ELK 是目前最流行的集中式日志解决方案,提供了对日志收集、存储、展示等一站式的解决方案。
ELK 分别指 Elasticsearch、Logstash、Kibana。
- Elasticsearch:分布式数据搜索引擎,基于 Apache Lucene 实现,可集群,提供数据的集中式存储,分析,以及强大的数据搜索和聚合功能。
- Logstash:数据收集引擎,相较于Filebeat 比较重量级,但它集成了大量的插件,支持丰富的数据源收集,对收集的数据可以过滤,分析,格式化日志格式。
- Kibana:数据的可视化平台,通过该 web 平台可以实时查看 Elasticsearch 中的相关数据,并提供了丰富的图表统计功能。
- Filebeat:Filebeat 是一款轻量级,占用服务资源非常少的数据收集引擎,它是 ELK 家族的新成员,可以代替 Logstash 作为在应用服务器端的日志收集引擎,支持将收集到的数据输出到 Kafka,Redis 等队列。
一、Elasticsearch
1.1 安装配置
1.1.1 拉取镜像
[root@localhost software]# docker pull elasticsearch:7.17.7
1.1.2 配置文件
第一步:在 Linux 上创建三个数据挂载目录。
第二步:在 conf 目录下创建 elasticsearch.yml 文件,并修改权限为777。
[root@localhost elasticsearch]# cd conf/
[root@localhost conf]# touch elasticsearch.yml
[root@localhost conf]# chmod 777 elasticsearch.yml
[root@localhost conf]# ll
总用量 0
-rwxrwxrwx. 1 root root 0 12月 5 11:03 elasticsearch.yml
