Hadoop概念
什么是Hadoop
Hadoop是一个由Apache基金会所开发的用于解决海量数据的存储及分析计算问题的分布式系统基础架构。

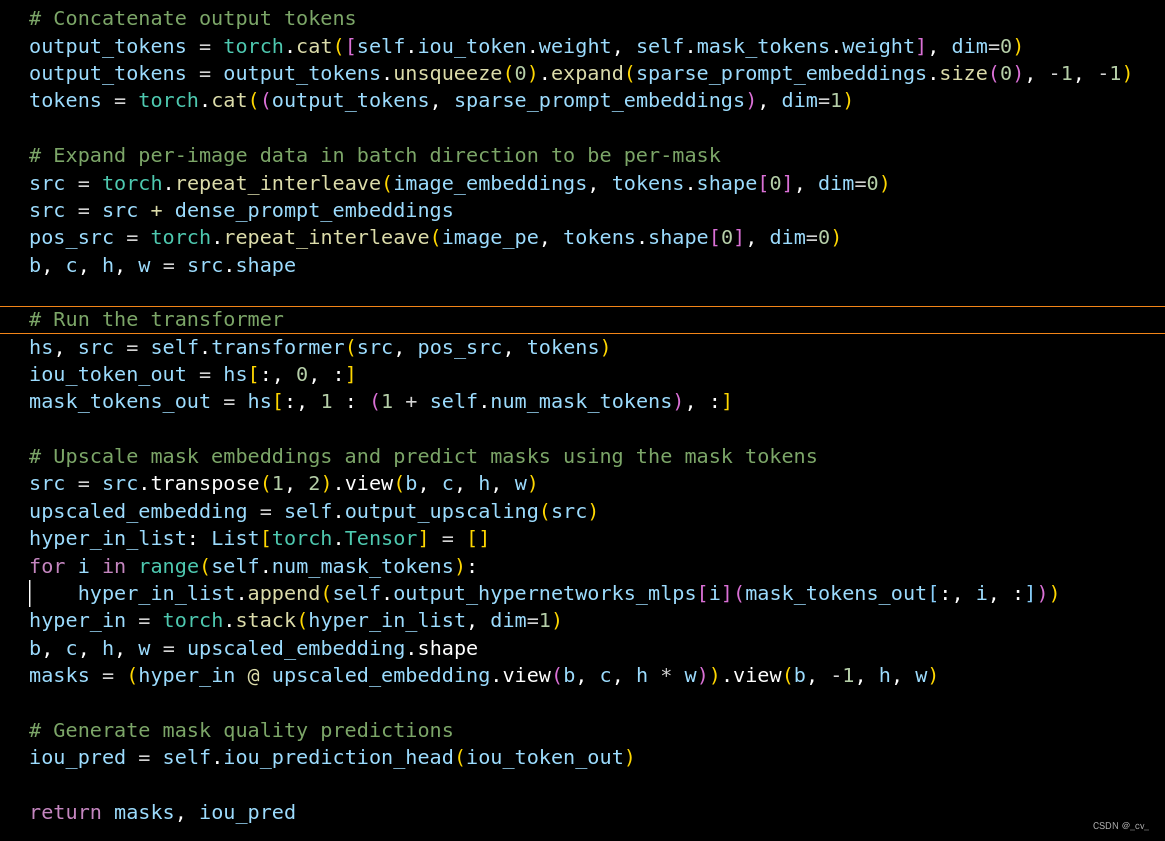
广义上来说,Hadoop通常指一个跟广泛的概念——Hadoop生态圈。
以下是hadoop生态圈中的技术:
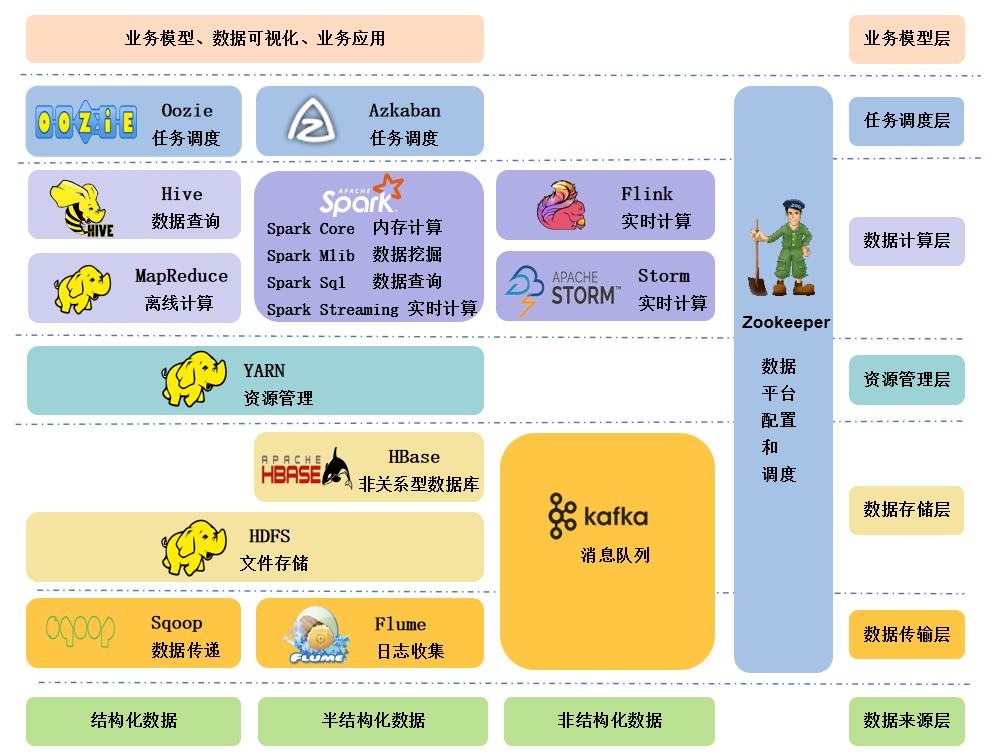
Hadoop优势
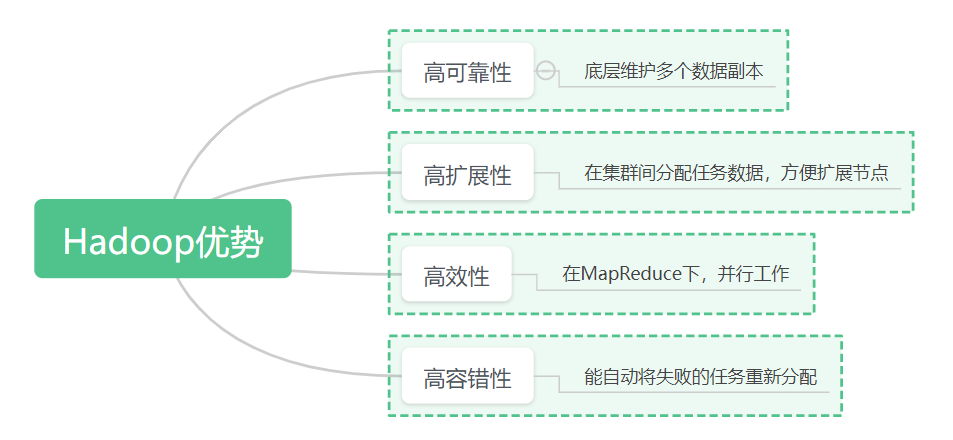
