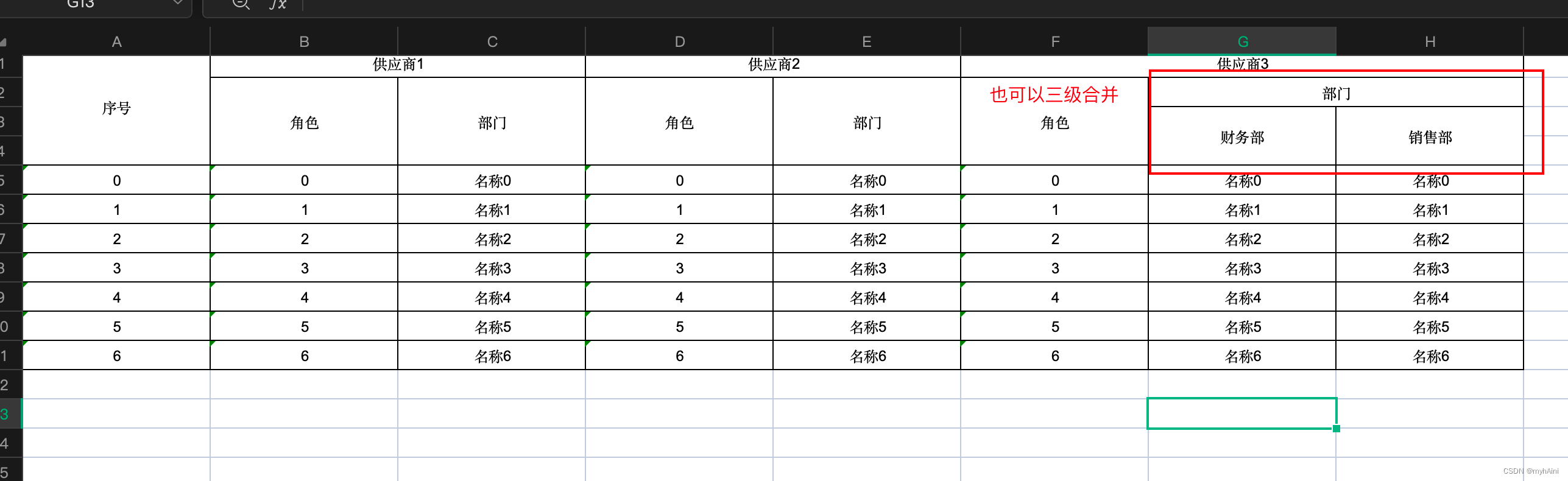
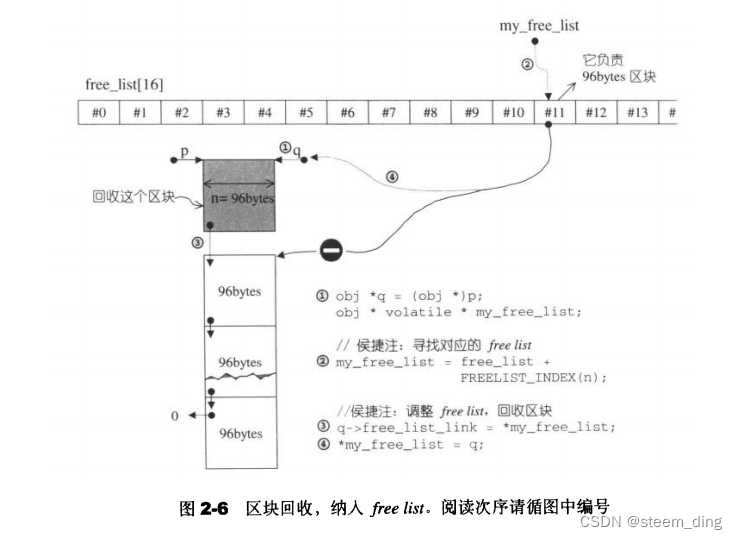
轻量级识别模型在我们前面的博文中已经有过很多实践了,感兴趣的话可以自行移步阅读:
《移动端轻量级模型开发谁更胜一筹,efficientnet、mobilenetv2、mobilenetv3、ghostnet、mnasnet、shufflenetv2驾驶危险行为识别模型对比开发测试》
《基于Pytorch框架的轻量级卷积神经网络垃圾分类识别系统》
《基于轻量级卷积神经网络模型实践Fruits360果蔬识别——自主构建CNN模型、轻量化改造设计lenet、alexnet、vgg16、vgg19和mobilenet共六种CNN模型实验对比分析》
《探索轻量级模型性能上限,基于GhostNet模型开发构建多商品细粒度图像识别系统》
《基于轻量级神经网络GhostNet开发构建的200种鸟类细粒度识别分析系统》
《基于MobileNet的轻量级卷积神经网络实现玉米螟虫不同阶段识别分析》
《python开发构建轻量级卷积神经网络模型实现手写甲骨文识别系统》
《基于轻量级模型GHoshNet开发构建眼球眼疾识别分析系统,构建全方位多层次参数对比分析实验》
本文的核心思想是像基于ShuffleNetv2来开发构建辣椒病虫害识别系统,首先看下实例效果:
本文选择的是轻量级网络中非常强大的ShuffleNetv2,ShuffleNetv2网络是一种用于图像识别和分类任务的卷积神经网络结构,它旨在在保持准确性的同时尽可能地减少模型的计算和参数量。下面是对ShuffleNetv2网络构建原理的详细介绍,并针对性地分析其优点和缺点:
构建原理:
-
基本单元:ShuffleNetv2网络的基本单元是由深度可分离卷积和通道重排组成的特殊模块。其中深度可分离卷积用于减少计算量和参数数量,而通道重排则用于交换和重组特征通道。
-
分组卷积:ShuffleNetv2将卷积操作分组,使得每个分组内部进行特征提取,然后再将特征通道进行重排和整合,从而实现了计算效率的提升。
-
网络结构:ShuffleNetv2网络结构由多个堆叠的ShuffleNetv2块组成,每个块内部包含了多个基本单元,通过合理的设计实现了高效的信息流动和特征提取。
优点:
-
轻量级高效:ShuffleNetv2相比传统的卷积神经网络具有更少的参数量和计算量,适合于移动设备上的部署和实时推理。
-
准确性:尽管模型规模小,但ShuffleNetv2在保持较高的准确性的同时,实现了高效的模型推理。
-
结构灵活:ShuffleNetv2网络结构可以通过调整基本单元的个数和网络深度来适应不同的计算资源和任务需求。
缺点:
-
学习能力有限:由于参数数量较少,ShuffleNetv2网络可能在复杂场景和大规模数据上的表示学习能力相对较弱,可能无法取得更高的准确性。
-
训练复杂度:尽管ShuffleNetv2网络在推理时很高效,但在训练过程中相比一些大型网络结构可能需要更多的迭代才能取得好的效果,训练复杂度较大。
