本文所有案例基于《SQL进阶教程》实现。
概述
SQL中的CASE表达式是一种通用的条件表达式,类似于其他语言中的if/else语句。它用于在SQL语句中实现条件逻辑。CASE表达式以WHEN子句开始,后面跟着一个或多个WHEN条件,每个WHEN条件后面跟着一个THEN子句。如果任何WHEN条件为真,则返回相应的THEN子句中的表达式。如果没有任何WHEN条件为真,则可以选择性地使用ELSE子句来指定一个默认的表达式。
CASE表达式的语法如下:
-- 简单 CASE 表达式
CASE sex
WHEN '1' THEN '男'
WHEN '2' THEN '女'
ELSE '其他' END
-- 搜索 CASE 表达式
CASE WHEN sex = '1' THEN '男'
WHEN sex = '2' THEN '女'
ELSE '其他' END需要注意,在发现为真的 WHEN 子句时,CASE 表达式的真假值判断就会中止,而剩余的 WHEN 子句会被忽略。为了避免引起不必要的混乱,使用 WHEN 子句时要注意条件的排他性。
-- 例如,这样写的话,结果里不会出现“第二”
CASE WHEN col_1 IN ('a', 'b') THEN '第一'
WHEN col_1 IN ('a') THEN '第二'
ELSE '其他' END此外,使用 CASE 表达式的时候,还需要注意以下几点。
- 统一各分支返回的数据类型
- 不要忘了写 END
- 养成写 ELSE 子句的习惯
结果转化
例如,现在有一张按照“‘1:北海道’、‘2:青森’、……、‘47:冲绳’”
这种编号方式来统计都道府县 A 人口的表,我们需要以东北、关东、九州等地区为单位来分组,并统计人口数量。具体来说,就是统计下表 PopTbl中的内容,得出如右表“统计结果”所示的结果。
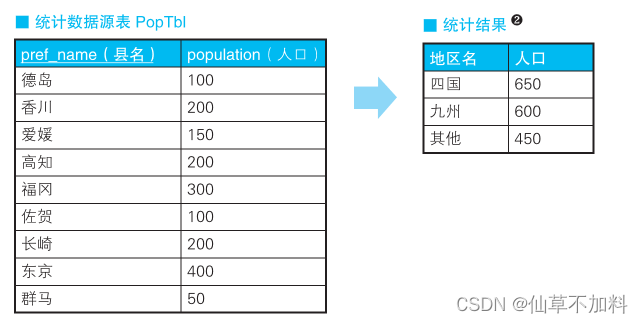
代码如下:
SELECT CASE pref_name
WHEN '德岛' THEN '四国'
WHEN '香川' THEN '四国'
WHEN '爱媛' THEN '四国'
WHEN '高知' THEN '四国'
WHEN '福冈' THEN '九州'
WHEN '佐贺' THEN '九州'
WHEN '长崎' THEN '九州'
ELSE '其他' END AS district,
SUM(population)
FROM PopTbl
-- GROUP BY 子句里引用了 SELECT 子句中定义的别名
GROUP BY district; 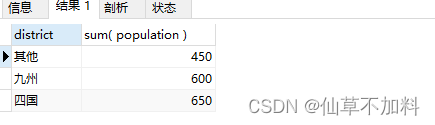
使用case表达式能够方便的将数据库中查询到的结果转化为我们需要的结果,但是在本代码中使用到的别名进行分组,这种写法是违反标准sql的规则的。在select语句的执行流程中,group by语句会比select语句先执行,所以在group by语句中引用在select语句里定义的别称是不被允许的。
条件统计
例如,我们需要往存储各县人口数量的表 PopTbl 里添加上“性别”列,然后求按性别、县名汇总的人数。具体来说,就是统计表 PopTbl2 中的数据,然后求出如表“统计结果”所示的结果。
代码如下:
SELECT pref_name,
-- 男性人口
SUM( CASE WHEN sex = '1' THEN population ELSE 0 END) AS cnt_m,
-- 女性人口
SUM( CASE WHEN sex = '2' THEN population ELSE 0 END) AS cnt_f
FROM PopTbl2
GROUP BY pref_name;配合check约束使用
假设某公司规定“女性员工的工资必须在 20 万日元以下”,而在这个公司的人事表中,这条无理的规定是使用 CHECK 约束来描述的,代码如下所示。
-- 代码1
CONSTRAINT check_salary CHECK
( CASE WHEN sex = '2'
THEN CASE WHEN salary <= 200000
THEN 1 ELSE 0 END
ELSE 1 END = 1 )
-- 代码2
CONSTRAINT check_salary CHECK
( sex = '2' AND salary <= 200000 )代码1表示的含义是:限制插入“如果员工的性别为女,在此基础上判断工资是否在20万日元以下”的数据,如果员工不是女性,则不做限制。
代码2表示的含义是:限制插入“员工必须为女性而且工资必须在20万日元以下”的数据。
所以代码1表示的含义才是我们所需求的,这就体现出与case与check配合的独特性了。
