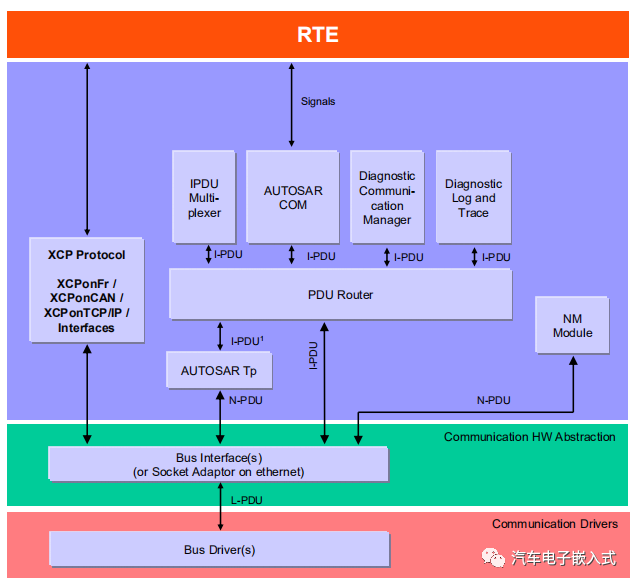
我们都知道在大多数情况下,语言模型的体量和其推理能力之间存在着正相关的关系:模型越大,其处理复杂任务的能力往往越强。
然而,这并不意味着小型模型就永远无法展现出色的推理性能。最近,奶茶发现了微软的Orca2公开了论文,它详细探讨了如何提升小型大语言模型的推理能力,这样的研究无疑是在资源有限或对模型大小有特定要求的场景的重大进步。接下来,让我们一起来了解这篇论文的详细工作吧!
论文题目:
Orca 2: Teaching Small Language Models How to Reason
论文链接:
https://arxiv.org/pdf/2311.11045.pdf
在研究团队之前发布的Orca1中,通过使用解释跟踪这类更丰富的信号训练模型,已经超过了传统指令调优模型在BigBench Hard和AGIEval基准测试中的表现。
大模型研究测试传送门
GPT-4传送门(免墙,可直接测试,遇浏览器警告点高级/继续访问即可):
http://hujiaoai.cn
在Orca2中,研究团队继续探索了改进训练信号来增强小型的大语言模型的推理能力。实验结果证明过度依赖模仿学习(即复制更强大模型的输出)可能会限制小模型的潜力。
Orca 2的目标是教会小模型如逐步处理、回忆-生成、回忆-推理-生成、提取-生成和直接回答这些推理技巧,并帮助这些模型决定何时使用最有效的推理策略,研究团队称这种方法为“谨慎推理”(Cautious Reasoning),旨在根据任务选择最佳解决策略。Orca 2模型在15个不同的基准测试(包括约100个任务和超过36000个独特提示)上进行了评估,表现显著超过同等大小的模型,并达到或超过了体量为其5-10倍的模型的性能水平。
调优方法
研究团队采用了 “指令调优”(instruction tuning)和“解释调优”(explanation tuning) 的方法。
指令调优
指令调优(Instruction Tuning)是训练的关键步骤,涉及从自然语言任务描述和期望行为示范的输入-输出对中学习。输入的是任务的描述,输出是期望的行为的演示,通过过自然语言任务描述(输入)和所需行为的演示(输出)来学习。这种方法在模仿“教师”模型的风格方面非常有效,然而,研究也表明,在对知识密集或推理密集型任务进行评估时,这种方法容易仅复制“风格”,忽视答案的正确性。
解释调优