总的来说,ShuffleNetv2网络在轻量级和高效方面具有明显的优势,适用于移动设备和资源受限的场景,但在一些大规模和复杂任务上可能会存在一定的限制。
这里给出基于Keras和pytorch对应的代码实现,首先是keras实现,如下所示:
#!usr/bin/env python
# encoding:utf-8
from __future__ import division
import os
import numpy as np
from keras.utils import plot_model
from keras.applications.imagenet_utils import _obtain_input_shape
from keras.engine.topology import get_source_inputs
from keras.layers import *
from keras.models import Model
import keras.backend as K
from utils import block
def ShuffleNetV2(
include_top=True,
input_tensor=None,
scale_factor=1.0,
pooling="max",
input_shape=(224, 224, 3),
load_model=None,
num_shuffle_units=[3, 7, 3],
bottleneck_ratio=1,
classes=1000,
):
if K.backend() != "tensorflow":
raise RuntimeError("Only tensorflow supported for now")
name = "ShuffleNetV2_{}_{}_{}".format(
scale_factor, bottleneck_ratio, "".join([str(x) for x in num_shuffle_units])
)
input_shape = _obtain_input_shape(
input_shape,
default_size=224,
min_size=28,
require_flatten=include_top,
data_format=K.image_data_format(),
)
out_dim_stage_two = {0.5: 48, 1: 116, 1.5: 176, 2: 244}
if pooling not in ["max", "avg"]:
raise ValueError("Invalid value for pooling")
if not (float(scale_factor) * 4).is_integer():
raise ValueError("Invalid value for scale_factor, should be x over 4")
exp = np.insert(
np.arange(len(num_shuffle_units), dtype=np.float32), 0, 0
)