在update语句进行条件分支
需求:以某数值型的列的当前值为判断对象,将其更新成别的值。这里的问题是,此时UPDATE操作的条件会有多个分支。例如,我们通过下面这样一张公司人事部的员工工资信息表 Salaries 来看一下这种情况。
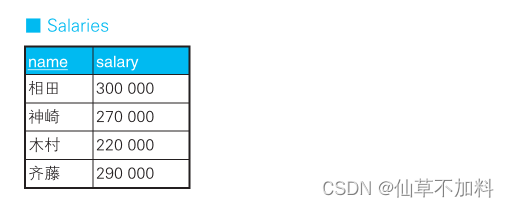
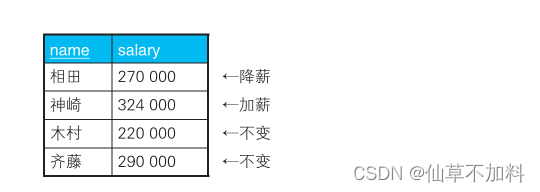
假设现在需要根据以下条件对该表的数据进行更新。
1. 对当前工资为 30 万日元以上的员工,降薪 10%。
2. 对当前工资为 25 万日元以上且不满 28 万日元的员工,加薪 20%。按照这些要求更新完的数据应该如下表所示。
代码如下:
-- 代码1
-- 条件 1
UPDATE Salaries
SET salary = salary * 0.9
WHERE salary >= 300000;
-- 条件 2
UPDATE Salaries
SET salary = salary * 1.2
WHERE salary >= 250000 AND salary < 280000;
-- 代码2
-- 用 CASE 表达式写正确的更新操作
UPDATE Salaries
SET salary = CASE WHEN salary >= 300000
THEN salary * 0.9
WHEN salary >= 250000 AND salary < 280000
THEN salary * 1.2
ELSE salary END;代码1使用了2条update语句,分别对这两种条件进行修改,先更新工资大于30万日元的数据,再更新25-28万日元的数据,这就会导致第一次更新之后,相田的工资已经被更新成25-28万日元之间了,第二次继续更新,影响了最终结果。所以这种更新方式不可取。
代码2使用了case条件进行更新,这种好处是只执行1次sql,效率更高,且对数据更安全。
数据匹配
如下所示,这里有一张资格培训学校的课程一览表和一张管理每个月所设课程的表。
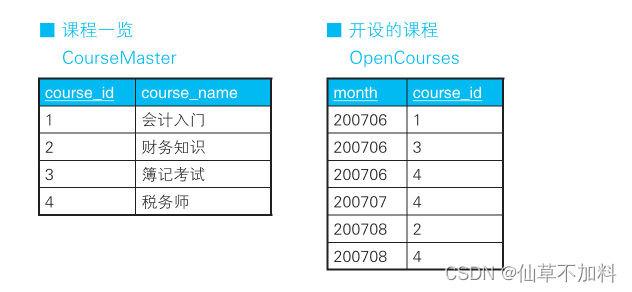
我们要用这两张表来生成下面这样的交叉表,以便于一目了然地知道每个月开设的课程。
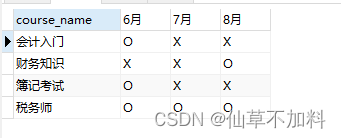
代码如下:
-- 表的匹配 :使用 IN 谓词
SELECT course_name,
CASE WHEN course_id IN
(SELECT course_id FROM OpenCourses
WHERE month = 200706) THEN '○' ELSE '×' END AS "6 月",
CASE WHEN course_id IN
(SELECT course_id FROM OpenCourses
WHERE month = 200707) THEN '○' ELSE '×' END AS "7 月",
CASE WHEN course_id IN
(SELECT course_id FROM OpenCourses
WHERE month = 200708) THEN '○' ELSE '×' END AS "8 月"
FROM CourseMaster;
-- 表的匹配 :使用 EXISTS 谓词
SELECT CM.course_name,
CASE WHEN EXISTS
(SELECT course_id FROM OpenCourses OC
WHERE month = 200706 AND OC.course_id = CM.course_id) THEN '○'
ELSE '×' END AS "6 月",
CASE WHEN EXISTS
(SELECT course_id FROM OpenCourses OC
WHERE month = 200707 AND OC.course_id = CM.course_id) THEN '○'
ELSE '×' END AS "7 月",
CASE WHEN EXISTS
(SELECT course_id FROM OpenCourses OC
WHERE month = 200708 AND OC.course_id = CM.course_id) THEN '○'
ELSE '×' END AS "8 月"
FROM CourseMaster CM; 这样的查询没有进行聚合,因此也不需要排序,月份增加的时候仅修改 SELECT 子句就可以了,扩展性比较好。
