PPOCRv3检测模型和识别模型的训练和推理
文章目录
- PPOCRv3检测模型和识别模型的训练和推理
- 前言
- 一、环境安装
- 1,官方推荐环境:
- 2,本机GPU环境
- 二、Conda虚拟环境
- 1.Win10安装Anaconda3
- 2.使用conda创建虚拟环境
- 三、安装PPOCR环境
- 1,安装paddlepaddle
- 2,安装paddleOCR
- 3,测试中英文模型识别
- 4,可能遇到的错误
- 四、Win10环境训练提示
- 五、标注图片
- 1,安装PPOCRLabel
- 2,启动运行
- 3、准备数据集
- 七、检测模型训练
- 1. 进入主目录
- 2. 开始训练
- 3. 可能出现的错误
- 4. 断点训练
- 5. 指标评估(F-score)
- 6. 单张测试
- 7. 文件夹测试
- 8. 模型转换
- 9. DB模型预测
- 八、识别模型训练
- 1. 单卡训练命令如下:
- 2. 断点训练
- 3. GPU 评估
- 4. 预测结果
- 5. 模型导出
- 6. 使用中间值测试
- 九、模型转为nb格式
- 总结
前言
PPOCR是百度飞桨的开源OCR产品,在OCR领域优势领先。
一、环境安装
1,官方推荐环境:
PaddlePaddle >= 2.1.2
Python 3.7
CUDA10.1 / CUDA10.2
CUDNN 7.6
2,本机GPU环境
本机系统:Win10
显卡型号:GeForce RTX 2060, NVIDIA控制面板
驱动版本: 457.20
cuda:cuda10.2
cudnn:cudnn7.6.5
cuda安装参考:
https://zhuanlan.zhihu.com/p/99880204
https://developer.nvidia.com/cuda-toolkit-archive
cuda版本查看:nvcc -V
cudnn安装参考:
https://developer.nvidia.com/rdp/cudnn-archive
二、Conda虚拟环境
1.Win10安装Anaconda3
略
2.使用conda创建虚拟环境
conda create --name paddle_env python=3.8
#激活paddle_env环境
conda activate paddle_env
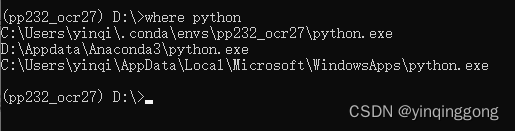
#查看当前python的位置
where python
三、安装PPOCR环境
1,安装paddlepaddle
需要对应cuda版本的paddlepaddle,参考链接:
https://www.paddlepaddle.org.cn/install/quick?docurl=/documentation/docs/zh/install/pip/windows-pip.html
由于项目中使用C++版本paddleInference2.3.2.dll推理,所以使用的安装命令:
conda install paddlepaddle-gpu==2.3.2 cudatoolkit=10.2 --channel https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/Paddle/
官方推荐命令:
conda install paddlepaddle-gpu==2.5.1 cudatoolkit=10.2 --channel https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/Paddle/
或者
python -m pip install paddlepaddle-gpu==2.5.1.post102 -f https://www.paddlepaddle.org.cn/whl/windows/mkl/avx/stable.html
2,安装paddleOCR
pip install "paddleocr>=2.0.1" # 推荐使用2.0.1+版本
命令默认安装最新版本2.7.0.2
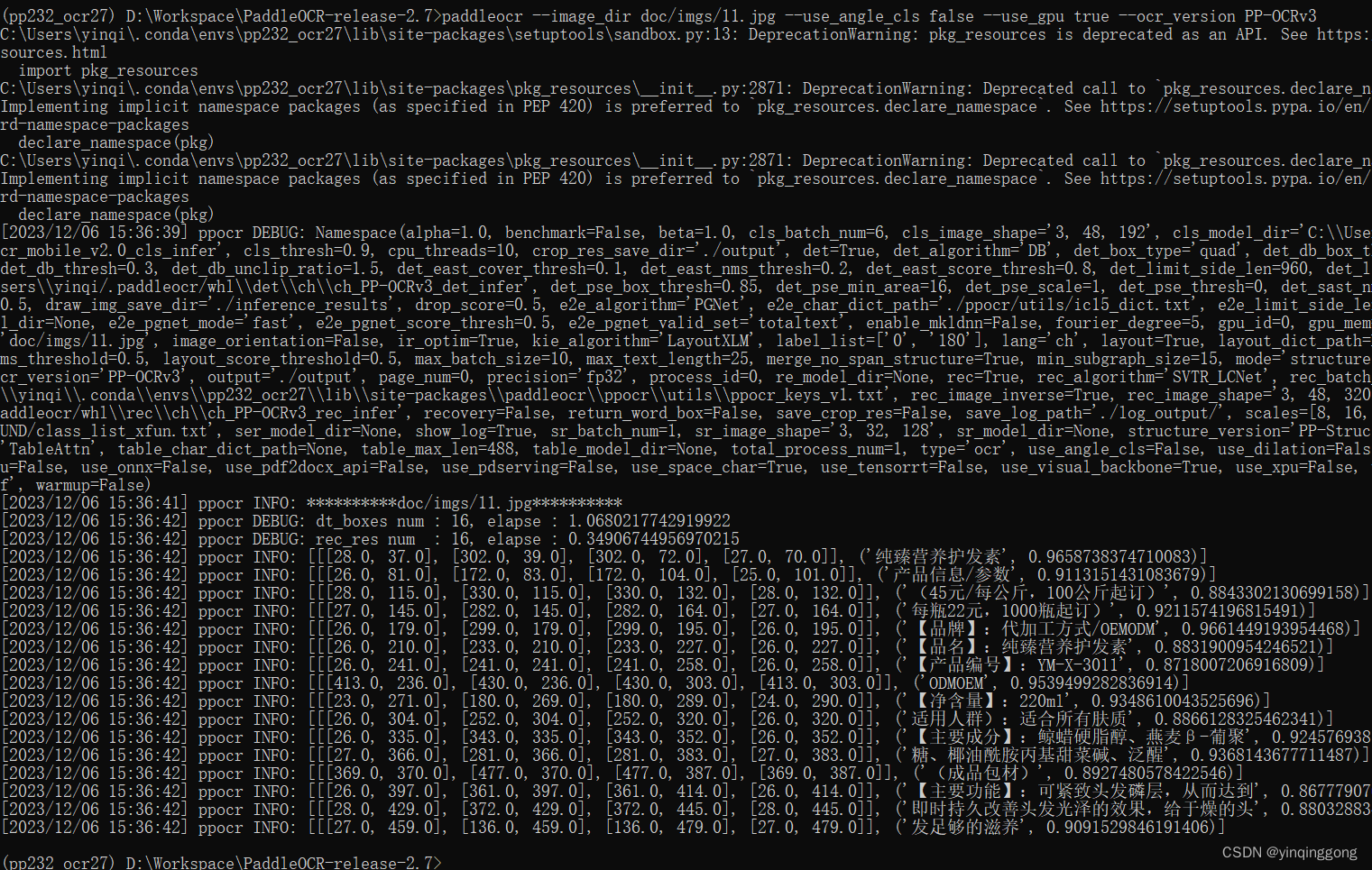
3,测试中英文模型识别
paddleocr --image_dir doc/imgs/11.jpg --use_angle_cls false --use_gpu true --ocr_version PP-OCRv3
4,可能遇到的错误
错误处理1:(OMP: Error #15: Initializing libiomp5md.dll, but found libiomp5 already initialized)
set KMP_DUPLICATE_LIB_OK=True
错误处理2:(AttributeError: module ‘numpy’ has no attribute ‘int’.)
pip install "Numpy==1.23.5"
四、Win10环境训练提示
a. 检测需要的数据相对较少,在PaddleOCR模型的基础上进行Fine-tune,一般需要500张可达到不错的效果。
b. 识别分英文和中文,一般英文场景需要几十万数据可达到不错的效果,中文则需要几百万甚至更多。
c, Windows GPU/CPU 在Windows平台上与Linux平台略有不同: Windows平台只支持单卡的训练与预测,指定GPU进行训练set CUDA_VISIBLE_DEVICES=0
d, 在Windows平台,DataLoader只支持单进程模式,因此需要设置 num_workers 为0;
五、标注图片
1,安装PPOCRLabel
pip install PPOCRLabel -i https://mirror.baidu.com/pypi/simple