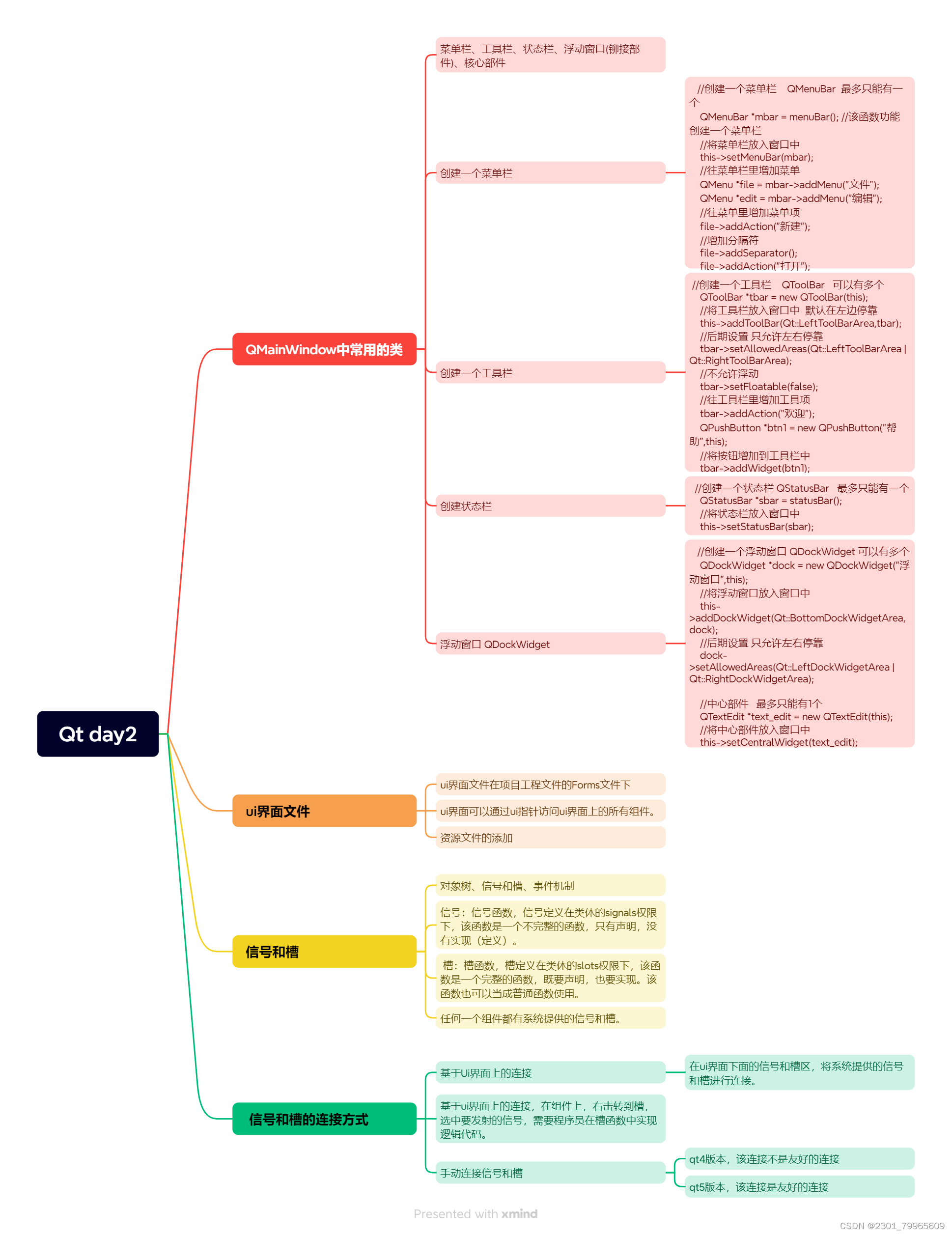
hadoop组成
HDFS架构概述
HDFS(Hadoop Distributed File System)是一个分布式文件系统,用于存储文件,通过目录树来定位文件。
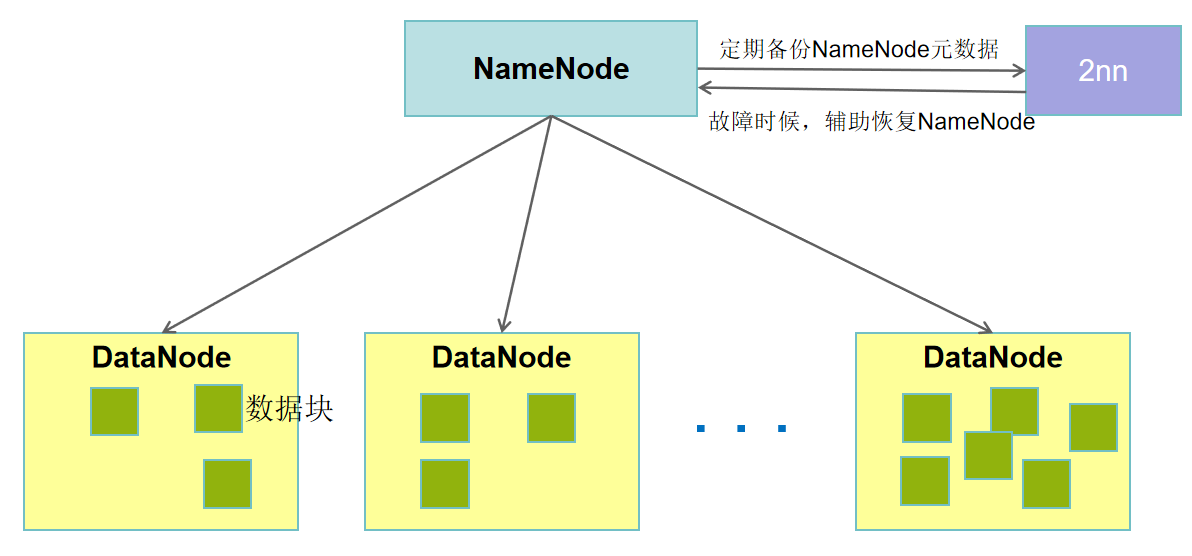
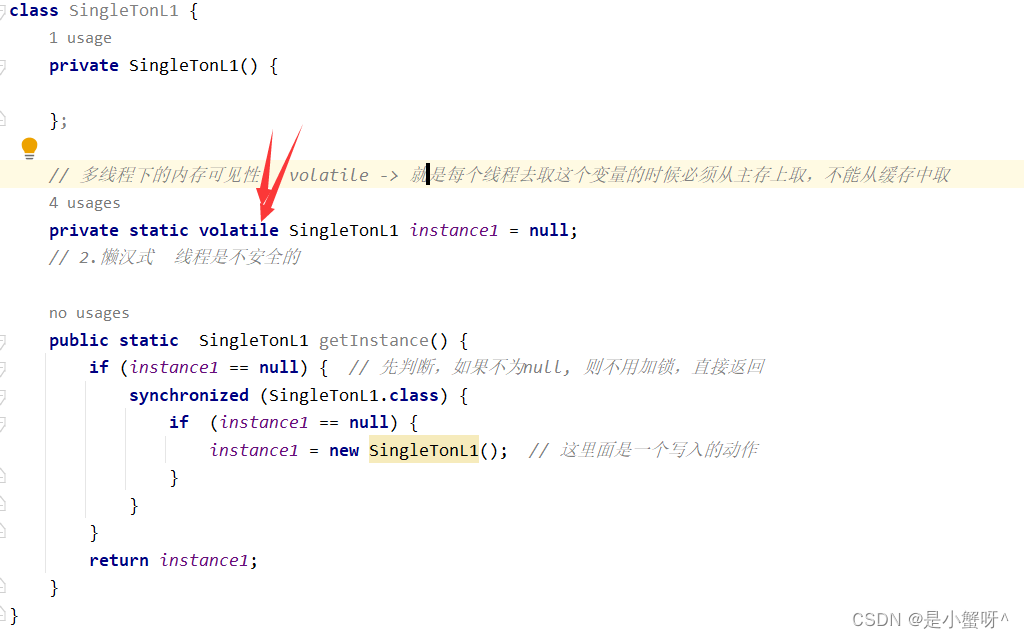
- NameNode(nn):存储文件元数据,比如文件名、目录结构、文件属性(生成时间、副本数、文