检索增强生成 (RAG) 定义
检索增强生成 (RAG) 是一种利用来自私有或专有数据源的信息来补充文本生成的技术。 它将旨在搜索大型数据集或知识库的检索模型与大型语言模型 (LLM) 等生成模型相结合,后者获取该信息并生成可读的文本响应。
检索增强生成可以通过添加来自其他数据源的上下文并通过培训补充 LLMs 的原始知识库来提高搜索体验的相关性。 这增强了大型语言模型的输出,而无需重新训练模型。 其他信息来源的范围包括 LLM 未受过培训的互联网上的新信息、专有业务背景或属于企业的机密内部文件。
RAG 对于问答和内容生成等任务很有价值,因为它使生成式 AI系统能够使用外部信息源来生成更准确和上下文感知的响应。 它实现搜索检索方法(通常是语义搜索或混合搜索)来响应用户意图并提供更相关的结果。
那么,什么是信息检索呢?
信息检索(information retrieval - IR)是指从知识源或数据集中搜索和提取相关信息的过程。 这很像使用搜索引擎在互联网上查找信息。 你输入查询,系统会检索并向你显示最有可能包含你正在查找的信息的文档或网页。
信息检索涉及对大型数据集进行有效索引和搜索的技术; 这使得人们更容易从大量可用数据中访问他们需要的特定信息。 除了网络搜索引擎之外,IR 系统还经常用于数字图书馆、文档管理系统和各种信息访问应用程序。
AI 语言模型的演变

多年来,人工智能语言模型已经发生了显着的发展:
- 在 20 世纪 50 年代和 1960 年代,该领域还处于起步阶段,基本的基于规则的系统对语言的理解有限。
- 20 世纪 70 年代和 80 年代引入了专家系统:这些系统编码了人类解决问题的知识,但语言能力非常有限。
- 20 世纪 90 年代见证了统计方法的兴起,这些方法使用数据驱动的方法来完成语言任务。
- 到 2000 年代,支持向量机(在高维空间中对不同类型的文本数据进行分类)等机器学习技术已经出现,尽管深度学习仍处于早期阶段。
- 2010 年代标志着深度学习的重大转变。 Transformer 架构通过使用注意力机制改变了自然语言处理,这使得模型在处理输入序列时能够关注输入序列的不同部分。
如今,Transformer 模型处理数据的方式可以通过预测单词序列中接下来出现的单词来模拟人类语音。 这些模型彻底改变了该领域,并导致了 LLM 的兴起,例如谷歌的 BERT(来自 Transformers 的双向编码器表示)。
我们看到大量预训练模型和专为特定任务设计的专用模型的组合。 RAG 等模型继续受到关注,将生成式 AI 语言模型的范围扩展到标准训练的限制之外。 2022 年,OpenAI 推出了 ChatGPT,这可以说是最著名的基于 Transformer 架构的 LLM。 它的竞争对手包括基于聊天的基础模型,例如 Google Bard 和微软的 Bing Chat。 Meta 的 LLaMa 2 不是消费者聊天机器人,而是开源 LLM,熟悉 LLM 工作原理的研究人员可以免费使用。
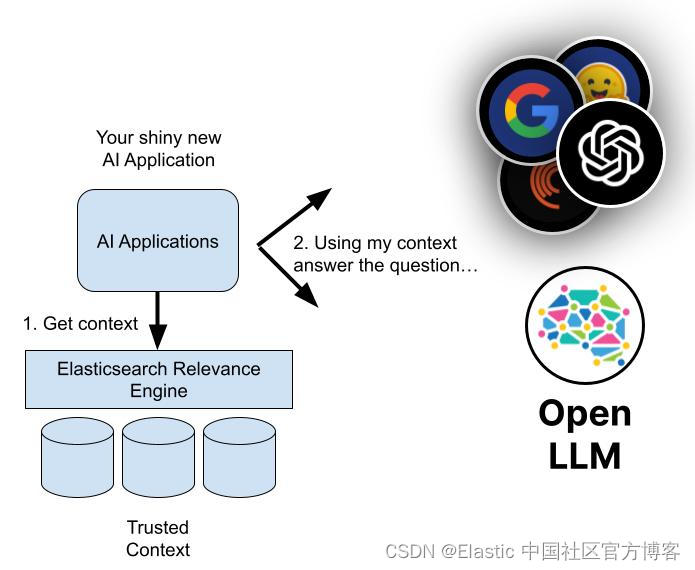
检索增强生成如何工作?