# [0., 0., 1., 2.]
out_channels_in_stage = 2**exp
out_channels_in_stage *= out_dim_stage_two[
bottleneck_ratio
]
# calculate output channels for each stage
out_channels_in_stage[0] = 24
# first stage has always 24 output channels
out_channels_in_stage *= scale_factor
out_channels_in_stage = out_channels_in_stage.astype(int)
if input_tensor is None:
img_input = Input(shape=input_shape)
else:
if not K.is_keras_tensor(input_tensor):
img_input = Input(tensor=input_tensor, shape=input_shape)
else:
img_input = input_tensor
# create shufflenet architecture
x = Conv2D(
filters=out_channels_in_stage[0],
kernel_size=(3, 3),
padding="same",
use_bias=False,
strides=(2, 2),
activation="relu",
name="conv1",
)(img_input)
x = MaxPool2D(pool_size=(3, 3), strides=(2, 2), padding="same", name="maxpool1")(x)
# create stages containing shufflenet units beginning at stage 2
for stage in range(len(num_shuffle_units)):
repeat = num_shuffle_units[stage]
x = block(
x,
out_channels_in_stage,
repeat=repeat,
bottleneck_ratio=bottleneck_ratio,
stage=stage + 2,
)
if bottleneck_ratio < 2:
k = 1024
else:
k = 2048
x = Conv2D(
k,
kernel_size=1,
padding="same",
strides=1,
name="1x1conv5_out",
activation="relu",
)(x)
if pooling == "avg":
x = GlobalAveragePooling2D(name="global_avg_pool")(x)
elif pooling == "max":
x = GlobalMaxPooling2D(name="global_max_pool")(x)
if include_top:
x = Dense(classes, name="fc")(x)
x = Activation("softmax", name="softmax")(x)
if input_tensor:
inputs = get_source_inputs(input_tensor)
else:
inputs = img_input
model = Model(inputs, x, name=name)
if load_model:
model.load_weights("", by_name=True)
return model
接下来是PyTorch的实现:
#!usr/bin/env python
# encoding:utf-8
from __future__ import division
import os
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.nn import init
from collections import OrderedDict
def _make_divisible(v, divisor, min_value=None):
"""
This function is taken from the original tf repo.
It ensures that all layers have a channel number that is divisible by 8
It can be seen here:
https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet/mobilenet.py
:param v:
:param divisor:
:param min_value:
:return:
"""
if min_value is None:
min_value = divisor
new_v = max(min_value, int(v + divisor / 2) // divisor * divisor)
# Make sure that round down does not go down by more than 10%.
if new_v < 0.9 * v:
new_v += divisor
return new_v
def channel_shuffle(x, groups):
batchsize, num_channels, height, width = x.data.size()
assert num_channels % groups == 0
channels_per_group = num_channels // groups
# reshape
x = x.view(batchsize, groups, channels_per_group, height, width)