件权限),以及每个文件的数据块(Block)列表和数据库映射信息(比如块所在哪几个DataNote)等。
- DataNode(dn):在本地文件系统存储文件块数据,以及块数据的校验和;执行数据块的读写操作。
- Secondary NameNode(2nn):定期备份NameNode元数据;在紧急情况下,可辅助恢复NameNode。
HDFS 优缺点

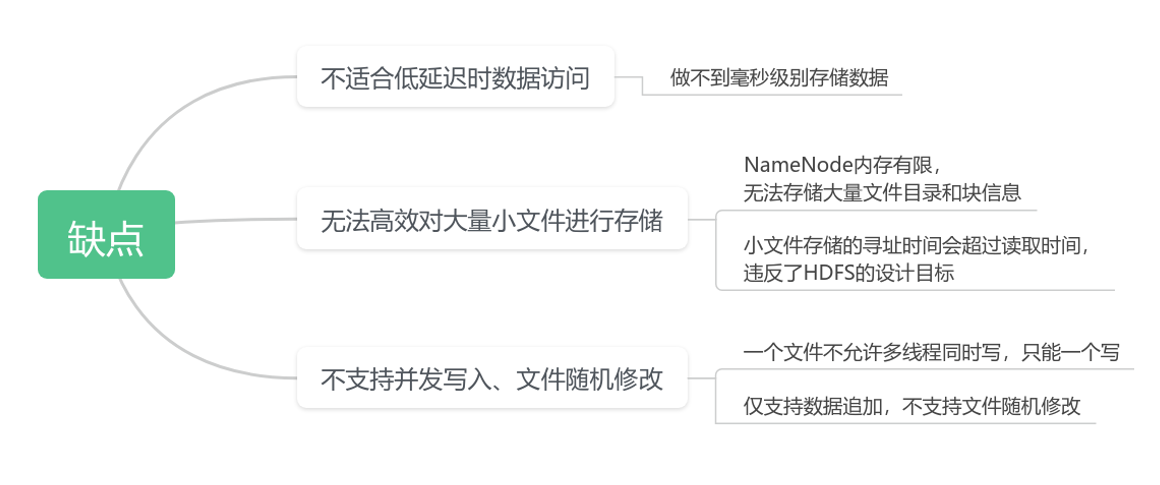
HDFS 的使用场景:适合一次写入,多次读出的场景。一个文件经过创建、写入和关闭之后就不需要改变
