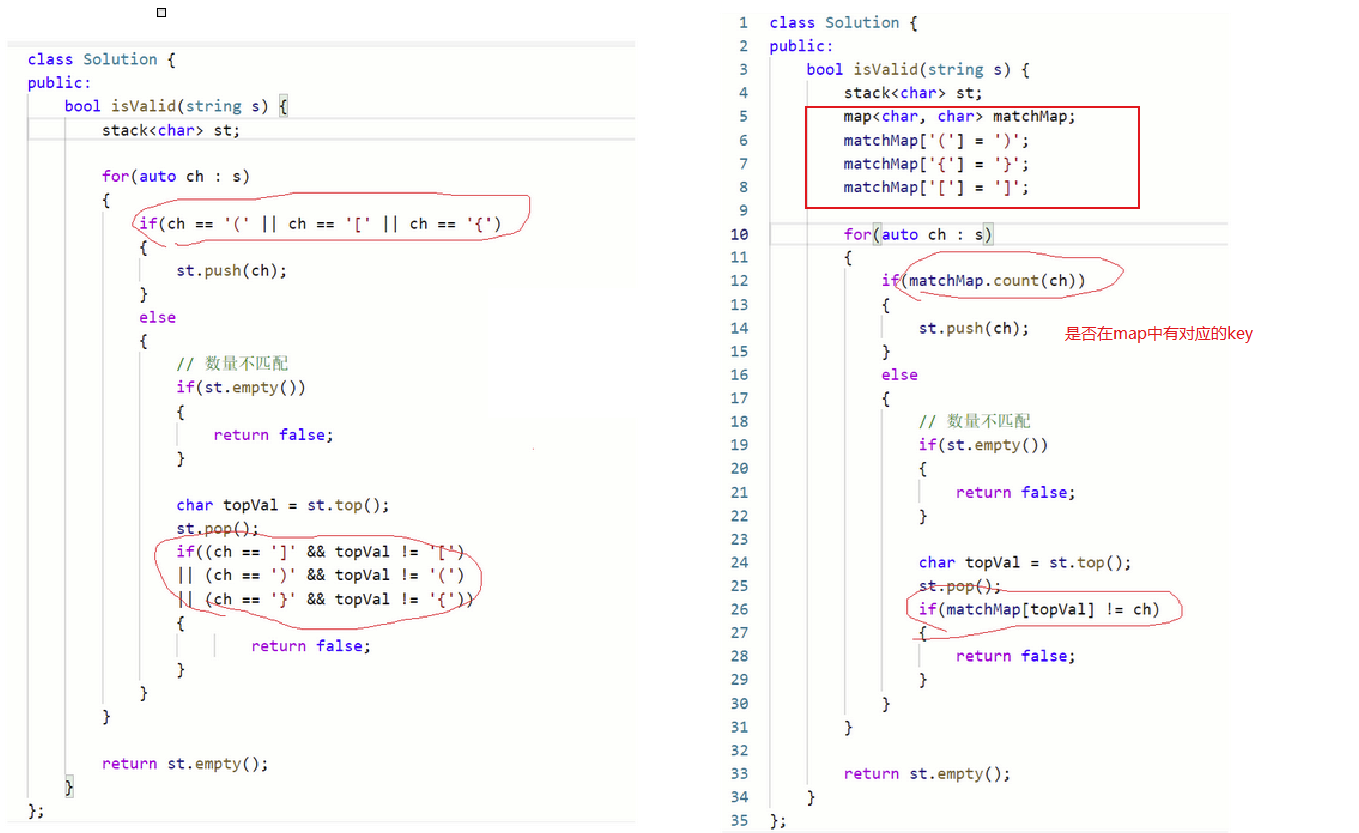
二.左右符号匹配问题【map】
题目:
解题思路分析:
- 这道题是我们学习栈时遇到的经典例题, 将一个字符串中的左括号【“【”“{”“(”】分别进栈,遇到右括号时,对栈顶元素进行保存并头删,再进行左右括号匹配
- 当我们学会map后,可以建立"{" “}” “(”“)”“[”"]"的映射关系来代替法一中的 左右括号匹配
- 但大体逻辑还是相同

三.两个数组的交集I【set】
题目:
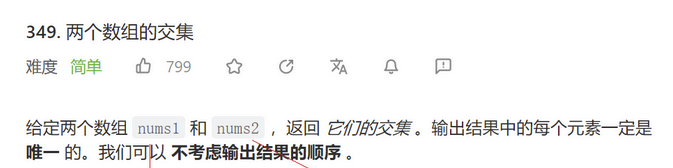
解题思路1分析:
- 先把数组都 放到set中(进行去重)
- 遍历另一个set 中的元素,判断有哪些在第一个set中,在的就是他们的交集元素