# transpose
# - contiguous() required if transpose() is used before view().
# See https://github.com/pytorch/pytorch/issues/764
x = torch.transpose(x, 1, 2).contiguous()
# flatten
x = x.view(batchsize, -1, height, width)
return x
class SELayer(nn.Module):
def __init__(self, channel, reduction=16):
super(SELayer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction),
nn.ReLU(inplace=True),
nn.Linear(channel // reduction, channel),
nn.Sigmoid(),
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y
class BasicUnit(nn.Module):
def __init__(
self,
inplanes,
outplanes,
c_tag=0.5,
activation=nn.ReLU,
SE=False,
residual=False,
groups=2,
):
super(BasicUnit, self).__init__()
self.left_part = round(c_tag * inplanes)
self.right_part_in = inplanes - self.left_part
self.right_part_out = outplanes - self.left_part
self.conv1 = nn.Conv2d(
self.right_part_in, self.right_part_out, kernel_size=1, bias=False
)
self.bn1 = nn.BatchNorm2d(self.right_part_out)
self.conv2 = nn.Conv2d(
self.right_part_out,
self.right_part_out,
kernel_size=3,
padding=1,
bias=False,
groups=self.right_part_out,
)
self.bn2 = nn.BatchNorm2d(self.right_part_out)
self.conv3 = nn.Conv2d(
self.right_part_out, self.right_part_out, kernel_size=1, bias=False
)
self.bn3 = nn.BatchNorm2d(self.right_part_out)
self.activation = activation(inplace=True)
self.inplanes = inplanes
self.outplanes = outplanes