针对指令调优的问题,研究团队引入了解释调优(Explanation Tuning),使它们能够从教师模型那里获取更丰富、更有表现力的推理信号。这些信号是基于系统指令提取的,旨在从强大的LLM(如GPT-4)中提取“慢思考”(Slow Thinking)的丰富示范。通过系统指令获得详细解释来训练学生模型,目的是提取丰富的、更具表现力的推理信号。
解释调优开始于编制N个通用系统指令,使模型进行更谨慎的推理,例如“逐步思考”和“生成详细答案”。接下来,这些指令与广泛且多样化的用户提示结合,形成一个包含(系统指令,用户提示,LLM答案)的三元组数据集。
学生模型被训练以根据系统指令和用户提示来预测LLM的答案。如果用户提示可以被分为M个不同的类别,这些类别代表了不同类型的问题,解释调优就会生成M×N个不同的答案组合,从而增加训练数据的数量和多样性。

实验设计
数据集构建
Orca 2数据集有四个主要来源,包括FLAN-v2集合的各个子集合。这些子集合包含多个任务,总共1913个任务。从这些任务中选择了约包含23个类别的602K个零样本的用户查询,用来构建Cautious-Reasoning-FLAN数据集。
训练目标
Orca 2模型的训练起始于LLaMA-2-7B或LLaMA-2-13B的检查点,首先对FLAN-v2数据集进行了精细的微调处理。随后,模型在Orca 1提供的500万条ChatGPT数据上进行了为期3个周期的训练,继而在Orca 1和Orca 2共计110万条GPT-4数据和817千条数据上进行了4个周期的深入训练。在这一过程中采用了LLaMA的字节对编码(BPE)分词器来处理输入样本,并运用了打包技术,不仅提高了训练过程的效率,也确保了计算资源的高效利用。
基线模型
在基准测试中,Orca 2与多个最新的模型进行比较,包括LLaMA-2模型系列和WizardLM。
实验
在实验中,Orca 2与多个最新的模型进行了基准测试,包括LLaMA-2模型、WizardLM和GPT模型。这些测试涉及到各种任务,以评估Orca 2在开放式生成、摘要、安全性、偏见、推理和理解能力方面的性能。其中,实验室提到了Orca-2-13B和Orca-2-7B两个模型,是Orca 2项目中公开的语言模型,区别是模型的参数量。
被选中的基准测试包括:
-
AGIEval:包括一系列标准化考试,如GRE、GMAT、SAT、LSAT、律师资格考试、数学竞赛和国家公务员考试等。
-
DROP:一个需要模型执行诸如加法或排序等离散操作的阅读理解基准测试。
-
