name_suggest最全最详细的参数解读
- 1. name_suggest的基本情况
- 2. name_suggest的参数
- 3. name_suggest的示例与理解
- 3.1 参数 【q】
- 3.2 参数【rank】
- 3.3 参数【limit】
- 3.4 参数【fields】
- 3.5 参数【datasetKey】
- 3.6 参数【curlopts】
1. name_suggest的基本情况
name_suggest是用rgbif下载物种分布数据的第一步,当然是至关重要的。

name_suggest是一个快速且方便的自动化补全服务函数,它通过对学名进行前缀匹配,至多返回20个名称,这些名称按照相关性进行排序。
name_suggest(
q = NULL,
datasetKey = NULL,
rank = NULL,
fields = NULL,
start = NULL,
limit = 100,
curlopts = list()
)
2. name_suggest的参数
| 参数 | 传入类型 | 描述 |
|---|---|---|
| q | 需要字符型,必填参数 | 最简便的检索参数。传入此参数的值可以是只是一个简单的单词或短语。使用单个单词时可以附加通配符。 |
| datasetKey | 需要字符型 | 根据数据集标识符(uuid)进行筛选,或者说是从特定数据集中进行检索。 |
| rank | 需要字符型 | 传入一个分类阶元,可选项包括:class, cultivar, cultivar_group, domain, family, form, genus, informal, infrageneric_name, infraorder, infraspecific_name, infrasubspecific_name, kingdom, order, phylum, section, series, species, strain, subclass, subfamily, subform, subgenus, subkingdom, suborder, subphylum, subsection, subseries, subspecies, subtribe, subvariety, superclass, superfamily, superorder, superphylum, suprageneric_name, tribe, unranked, or variety。 |
| fields | 需要字符型 | 决定返回的data.frame中的字段,或者说是对返回结果的列进行增减。 |
| start | 需要整数型 | 决定从第几条结果开始返回。默认为0。一般与limit配合使用。 |
