在深度学习中,MONAI(Medical Open Network for AI)是一个专注于医学图像分析的开源框架。它提供了一系列用于医学图像处理和深度学习的工具和函数,其中包括了Dataset函数。
Dataset函数是MONAI框架中的一个重要组件,它用于加载和管理医学图像数据集,并提供了数据增强、预处理和批处理等功能。
- 数据加载:
Dataset函数用于加载医学图像数据集,可以是常见的格式如NIfTI、DICOM等。 - 数据预处理:
Dataset函数可以对加载的医学图像数据进行预处理操作,如裁剪、缩放、平衡化等,以适应模型的需求。 - 数据增强:
Dataset函数可以实现数据增强操作,如旋转、平移、翻转、弹性变形等,以扩充数据集并提高模型的鲁棒性。 - 批处理:
Dataset函数支持批处理操作,可以将数据划分为固定大小的批次,并提供了多线程加载数据的功能,以加快模型训练过程。
这篇文章建议和之前的文章一起食用:
MONAI中,一定要学会的三种Dataset使用方法
文章目录
- 常规 Dataset
- CacheDataset
- PersistentDataset
- DecathlonDataset
- MedNISTDataset
- 不同Dataset之间的速度PK
常规 Dataset
一个典型的用法案例:
我们创建了一个Dataset对象,并传入数据集路径和预处理操作。最后,通过索引访问数据集中的样本。
- 导入相关库和模块:
import monai.data as data
from monai.transforms import Compose, AddChannel, ScaleIntensity
- 定义数据集路径和预处理操作:
data_dir = 'path/to/dataset'
transforms = Compose([AddChannel(), ScaleIntensity()])
# 其中`Compose`函数用于组合多个预处理操作,`AddChannel`函数用于在医学图像数据中添加通道维度,`ScaleIntensity`函数用于对图像数据进行强度归一化。
- 创建
Dataset对象并加载数据:
dataset = data.Dataset(data_dir, transforms)
- 使用索引访问数据集中的样本:
sample = dataset[index]
在MONAI中,除了通用的Dataset函数外,还提供了一些专门用于医学图像的Dataset,下面列举几个常用Dataset
CacheDataset
提供了一种机制,可以预加载所有原始数据。然后并将non-random transforms(非随机变换)应用到数据并缓存起来,就不需要每个epoch都做这些transform。这样就大大提升了数据加载速度。而random transforms(随机变换)则需要实时做,因为会随着epoch的变化,transform的结果也会跟着变化,没办法提前做了缓存起来。
例如,如果变换是由以下操作组成的 Compose:
transforms = Compose([
LoadImaged(),
EnsureChannelFirstd(),
Spacingd(),
Orientationd(),
ScaleIntensityRanged(),
RandCropByPosNegLabeld(),
ToTensord()
])
当 transforms 在多个epoch的训练流程中使用时,在第一个训练epoch之前,所有非随机变换 LoadImaged、EnsureChannelFirstd、Spacingd、Orientationd、ScaleIntensityRanged 都可以被缓存。在训练期间,数据集将加载缓存的结果并运行 RandCropByPosNegLabeld 和 ToTensord,因为 RandCropByPosNegLabeld 是一个随机化变换,其结果不会被缓存。
参数解析
train_transforms = transforms.Compose(省略)
