1.resize
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable {
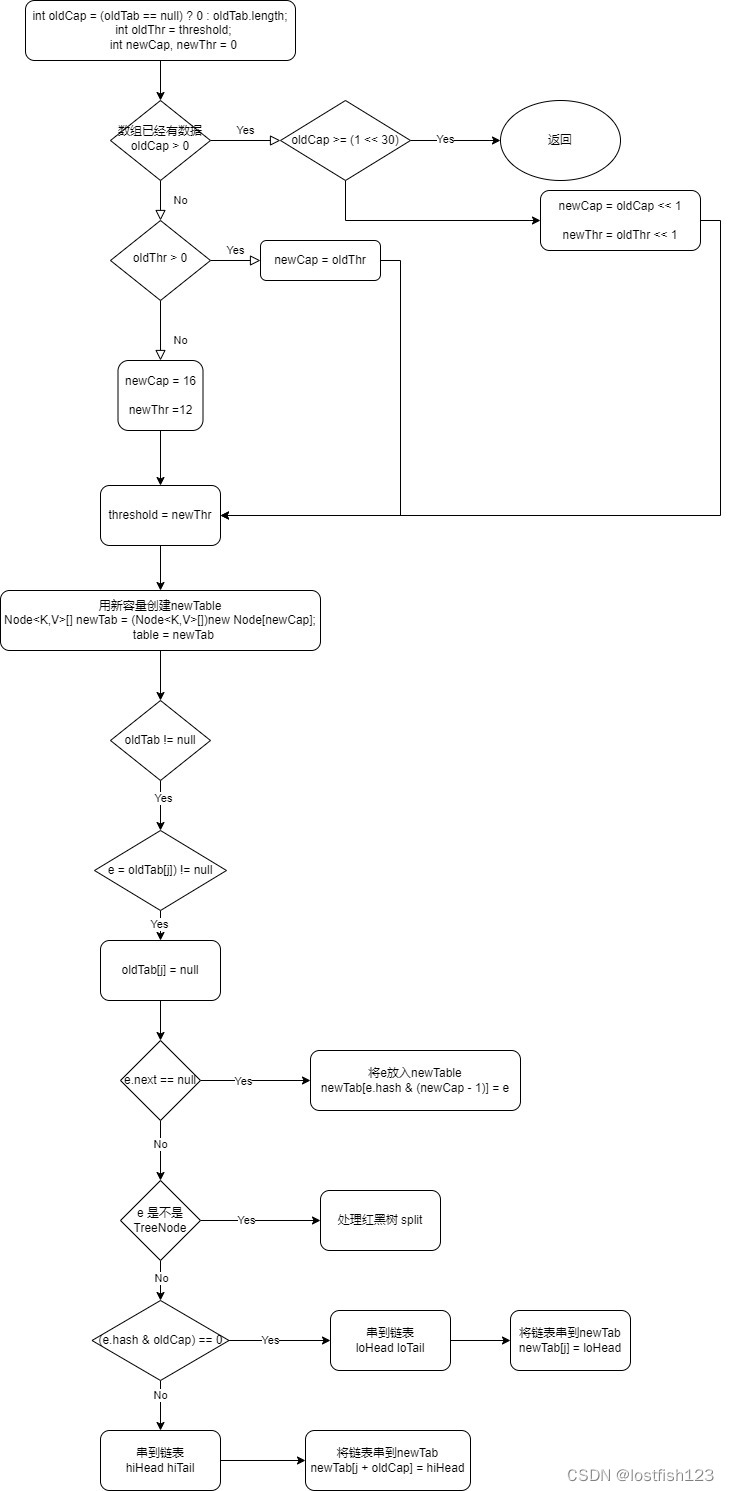
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length; //老的数组容量
int oldThr = threshold;//老的阈值
int newCap, newThr = 0;
if (oldCap > 0) {//老的数组容量大于0,说明table初始化过了
if (oldCap >= MAXIMUM_CAPACITY) { //已经达到最大容量
threshold = Integer.MAX_VALUE;
return oldTab;
} else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY){//新容量=老容量*2
newThr = oldThr << 1; // double threshold
}
} else if (oldThr > 0){ // initial capacity was placed in threshold
newCap = oldThr;//这里是大于初始化容量的最小的2的n次方
} else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;//默认为16
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY); //16*0.75
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;//赋值新阈值
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr; //更新全局threshold
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];//根据新容量创建新数组
table = newTab;//更新全局table
if (oldTab != null) {//说明老数组有数据,需要分配到新数组
for (int j = 0; j < oldCap; ++j) {//遍历数组
Node<K,V> e;
if ((e = oldTab[j]) != null) {//第j个桶
oldTab[j] = null;//老数组的值赋值为null,方便回收
if (e.next == null){
//只有一个元素,新算出index,赋值给新数组newTab[index]
newTab[e.hash & (newCap - 1)] = e;
} else if (e instanceof TreeNode){//如果是树
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
} else { // preserve order
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {//满足这个条件的元素组成一个链表
if (loTail == null){
loHead = e;
} else{
loTail.next = e;
}
loTail = e;
} else {//满足这个条件的元素组成一个链表
if (hiTail == null){
hiHead = e;
} else{
hiTail.next = e;
}
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;//链表头
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;//链表头
}
}
}
}
}
return newTab;
}
}2.流程图
3.(e.hash & oldCap) == 0的理解
&:按位与 两个数都为1的时候,才为1
(e.hash & oldCap) == 0 新索引:j(跟老索引一致)
(e.hash & oldCap) != 0 新索引:j + oldCap
3.1. (e.hash & oldCap) == 0
假设oldCap是16,二进制就是 0001 0000
(e.hash & oldCap) == 0 的时候,e.hash的从右到左第5位为0:xxx0 xxxx
oldIndex = e.hash & (oldCap -1)
xxx0 xxxx
0000 1111 15
===========
0000 xxxx
newIndex = e.hash & (2*oldCap - 1)
xxx0 xxxx
0001 1111 31
===========
0000 xxxx
所以,如果(e.hash & oldCap) == 0的时候,这些元素的新索引跟老索引一致。
3.2. (e.hash & oldCap) != 0
假设oldCap是16,二进制就是 0001 0000
(e.hash & oldCap) != 0 的时候,e.hash的从右到左第5位为1:xxx1 xxxx
oldIndex = e.hash & (oldCap -1)
xxx1 xxxx
0000 1111 15
===========
0000 xxxx
newIndex = e.hash & (2*oldCap - 1)
xxx1 xxxx
0001 1111 31
===========
0001 xxxx
所以,如果(e.hash & oldCap) != 0的时候,这些元素的新索引=老索引+oldCap。
4.疑惑
在挪动老的数据到新table的时候,为啥要这样计算呢?这样计算并没有省什么时间吧
计算在新table的位置e.hash & (newCap - 1),这个跟e.hash & oldCap执行速度一样,为啥不直接用e.hash & (newCap - 1)计算?
if ((e.hash & oldCap) == 0) {//满足这个条件的元素组成一个链表
if (loTail == null){
loHead = e;
} else{
loTail.next = e;
}
loTail = e;
} else {//满足这个条件的元素组成一个链表
if (hiTail == null){
hiHead = e;
} else{
hiTail.next = e;
}
hiTail = e;
}



![[linux运维] 利用zabbix监控linux高危命令并发送告警(基于Zabbix 6)](https://img-blog.csdnimg.cn/img_convert/c5db22c2ca3dbe1983b20642d6d9b8c4.png)


![[VSCode] Java开发环境配置](https://img-blog.csdnimg.cn/direct/a606654342694f43b7505ebf39c9eca5.png#pic_center)