| limit | 需要整数型 | 决定返回结果数量的上限。默认为100。最大值为1000。 |
| curlopts | 传递给HttpClient的命名curl选项列表。有关curl选项,请参见curl::curl_options。 |
3. name_suggest的示例与理解
通过一些示例可以对此函数的用法和参数有更深入的了解。
3.1 参数 【q】
==首先,此参数是必填的。==其次,传入此参数的值既可以是学名的全部或部分,需要注意一点的是,部分必须是从学名的首字母开始,因为name_suggest使用的是针对前缀的匹配方法。
有两个例子可以帮助理解:
例1:name_suggest(q='Puma concolor')
例2:name_suggest(q='Puma')
例1中,我们传入了完整的学名,而在例2中,我们传入了部分的学名(是完整学名的前半部分)。
下面我们看一下两个例子的结果:
例1结果分析:
在控制台中可以看到下图的输出结果
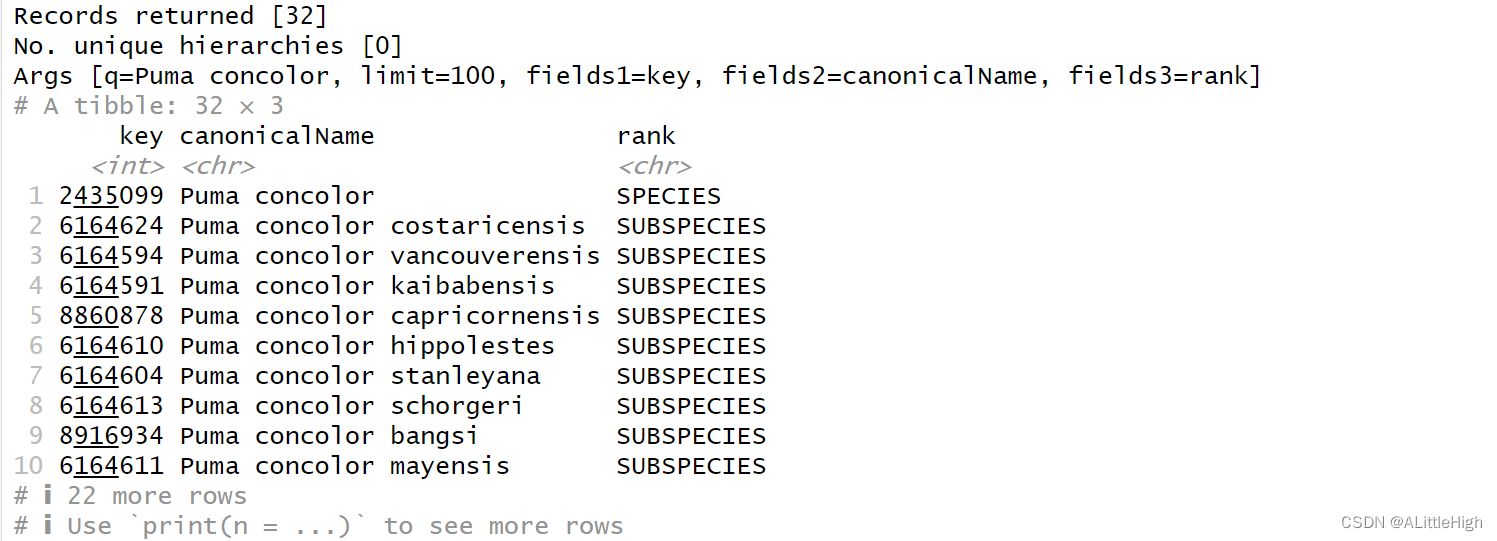
- 第一行指明返回了32条记录。
- 第二行指明的也许是分类阶元此类信息(暂不了解)