YARN架构概述
YARN(Yet Another Resource Negotiator)是一个资源调度平台,负责为运算程序提供服务器运算资源。
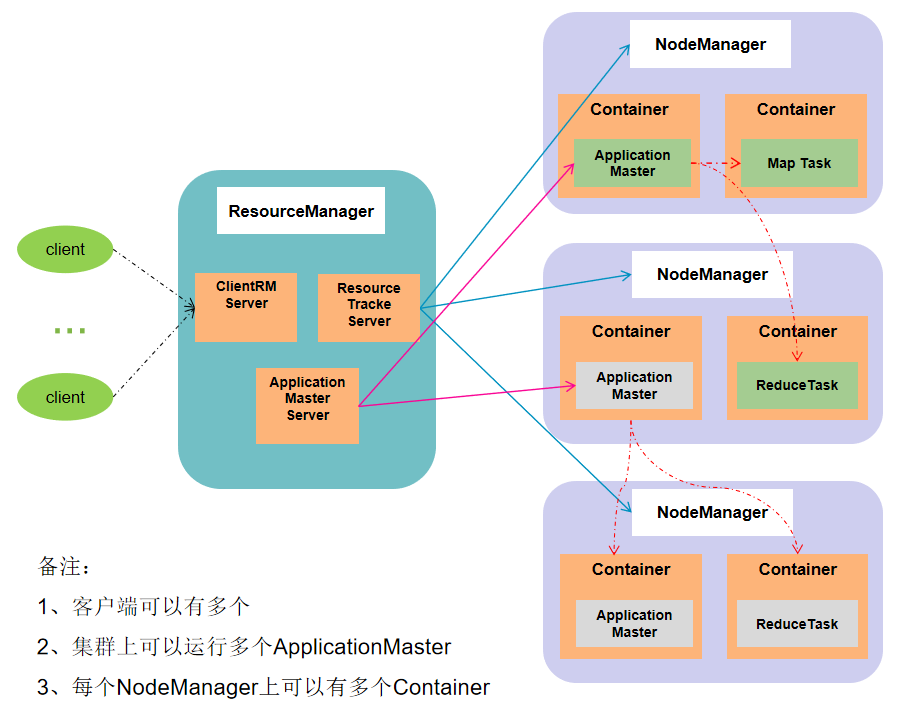
- ResourceManager(RM):核心管理服务,负责资源的管理和分配。
- NodeManager(NM):管理单个节点上的资源。
- ApplicationMaster(AM):负责内部任务的资源申请和分配;任务的监控和容错。
