系列文章目录
文章目录
- 系列文章目录
- 前言
- 一、数据分析框架
- 二、数据分析方法
- 1.数据清洗&数据探索
- 2.数据清洗之异常值判别
- 3.数据清洗之缺失值处理
- 4.数据探索
- 5.结构优化
- 三、大数据可视化
- 1.大数据可视化概念
- 1.1 定义
- 1.2 数据可视化的意义
- 2.可视化类型和模型
- 2.1 科学可视化
- 2.2 科学可视化的研究重点
- 2.3 体可视化
- 2.4 体可视化
- 2.5 科学可视化的组成
- 2.6 信息可视化
- 3.光与视觉特性
- 3.1 光的特性
- 3.2 三基色原理
- 3.3 黑白视觉特性
- 3.4 彩色视觉特性
- 3.5 数据可视化的基本特征
- 3.6 数据可视化模型
- 3.7 数据可视化基本图表
- 4.视觉编码
- 4.1 视觉感知
- 4.2 数据维度
- 4.3 可视化分析方法的常用
- 5.关键技术
- 5.1 定义
- 5.2 可视化关键技术
- 5.3 渲染技术
- 总结
前言
一、数据分析框架
业务理解->数据理解->数据准备->建立模型->模型评估
二、数据分析方法
1.数据清洗&数据探索
数据探索:
- 特征描述
- 分布推断
- 结构优化
数据清洗:
- 异常值判别
- 缺失值处理
- 数据结构统一
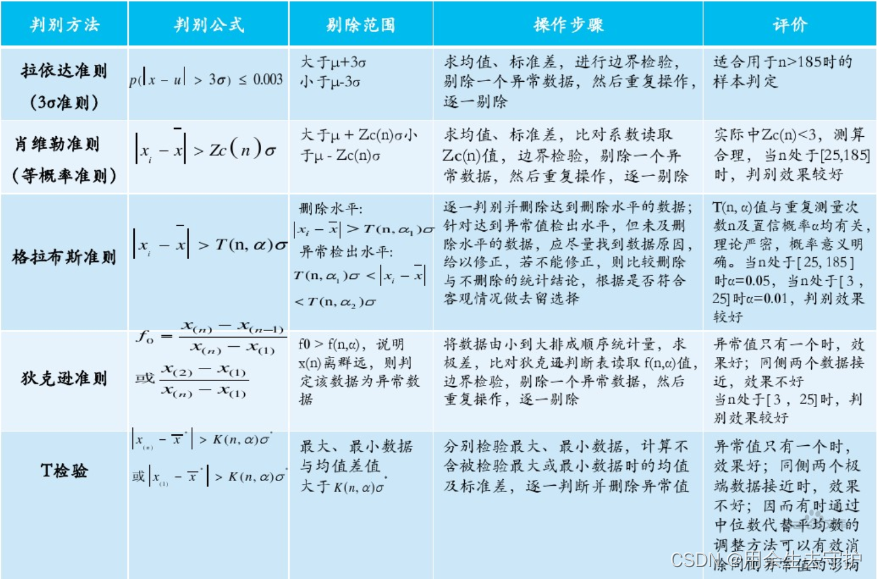
2.数据清洗之异常值判别
1、物理判别法
根据经验客观判别由于外界干扰、人为误差等原因造成的数据偏离,判断异常值
2、统计判别法
- 给定一个置信概率,并确定一个置信限,凡超过此限的误差,就认为它不属于随机误差范围,将其视为异常值。
- 常用的方法(数据来源于同一分布,且是正态的):拉依达准则、肖维勒准则、格拉布斯准则、秋克逊准则、t检验。
3.数据清洗之缺失值处理
在数据缺失严重时,会对分析结果造成较大影响,因此对剔除的异常值以及缺失值,要采用合理的方法进行填补,常见的方法有平均值填充、K最近距离法、回归法、极大似线估计法等
-
平均值填充
取所有对象(或与该对象具有相同决策属性值的对象)的平均值来填充该缺失的属性值 -
K最近距离法
先根据歇式距高或相关分析确定距高缺失数据样本最近的K个样本,将这K个值加权平均来估计缺失数据值 -
回归
基于完整的数据集,走立回归方程(模型),对于包含空值的对象,将已知属性值代入方程来钻计来知属性值,以此估计值来进行填充;但当变量不是线性相关或预测变量高度相关时会导致估计偏差 -
极大似然估计
在给定完全数据和前一次选代所得到的赛;数估计的情况下计算完全数据对应的对数!似然品教的条件期望;(E步),后用极大i化对数似然通敏以确!定参数的使,并用于;下步的选代(M步) -