或者
pip install PPOCRLabel # 安装
2,启动运行
选择标签模式来启动
PPOCRLabel --lang ch # 启动【普通模式】,用于打【检测+识别】场景的标签
可能遇到的问题:删除图片出现No module named ‘win32com’
pip install pypiwin32
3、准备数据集
a. 标注完成后导出识别结果
b. 划分数据集
cd D:\Workspace\PaddleOCR-release-2.7\PPOCRLabel # 将目录切换到PPOCRLabel文件夹下
python gen_ocr_train_val_test.py --trainValTestRatio 6:2:2 --datasetRootPath ../zrd_images
c. 生成检测和识别数据集目录
D:\Workspace\PaddleOCR-release-2.7\train_data
七、检测模型训练
1. 进入主目录
cd D:\Workspace\PaddleOCR-release-2.7
2. 开始训练
官方推荐使用的配置文件和预训练模型如下
python tools/train.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_student.yml -o Global.pretrained_model=./pretrain_models/ch_PP-OCRv3_det_distill_train/student
执行此命令前先从官网下载ch_PP-OCRv3_det_distill_train模型,并选择student模型(官方推荐),然后修改yml文件
a. 训练集位置
Train:
dataset:
name: SimpleDataSet
data_dir: ./train_data/det/ # 训练集目录
label_file_list:
- ./train_data/det/train.txt # 训练标注文件
ratio_list: [1.0]
b. 验证集位置
Eval:
dataset:
name: SimpleDataSet
data_dir: ./train_data/det/ # 验证集目录
label_file_list:
- ./train_data/det/val.txt # 验证标注文件
transforms:
- DecodeImage:
c. 非常重要,这俩参数需要跟推理的参数保持一致,官方默认DetResizeForTest:null, 从代码中其实是(limit_side_len:736 limit_type:min处理)
- DetResizeForTest:
limit_side_len: 960
limit_type: max
比如本人C++推理参数:
std::string FLAGS_limit_type = "max"; //"limit_type of input image.");
int FLAGS_limit_side_len = 960;// "max_side_len of input image.");
如果这俩参数不一致会导致推理结果跟官方相差较大。
d. 对于Win10
num_workers: 0
e. 如果显卡较弱,适当调小batchsize
batch_size_per_card: 32
3. 可能出现的错误
a. 训练出现错误1:module ‘numpy’ has no attribute ‘bool’,原因是numpy版本不对
pip3 install numpy==1.23.1
b. 训练出现错误2:Out of memory error on GPU,显卡内存小,调整batchsize大小
batch_size_per_card: 32
4. 断点训练
python tools/train.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_student.yml -o Global.checkpoints=./output/ch_PP-OCR_v3_det/latest
5. 指标评估(F-score)
python tools/eval.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_student.yml -o Global.checkpoints=./output/ch_PP-OCR_v3_det/best_accuracy
6. 单张测试
python tools/infer_det.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_student.yml -o Global.infer_img=./train_data/det/test/0a1a8ba8c6374088a2d13cbba443b526.jpg Global.pretrained_model=./output/ch_PP-OCR_v3_det/best_accuracy
7. 文件夹测试
python tools/infer_det.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_student.yml -o Global.infer_img=./train_data/det/test/ Global.pretrained_model=./output/ch_PP-OCR_v3_det/best_accuracy
8. 模型转换
加载配置文件ch_PP-OCRv3/ch_PP-OCRv3_det_student.yml,从output/det_db目录下加载best_accuracy模型,inference模型保存在./output/det_db_inference目录下