- 第三行指明的是一些请求信息和返回结果的字段名称(即列名称)。请求信息包括 q=Puma concolor, limit=100,而列名称包括 fields1=key(标识符),field2=canonicalName(标准化名称),filed3=rank(分类阶元)。
加深理解:即使输入了完整学名,当试图获取种级物种信息时,也会返回许多种下等级的信息,更不用说在请求种级以上类群名称时的情况了,譬如例2。
例2结果分析:
在控制台中可以看到下图的输出结果,与例1的结果结构相差无几。
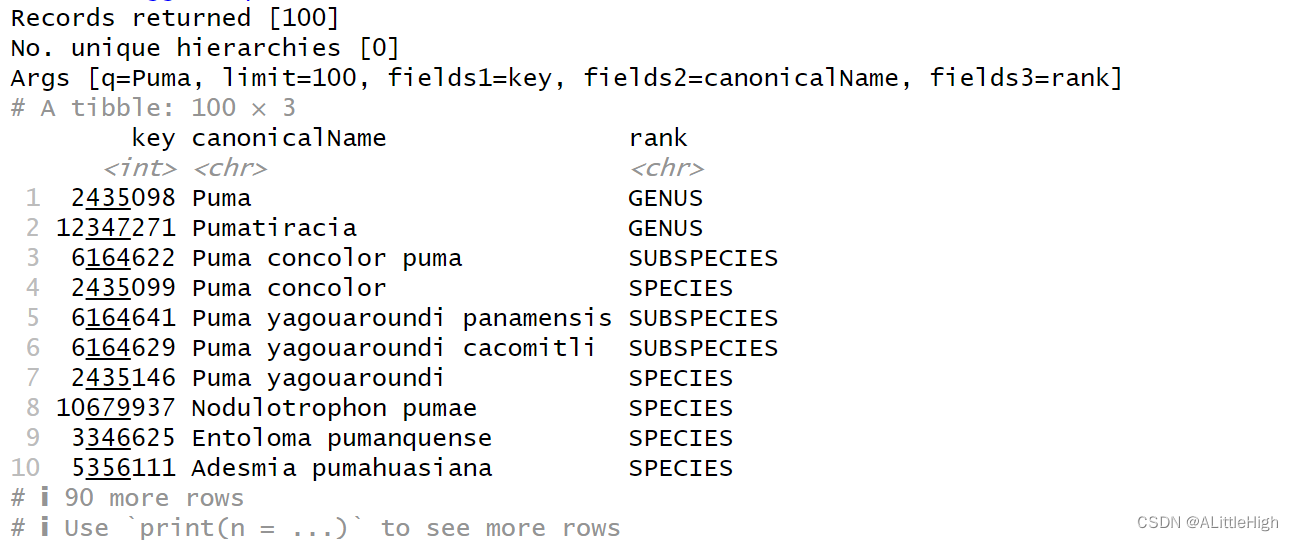
加深理解:例2返回了100条记录,原因很可能是limit=100的限制结果。
使用参数【q】的注意事项:
- 传入部分学名时,应从完整学名的起始开始截取。
- 无论传入了部分学名还是完整学名,都需要考虑到返回的结果数量受到参数【limit】的限制,从而导致返回的结果=limit<检索到的结果。
3.2 参数【rank】
顾名思义,参数【rank】通过判断检索结果的分类阶元是否为传入值来决定是否将该结果返回。
下面我们将通过几个例子来深入理解:
例3:name_suggest(q='Puma', rank="genus")
例4:name_suggest(q='Puma', rank="subspecies")
例5:name_suggest(q='Puma', rank="species")