多重插补法
由包含m个描补值的向量代替每一个缺失位,然后对新产生的m个数据集使用相同的方法处理,得到处理结果后,综合结果最终得到对目标变量的估计
随着数据量的增大,异常值和缺失值对整体分析结果的影响会逐渐变小,因此在“大数据”模式下,数据清洗可忽略异常值和缺失值的影响,而侧重对数据结构合理性的分析
4.数据探索
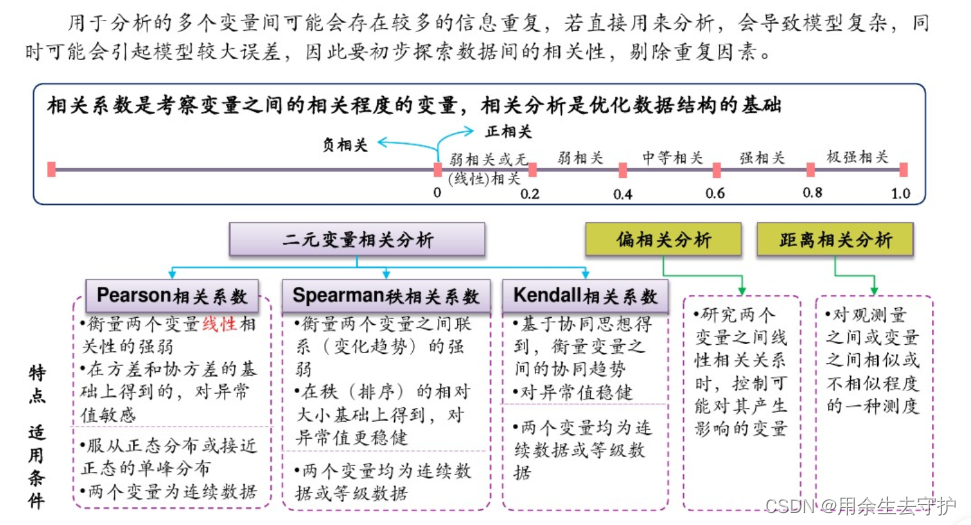
通过数据探索,初步发现数据特征、规律,为后续数据建模提供输入依据,常见的数据探索方法有数据特征描述、相关性分析、主成分分析等。

数据特征描述:
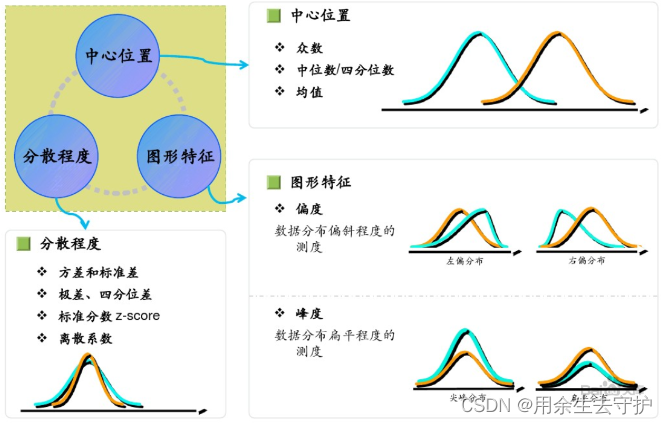
数据概率分布:
概率分布可以表述随机变量取值的概率规律,是掌握数据变化趋势和范围的一个重要手段。

参数检验
在已知总体分布的条件下(一般要求总体服从正态分布),对一些主要的参数(均值,百分数,方差,相关系数等)进行检验。
例如:U检验、T检验(单样本T检验,配对样本T检验,两个独立样本t检验)
| 检验方法名称 | 问题类型 | 假设 | 适用条件 | 抽样方法 |
|---|---|---|---|---|
| 单样本T-检验 | 判断一个总体平均数等于已知数 | 总体平均数等于A | 总体服从正态分布 | 从总体中抽取一个样本 |
| F一检验 | 判断两总体方差相等 | 两总体方差相等 | 总体服从正态分布 | 从两个总体中各抽取一个样本 |
| 独立样本T一检验 | 判断两总体平均数相等 | 两总体平均救相等 | 总体展从正态分布,两总体方程相等 | 从两个总体中各物取一个样本 |
| 配对样本T-检验 | 判断指标实验前后平均数相等 | 指标实验前后平均数相等 | 总体服从正态分布,两组数据是同一实验对象在实验前后的测试值 | 抽取一组试验对象,在试验前测得试验对象某指标的值,进行试验后再测得试验对象该指标的取值 |
| 二项分布假设检验 | 随机抽样实验的成功概率的检验 | 总体概率等于P | 总体服从二项分布 | 从总体中抽取一个样本 |
非参数检验
一般是在不知道数据分布的前提下,检验数据的分布情况(不考虑总体分布是否已知,常常也不是针对总体参数,而是针对总体的某些一次性假设进行检验)
例如:卡方检验,秩和检验,二项检验,游程检验,K-量检验等
| 检验方法名称 | 问题类型 | 假设 |
|---|---|---|
| 卡方检验 | 检测试剂观测频数与理论频数之间是否存在差异 | 观测频数与理论频数无差异 |
| K-S检验 | 检测实际观测频数与理论频数之间是否存在差异 | 服从正态分布 |