检索增强生成是一个多步骤过程,从检索开始,然后导致生成。 下面是它的工作原理:
检索
- RAG 以输入查询开始。 这可能是用户的问题或任何需要详细响应的文本。
- 检索模型从知识库、数据库或外部源(或同时从多个源)获取相关信息。 模型搜索的位置取决于输入查询的要求。 现在,检索到的信息可作为模型所需的任何事实和上下文的参考源。
- 检索到的信息被转换为高维空间中的向量。 这些知识向量存储在向量数据库中。
- 检索模型根据检索到的信息与输入查询的相关性对检索到的信息进行排名。 选择得分最高的文档或段落进行进一步处理。
生成
- 接下来,生成模型(例如 LLM)使用检索到的信息生成文本响应。
- 生成的文本可能会经过额外的后处理步骤,以确保其语法正确且连贯。
- 总体而言,这些响应更准确,并且在上下文中更有意义,因为它们是由检索模型提供的补充信息塑造的。 这种能力在公共互联网数据不足的专业领域尤其重要。
检索增强生成的好处
与孤立工作的语言模型相比,检索增强生成有几个好处。 以下是它改进文本生成和响应的几种方法:
- RAG 确保你的模型可以访问最新的事实和相关信息,因为它可以定期更新其外部参考。 这确保了它生成的响应包含可能与进行查询的用户相关的最新信息。 你还可以实施文档级安全性来控制对数据流中数据的访问并限制对特定文档的安全权限。
- RAG 是一种更具成本效益的选择,因为它需要更少的计算和存储,这意味着你不必拥有自己的 LLM 或花费时间和金钱来微调你的模型。
- 声称准确性是一回事,但实际证明它是另一回事。 RAG 可以引用其外部来源并将其提供给用户以支持他们的响应。 如果他们选择这样做,用户就可以评估来源以确认他们收到的响应是准确的。
- 虽然 LLM 支持的聊天机器人可以制作比以前的脚本响应更加个性化的答案,但 RAG 可以更加定制其答案。 这是因为它能够在通过衡量意图综合答案时使用搜索检索方法(通常是语义搜索)来引用一系列上下文信息点。
- 当面对未经训练的复杂查询时, LLM 有时会 “产生幻觉”,提供不准确的答案。 通过将其响应与相关数据源的附加参考结合起来,RAG 可以更准确地响应模糊的查询。
- RAG 模型用途广泛,可应用于一系列自然语言处理任务,包括对话系统、内容生成和信息检索。
- 偏见可能是任何人造人工智能中的一个问题。 通过依靠经过审查的外部来源,RAG 可以帮助减少其反应中的偏见。
检索增强生成与微调
检索增强生成和微调 (fine-tunning) 是训练人工智能语言模型的两种不同方法。 虽然 RAG 将广泛的外部知识检索与文本生成结合起来,但微调侧重于用于不同目的的狭窄数据范围。
在微调过程中,预训练模型会根据专门数据进行进一步训练,以使其适应任务子集。 它涉及根据新数据集修改模型的权重和参数,使其能够学习特定于任务的模式,同时保留初始预训练中的知识。
微调可用于各种人工智能。 一个基本的例子是在识别互联网上的猫照片的背景下学习识别小猫。 在基于语言的模型中,除了文本生成之外,微调还可以帮助完成文本分类、情感分析和命名实体识别等工作。 然而,这个过程可能非常耗时且昂贵。 RAG 加快了流程,并以更少的计算和存储需求整合了这些成本。
由于 RAG 可以访问外部资源,因此当任务需要合并来自 Web 或企业知识库的实时或动态信息以生成明智的响应时,RAG 特别有用。 微调具有不同的优势:如果手头的任务定义明确并且目标是单独优化该任务的性能,则微调可能非常有效。 这两种技术的优点是不必为每项任务从头开始培训 LLM。
检索增强生成的挑战和局限性
虽然 RAG 具有显着的优势,但它也面临着一些挑战和限制:
- RAG 依赖于外部知识。 如果检索到的信息不正确,它可能会产生不准确的结果。
- RAG 的检索组件涉及搜索大型知识库或网络,这可能在计算上昂贵且缓慢 - 尽管仍然比微调更快且更便宜。
- 无缝集成检索和生成组件需要仔细的设计和优化,这可能会导致训练和部署方面的潜在困难。
- 在处理敏感数据时,从外部来源检索信息可能会引起隐私问题。 遵守隐私和合规性要求也可能会限制 RAG 可以访问的来源。 但是,这可以通过文档级访问来解决,你可以在其中向特定角色授予访问和安全权限。
- RAG 基于事实准确性。 它可能难以生成富有想象力或虚构的内容,这限制了其在创意内容生成中的使用。
检索增强生成的未来趋势
检索增强生成的未来趋势集中在使 RAG 技术更高效、更适应各种应用。 以下是一些值得关注的趋势:
个性化
RAG 模型将继续纳入用户特定的知识。 这将使他们能够提供更加个性化的响应,特别是在内容推荐和虚拟助理等应用程序中。
可定制的行为
除了个性化之外,用户本身还可以更好地控制 RAG 模型的行为和响应方式,以帮助他们获得所需的结果。
可扩展性
RAG 模型将能够处理比目前更大量的数据和用户交互。
混合模式
RAG 与其他人工智能技术(例如强化学习)的集成将允许更通用和上下文感知的系统,可以同时处理各种数据类型和任务。
实时、低延迟部署
随着 RAG 模型检索速度和响应时间的提高,它们将更多地用于需要快速响应的应用程序(例如聊天机器人和虚拟助手)。
使用 Elasticsearch 检索增强生成
借助 Elasticsearch Relevance Engine,你可以为生成式 AI 应用程序、网站、客户或员工体验构建支持 RAG 的搜索。 Elasticsearch 提供了一个全面的工具包,使你能够:
- 存储和搜索专有数据和其他外部知识库以从中获取上下文
- 使用多种方法从你的数据生成高度相关的搜索结果:文本、向量、混合或语义搜索
- 为你的用户创建更准确的响应和更有吸引力的体验
了解 Elasticsearch 如何为你的企业改进生成式 AI