self.residual = residual
self.groups = groups
self.SE = SE
if self.SE:
self.SELayer = SELayer(self.right_part_out, 2) # TODO
def forward(self, x):
left = x[:, : self.left_part, :, :]
right = x[:, self.left_part :, :, :]
out = self.conv1(right)
out = self.bn1(out)
out = self.activation(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.conv3(out)
out = self.bn3(out)
out = self.activation(out)
if self.SE:
out = self.SELayer(out)
if self.residual and self.inplanes == self.outplanes:
out += right
return channel_shuffle(torch.cat((left, out), 1), self.groups)
class DownsampleUnit(nn.Module):
def __init__(self, inplanes, c_tag=0.5, activation=nn.ReLU, groups=2):
super(DownsampleUnit, self).__init__()
self.conv1r = nn.Conv2d(inplanes, inplanes, kernel_size=1, bias=False)
self.bn1r = nn.BatchNorm2d(inplanes)
self.conv2r = nn.Conv2d(
inplanes,
inplanes,
kernel_size=3,
stride=2,
padding=1,
bias=False,
groups=inplanes,
)
self.bn2r = nn.BatchNorm2d(inplanes)
self.conv3r = nn.Conv2d(inplanes, inplanes, kernel_size=1, bias=False)
self.bn3r = nn.BatchNorm2d(inplanes)
self.conv1l = nn.Conv2d(
inplanes,
inplanes,
kernel_size=3,
stride=2,
padding=1,
bias=False,
groups=inplanes,
)
self.bn1l = nn.BatchNorm2d(inplanes)
self.conv2l = nn.Conv2d(inplanes, inplanes, kernel_size=1, bias=False)
self.bn2l = nn.BatchNorm2d(inplanes)
self.activation = activation(inplace=True)
self.groups = groups