CRASS:评估LLM的反事实推理能力的数据集。
-
RACE:从中国学生英语考试中提取的阅读理解问题集合。
-
BBH (Big-Bench Hard):BIG-Bench的23个最难任务的子集。
-
GSM8K:测试多步骤数学推理能力的单词问题集合。
-
MMLU:衡量模型语言理解、知识和推理能力的基准测试,包含57个任务。
-
ARC:AI2推理挑战,是一个测试文本模型回答科学考试多项选择题的基准测试,分为“简单”和“挑战”两个子集。
除了上述基准测试外,还进行了针对文本完成、多轮开放式对话、归纳和抽象性摘要、安全性和真实性的评估。

推理能力
Orca 2在多种推理基准上的平均表现显示了其显著的推理能力。特别是在AGI Eval、BigBench-Hard (BBH)、DROP、RACE、GSM8K和CRASS测试中,Orca 2的表现超过了同等大小的其他模型。在更大的模型间的比较中,Orca 2-13B的表现与更大的LLaMA-2-Chat-70B相当,并与WizardLM-70B相比较为接近。

知识与语言理解
在MMLU、ARC-Easy和ARC-Challenge任务中,Orca 2-13B的表现超过了同等大小的LLaMA-2-Chat-13B和WizardLM-13B。在MMLU基准上,Orca 2-13B与更大的LLaMA-2-Chat-70B和WizardLM-70B的表现相似。

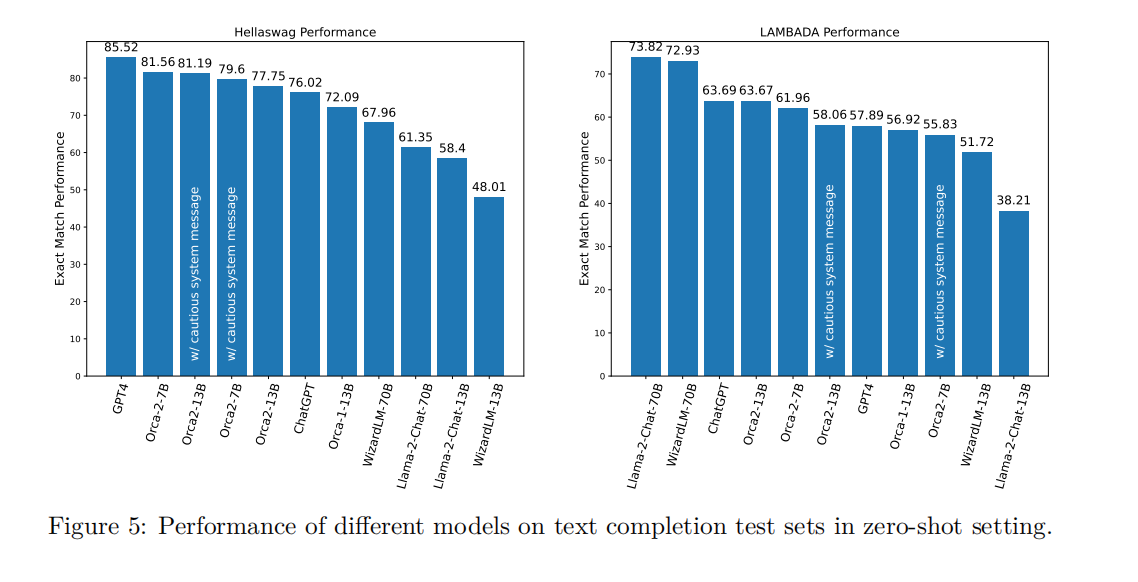
文本完整度
在HellaSwag和LAMBADA测试中,Orca 2-7B和Orca 2-13B均展现出较强的文本完成能力,特别是在HellaSwag测试中表现超过了13B和70B的基准模型。
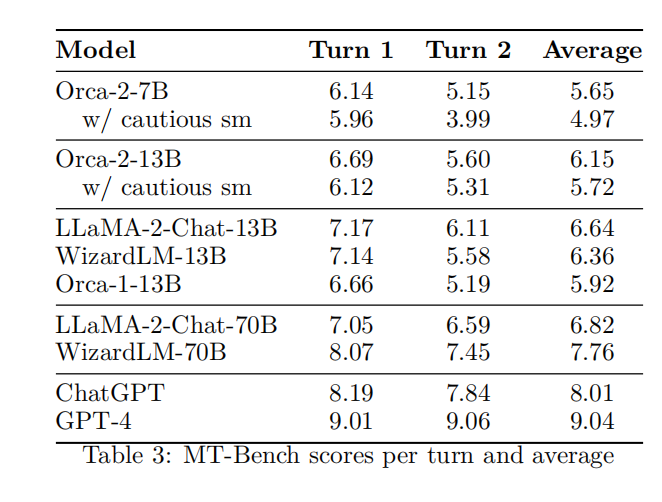
多轮开放式对话
在MT-Bench数据集上,Orca 2-13B与其他13B模型的表现相当。这表明Orca 2具有参与多轮对话的能力,尽管其训练数据中缺少对话内容。
基于对话的概括和抽象概括
在三个不同的任务中,Orca 2-13B展现了最低的虚构信息生成率,相较于其他Orca 2变体以及其他13B和70B的LLM模型。

安全性和真实性
在ToxiGen、HHH和TruthfulQA等数据集上的安全性评估显示,Orca 2在识别有毒声明和中性声明方面的表现与其他大小相当的模型相比具有一定的优势。
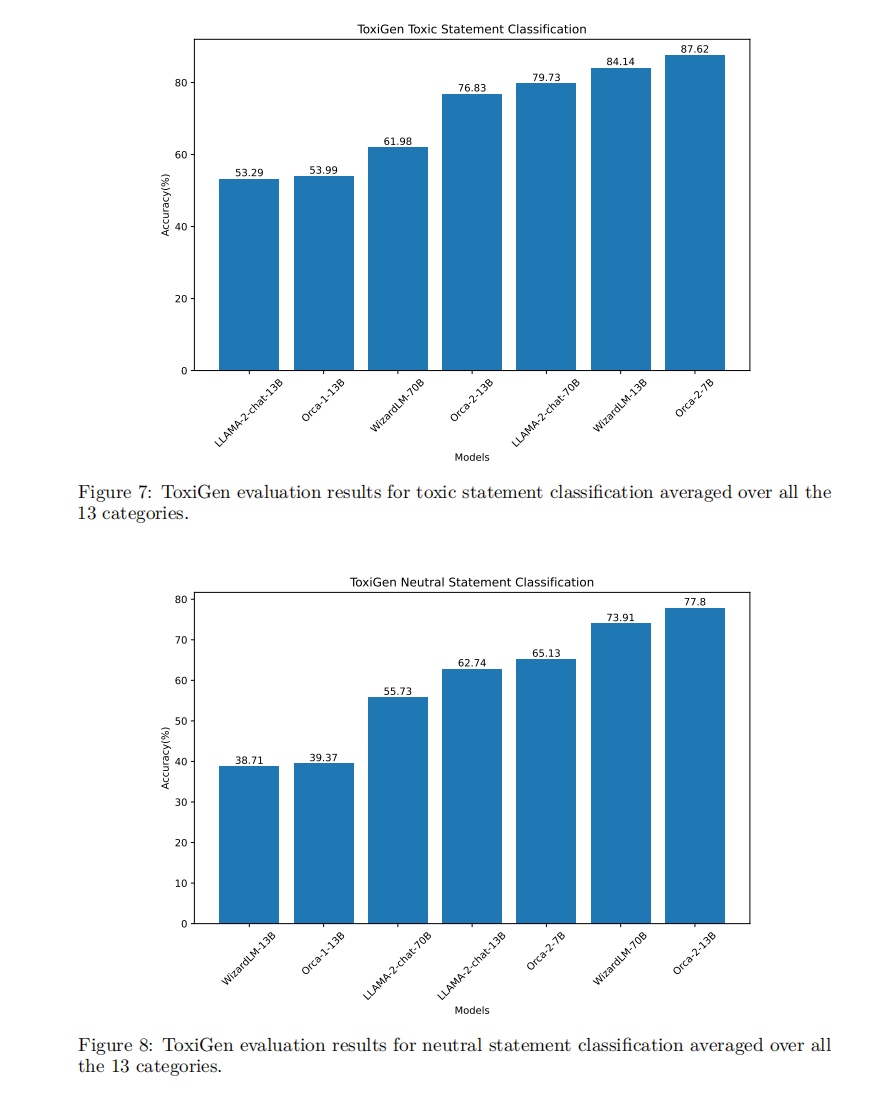