| 游程检验 | 检测一组观测值是否有明显变化趋势 | 无明显变化趋势 |
| 二项分布假设检验 | 通过样本数据检验样本的总体是否服从指定的概率为P的二项分布 | 服从二项分布 |
结论:
- 参数检验是针对参数做的假设,非参数检验是针对总体分布情况做的假设。
- 二者的根本区别在于参数检验要利用到总体的信息,以总体分布和样本信息对总体参数作出推断;非参数检验不需要利用总体的信息。
5.结构优化
三、大数据可视化
1.大数据可视化概念
1.1 定义
数据:聚焦于数据的采集、清理、预处理、分析、挖掘
图形:聚焦于解决对光学图像进行接收,提取信息、加工变换模式识别及存储显示
可视化:聚焦于解决将数据转换成图形,并进行交互处理
数据空间:是由n维属性和m个元素组成的数据集所构成的多维信息空间
数据开发:是指利用一定的算法和工具对数据进行定量的推演和计算
数据分析:指对多维数据进行切片、块、旋转等动作剖析数据,从而能多角度侧面观察数据
数据可视化:是指将大型数据集中的数据以图形形式表示,并利用数据分析和开发工具发现其中未知信息的处理过程
数据可视化根据可视化原理不同可划分为几何技术、面向像素技术、基于图标的技术、基于层次的技术、基于图像的技术、和分布式技术等
1.2 数据可视化的意义
- 视觉是人类获得信息的最主要途径
- 能帮助我们提高理解和处理数据的效率
- 可以在小空间中展示大规模数据
- 在工业4.0、智能交通、人工智能、其它
2.可视化类型和模型
2.1 科学可视化
科学可视化最初称为“科学计算中的可视化”,(Visualzation In Scientific Computing,VISC),运用计算机图形学和图像处理的研究成果创建视觉图像,替代数字;
2.2 科学可视化的研究重点
- 判断可视化对象的类别,进行可视化表现
- 将研究对象以最接近真实的效果绘制,用视觉、触觉等交互方式理解和研究
2.3 体可视化
体可视化研究对象主要是体数据,即三维数据,其绘制技术包括等值面的抽取技术,直接体绘制
流场可视化,运用计算机图形学和图像学技术,将流场数据转换为二维或三维–计算流体力学的手段
大规模数据可视化-高效快捷
2.4 体可视化
- 颜色映射方法
- 等值线方法-等值线的疏密程度判断现象的数量变化趋势
- 立体图法和层次分割法
- 矢量数据场和直接法和流线法-通过记录坐标的方式尽可能将地理实体的空间位置表现出来
2.5 科学可视化的组成
可视化流水线模型
模拟->预处理->映射->绘制->解释
2.6 信息可视化