配置内容如下:

http:
host: 0.0.0.0
cors:
enabled: true
allow-origin: "*"
xpack:
security:
enabled: false
1.1.3 修改 Linux 的 vm.max_map_count
直接启动后会报下面的异常
max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
表示系统虚拟内存默认最大映射数为65530,无法满足ES系统要求,需要调整为262144以上。
修改方法如下:
查看 sysctl -a|grep vm.max_map_count
修改 sysctl -w vm.max_map_count=262144
1.2 创建运行
docker run -itd \
--name es \
--privileged \
--network docker_net \
--ip 172.18.12.80 \
-p 9200:9200 \
-p 9300:9300 \
-e "discovery.type=single-node" \
-e ES_JAVA_OPTS="-Xms4g -Xmx4g" \
-v /usr/local/software/elk/elasticsearch/conf/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \
-v /usr/local/software/elk/elasticsearch/data:/usr/share/elasticsearch/data \
-v /usr/local/software/elk/elasticsearch/plugins:/usr/share/elasticsearch/plugins \
elasticsearch:7.17.7
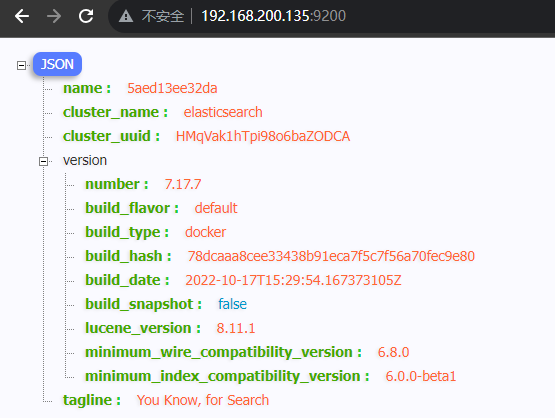
