文章目录
- 1 满秩分解(Full-Rank Factorization)
- 2 三角分解(Triangular Factorization)
- 3 正交三角分解(QR Factorization)
- 4 奇异值分解(SVD)
1 满秩分解(Full-Rank Factorization)
-
满秩分解定理
设 m × n m\times n m×n矩阵 A A A的秩为 r > 0 r>0 r>0,则存在 m × r m\times r m×r矩阵 B B B(列满秩矩阵)和 r × n r\times n r×n矩阵 C C C(行满秩矩阵)使得
A = B C A=BC A=BC
并且 r a n k ( B ) = r a n k ( C ) = r rank(B)=rank(C)=r rank(B)=rank(C)=r满秩分解不唯一
定理:设 A A A为 m × n m\times n m×n矩阵,且 r a n k ( A ) = r rank(A)=r rank(A)=r,存在 m m m阶可逆矩阵 P P P和 n n n阶可逆矩阵 Q Q Q,使得 A = P [ I r 0 0 0 ] Q A=P\begin{bmatrix}I_r & 0 \\ 0 & 0\end{bmatrix}Q A=P[Ir000]Q。
证明满秩分解定理:
∵ [ I r 0 0 0 ] = [ I r 0 ] [ I r 0 ] \because \begin{bmatrix}I_r & 0 \\ 0 & 0\end{bmatrix}=\begin{bmatrix}I_r \\ 0\end{bmatrix}\begin{bmatrix}I_r & 0\end{bmatrix} ∵[Ir000]=[Ir0][Ir0]
∴ A = P [ I r 0 ] [ I r 0 ] Q \therefore A=P\begin{bmatrix}I_r \\ 0\end{bmatrix}\begin{bmatrix}I_r & 0\end{bmatrix}Q ∴A=P[Ir0][Ir0]Q
则令 P [ I r 0 ] = B P\begin{bmatrix}I_r \\ 0\end{bmatrix}=B P[Ir0]=B, [ I r 0 ] Q = C \begin{bmatrix}I_r & 0\end{bmatrix}Q=C [Ir0]Q=C,可得到 A = B C A=BC A=BC
∵ \because ∵ P , C P,C P,C是可逆矩阵, B B B的 r r r个列是 P P P的前 r r r列; C C C的 r r r个行是 Q Q Q的前 r r r行
∴ \therefore ∴ r a n k ( B ) = r a n k ( C ) = r rank(B)=rank(C)=r rank(B)=rank(C)=r
-
满秩分解步骤
- 设 A A A为 m × n m\times n m×n矩阵,首先求 r a n k ( A ) rank(A) rank(A)
- 取 A A A的 j 1 , j 2 , . . . j r j_1,j_2,...j_r j1,j2,...jr列构成 B m × r B_{m\times r} Bm×r
- 取
A
A
A的
Hermite标准型(即行最简行矩阵) H H H的前 r r r行构成矩阵 C r × n C_{r\times n} Cr×n - 则 A = B C A=BC A=BC就是矩阵 A A A的一个满秩分解
-
Python求解满秩分解import numpy as np from sympy import Matrix ''' Full-Rank Factorization @params: A Matrix @return: F, G Matrix ''' def full_rank(A): r = A.rank() A_arr1 = np.array(A.tolist()) # 求解A的最简行阶梯矩阵,要转换成list,再转换成array A_rref = np.array(A.rref()[0].tolist()) k = [] # 存储被选中的列向量的下标 # 遍历A_rref的行 for i in range(A_rref.shape[0]): # 遍历A_rref的列 for j in range(A_rref.shape[1]): # 遇到1就说明找到了A矩阵的列向量的下标 # 这些下标的列向量组成F矩阵,然后再找下一行 if A_rref[i][j] == 1: k.append(j) break # 通过选中的列下标,构建F矩阵 B = Matrix(A_arr1[:,k]) # G就是取行最简行矩阵A的前r行构成的矩阵 C = Matrix(A_rref[:r]) return B, C if __name__ == "__main__": # 表示矩阵A A = np.array([[1, 1, 0], [0, 1, 1], [-1, 0, 0], [1, 1, 1]]) A = Matrix(A) B, C = full_rank(A) print("B:", B) print("C:", C)
2 三角分解(Triangular Factorization)
-
L U LU LU分解定义
如果有一个矩阵 A A A,我们能表示下三角矩阵 L L L和上三角矩阵 U U U的乘积,称为 A A A的三角分解或 L U LU LU分解。