信息可视化是1989年斯图尔特卡德、约克·麦金利和乔治·罗伯逊提出的,利用计算机将非空间数据的信息对象的特征值抽取、转换、映射、高度抽象与整合,用图形、图像、动画等方式表示信息对象内容特征和语义的过程;
3.光与视觉特性
3.1 光的特性
可见光的波长由780nm到380nm变化时,人眼的感觉依次是红橙黄绿青蓝紫;
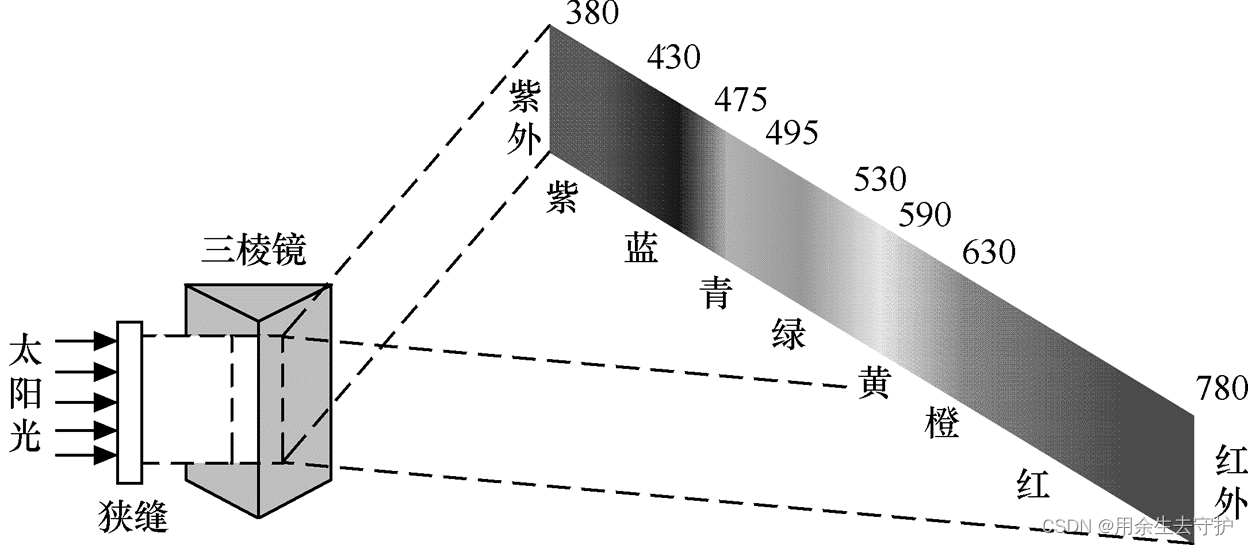
3.2 三基色原理
三基色原理是根据色度学中著名的格拉兹曼法则和配色实验总结出来的。
自然界中几乎所有的彩色都由3种线性无关的色光按一定比例混配得到,合成的彩色亮度由3种色光的亮度之和决定,色度由3种色光所占的比例决定;
线性无关是指3种色光必须相互独立,其中任何一种色光都不能由其他两种色光混配得到;
- 人的视觉只能分辨颜色的三种变化,即亮度、色调和色饱和度;
- 任何彩色均可以由3中线性无关的彩色混合得到,称为三基色;
- 合成彩色光的亮度等于三基色分量亮度之和,即符合亮度相加定律;
- 光谱组成成分不同的光在视觉上可能具有相同的颜色外貌,即相同的彩色感觉;
- 在由两个成分组成的混合色中,如果一个成分连续变化,混合色也连续变化;
补色律:每种颜色都有一个相应的补色;
中间色律:任何两个非补色的色光相混合,可产生出它们两个色调之间的新的中间色调;
3.3 黑白视觉特性
- 视敏特性:指人眼对不同波长和光具有不同的灵敏度,即辐射功率相同的各色光具有不同的亮度感觉。在相同的辐射功率条件下,人眼感到最亮的是黄绿光,最暗的是红光和紫光;

- 亮度感觉:亮度感觉不仅仅取决于景物给出的亮度值,还与周围的平均亮度有关,是一个主观量;
- 人眼感光适应性:适应性是指随着外界光的强弱变化,人眼能自动调节感光灵敏度的特性;
- 亮度视觉范围:与环境亮度有关
- 亮度可见度阈值:人眼对亮度变化的分辨力是有限的,人眼无法区分非常微弱的亮度变化。通常用亮度极差来表示人眼刚刚能感觉到的两者的差异
- 人眼视觉的掩盖效应:如果是在空间和时间上不均匀的背景中,测量可见度阈值,可见度阈值就会增大,即人员会丧失分辨一些亮度的能力;
- 对比度:把景物或重现图像最大亮度和最小亮度的比值称为对比度;
- 亮度层次:画面最大亮度与最小亮度之间可分辨的亮度极差数称为亮度层次或灰度层次;
- 视觉惰性:人眼的视觉有惰性,这种惰性现象称为视觉残留;
- 闪烁:观察者观察按时间重复的亮度脉冲,当脉冲重复频率不够高时,人眼就有一亮一暗的感觉
- 视角:观看景物时,景物大小对眼睛形成的张角
- 分辨力:当与人眼相隔一定距离的两个黑点靠近到一定程度时,人眼就分辨不出有两个黑点的存在,而只感觉到是连在一起的一个点,这种现象表明人眼分辨景物细节的能力是有一定极限的;
3.4 彩色视觉特性