容器创建并运行成功后,我们在浏览器里面访问 虚拟机地址:9200,出现内容表示运行成功。
1.3 ES 的分词器
1.3.1 下载并上传分词器到 Linux 中
下载链接:https://github.com/medcl/elasticsearch-analysis-ik/releases
注意:需下载和 es 一致的版本,避免出错。
上传到 /usr/local/software/elk/plugins/目录下。
1.3.2 拷贝分词器插件到容器 ik 文件夹
[root@localhost plugins]# docker cp elasticsearch-analysis-ik-7.17.7.zip es:/usr/share/elasticsearch/plugins/ik
1.3.3 解压分词器
进入容器 ik 文件夹下面(没有ik文件夹就手动创建),解压插件。
解压:
unzip elasticsearch-analysis-ik-7.17.7.zip
解压完将压缩包删除,并记得重启容器。
二、Kibana
2.1 安装
安装 Kibana 前需保证 ES 已经运行成功。
2.1.1 拉取镜像
docker pull kibana:7.17.7
注意版本尽量保持一致。
2.1.2 创建并运行容器
docker run -it \
--name kibana \
--privileged \
--network docker_net \
--ip 172.18.12.81 \
-e "ELASTICSEARCH_HOSTS=http://192.168.200.135:9200" \
-p 5601:5601 \
-d kibana:7.17.7
2.1.3 测试
浏览器打开 http://虚拟机地址:5601/ 成功进入即表示运行成功。
2.2 简单使用
- 打开
Dev Tools
- 执行查询,可看到出现右面的数据