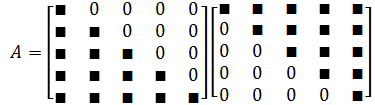
更进一步,我们希望下三角矩阵的对角元素都为 1 1 1
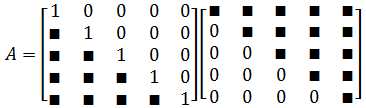
-
L U LU LU分解定理
若 A A A是== n n n阶非奇异矩阵==,则存在唯一的单位下三角矩阵 L L L和上三角矩阵 U U U使得 A = L U A=LU A=LU的充分必要条件是 A A A的所有顺序主子式均非零(这一条件保证了对角线元素非零),即 Δ k ≠ 0 ( k = 1 , . . . , n − 1 ) \Delta_k\neq 0(k=1,...,n-1) Δk=0(k=1,...,n−1)
-
L U LU LU分解步骤
设 A A A为 n × n n\times n n×n矩阵
- 进行初等行变换(注意:不涉及行交换的初等变换),从第 1 1 1行开始,到第 n n n行结束。将第 i i i行第 i i i列以下的元素全部消为 0 0 0
- 这样操作后得到的矩阵即为 U U U
- 构造对角线元素全为 1 1 1的单位下三角矩阵 L L L, L L L的剩余元素通过构建方程组的形式来求解。
-
Python求解 L U LU LU分解 -
L U LU LU分解的实际意义
-
解线性方程组
假设我们有一个线性方程组 A x = b Ax=b Ax=b,其中 A A A是一个非奇异矩阵,而 b b b是一个列向量。通过 L U LU LU分解,我们可以将方程组转化为两个简化的方程组 L y = b Ly=b Ly=b和 U x = y Ux=y Ux=y,其中 L L L是下三角矩阵, U U U是上三角矩阵。这两个方程组分别易于求解。
具体:
首先,通过前代法(forward substitution)解 L y = b Ly=b Ly=b,然后通过回代法(backward substitution)解 U x = y Ux=y Ux=y。这样,我们就得到了方程组的解。
-
-
L D U LDU LDU分解定理
设 A A A是== n n n阶非奇异矩阵==,则存在唯一的单位下三角矩阵 L L L,对角矩阵 D = d i a g ( d 1 , d 2 , . . . , d n ) D=diag(d_1,d_2,...,d_n) D=diag(d1,d2,...,dn)和上三角矩阵 U U U使得 A = L D U A=LDU A=LDU的充分必要条件是 A A A的所有顺序主子式均非零(这一条件保证了对角线元素非零),即 Δ k ≠ 0 ( k = 1 , . . . , n − 1 ) \Delta_k\neq 0(k=1,...,n-1) Δk=0(k=1,...,n−1)并且 d 1 = a 11 , d k = Δ k Δ k + 1 , k = 2 , . . . , n d_1=a_{11},d_k=\frac{\Delta _k}{\Delta_{k+1}},k=2,...,n d1=a11,dk=Δk+1Δk,k=2,...,n
-
L D U LDU LDU分解步骤
设 A A A为 n × n n\times n n×n矩阵
- 先求 L U LU LU分解
- 将 U U U的对角线元素提出来构成对角矩阵 D D D
- U U U中的元素 u i j u_{ij} uij除以 d i d_i di,其中 d i d_i di表示第 i i i个对角元素。这样操作得到变换后的 U U U
-
Python求解 L D U LDU LDU分解import numpy as np from sympy import Matrix import pprint EPSILON = 1e-8 def is_zero(x): return abs(x) < EPSILON def LU(A): # 断言A必须是非奇异方阵A assert A.rows == A.cols, "Matrix A must be a square matrix" assert A.det() != 0, "Matrix A must be a nonsingular matrix" n = A.rows U = A # 构建出U矩阵 # 将U转换成list,再转换成array U = np.array(U.tolist()) # 遍历U的每一行利用高斯消元法 for i in range(n): # 判断U[i][i]是否为0 assert not is_zero(U[i][i]), "主元为0,无法进行LU分解" # 对i+1行到n行进行消元 for j in range(i + 1, n): # 计算消元因子 factor = U[j][i] / U[i][i] # 对第j行进行消元 for k in range(i, n): U[j][k] -= factor * U[i][k] # 消元后的矩阵U则是最终U矩阵 U = Matrix(U) # 根据LU = A,得到L矩阵 L = A * U.inv() return L, U def LDU(A): L, U = LU(A) D = Matrix(np.diag(np.diag(U))) U = D.inv() * U return L, D, U if __name__ == '__main__': A = np.array([[2, 3, 4], [1, 1, 9], [1, 2, -6]]) A = Matrix(A) ''' # test LU分解 L, U = LU(A) pprint.pprint("L:") pprint.pprint(L) pprint.pprint("U:") pprint.pprint(U) ''' # test LDU分解 L, D, U = LDU(A) pprint.pprint("L:") pprint.pprint(L) pprint.pprint("D:") pprint.pprint(D) pprint.pprint("U:") pprint.pprint(U) -