train_ds = CacheDataset(data=train_dicts, transform=train_transforms, cache_rate=1.0, num_workers=4, progress=True)
- cache_rate:总缓存数据的百分比(如果不能全部缓存,可以设置百分比),默认为 1.0(全部缓存)。将取 (cache_num,data_length x cache_rate,data_length) 中的最小值。
- cache_num:要缓存的项目数量,默认是 sys.maxsize。将取 (cache_num, data_length x cache_rate, data_length) 的最小值。
- num_workers:如果在初始化时计算缓存,这是工作线程的数量。如果 num_workers 是 None,则使用 os.cpu_count() 返回的数字。如果指定的值小于 1,则会使用 1。
- progress:是否显示进度条。

适用情况:如果数据量不太大,能全部缓存到内存,则这是最高性能的Dataset。
注意:CacheDataset 在第一个epoch之前,在主进程中执行非随机变换并准备缓存内容,然后 DataLoader 的所有子进程在训练期间将从主进程读取相同的缓存内容。根据缓存数据的大小,准备缓存内容可能需要很长时间。因此,为了在实际训练之前调试或验证程序,用户可以设置 cache_rate=0.0 或 cache_num=0 来临时跳过缓存。代码调试完毕后再改回去。
PersistentDataset
我们知道一般中小型服务器内存大多在512GB及以下,假设想要训练一个大模型,数据量在几万到十几万的3D CT数据,想要全部缓存在内存中是根本不可能的。PersistentDataset就可以用于处理大型数据集,支持高效的数据加载和管理。
PersistentDataset在第一个epoch之前,将non-random transforms(非随机变换)应用到数据并缓存储到磁盘上的持久化表示中。它同样是把数据全部缓存起来,CacheDataset是缓存在内存中,PersistentDataset是缓存在磁盘中(磁盘读写速度肯定没有内存快)
参数解析
train_transforms = transforms.Compose(省略)
train_ds = PersistentDataset(data=train_dicts, transform=train_transforms, cache_dir="./data/cache")
train_loader = DataLoader(train_ds, batch_size=1, num_workers=8, pin_memory=torch.cuda.is_available())
- cache_dir: 这里需要输入缓存的地址
当你只运行到train_loader的时候,缓存地址里是不会有数据的,需要调用它才会对数据进行处理。因此,它不会像CacheDataset把数据都加载进去,所以这一步运行的贼快。
如果想要调试它是否会加载数据:
data = iter(train_loader).next()
print(data["image"].shape)
这是你就会发现缓存地址了存了数据
所以使用PersistentDataset后,哪怕训练结束,仍然会占用磁盘空间去存储这些中间结果。而CacheDataset会在训练结束就释放内存。
适用情况:适用于大规模数据集,搞大模型就用这个!!
DecathlonDataset
医学分割十项全能挑战数据集(DecathlonDataset)是一个用于医学图像分割任务的数据集(very hot!)。该数据集包含来自不同医学影像模态(如MRI、CT等)的图像数据以及标签。
MONAI的DecathlonDataset会自动下载该数据集,并且分好了训练、验证和测试集。它还基于monai.data.CacheDataset类来加速训练过程。