- 辨色能力:亮度、色调和饱和度称为彩色的三要素。人眼对不同波长的谱色光有不同的色调感觉。人眼的彩色视觉的辨色能力共有3000-4000种。人眼对彩色感觉具有非单一性。颜色感觉相同,光谱组成可以不同;
- 彩色细节分辨力:画面最大亮度和最小亮度之间可以分辨的亮度极差数称为亮度层次或灰度层次。人眼对彩色细节的分辨力对比黑白细节的分辨力要低。只有对黑白细节分辨力的1/3~1/5
- 混色特性:包括时间混色,空间混色和双眼混色等
3.5 数据可视化的基本特征
- 易懂性
- 必然性
- 多维性
- 片面性
- 专业性
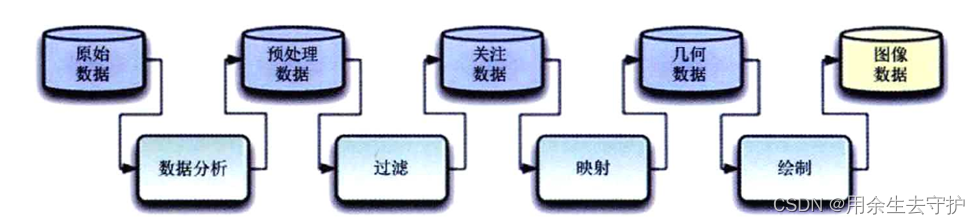
3.6 数据可视化模型
可视化流水线
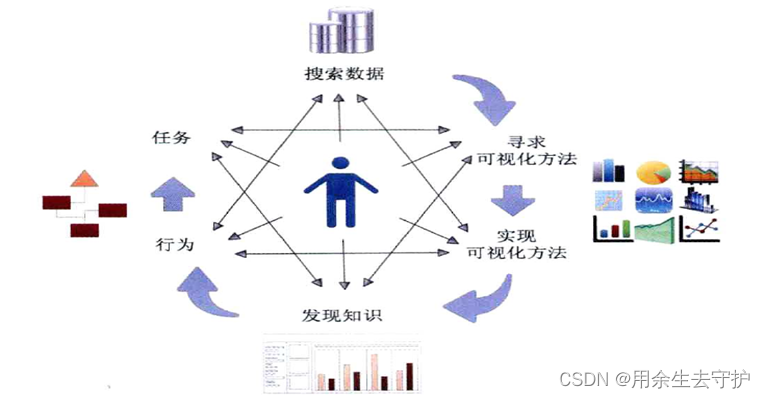
循环模型
3.7 数据可视化基本图表
- 原始数据绘图用于可视化原始数据的属性值,直观呈现数据特征,其代表性方法包括:数据轨迹、柱状图、折线图、直方图、饼图、等值线图、散点图、气泡图、维恩图、热力图和雷达图等;
- 简单统计值标绘:盒须图
- 多视图协调关联
4.视觉编码
4.1 视觉感知
视觉感知是指客观事物通过人的视觉器官在人脑中形成的直接反映;
视觉通道:用于控制几何标记的展示特性,包括标记的位置、大小、形状、方向、色调、饱和度、亮度等
4.2 数据维度
基于任务分类的数据类型(TTT,data Type by Task Taxonomy)。
七类:一维线性数据、二维数据、三维数据、多维数据、时态数据、树形数据和网状数据;
4.3 可视化分析方法的常用
- 主成分分析(Principal Component Analysis ,PCA)是一种利用线性映射来进行数据降维的方法,同时去除数据相关性,以最大限度保持原始数据的方差信息,从而进行有效的特征提取;
- 聚类分析:
系统聚类分析:将变量由多变少的一种方法,先将距离最小的变量归为一类,再将其合并,合并后将新类计算相互间的距离,再将距离最小的新类合并,直到所有的变量归为一类为止。距离的定义有最短距离法、最长距离法、中心法、类平均法、中间距离法、离差平和法;
动态聚类法:动态聚类先设定好数值K,然后将所有样本分成K类作为聚核,再计算每个样本到聚核的距离,与聚核距离最小的样本归为一类,这样样本被分为K类;
5.关键技术
5.1 定义
- 数据空间:是由n维属性和m个元素组成的数据集所构成的多维信息空间;
- 数据开发:是指利用一定的算法和工具对数据进行定量的推演和计算;
- 数据分析:是指对多维数据进行切片、块、旋转等动作剖析数据,从而多角度观察;
- 数据可视化:利用数据分析和开发工具发现其中未知信息的处理过程;