P L U PLU PLU分解
PLU 分解是将矩阵 A A A分解成一个置换矩阵 P P P、单位下三角矩阵 L L L和上三角矩阵 U U U的乘积,即
A = P L U A=PLU A=PLU
之前 L U LU LU分解中限制了行交换,如果不可避免的必须进行行互换,我们就需要进行 P L U PLU PLU分解。实际上只需要把 A = L U A = LU A=LU变成 P − 1 A = P − 1 P L U P^{-1}A = P^{-1}PLU P−1A=P−1PLU就可以了,实际上所有的 A = L U A = LU A=LU都可以写成 P − 1 A = L U P^{-1}A = LU P−1A=LU的形式,由于左乘置换矩阵 P − 1 P^{-1} P−1是在交换行的顺序,所以由 P − 1 A = P − 1 P L U P^{-1}A = P^{-1}PLU P−1A=P−1PLU推得适当的交换 A A A的行的顺序,即可将 A A A 做 L U LU LU 分解。当 A A A没有行互换时, P P P就是单位矩阵。
事实上,所有的方阵都可以写成 P L U PLU PLU 分解的形式,事实上, P L U PLU PLU 分解有很高的数值稳定性,因此实用上是很好用的工具。
有时为了计算上的方便,会同时间换行与列的顺序,此时会将 A A A 分解成
A = P L U Q A=PLUQ A=PLUQ
其中 P P P、 L L L、 U U U 同上, Q Q Q 是一个置换矩阵。
3 正交三角分解(QR Factorization)
-
Q R QR QR分解定理
设 A A A是 m × n m\times n m×n实(复)矩阵, m ≥ n m\ge n m≥n且其 n n n个列向量线性无关,则存在 m m m阶正交(酉)矩阵 Q Q Q和 n 阶 n阶 n阶非奇异实(复)上三角矩阵 R R R使得
A = Q [ R 0 ] A=Q\begin{bmatrix}R \\ 0\end{bmatrix} A=Q[R0] -
Q R QR QR分解步骤
设 A A A为 3 × 3 3\times 3 3×3矩阵,即 A = ( α 1 , α 2 , α 3 ) A=(\alpha_1, \alpha_2,\alpha_3) A=(α1,α2,α3)。则:
-
正交化: β 1 = α 1 \beta_1=\alpha_1 β1=α1, β 2 = α 2 − k 21 β 1 \beta_2=\alpha_2-k_{21}\beta_1 β2=α2−k21β1, β 3 = α 3 − k 31 β 1 − k 32 β 2 \beta_3=\alpha_3-k_{31}\beta_1-k_{32}\beta_2 β3=α3−k31β1−k32β2,其中 k 21 = < α 2 , β 1 > < β 1 , β 1 > k_{21}=\frac{<\alpha_2,\beta_1>}{<\beta_1,\beta_1>} k21=<β1,β1><α2,β1>, k 31 = < α 3 , β 1 > < β 1 , β 1 > k_{31}=\frac{<\alpha_3,\beta_1>}{<\beta_1,\beta_1>} k31=<β1,β1><α3,β1>, k 31 = < α 3 , β 2 > < β 2 , β 2 > k_{31}=\frac{<\alpha_3,\beta_2>}{<\beta_2,\beta_2>} k31=<β2,β2><α3,β2>。
-
单位化得到矩阵 Q Q Q: Q = ( β 1 ∣ ∣ β 1 ∣ ∣ , β 2 ∣ ∣ β 2 ∣ ∣ , β 3 ∣ ∣ β 3 ∣ ∣ ) Q=(\frac{\beta_1}{||\beta_1||},\frac{\beta_2}{||\beta_2||},\frac{\beta_3}{||\beta_3||}) Q=(∣∣β1∣∣β1,∣∣β2∣∣β2,∣∣β3∣∣β3)
-
计算得到矩阵 R R R:
( ∣ ∣ β 1 ∣ ∣ ∣ ∣ β 2 ∣ ∣ ∣ ∣ β 3 ∣ ∣ ) ( 1 k 21 k 31 1 k 32 1 ) = ( ∣ ∣ β 1 ∣ ∣ ∣ ∣ β 1 ∣ ∣ × k 21 ∣ ∣ β 1 ∣ ∣ × k 31 ∣ ∣ β 2 ∣ ∣ ∣ ∣ β 2 ∣ ∣ × k 32 ∣ ∣ β 3 ∣ ∣ ) \begin{pmatrix} ||\beta _1|| & & \\ & ||\beta _2|| & \\ & &||\beta _3|| \end{pmatrix}\begin{pmatrix} 1 & k_{21} & k_{31} \\ & 1 & k_{32} \\ & & 1 \end{pmatrix}=\begin{pmatrix} ||\beta _1|| & ||\beta _1||\times k_{21} & ||\beta _1||\times k_{31}\\ & ||\beta _2|| & ||\beta _2||\times k_{32}\\ & & ||\beta _3|| \end{pmatrix} ∣∣β1∣∣∣∣β2∣∣∣∣β3∣∣ 1k211k31k321 = ∣∣β1∣∣∣∣β1∣∣×k21∣∣β2∣∣∣∣β1∣∣×k31∣∣β2∣∣×k32∣∣β3∣∣ -
这样, A = Q R A=QR A=QR
-
-
Python求解 Q R QR QR分解常规计算:
import numpy as np import sympy from sympy import Matrix from sympy import * import pprint #正交三角分解(QR) a = [[1, 1, -1], [-1, 1, 1], [1, 1, -1], [1, 1, 1]] # a = [[1,1,-1], # [1,0,0], # [0,1,0], # [0,0,1]] A_mat = Matrix(a)#α向量组成的矩阵A # A_gs= GramSchmidt(A_mat) A_arr = np.array(A_mat) L = [] for i in range(A_mat.shape[1]): L.append(A_mat[:,i]) #求Q A_gs = GramSchmidt(L)#α的施密特正交化得到β A_gs_norm = GramSchmidt(L,True)#β的单位化得到v A = [] for i in range(A_mat.shape[1]): for j in range(A_mat.shape[0]): A.append(A_gs_norm[i][j])#把数排成一行 A_arr = np.array(A) A_arr = A_arr.reshape((A_mat.shape[0],A_mat.shape[1]),order = 'F')#用reshape重新排列(‘F’为竖着写) #得到最后的Q Q = Matrix(A_arr) #求R C = [] for i in range(A_mat.shape[1]): for j in range(A_mat.shape[1]): if i > j: C.append(0) elif i == j: t = np.array(A_gs[i]) m = np.dot(t.T,t) C.append(sympy.sqrt(m[0][0])) else: t = np.array(A_mat[:,j]) x = np.array(A_gs_norm[i]) n = np.dot(t.T,x) # print(n) C.append(n[0][0]) # C_final为R C_arr = np.array(C) # print(C_arr) C_arr = C_arr.reshape((A_mat.shape[1],A_mat.shape[1])) R = Matrix(C_arr) pprint.pprint("Q:") pprint.pprint(Q) pprint.pprint("R:") pprint.pprint(R)调用库函数
# 求矩阵A的QR分解,保留根号 Q_, R_ = A_mat.QRdecomposition() pprint.pprint("Q_:") pprint.pprint(Q_) pprint.pprint("R_:") pprint.pprint(R_) assert Q_ == Q, "Q_ != Q" assert R_ == R, "R_ != R"
4 奇异值分解(SVD)
-
S V D SVD SVD定理
设 A A A是 m × n m\times n m×n矩阵,且 r a n k ( A ) = r rank(A)=r rank(A)=r,则存在 m m m阶酉矩阵 U U U和 n n n阶酉矩阵 V V V使得
A = U [ Σ 0 0 0 ] V H A=U\begin{bmatrix}\Sigma & 0\\ 0 & 0 \end{bmatrix}V^H A=U[Σ000]VH
其中 Σ = d i a g ( σ 1 , . . . , σ r ) \Sigma=diag(\sigma_1,...,\sigma_r) Σ=diag(σ1,...,σr),且 σ 1 ≥ . . . ≥ σ r > 0 \sigma_1\geq ...\geq \sigma_r>0 σ1≥...≥σr>0。σ \sigma σ为 A A A的奇异值,具体含义这里不在叙述,但需要记住的是 σ 2 \sigma^2 σ2是 A H A A^HA AHA的特征值,也是 A A H AA^H AAH的特征值,且:
- A H A A^HA AHA与 A A H AA^H AAH的特征值均为非负数
- A H A A^HA AHA与 A A H AA^H AAH的非零特征值相同,并且非零特征值的个数(重特征值按重数计算)等于 r a n k ( A ) rank(A) rank(A)
所以我们求 Σ \Sigma Σ就转换成求这两个矩阵其中一个的特征值。
-
S V D SVD SVD分解步骤