python tools/export_model.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_student.yml -o Global.pretrained_model=./output/ch_PP-OCR_v3_det/best_accuracy Global.save_inference_dir=./output/det_db_inference/
导出有三个文件夹 student student2 teacher,选student和student2中效果好的使用
9. DB模型预测
python tools/infer/predict_det.py --det_algorithm="DB" --det_model_dir="./output/det_db_inference/" --image_dir="D:\Workspace\ZrdQRCode\ZrdDecoderServer2.13\images\test\2022-09-26-04-16-03-229.jpg" --use_gpu=True
八、识别模型训练
1. 单卡训练命令如下:
python tools/train.py -c configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml -o Global.pretrained_model=./pretrain_models/ch_PP-OCRv3_rec_train/best_accuracy
执行命令前下载预训练模型ch_PP-OCRv3_rec_train,然后修改ch_PP-OCRv3_rec_distillation.yml文件
a. 训练数据集
Train:
dataset:
name: SimpleDataSet
data_dir: ./train_data/rec/
ext_op_transform_idx: 1
label_file_list:
- ./train_data/rec/train.txt
transforms:
b. 验证数据集
Eval:
dataset:
name: SimpleDataSet
data_dir: ./train_data/rec
label_file_list:
- ./train_data/rec/val.txt
transforms:
c. 对于Windows
num_workers: 0
d. 如果显卡较弱
batch_size_per_card: 32
e. 错误处理
错误处理1:No module named ‘yaml’
pip install pyyaml
2. 断点训练
python tools/train.py -c configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml -o Global.checkpoints=./output/rec_ppocr_v3_distillation/latest
3. GPU 评估
python -m paddle.distributed.launch --gpus 0 tools/eval.py -c configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml -o Global.checkpoints=./output/rec_ppocr_v3_distillation/best_accuracy
Global.checkpoints 为待测权重
4. 预测结果
python tools/infer_rec.py -c configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml -o Global.pretrained_model=./output/rec_ppocr_v3_distillation/best_accuracy Global.infer_img=doc/imgs_words/ch/word_7.jpg
5. 模型导出
python tools/export_model.py -c configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml -o Global.pretrained_model=./output/rec_ppocr_v3_distillation/best_accuracy Global.save_inference_dir=./output/rec_db_inference/
-c 后面设置训练算法的yml配置文件
-o 配置可选参数
Global.pretrained_model 参数设置待转换的训练模型地址,不用添加文件后缀 .pdmodel,.pdopt或.pdparams
Global.save_inference_dir参数设置转换的模型将保存的地址。
6. 使用中间值测试
python tools/export_model.py -c configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml -o Global.pretrained_model=./output/rec_ppocr_v3_distillation/iter_epoch_3 Global.save_inference_dir=./output/iter_epoch_3/
由于训练中间值都保存着,可以选中间值测试一下,执行效果和速度
九、模型转为nb格式
待补充
总结
作为学习的记录,仅供参考