self.inplanes = inplanes
def forward(self, x):
out_r = self.conv1r(x)
out_r = self.bn1r(out_r)
out_r = self.activation(out_r)
out_r = self.conv2r(out_r)
out_r = self.bn2r(out_r)
out_r = self.conv3r(out_r)
out_r = self.bn3r(out_r)
out_r = self.activation(out_r)
out_l = self.conv1l(x)
out_l = self.bn1l(out_l)
out_l = self.conv2l(out_l)
out_l = self.bn2l(out_l)
out_l = self.activation(out_l)
return channel_shuffle(torch.cat((out_r, out_l), 1), self.groups)
class ShuffleNetV2(nn.Module):
"""
ShuffleNetV2 implementation
"""
def __init__(
self,
scale=1.0,
in_channels=3,
c_tag=0.5,
num_classes=1000,
activation=nn.ReLU,
SE=False,
residual=False,
groups=2,
):
"""
ShuffleNetV2 constructor
:param scale:
:param in_channels:
:param c_tag:
:param num_classes:
:param activation:
:param SE:
:param residual:
:param groups:
"""
super(ShuffleNetV2, self).__init__()
self.scale = scale
self.c_tag = c_tag
self.residual = residual
self.SE = SE
self.groups = groups
self.activation_type = activation
self.activation = activation(inplace=True)
self.num_classes = num_classes
self.num_of_channels = {
0.5: [24, 48, 96, 192, 1024],
1: [24, 116, 232, 464, 1024],
1.5: [24, 176, 352, 704, 1024],
2: [24, 244, 488, 976, 2048],
}
self.c = [_make_divisible(chan, groups) for chan in self.num_of_channels[scale]]
self.n = [3, 8, 3] # TODO: should be [3,7,3]
self.conv1 = nn.Conv2d(