-
求 A H A A^HA AHA的 n n n个特征值,即计算 ∣ λ I − A H A ∣ = 0 |\lambda I-A^HA|=0 ∣λI−AHA∣=0。得到特征值: λ 1 , . . . , λ r , λ r + 1 = 0 , . . . , λ n = 0 \lambda_1,...,\lambda_r,\lambda_{r+1}=0,...,\lambda_n=0 λ1,...,λr,λr+1=0,...,λn=0,其中 r = r a n k ( A ) r=rank(A) r=rank(A)。
-
将 r r r个奇异值(即非零特征值开根号)从大到小排列组成对角矩阵,再添加额外的 0 0 0构成 Σ m × n \Sigma_{m\times n} Σm×n矩阵。
Σ m × n = ( λ 1 . . . 0 0 0 0 λ 2 0 0 0 . . . . . . . . . . . . . . . . . . . . . . . . λ r . . . 0 . . . 0 0 0 ) \Sigma_{m\times n}=\begin{pmatrix} \sqrt[]{\lambda _1} & ... & 0&0&0 \\ 0& \sqrt[]{ \lambda _2} & 0 &0&0\\ ...& ... & ... &...&...\\ ...& ... & ... &\sqrt[]{\lambda_r}&...\\ 0& ... & 0 &0&0 \end{pmatrix} Σm×n= λ10......0...λ2.........00......000...λr000......0 -
求特征值: λ 1 , . . . , λ r , λ r + 1 = 0 , . . . , λ n = 0 \lambda_1,...,\lambda_r,\lambda_{r+1}=0,...,\lambda_n=0 λ1,...,λr,λr+1=0,...,λn=0对应的特征向量 ξ 1 , . . . , ξ n \xi_1,...,\xi_n ξ1,...,ξn:当 λ = λ 1 \lambda=\lambda_1 λ=λ1时, ( λ I − A H A ) × ξ 1 = 0 (\lambda I-A^HA)\times \xi_1=0 (λI−AHA)×ξ1=0,解得 ξ 1 \xi_1 ξ1,同理,计算其余特征向量。
-
因为 ξ 1 , . . . , ξ n \xi_1,...,\xi_n ξ1,...,ξn相互正交,我们还需要进行单位化,得到 v 1 , . . . , v n v_1,...,v_n v1,...,vn,即 v 1 = ξ 1 ∣ ∣ ξ 1 ∣ ∣ , . . . , v n = ξ n ∣ ∣ ξ n ∣ ∣ v_1=\frac{\xi_1}{||\xi_1||},...,v_n=\frac{\xi_n}{||\xi_n||} v1=∣∣ξ1∣∣ξ1,...,vn=∣∣ξn∣∣ξn。则 V = ( v 1 , . . . , v n ) V=(v_1,...,v_n) V=(v1,...,vn)。
-
根据 A = U m × m Σ m × n V n × n H A=U_{m\times m}\Sigma_{m\times n}V_{n\times n}^H A=Um×mΣm×nVn×nH,可得 U 1 = A V n × n Σ r × n − 1 U_1=AV_{n\times n}\Sigma_{r\times n}^{-1} U1=AVn×nΣr×n−1(注意, σ \sigma σ此时为 Σ m × n \Sigma_{m\times n} Σm×n的前 r r r行),易知 U 1 U_1 U1为 m × r m\times r m×r的矩阵,我们还需要扩充 U 2 U_2 U2,其为 m × ( m − r ) m\times (m-r) m×(m−r)矩阵。
-
取 U 1 H U 2 = 0 U_1^HU_2=0 U1HU2=0,取 U 2 U_2 U2,必须要单位化 U 2 U_2 U2,这样 U = [ U 1 : U 2 ] U=[U_1:U_2] U=[U1:U2]
-
则 A = U m × m [ Σ 0 0 0 ] m × n V n × n H A=U_{m\times m}\begin{bmatrix}\Sigma & 0\\ 0 & 0 \end{bmatrix}_{m\times n}V_{n\times n}^H A=Um×m[Σ000]m×nVn×nH
-
-
Python求解奇异值分解import numpy as np from sympy import Matrix import pprint A = np.array([[1,0],[0,1],[1,1]]) # 求A的奇异值分解 U, sigma, VT = np.linalg.svd(A) print ("U:", U) print ("sigma:", sigma) print ("VT:", VT)




![C# 通俗讲解Public、Private以及Protected、[HideInInspector]、[SerializeField]的区别](https://img-blog.csdnimg.cn/direct/1f28f1acec434dd58d4818bec487b0ad.png)