例6:name_suggest(q='Puma', rank="infraspecific_name")
这些例子中,参数【rank】分别被传入了不同的分类阶元,那么它们的结果有什么不同呢?
左边黄框中是name_suggest(q='Puma')的结果,也就是不通过参数【rank】筛选。
右边粉框中自上而下是例3-6的结果。
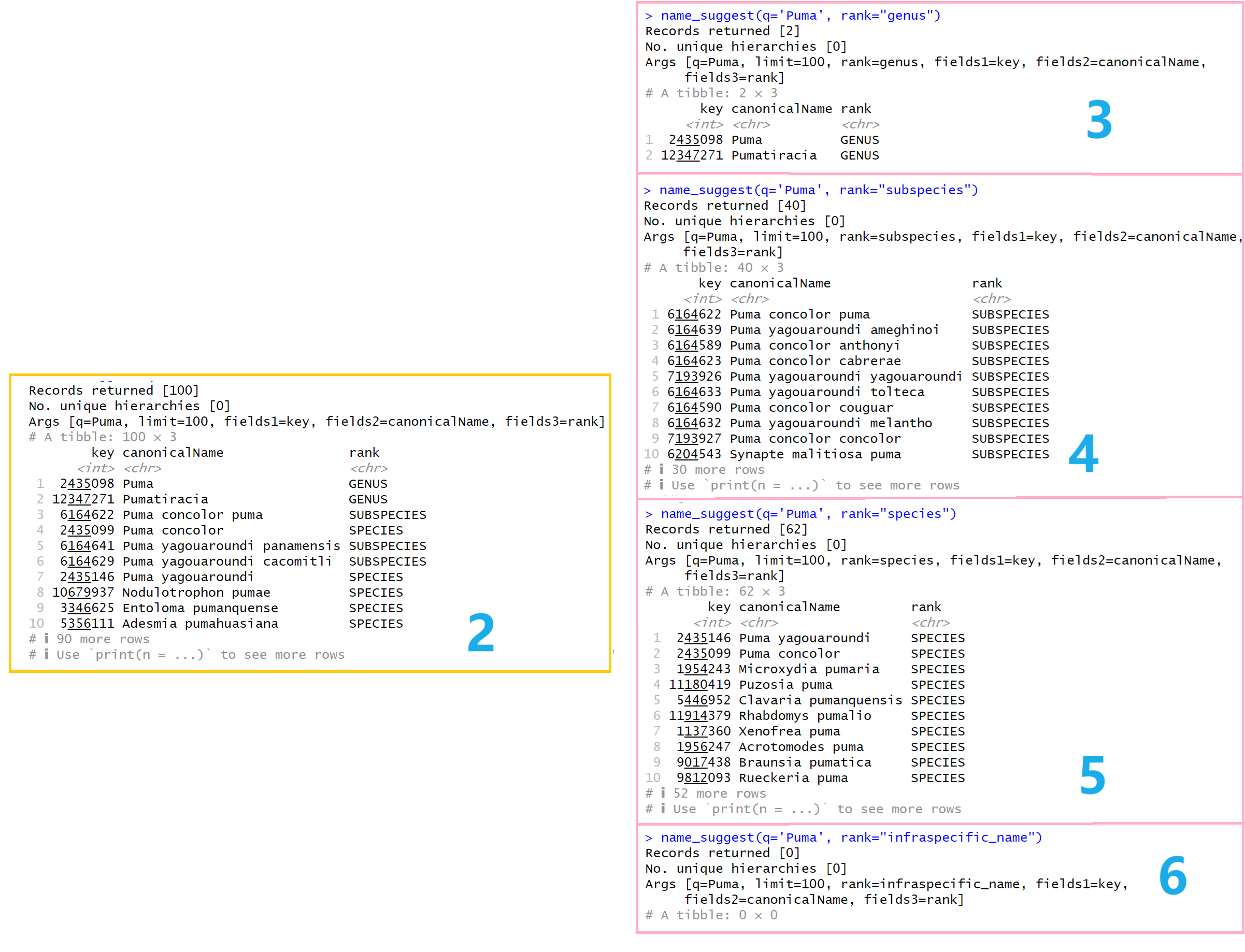
例3,4,5,6结果分析:例子的结果结构相差无几,只有结果数量有所变化。
加深理解:这四个例子返回的结果数量相加多于100,也就是参数【limit】导致name_suggest(q='Puma')的结果返回不完整。
特殊情况:参数【rank】可以同时接受多个分类阶元等级输入,例如:name_suggest(rank = c("family", "genus"))
3.3 参数【limit】
在 2. name_suggest的参数的表格中对参数【limit】的介绍已经十分简明了然。
在前文中,我们已经发现参数【limit】默认的100限制了name_suggest(q='Puma')的所有检索结果。下面我们改变参数【limit】的值来看一下结果的变化:
例7:name_suggest(q='Puma', limit=2)
例8:name_suggest(q='Puma', limit=200)