in_channels, self.c[0], kernel_size=3, bias=False, stride=2, padding=1
)
self.bn1 = nn.BatchNorm2d(self.c[0])
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2)
self.shuffles = self._make_shuffles()
self.conv_last = nn.Conv2d(self.c[-2], self.c[-1], kernel_size=1, bias=False)
self.bn_last = nn.BatchNorm2d(self.c[-1])
self.avgpool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Linear(self.c[-1], self.num_classes)
self.init_params()
def init_params(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight, mode="fan_out")
if m.bias is not None:
init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
init.constant_(m.weight, 1)
init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
init.normal_(m.weight, std=0.001)
if m.bias is not None:
init.constant_(m.bias, 0)
def _make_stage(self, inplanes, outplanes, n, stage):
modules = OrderedDict()
stage_name = "ShuffleUnit{}".format(stage)
# First module is the only one utilizing stride
first_module = DownsampleUnit(
inplanes=inplanes,
activation=self.activation_type,
c_tag=self.c_tag,
groups=self.groups,
)
modules["DownsampleUnit"] = first_module
second_module = BasicUnit(
inplanes=inplanes * 2,
outplanes=outplanes,
activation=self.activation_type,
c_tag=self.c_tag,
SE=self.SE,
residual=self.residual,
groups=self.groups,
)
modules[stage_name + "_{}".format(0)] = second_module