2.3 测试分词器
2.3.1 标准分词器
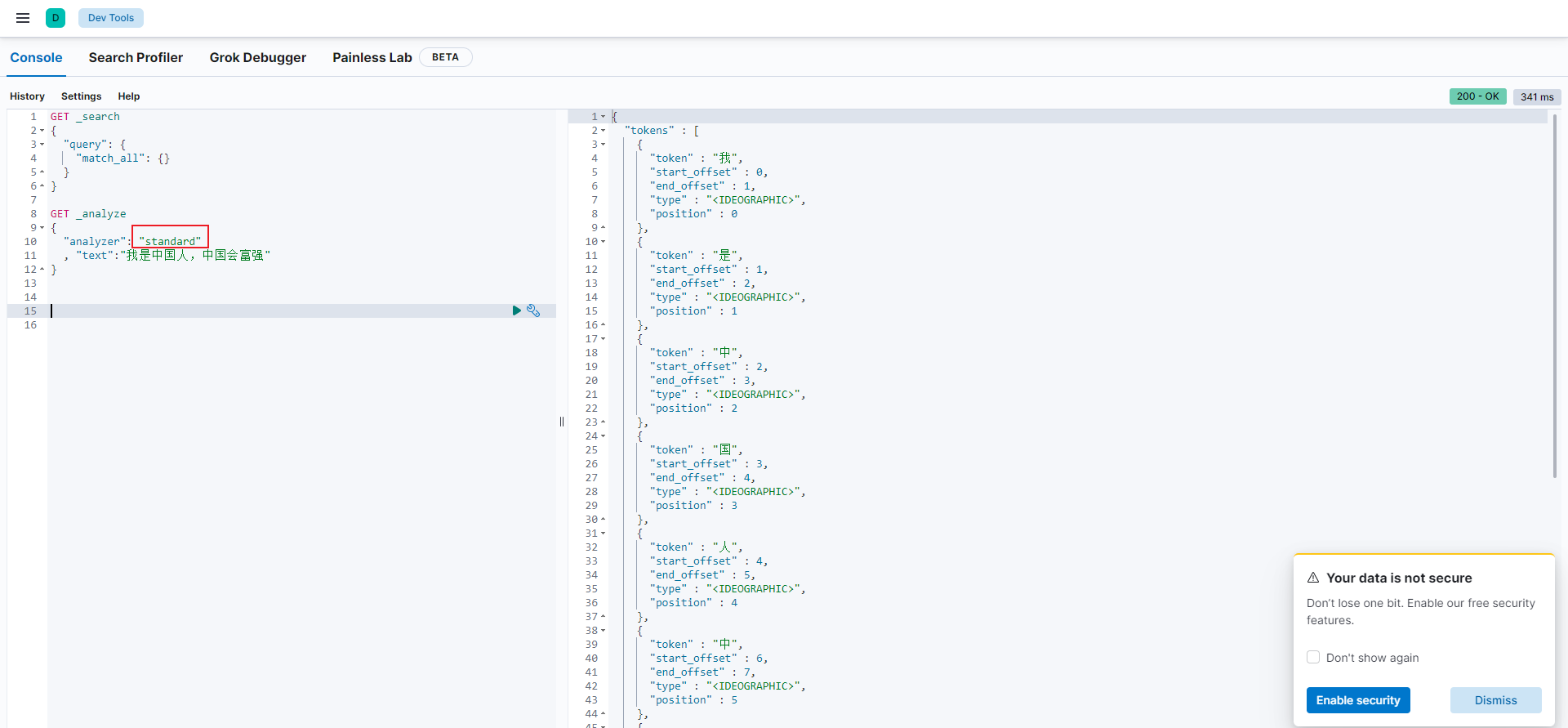
如上图所示,标准分词器对中文不太友好。
2.3.2 ES 分词器
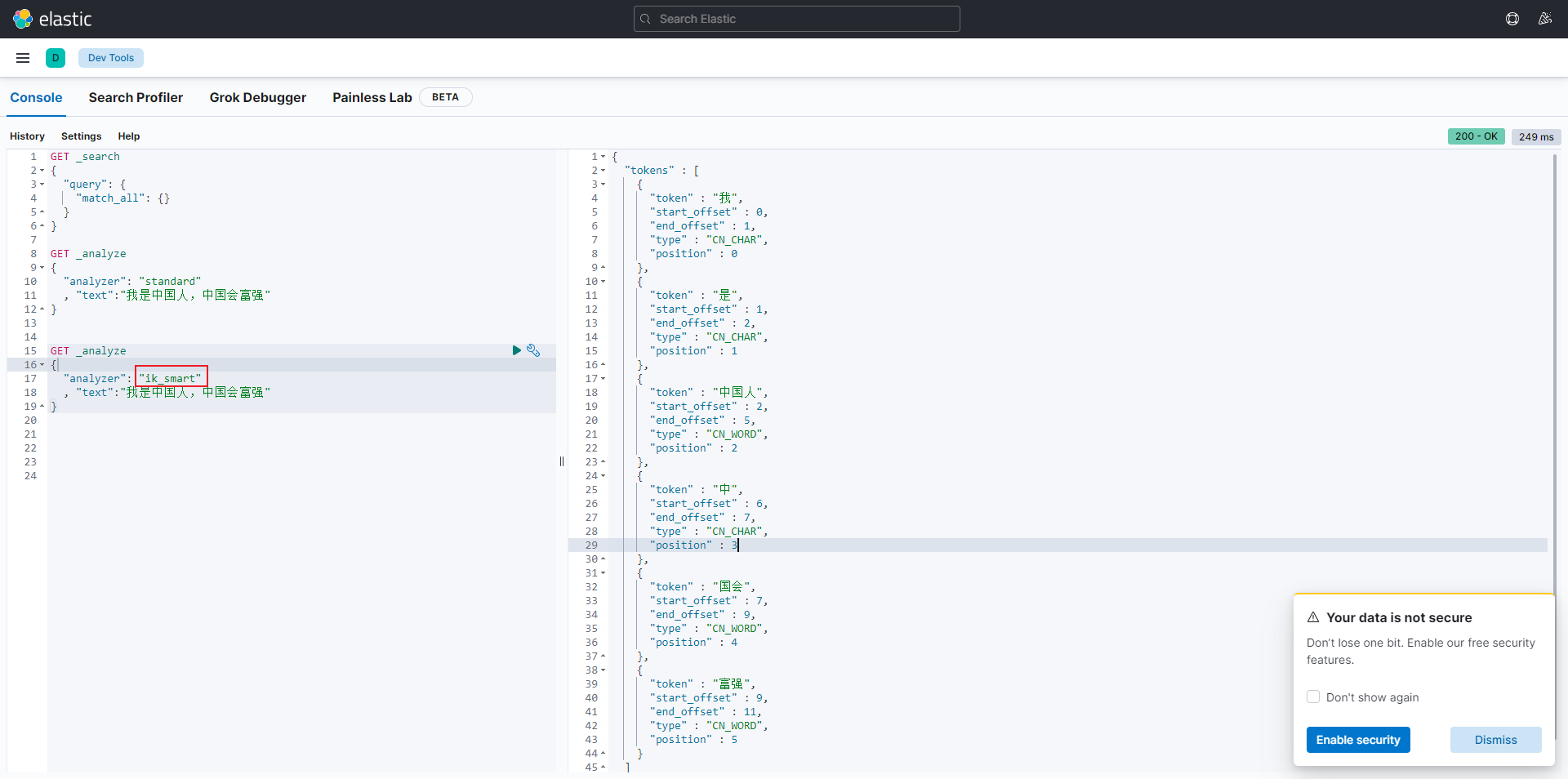
如上图所示,es 分词器对中文分词好一点,但是还是不够灵活。所以我们可以自定义一下 es 的分词器词典。
2.3.3 自定义 es 分词器词典
- 进入 es 容器的 ik/config 目录
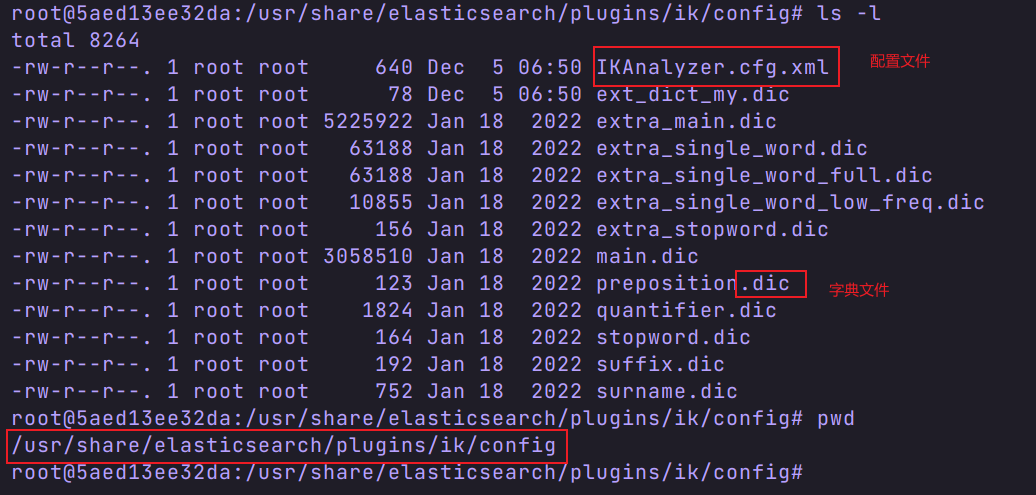
- 查看配置文件
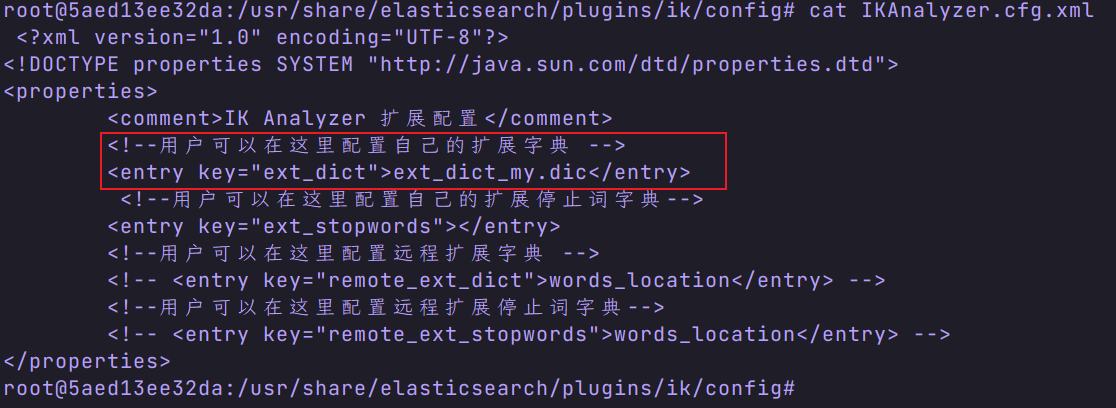
注意:ext_dict_my.dic 是我自定义的词典文件,默认没有。 - 编写自己的配置文件
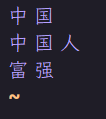
- 重启容器,并测试 。
三、Logstash
3.1 安装
3.1.1 拉取 logstash
[root@localhost ~]# docker pull logstash:7.17.7
3.1.2 创建容器
docker run -it \
--name logstash \
--privileged \
-p 5044:5044 \
-p 9600:9600 \
--network docker_net \
--ip 172.18.12.82 \
-v /etc/localtime:/etc/localtime \
-d logstash:7.17.7
3.2 容器配置
有三个配置文件,分别是
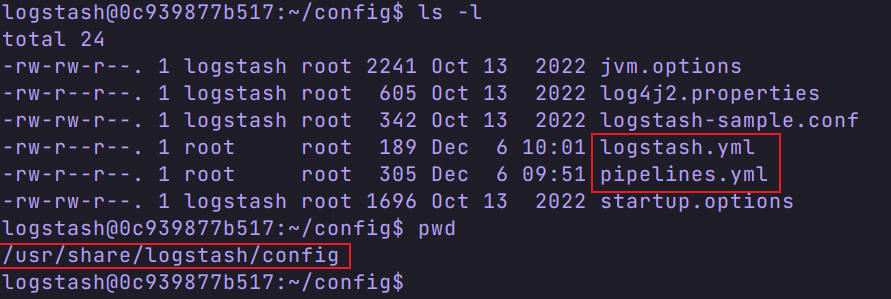
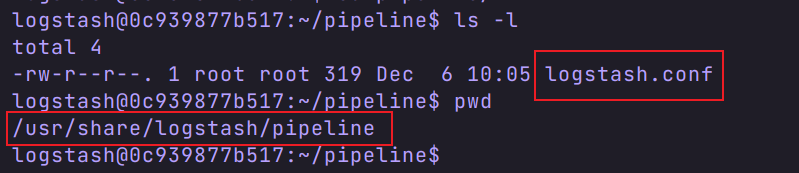
我们在宿主机创建一个 logstash 文件夹( /usr/local/software/elk/logstash),将三个配置文件复制到这个目录下,方便编辑。
logstash.yml
path.logs: /usr/share/logstash/logs
config.test_and_exit: false
config.reload.automatic: false
http.host: "0.0.0.0"
xpack.monitoring.elasticsearch.hosts: [ "http://192.168.200.135:9200" ]
piplelines.xml
- pipeline.id: main
path.config: "/usr/share/logstash/pipeline/logstash.conf"
logstash.conf
input {
tcp {
mode => "server"
host => "0.0.0.0"
port => 5044
codec => json_lines
}
}
filter{
}
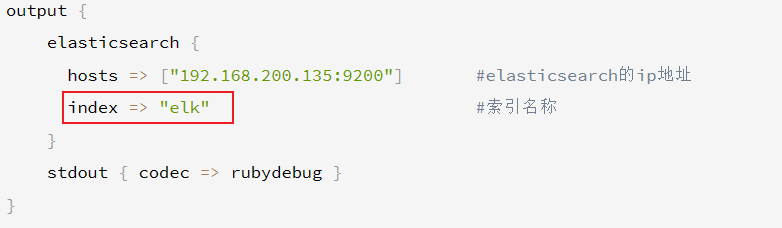
output {
elasticsearch {
hosts => ["192.168.200.135:9200"] #elasticsearch的ip地址
index => "elk" #索引名称
}
stdout { codec => rubydebug }
}
修改完成后,将配置文件拷贝到容器相应位置,并重启容器。
3.3 释放端口
firewall-cmd --add-port=9600/tcp --permanent
firewall-cmd --add-port=5044/tcp --permanent
firewall-cmd --reload
四、springboot 中使用 logstash
4.1 引入框架
<dependency>
<groupId>net.logstash.logback</groupId>
<artifactId>logstash-logback-encoder</artifactId>
<version>7.3</version>
</dependency>
4.2 创建 logback-spring.xml
<?xml version="1.0" encoding="UTF-8"?>
<!-- 日志级别从低到高分为TRACE < DEBUG < INFO < WARN < ERROR < FATAL,如果设置为WARN,则低于WARN的信息都不会输出 -->
<!-- scan:当此属性设置为true时,配置文档如果发生改变,将会被重新加载,默认值为true -->
<!-- scanPeriod:设置监测配置文档是否有修改的时间间隔,如果没有给出时间单位,默认单位是毫秒。
当scan为true时,此属性生效。默认的时间间隔为1分钟。 -->
<!-- debug:当此属性设置为true时,将打印出logback内部日志信息,实时查看logback运行状态。默认值为false。 -->
<configuration scan="true" scanPeriod="10 seconds">
<!--1. 输出到控制台-->
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<!--此日志appender是为开发使用,只配置最低级别,控制台输出的日志级别是大于或等于此级别的日志信息-->
<filter class="ch.qos.logback.classic.filter.ThresholdFilter">
<level>DEBUG</level>
</filter>
<encoder>
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} -%5level ---[%15.15thread] %-40.40logger{39} : %msg%n</pattern>
<!-- 设置字符集 -->
<charset>UTF-8</charset>
</encoder>
</appender>
<!-- 2. 输出到文件 -->
<appender name="FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<!--日志文档输出格式-->
<append>true</append>
<encoder>
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} -%5level ---[%15.15thread] %-40.40logger{39} : %msg%n</pattern>
<charset>UTF-8</charset> <!-- 此处设置字符集 -->
</encoder>
</appender>
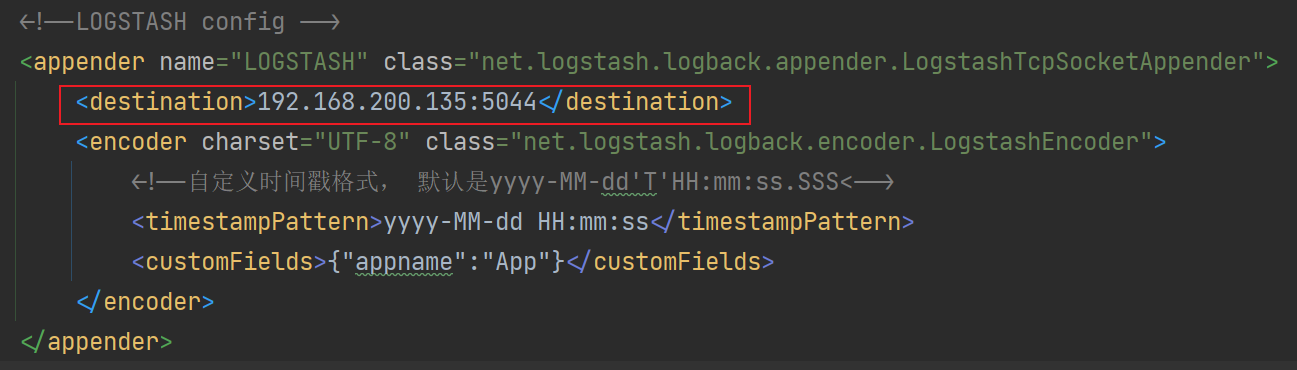
<!--3. LOGSTASH config -->
<appender name="LOGSTASH" class="net.logstash.logback.appender.LogstashTcpSocketAppender">
<destination>192.168.200.135:5044</destination>
<encoder charset="UTF-8" class="net.logstash.logback.encoder.LogstashEncoder">
<!--自定义时间戳格式, 默认是yyyy-MM-dd'T'HH:mm:ss.SSS<-->
<timestampPattern>yyyy-MM-dd HH:mm:ss</timestampPattern>
<customFields>{"appname":"QueryApp"}</customFields>