5.2 可视化关键技术
- 数据信息的符号表达技术
- 数据表达模型技术
- 数据交互技术
- 数据渲染技术
- 可视化设计与开发模型
5.3 渲染技术
渲染的功能是把三维坐标系中的场景显示出来。在计算机中,三维世界是由坐标系和坐标系的点构成的,还包括物体的材质、纹理、光照等信息。渲染是完成从数据到显示的过程,主要存在三种渲染技术:深度缓存技术、光线跟踪技术和辐射度技术。
1、基于CPU渲染
- 早期的渲染都是基于CPU来完成,但由于当时图形化技术没有达到真实感绘制的效果,所以依靠单线程CPU运行计算的速度也是能达到要求;
- 现在的渲染方式多采用多核CPU和GPU结合的方式,多核CPU对渲染速度的提升影响极大。几乎所有的CPU渲染软件都能对CPU的多线程实现良好的支持,也就是说,核心线程数量越多,渲染的效率越高;
2、基于GPU的渲染
- GPU是能够从硬件上支持多边形转换与光源处理的显示芯片,其作用是计算多边形的3D位置和处理动态光线效果,也可以称为"几何处理"
3、集群渲染技术
集群渲染是指一组计算机通过通信协议连接在一起的计算机群,能够将工作负载从一个超载的计算机迁移到集群中。目标是使用主流的硬件设备组成网格计算能力,达到超级计算机的性能。典型的超级计算机厂商有IBM、SGI、以及一些科研组织。
集群计算机通常分为SMP和MPP两种
- SMP(symmetric multiprocessing,对称处理),计算机的I/O总线,多处理器,内存等所有的控制都运行在一个操作系统中(Unix、Linux)
- MPP(massively parallel processing,大规模并行处理):每个处理器都有属于自己的操作系统,通过通信协议连接,可以同时处理同一程序的不同部分。
集群渲染技术优点:
- 多颗多核处理器的密集式服务器渲染节点将计算能力发挥极致
- 满足高速带宽的任务分发管理中心
- 支持多应用,需要复杂运算的场景统一部署
- 兼容多操作系统,多软件
- 实时监控渲染动态,随时调整任务
- 数据共享,易操作,易管理
- 稳定性,安全的数据与足够的网络带宽环境
- 单机具备升级空间,系统具备扩容性
4、云渲染:由客户端处理的图形渲染转移至服务器端;
总结
分享:
石上偈
无材可去补苍天,枉入红尘若许年;
此系身前身后事,倩谁记去做奇传?









![[足式机器人]Part2 Dr. CAN学习笔记-数学基础Ch0-9阈值选取-机器视觉中应用正态分布和6-sigma](https://img-blog.csdnimg.cn/direct/cc78b19f146c4185a1082da5319042ac.png)