- Container:容器,里面封装了任务运行所需要的资源。
MapReduce架构概述
MapReduce 是一个分布式运算程序的编程框架,是用户开发“基于 Hadoop 的数据分析应用”的核心框架。
MapReduce 核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个 Hadoop 集群上。
MapReduce将计算过程分为两个阶段:Map和Reduce。
- Map 阶段并行处理输入数据;
- Reduce 阶段对 Map 结果进行汇总。
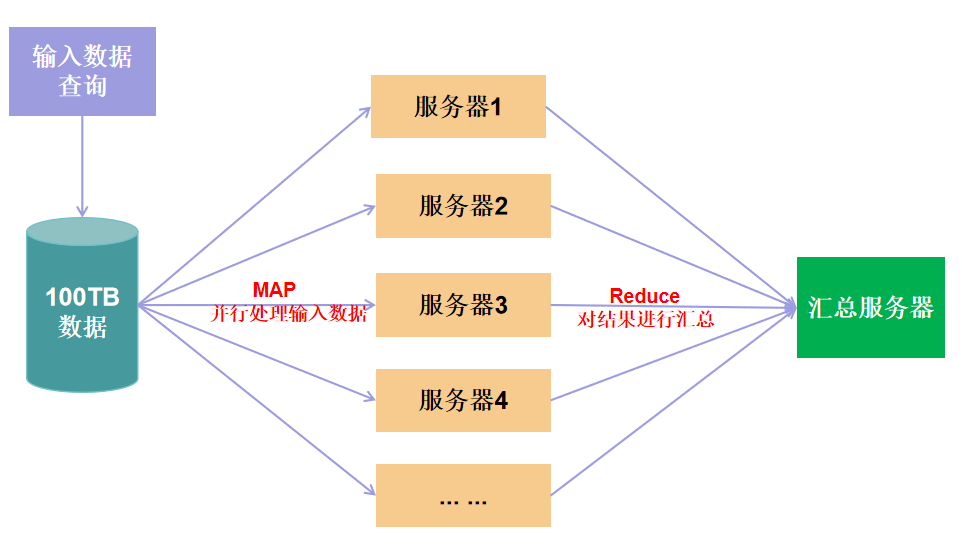
HDFS、YARN、MapReduce三者关系
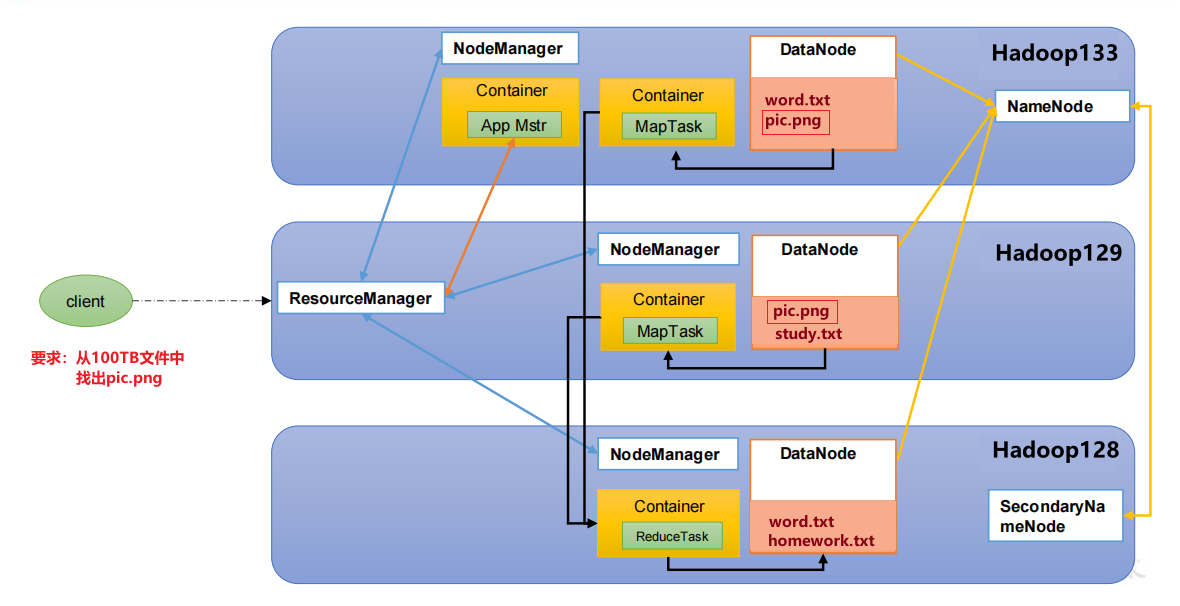
Hadoop运行环境集群部署采用了三台服务器,以下是集群部署规划:

注意:
- NameNode 和 SecondaryNameNode 不要安装在同一台服务器
- ResourceManager 也很消耗内存,不要和 NameNode、SecondaryNameNode 配置在同一台机器上。
本文由mdnice多平台发布