Orca 2模型在所进行的基准测试中整体表现卓越,明显超越了同等规模的其他模型,并能与其体量为5至10倍的模型相抗衡。特别是在零样本推理任务上,Orca-2-13B的成绩显著高于同类模型,相较于LLaMA-2-Chat-13B和WizardLM-13B,分别取得了47.54%和28.15%的相对提升。这一成绩凸显了Orca 2训练流程的高效性。这些成果展示了即使在较小规模的大语言模型中,通过精细的训练方法也能达到优异的推理能力。Orca 2在推理任务上的表现不仅在同等规模模型中脱颖而出,而且在某些场合甚至可与大型的模型匹敌,这对小型模型的进步和发展具有重要的启示意义。
模型的限制
在论文的第7部分,作者们讨论了Orca 2模型的一些限制。这些限制不仅包括基于LLaMA 2模型家族的Orca 2所继承的限制,还包括大型语言模型和Orca 2特定训练过程中的通用限制:
1.数据偏见:基于大量数据训练的大语言模型可能无意中承载了源数据中的偏见。导致偏见或不公平的输出。
2.缺乏透明度:由于复杂性和规模,大语言模型表现得像“黑盒子”,难以理解特定输出或决策背后的逻辑。
3.内容伤害:大语言模型可能造成各种类型的内容伤害,建议利用不同公司和机构提供的各种内容审查服务。
4.幻觉现象:作者建议要意识到并谨慎地避免完全依赖于语言模型进行关键决策或信息,因为目前还不清楚如何防止这些模型编造内容。
5.滥用潜力:如果没有适当的保护措施,这些模型可能被恶意用于生成虚假信息或有害内容。
6.数据分布:Orca 2的性能可能与调优数据的分布密切相关。这种相关性可能会限制模型在训练数据集中代表性不足的领域(如数学和编码)的准确性。
7.系统信息:Orca 2根据系统指令的不同表现出性能的变化。此外,模型大小引入的随机性可能导致对不同系统指令产生非确定性响应。
8.零样本设置:Orca 2主要在模拟零样本设置的数据上进行训练。虽然模型在零样本设置中表现非常强劲,但与其他更大模型相比,它并没有展现出使用少样本学习的同等增益。
10.合成数据:由于Orca 2是在合成数据上训练的,它可能继承了用于数据生成的模型和方法的优势和缺点。作者认为Orca 2受益于训练过程中纳入的安全措施和Azure OpenAI API中的安全护栏(如内容过滤器)。然而,需要更详细的研究来更好地量化这些风险。
11.小型模型容量:训练后的小型模型,虽然在教会模型解决任务方面大有裨益,但并不一定会教会模型新知识。因此,训练后的模型主要受限于预训练期间学到的知识。