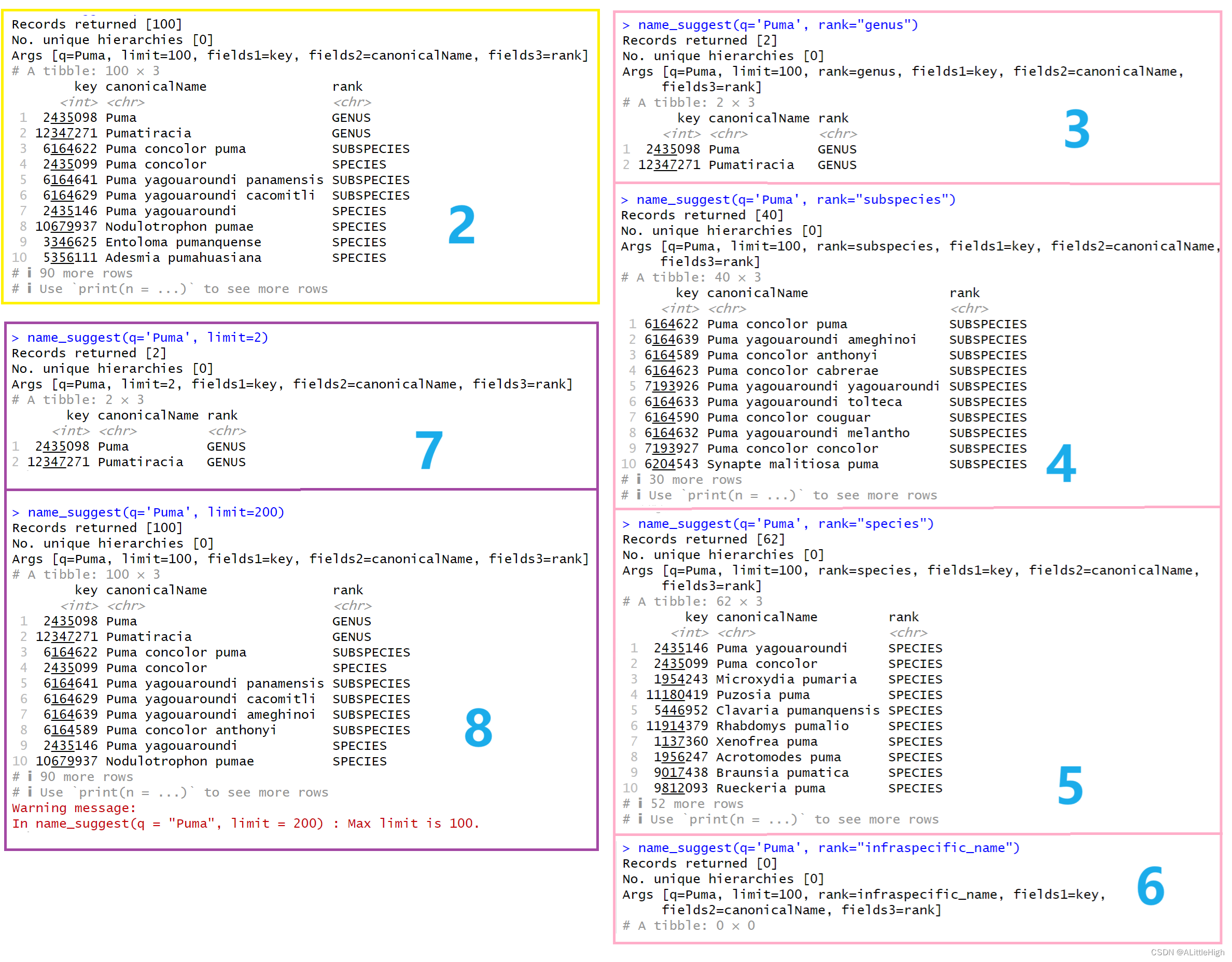
加深理解:虽然帮助文档里说明参数【limit】的上限是1000,但在github的name_suggest appears to ignore the limit parameter 中,已经明确说明参数【limit】的上限就是100,即默认值,相当于此参数失效了。聊胜于无的是,当我们指定参数【limit】的值超过100时,会给出警告信息。
3.4 参数【fields】
此参数决定了返回结果的数据框中的字段信息,即列。
由上文可知,参数【fields】默认的列信息包括:key,canonicalName和rank。
我们也可以根据需要进行调整:
例9:name_suggest(q='Puma', fields=c('key','canonicalName'))
例10:name_suggest(q='Puma', fields=c('key','canonicalName', 'higherClassificationMap'))
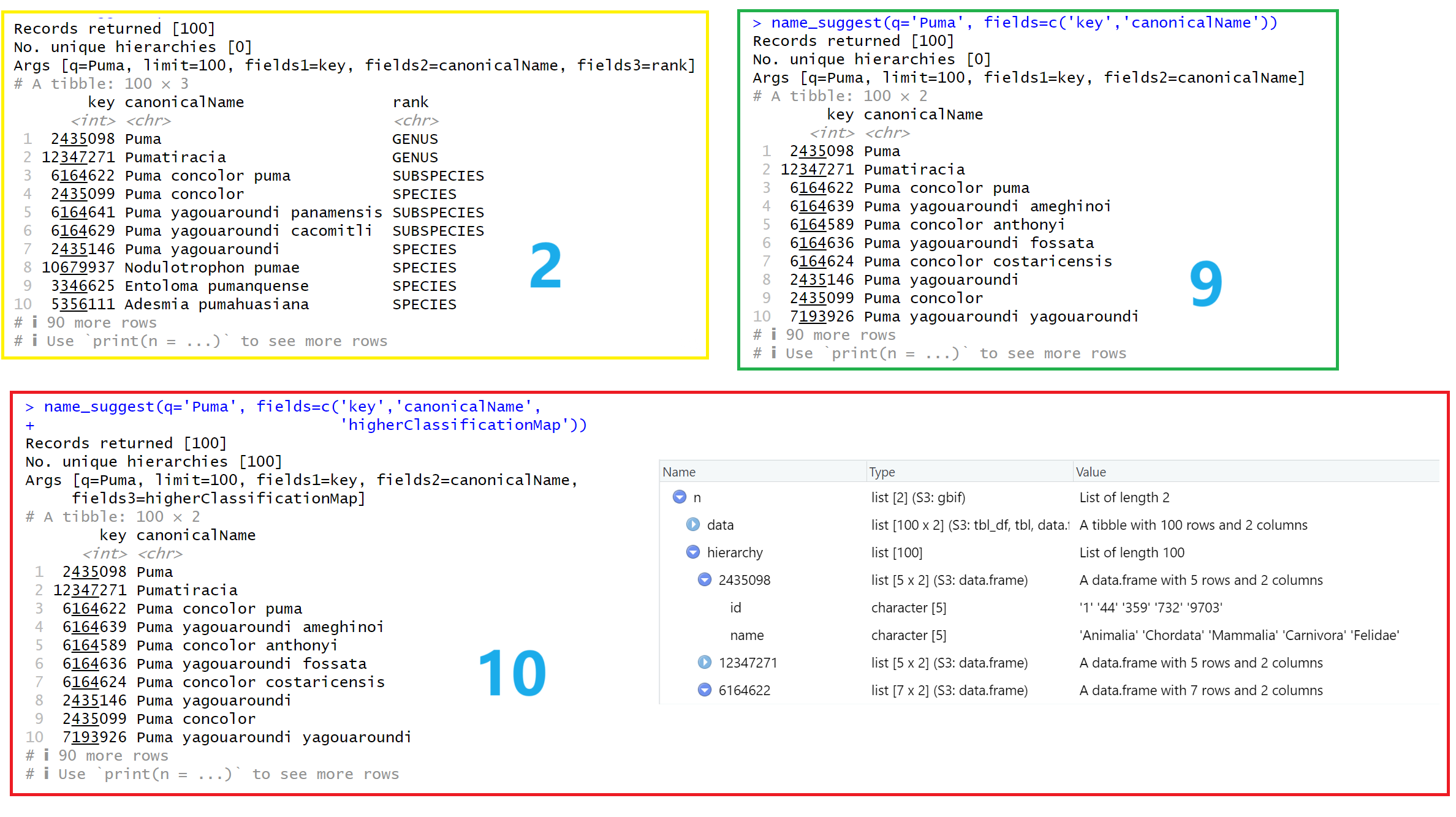
例9,10结果分析:例9的结果很容易理解。但是例10在控制台输出的结果中,并未出现有关higherClassificationMap列的信息。将例10的结果保存在变量中查看,发现higherClassificationMap列储存在名为hierarchy的数据框中,其中每条数据包含的是完整的分类阶元树及对应的标识符。