train_ds = DecathlonDataset(
root_dir=root_dir,
task="Task01_BrainTumour",
section="training",
cache_rate=1.0, # you may need a few Gb of RAM... Set to 0 otherwise
num_workers=4,
download=True, # Set download to True if the dataset hasnt been downloaded yet
seed=0,
transform=train_transforms,
)
train_loader = DataLoader(
train_ds, batch_size=32, shuffle=True, num_workers=4, drop_last=True, persistent_workers=True
)
MedNISTDataset
受 Medical Segmentation Decathlon(医学分割十项全能)的启发,上海交通大学的研究人员创建了医疗图像数据集 MedMNIST,共包含 10 个预处理开放医疗图像数据集(其数据来自多个不同的数据源,并经过预处理)。和 MNIST 数据集一样,MedMNIST 数据集在轻量级 28 × 28 图像上执行分类任务,所含任务覆盖主要的医疗图像模态和多样化的数据规模,作为 AutoML 在医疗图像分类领域的基准。
代码如下:
train_ds = MedNISTDataset(root_dir=root_dir, transform=transform, section="training", download=True)
# the dataset can work seamlessly with the pytorch native dataset loader,
# but using monai.data.DataLoader has additional benefits of mutli-process
# random seeds handling, and the customized collate functions
train_loader = DataLoader(train_ds, batch_size=300, shuffle=True, num_workers=10)
DecathlonDataset和MedNISTDataset主要是用于加载特定的公开数据集,具体的使用方法详见之前的教程 使用MONAI轻松加载医学公开数据集
不同Dataset之间的速度PK
所以到底哪个Dataset快?MONAI官方对PersistentDataset, CacheDataset, LMDBDataset, and simple Dataset 进行了速度PK,代码详见monai dataset 性能比较。使用unet对十项全能数据集Task09_Spleen进行分割,相同的实验设置下,仅改变Datasets,结果如下
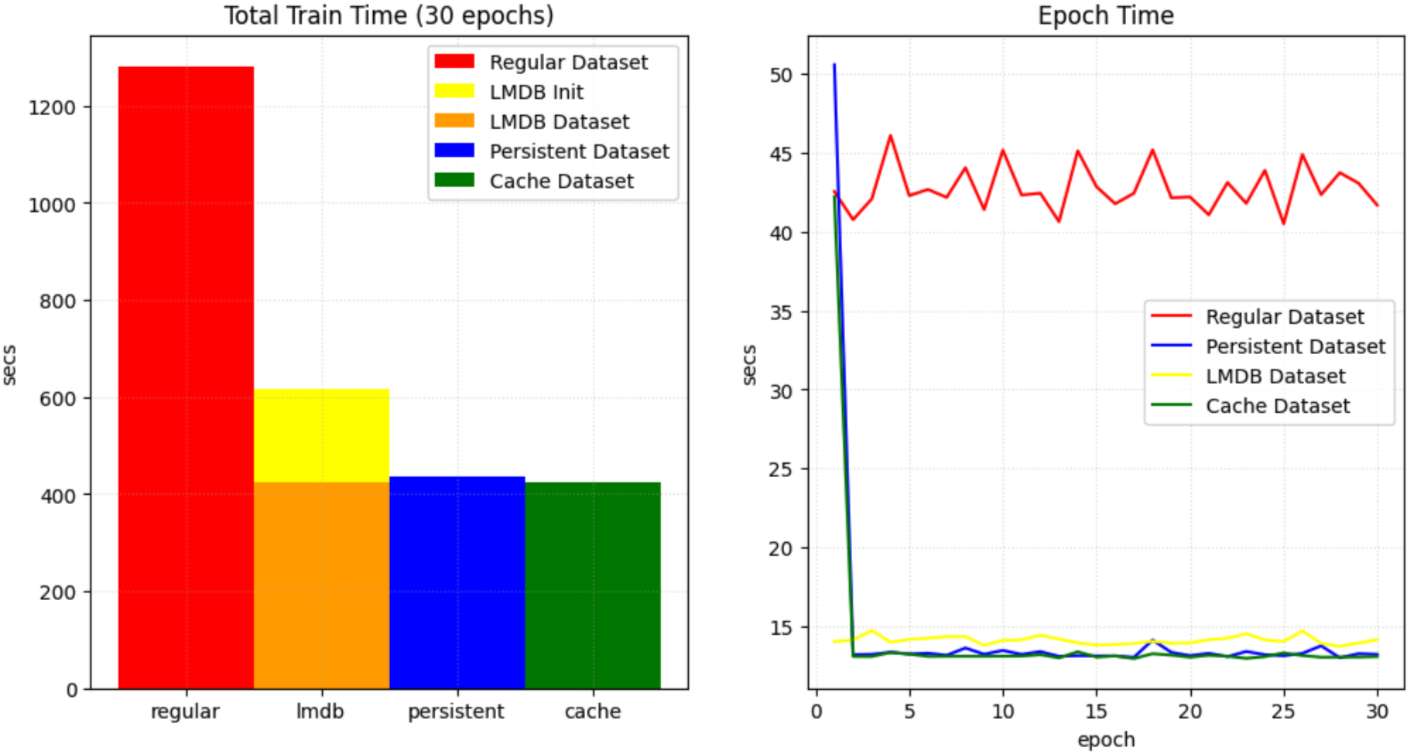
左边是一共训练30个epoch,不同Dataset用的总时间对比,右边是每个epoch花费的时间曲线。
结论:常规Dataset花费的时间最多,PersistentDataset和 CacheDataset效率相差不大。数据量不大,选择CacheDataset。数据量大选择PersistentDataset。当然还有好多其他的Dataset,以后遇到再做分享。
文章持续更新,可以关注微公【医学图像人工智能实战营】获取最新动态,一个关注于医学图像处理领域前沿科技的公众号。坚持以实践为主,手把手带你做项目,打比赛,写论文。凡原创文章皆提供理论讲解,实验代码,实验数据。只有实践才能成长的更快,关注我们,一起学习进步~
我是Tina, 我们下篇博客见~
白天工作晚上写文,呕心沥血
觉得写的不错的话最后,求点赞,评论,收藏。或者一键三连