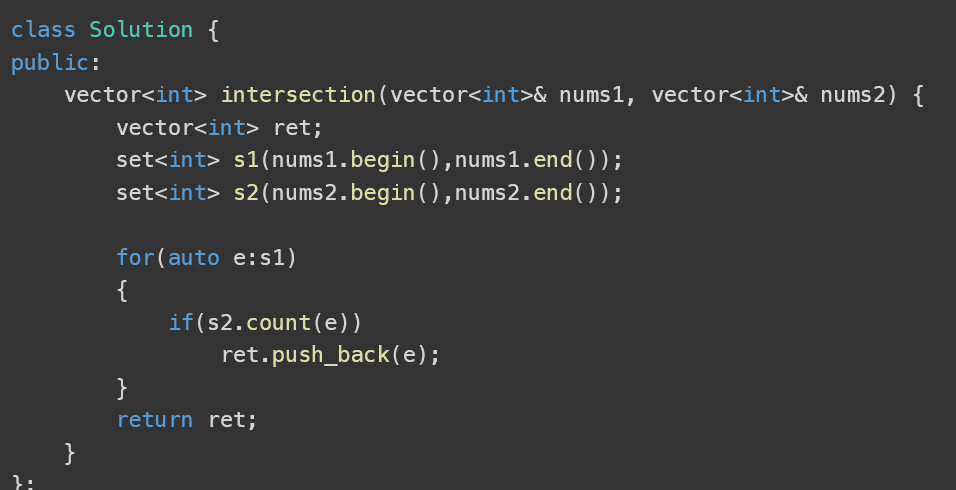
解题思路2分析:
- 先把数组都 放到set中(进行去重)
- 我们通过set的性质知:通过其迭代器进行遍历,元素key是有序的(从小到大)
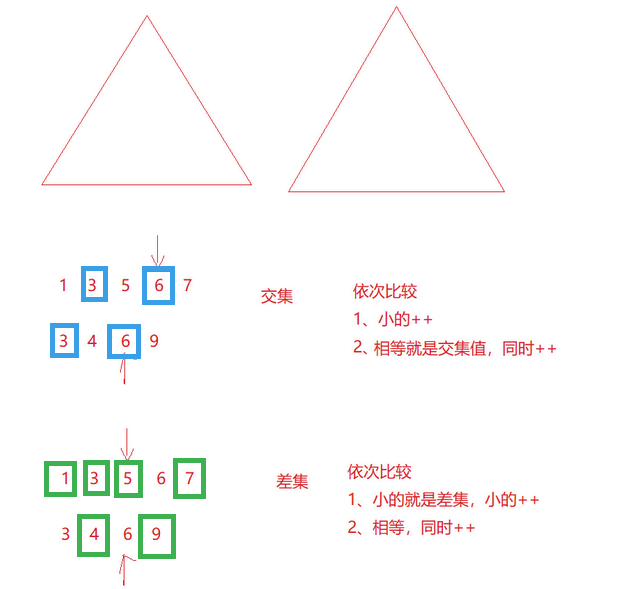
- 那么我们可以对这两个数组对应的set的元素进行分别比较 , 小的key++,相等一起++,最后得到相等得就是【交集】;小的key++,相等同时++,最后得到的就是【差集】如图所示
- 下图演示的是交集;如果求差集,还要在后面加两个判断,分别是set1不为空,set2不为空,并且将剩余元素入栈
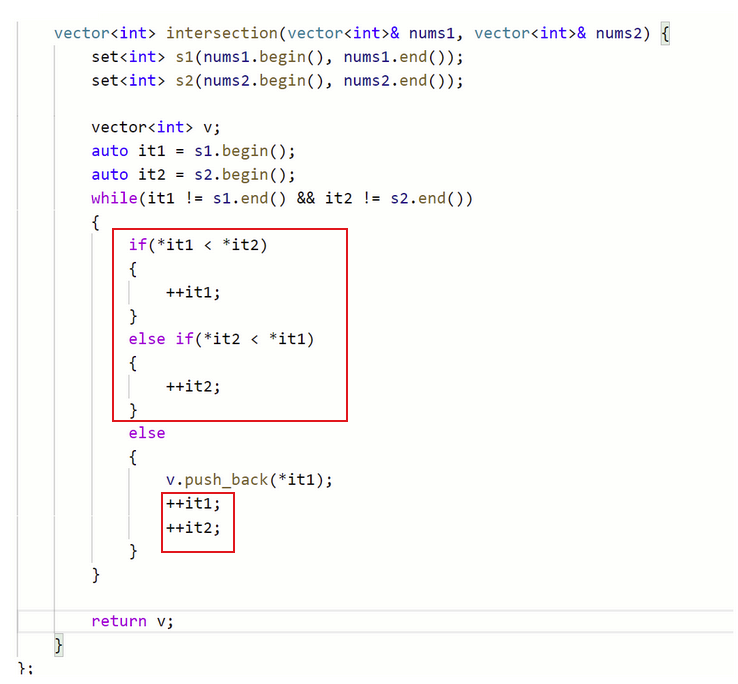
- 代码展示: