1.目前针对中文的bert预训练模型有三家:
谷歌发布的chinese_L-12_H-768_A-12
还有哈工大的chinese-bert-wwm / chinese-bert-wwm-ext
以及HuggingFace上的bert-base-chinese(由清华大学基于谷歌的BERT在中文数据集上训练开发的模型,上传在HuggingFace) 我好像记得谷歌也开源过bert-base-chinese?
谷歌的是tf写的,需要借助转换脚本将其转化为pytorch的,哈工大的既有tf版本又有pytorch版本。hugging face 包罗万象,估计tf和pytorch也会都有。
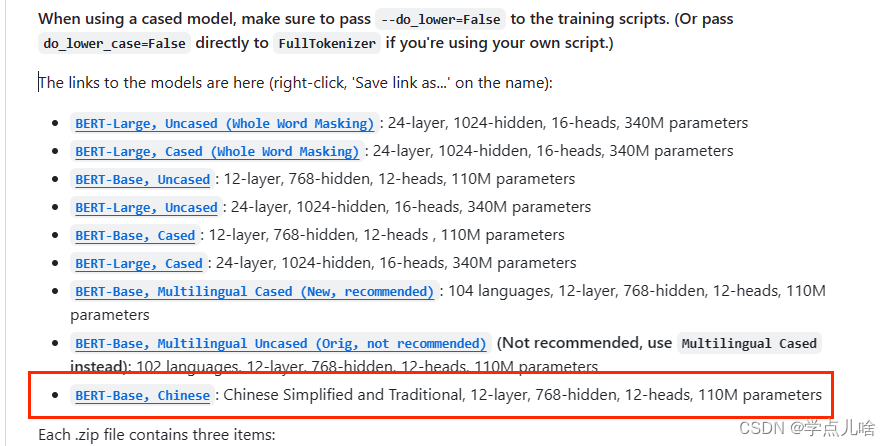
1. 谷歌发布的 chinese_L-12_H-768_A-12
地址:https://github.com/google-research/bert 找到中文模型并下载
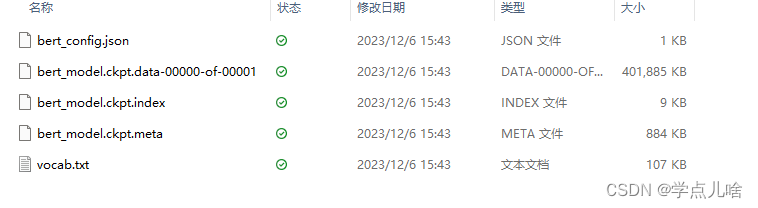
其中包含5个文件,这是用tensorflow1.11训练得到的。
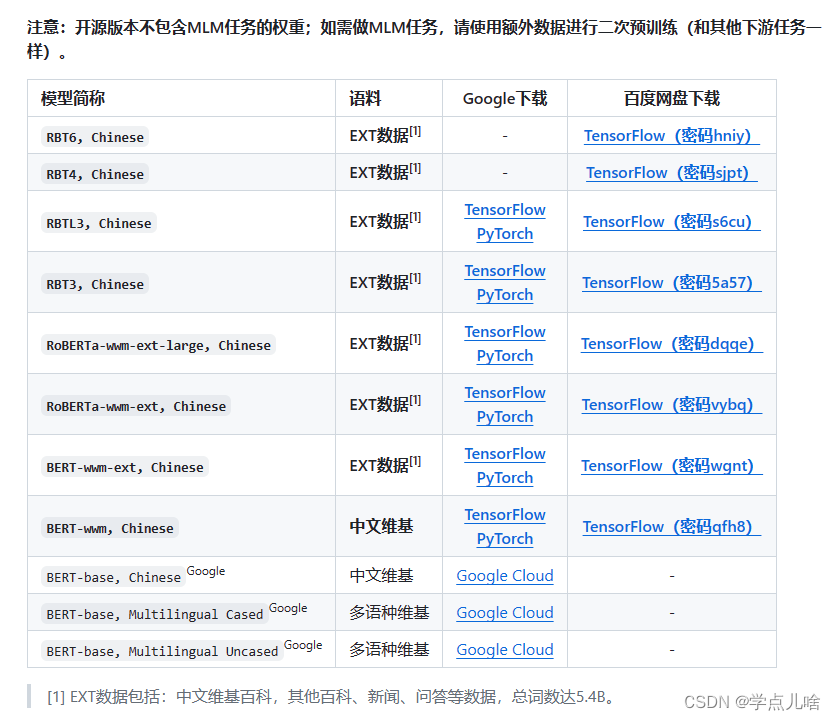
2. 哈工大的 chinese-bert-wwm / chinese-bert-wwm-ext
wwm为whole world mask的缩写,译为全词遮蔽,是针对中文词语针对熊训练的一种遮蔽模型。
这个是是哈工大讯飞联合实验室发布的中文预训练bert模型,包含tf和pytorch两种版本。wwm指的全词匹配策略,这是和谷歌bert最大的区别。ext指的是用了更大的数据集,RoBERT是bert的改良版本,并在不断更新。
疑问:这里为什么只有Google下载提供了pytorch版本? 既然有了pytorch版本为什么他们官网还提供了hugging face 将tf权重转化为torch权重的脚本链接?
地址:https://github.com/ymcui/Chinese-BERT-wwm
3. HuggingFace的 bert-base-chinese
这里边包含了许多模型,有bert-base-chinese,也有哈工大的chinese-bert-wwm-ext
哈工大的chinese-bert-wwm-ext :
2. 将谷歌发布的tf版本的预训练全权重转化为pytorch版本的
转换脚本链接1为:https://github.com/YaoXinZhi/Convert-Bert-TF-checkpoint-to-Pytorch,对应的博客讲解为https://www.jianshu.com/p/2df27f66eec9
要运行转换脚本1,需要安装TensorFlow和PyTorch,转换命令:
# 依赖自行下载
# $checkpoint_path 为TF-checkpoint路径
# $save_file 为pytorch-checkpoint 保存文件
python3 convert_bert_tf_checkpoint_to_pytorch.py --tf_checkpoint_path $checkpoint_path/model.ckpt --bert_config_file $checkpoint_path/bert_config.json --pytorch_dump_path $save_file
也可以参考博客https://blog.csdn.net/sarracode/article/details/109060358
转换脚本2为hugging face的 :https://huggingface.co/docs/transformers/v4.28.1/en/converting_tensorflow_models
当然也可以直接下载现成的pytorch权重:
哈工大的:https://github.com/ymcui/Chinese-BERT-wwm
hugging face的:https://huggingface.co/bert-base-chinese/tree/main
以及 https://huggingface.co/hfl/chinese-bert-wwm-ext/tree/main
但是谷歌、哈工大、清华这三家发布的模型权重是否通用,能否用一套代码调用,以及在hugging face和哈工大两个地方发布的chinese-bert-wwm-ext模型是否是一模一样的,还有待验证。
我测试的使用hugging face 的bert-base-chinese的权重来代替谷歌chinese_L-12_H-768_A-12的权重是可行的,就是不知道效果会不会变差。起码在一定程度上是通用的吧,这样就省去了使用脚本转换的麻烦。
参考博客
将TF-checkpoint 文件转换为 pytorch-checkpoint 踩坑 https://www.jianshu.com/p/2df27f66eec9
bert中文使用总结 https://blog.csdn.net/sarracode/article/details/109060358