代码随想录二刷 | 栈与队列 | 前 k 个高频元素
- 题目描述
- 解题思路 & 代码实现
题目描述
347.前k个高频元素
给你一个整数数组 nums 和一个整数 k ,请你返回其中出现频率前 k 高的元素。你可以按 任意顺序 返回答案。
示例 1:
输入: nums = [1,1,1,2,2,3], k = 2
输出: [1,2]
示例 2:
输入: nums = [1], k = 1
输出: [1]
提示:
- 1 <= nums.length <= 105
- k 的取值范围是 [1, 数组中不相同的元素的个数]
题目数据保证答案唯一,换句话说,数组中前 k 个高频元素的集合是唯一的
进阶:你所设计算法的时间复杂度 必须 优于 O(n log n) ,其中 n 是数组大小。
解题思路 & 代码实现
这道题目主要涉及到如下三块内容:
- 要统计元素出现频率
- 对频率排序
- 找出前K个高频元素
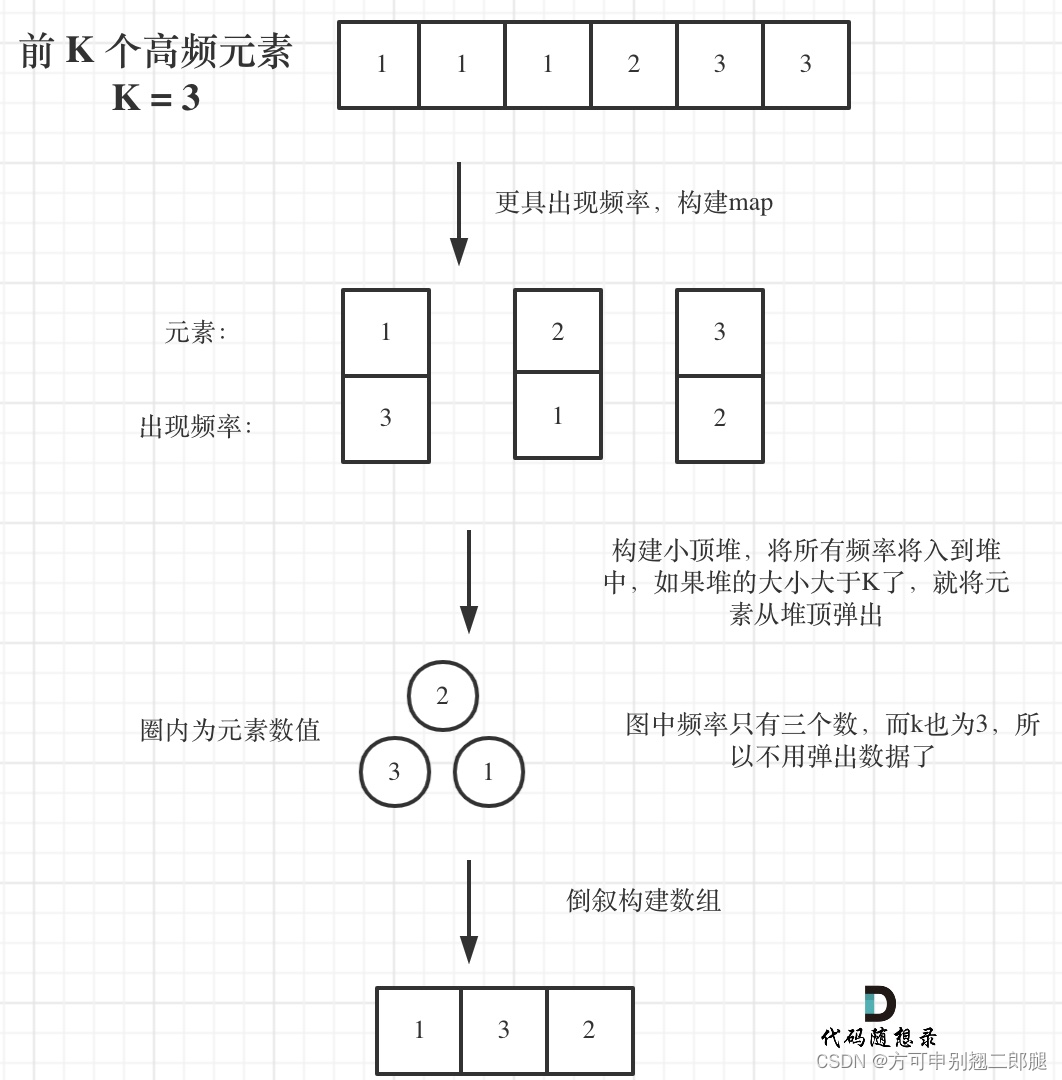
首先统计元素出现的频率,这一类的问题可以使用map来进行统计。
然后是对频率进行排序,这里我们可以使用一种容器适配器,就是优先级队列。
优先级队列是一个披着队列外衣的堆,因为优先级队列对外接口只是从队头取元素,从队尾添加元素,再无其他取元素的方式,看起来就是一个队列。而且优先级队列内部元素是自动依照元素的权值排列。
缺省情况下priority_queue利用max-heap(大顶堆)完成对元素的排序,这个大顶堆是以vector为表现形式的complete binary tree(完全二叉树)。
堆是一棵完全二叉树,树中每个结点的值都不小于(或不大于)其左右孩子的值。 如果父亲结点是大于等于左右孩子就是大顶堆,小于等于左右孩子就是小顶堆。
因为要统计最大前 k 个元素,只有小顶堆每次将最小的元素弹出,最后小顶堆里积累的才是前 k 个最大元素。
class Solution {
public:
// 小顶堆
class myComparison {
public:
bool operator()(const pair<int, int>& lhs, const pair<int, int>& rhs) {
return lhs.second > rhs.second;
}
};
vector<int> topKFrequent(vector<int>& nums, int k) {
// 统计元素出现频率
unordered_map<int, int> map; // map<nums[i], 对应出现的次数>
for (int i = 0; i < nums.size(); i++;) {
map[nums[i++]]++;
}
// 对频率排序
// 定义一个小顶堆,大小为 k
priority_queue<pair<int, int>, vector<pair<int, int>>, myComparison> pri_que;
// 用固定大小为 k 的小顶堆,扫描所有频率的数值
for (unordered_map<int, int>::iterator it = map.begin(); it != map.end(); it++) {
pri_que.push(*it);
// 如果堆的大小大于 k,则队列弹出,保证堆的大小一直为 k
if (pri_que.size() > k) {
pri_que.pop();
}
}
// 找出前 k 个高频元素,因为小顶堆先弹出的是最小的,所以倒序来输出到数组中
vector<int> result(k);
for (int i = k - 1; i >= 0; i--) {
result[i] = pri_que.top().first;
pri_que.pop();
}
return result;
}
};
![[node] Node.js的Web 模块](https://img-blog.csdnimg.cn/999f27a1616742569128568e8d1f3b4a.png)