</encoder>
</appender>
<root level="DEBUG">
<appender-ref ref="CONSOLE"/>
<appender-ref ref="FILE"/>
<appender-ref ref="LOGSTASH"/>
</root>
</configuration>
注意这个地址,需配置 es 的地址。
文件存放位置
4.3 测试代码
@Slf4j
@RestController
@RequestMapping("/api/query")
public class QueryController {
@Autowired
private IBookDocService ibs;
@GetMapping("/helloLog")
public HttpResp helloLog(){
List<BookDoc> all = ibs.findAll();
log.debug("从es中查询到的数据:{}",all);
log.debug("我是来测试logstash是否工作的");
return HttpResp.success(all.subList(0,10));
}
}
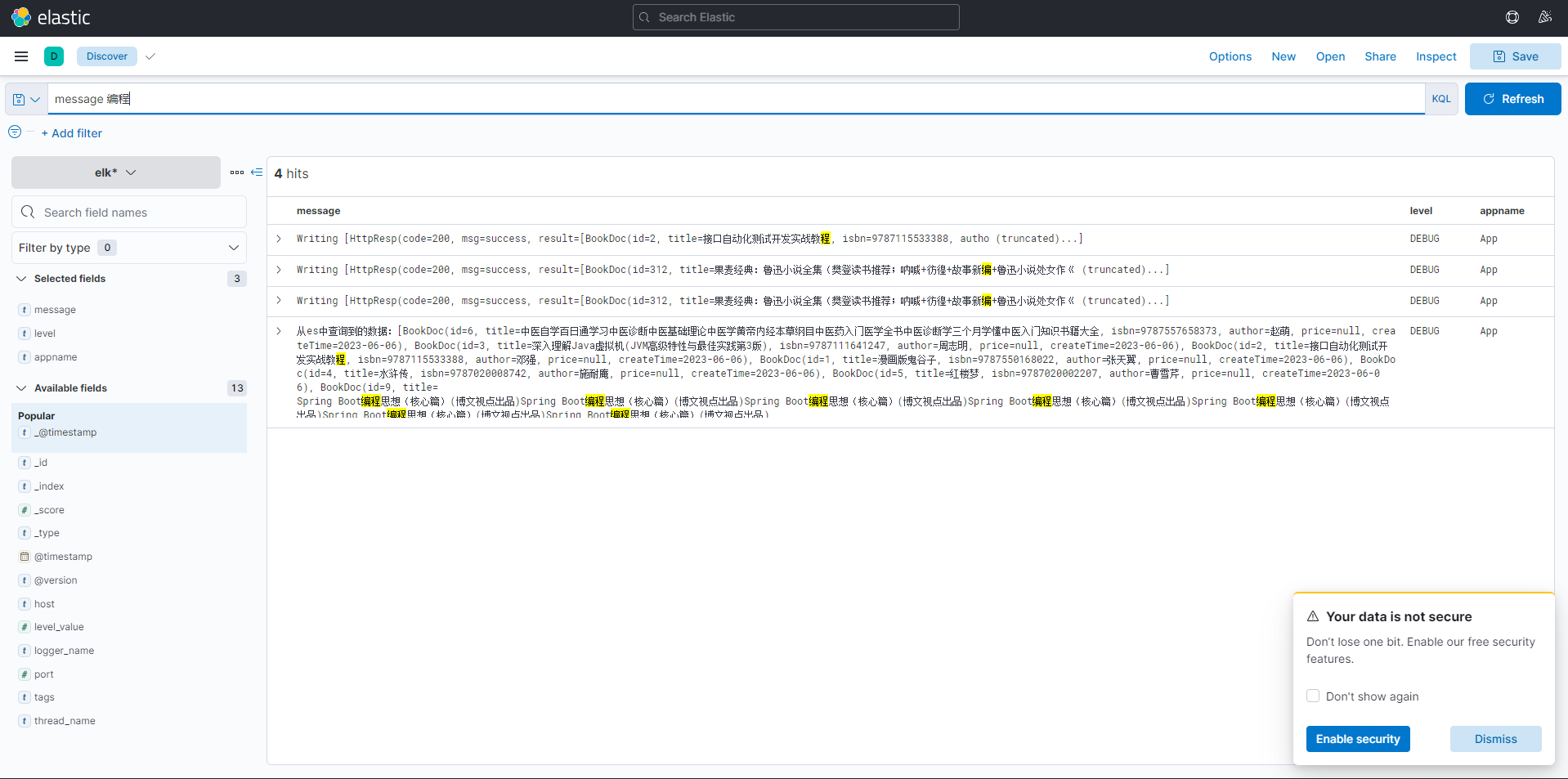
4.4 Kibana 中查看
4.4.1 创建一个索引
put elk
elk 名称是之前 logstash.conf 文件中配置的。
4.4.2 创建索引模式
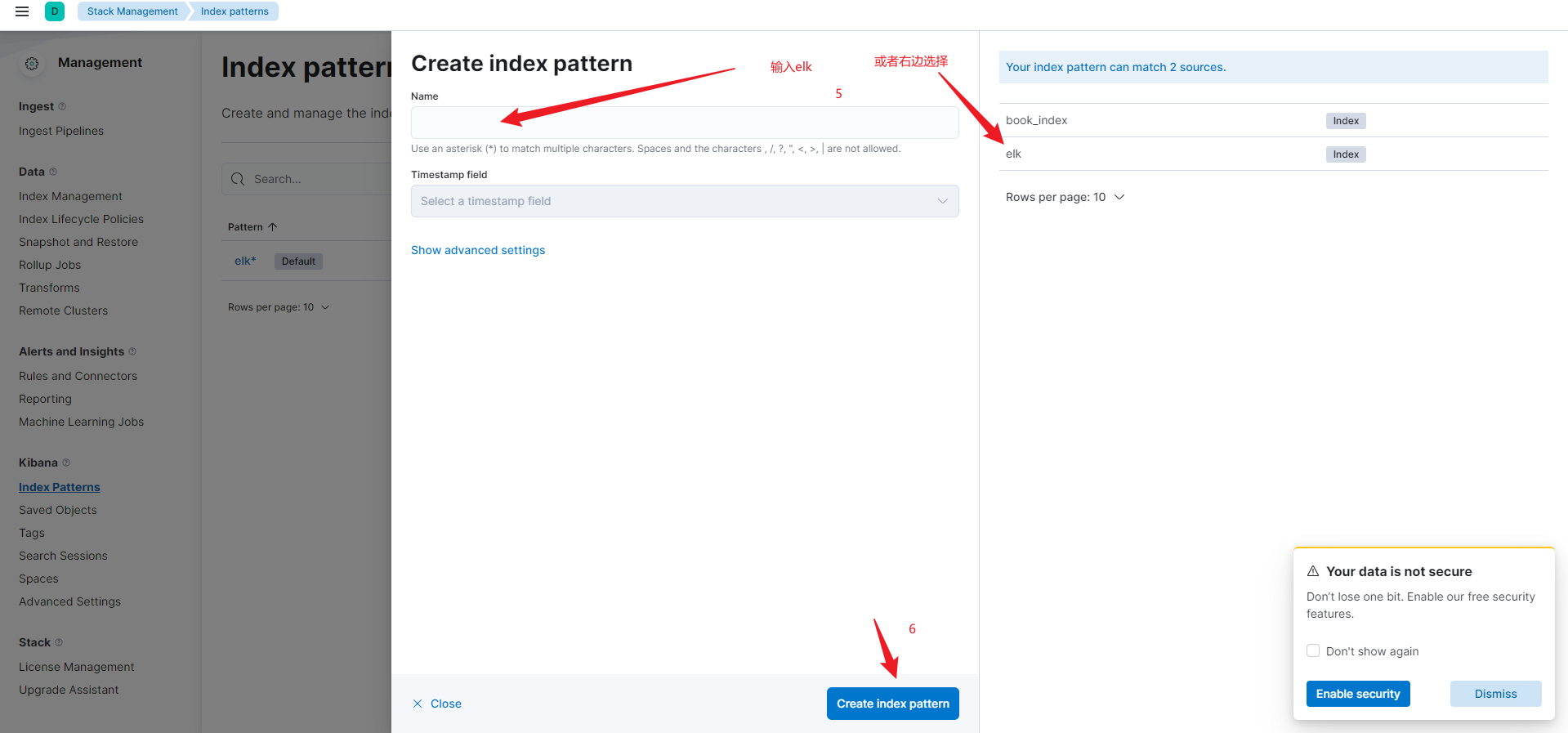
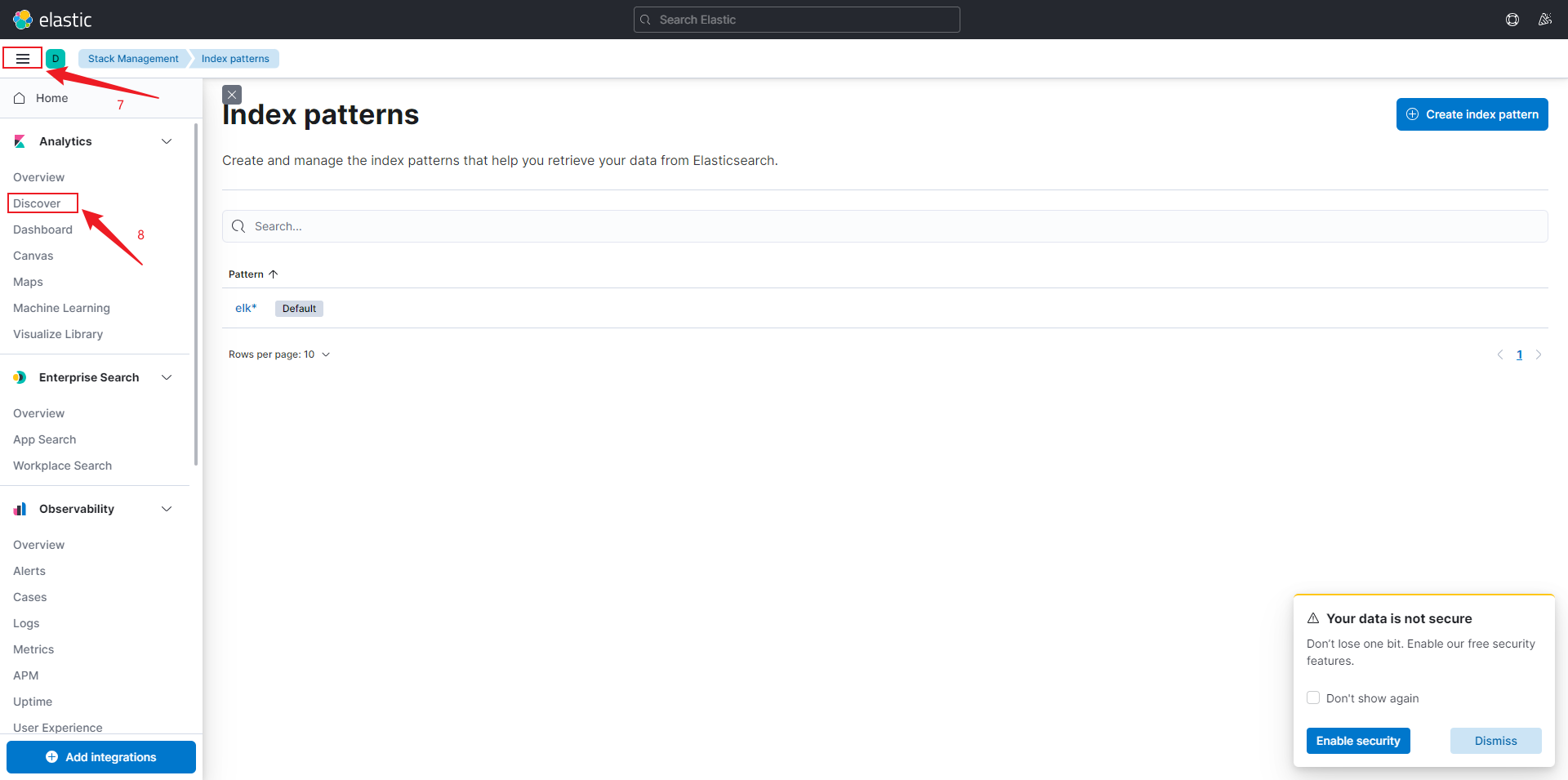
执行操作,如搜索。

![[论文阅读]DETR](https://img-blog.csdnimg.cn/direct/fefcccbf4a1541128ea97dbe17b29a1d.png)