# add more LinearBottleneck depending on number of repeats
for i in range(n - 1):
name = stage_name + "_{}".format(i + 1)
module = BasicUnit(
inplanes=outplanes,
outplanes=outplanes,
activation=self.activation_type,
c_tag=self.c_tag,
SE=self.SE,
residual=self.residual,
groups=self.groups,
)
modules[name] = module
return nn.Sequential(modules)
def _make_shuffles(self):
modules = OrderedDict()
stage_name = "ShuffleConvs"
for i in range(len(self.c) - 2):
name = stage_name + "_{}".format(i)
module = self._make_stage(
inplanes=self.c[i], outplanes=self.c[i + 1], n=self.n[i], stage=i
)
modules[name] = module
return nn.Sequential(modules)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.activation(x)
x = self.maxpool(x)
x = self.shuffles(x)
x = self.conv_last(x)
x = self.bn_last(x)
x = self.activation(x)
# average pooling layer
x = self.avgpool(x)
# flatten for input to fully-connected layer
x = x.view(x.size(0), -1)
x = self.fc(x)
return F.log_softmax(x, dim=1)
可以拿到自己的项目中直接集成使用。
接下来看下数据集:
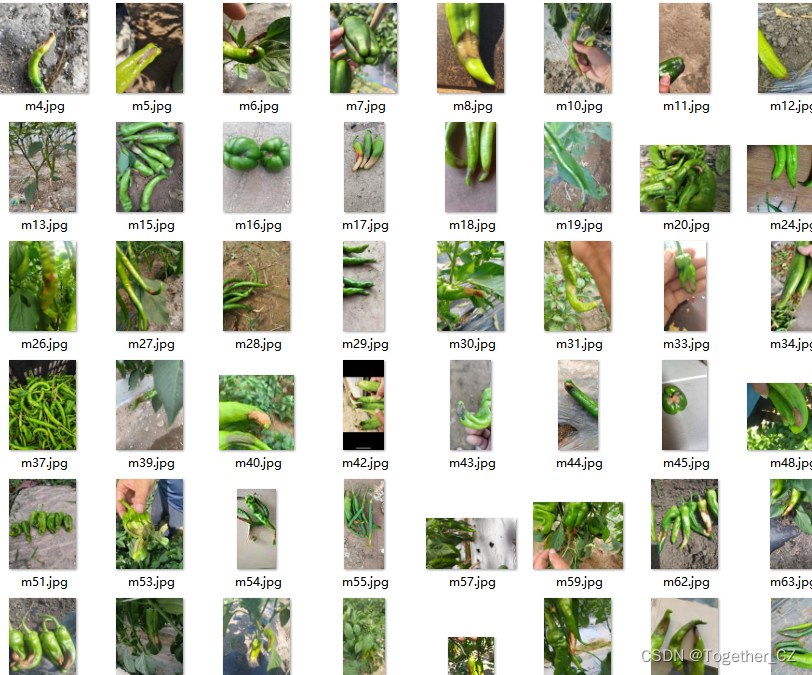


一共包含11种对应的疾病,如下:
炭疽病
疫病
用药不当
病毒病
温度不适
螨虫
细菌性病害
根腐病
缺素
脐腐病
蓟马数据分布可视化如下所示:
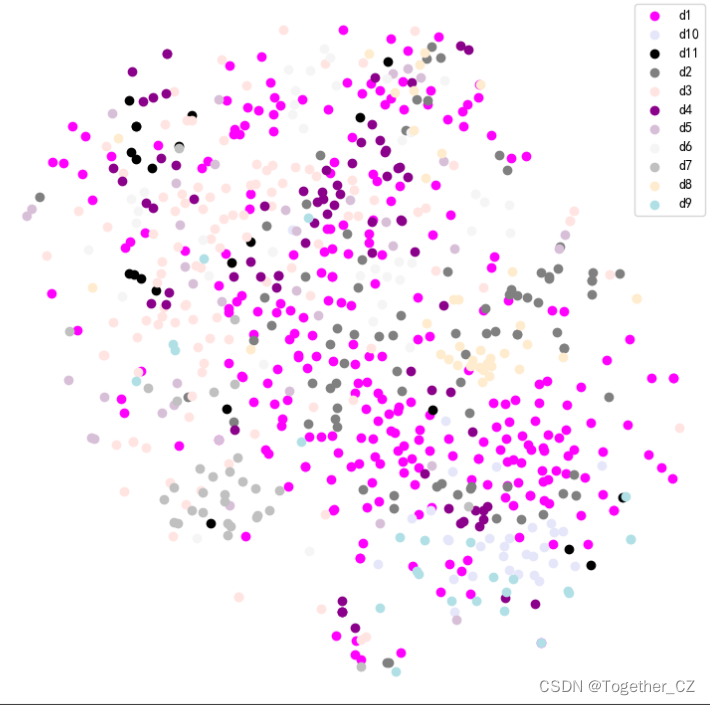
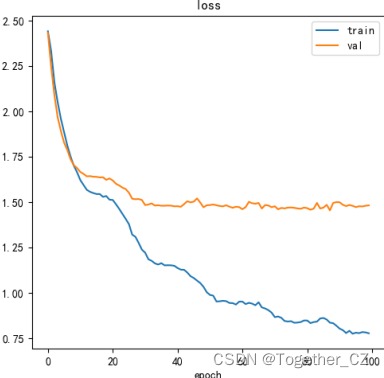
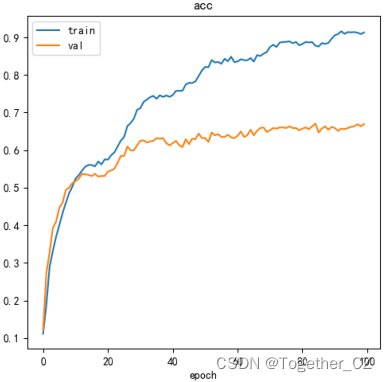
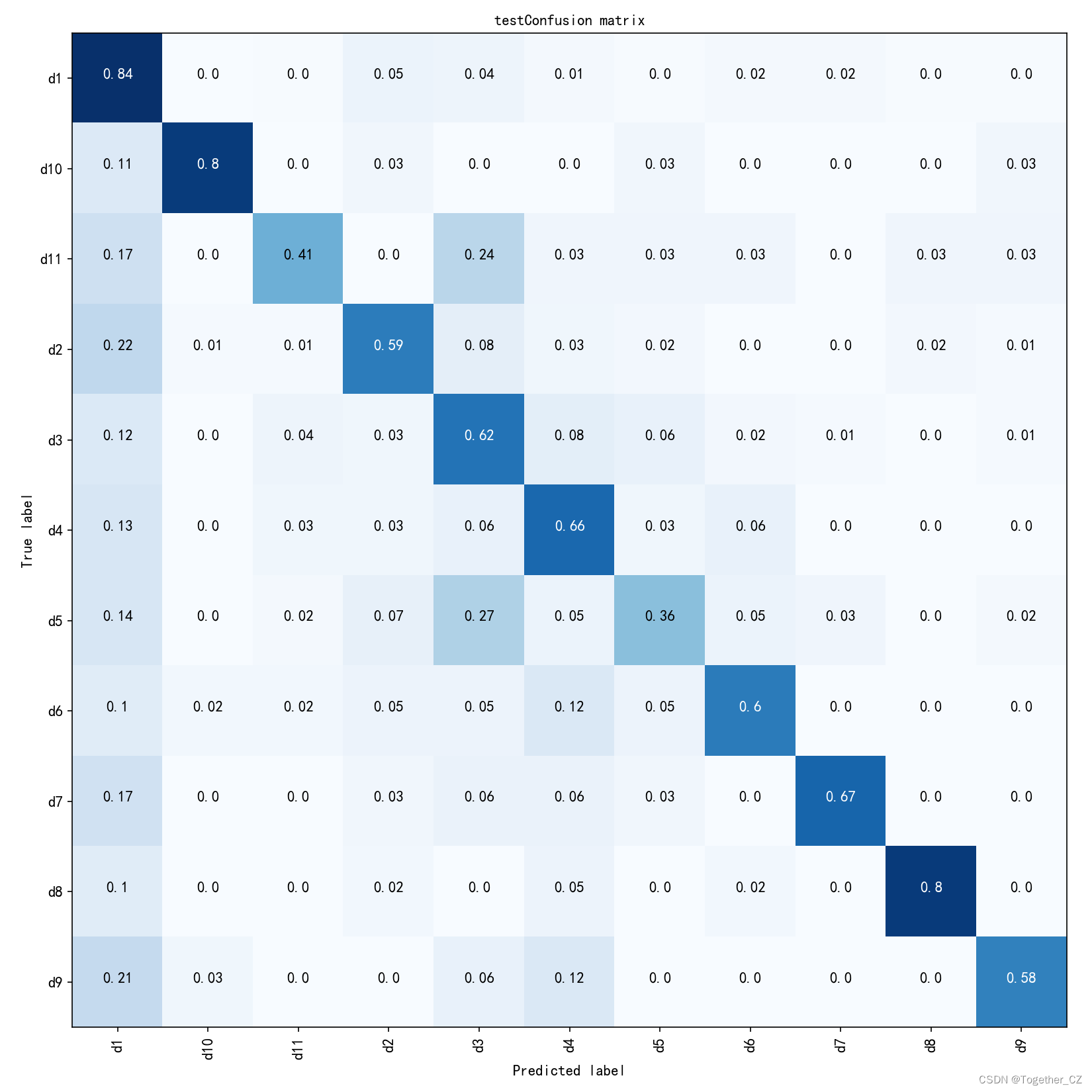
默认100次的迭代训练,执行结束后来看下结果详情:
【loss曲线】
【acc曲线】
【混淆矩阵】
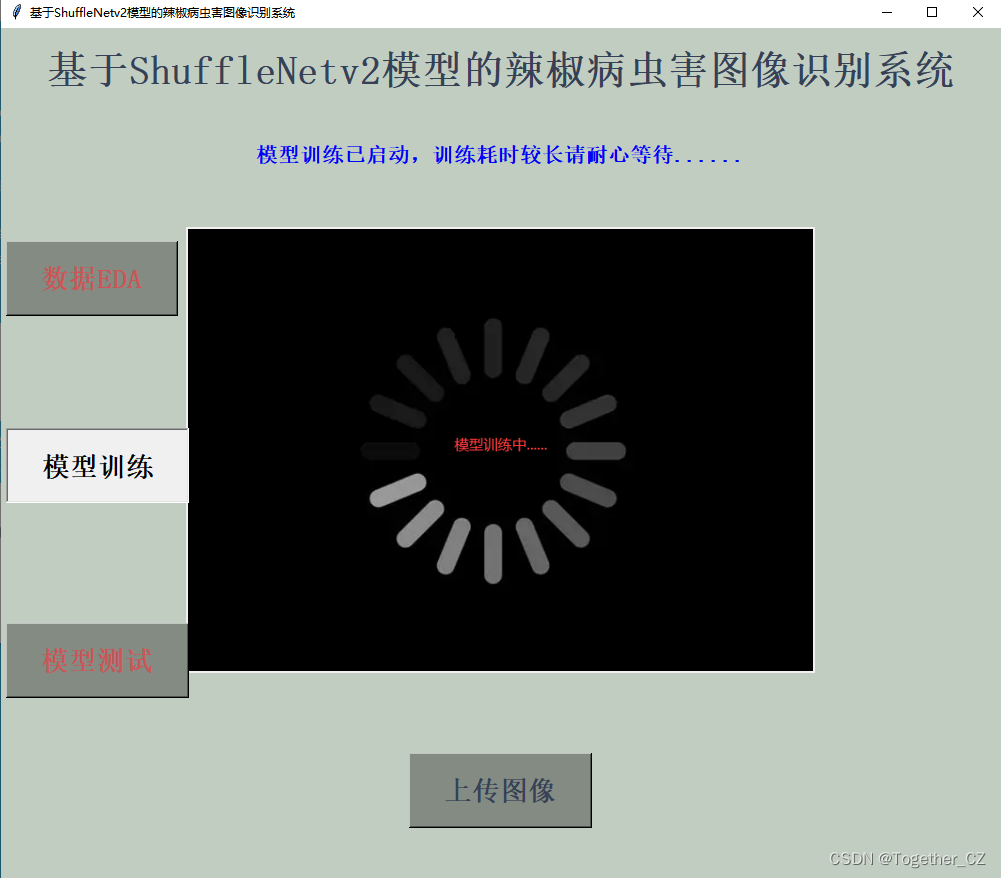
开发专用的系统界面实现可视化推理实例如下所示:


感兴趣的话都可以自行动手实践一下。