3.5 参数【datasetKey】
此参数意味着将在指定的数据子集中进行操作。
这里我们尝试输入一个子集的标识符:
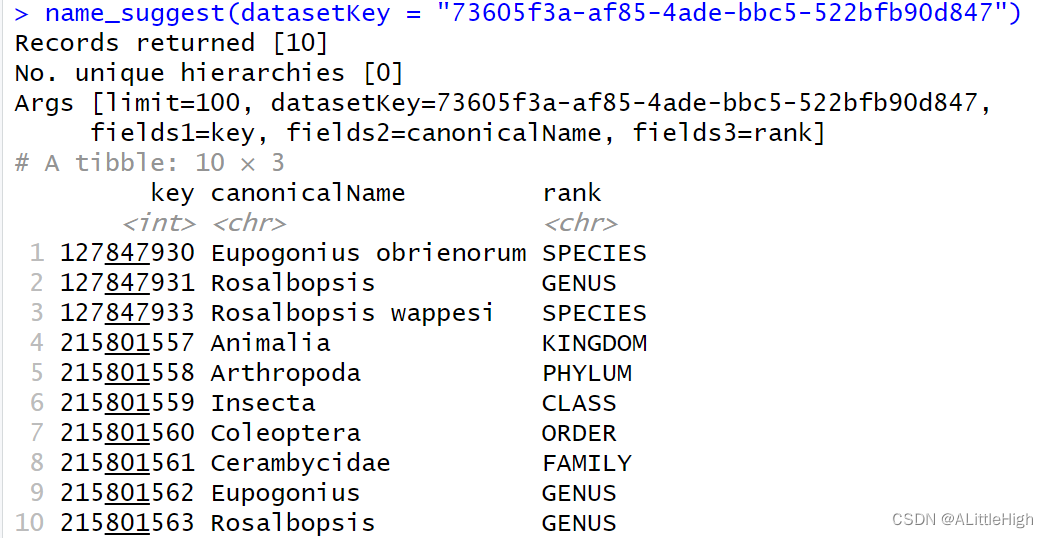
73605f3a-af85-4ade-bbc5-522bfb90d847
例11:name_suggest(datasetKey = "73605f3a-af85-4ade-bbc5-522bfb90d847")
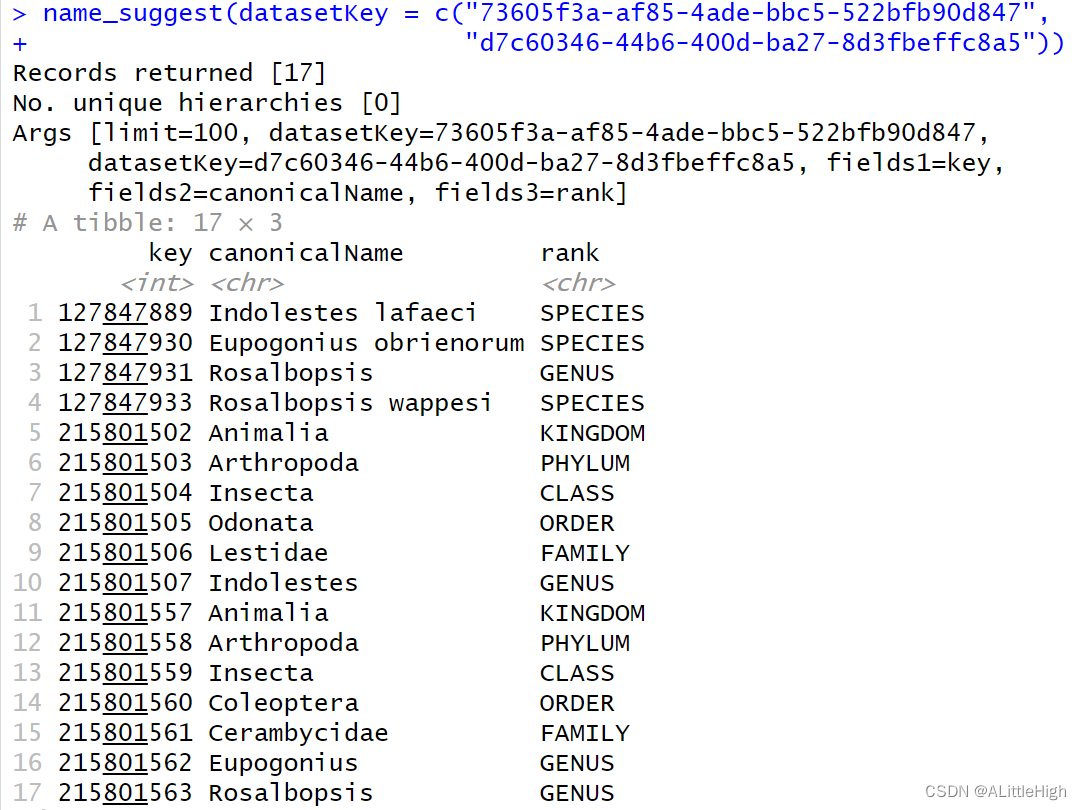
特殊情况:参数【datasetKey】支持一次输入多个子集标识符,比如:name_suggest(datasetKey = c("73605f3a-af85-4ade-bbc5-522bfb90d847", "d7c60346-44b6-400d-ba27-8d3fbeffc8a5"))
3.6 参数【curlopts】
此参数已经脱离了GBIF的范围,在调试时有较大的用处。
比如:name_suggest(q='Puma', limit=200, curlopts = list(verbose=TRUE))
运行上述代码后,控制台中会显示网络请求的一些详情。