无论使用 IN 还是 EXISTS,得到的结果是一样的,但从性能方面来说,EXISTS 更好。通过 EXISTS 进行的子查询能够用到“month, course_id”这样的主键索引,因此尤其是当表 OpenCourses 里数据比较多的时候更有优势。
使用聚合函数
假设这里有一张显示了学生及其加入的社团的一览表。如表 StudentClub 所示,这张表的主键是“学号、社团 ID”,存储了学生和社团之间多对多的关系。

有的学生同时加入了多个社团(如学号为 100、200 的学生),有的学生只加入了某一个社团(如学号为 300、400、500 的学生)。对于加入了多个社团的学生,我们通过将其“主社团标志”列设置为 Y 或者 N 来表明哪一个社团是他的主社团;对于只加入了一个社团的学生,我们将其“主社团标志”列设置为 N。
接下来,我们按照下面的条件查询这张表里的数据。
1. 获取只加入了一个社团的学生的社团 ID。
2. 获取加入了多个社团的学生的主社团 ID。
SELECT std_id,
CASE WHEN COUNT(*) = 1 -- 只加入了一个社团的学生
THEN MAX(club_id)
ELSE MAX(CASE WHEN main_club_flg = 'Y'
THEN club_id
ELSE NULL END)
END AS main_club
FROM StudentClub
GROUP BY std_id;
使用CASE 表达式表示了“只加入了一个社团还是加入了多个社团”这样的条件分支。如果只加入一个社团就获取社团id,如果加入多个社团就获取主社团id。
总结
- 在 GROUP BY 子句里使用 CASE 表达式,可以灵活地选择作为聚合的单位的编号或等级。这一点在进行非定制化统计时能发挥巨大的威力。
- 在聚合函数中使用 CASE 表达式,可以轻松地将行结构的数据转换成列结构的数据。
- 相反,聚合函数也可以嵌套进 CASE 表达式里使用。
- 相比依赖于具体数据库的函数,CASE 表达式有更强大的表达能力和更好的可移植性。
- 正因为 CASE 表达式是一种表达式而不是语句,才有了这诸多优点。
练习题
1.用 SQL 从多行数据里选出最大值或最小值很容易——通过 GROUP BY子句对合适的列进行聚合操作,并使用 MAX 或 MIN 聚合函数就可以求出。那么,从多列数据里选出最大值该怎么做呢?
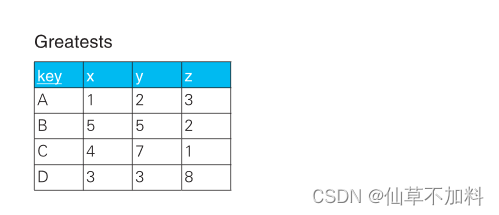
代码如下:
select gkey,
case when x > y then (case when x > z then x else z end)
else (case when y > z then y else z end) end as greatest
from greatests 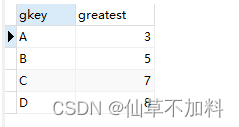
2.使用正文中的表 PopTbl2 作为样本数据,练习一下把行结构的数据转换为列结构的数据吧。这次请生成下面这样的表头里带有汇总和再揭的二维表。

代码如下:
select
case sex when 1 then '男' else '女' end as '性别',
sum(population) as '全国',
sum(case when pref_name = '德岛' then population else 0 end) as '德岛',
sum(case when pref_name = '香川' then population else 0 end) as '香川',
sum(case when pref_name = '爱媛' then population else 0 end) as '爱媛',
sum(case when pref_name = '高知' then population else 0 end) as '高知',
sum(case when pref_name in ('德岛','香川','爱媛','高知') then population else 0 end) as '四国(再揭)'
from poptbl2
group by sex
3.对练习题 1 里用过的表 Greatests 正常执行 SELECT key FROM Greatests ORDER BY key; 这个查询后,结果会按照 key 这一列值的字母表顺序显示出来。
那么,请思考一个查询语句,使得结果按照 B-A-D-C 这样的指定顺序进行排列。
代码如下:
SELECT gkey
FROM Greatests
ORDER BY case gkey
when 'B' then 1
when 'A' then 2
when 'D' then 3
when 'C' then 4
else null end