深度学习工具链名词解释
| 更新时间 | 更新内容 |
| 2022年12月29日 | 初始化 |
这个是实习的时候自己做的笔记,这里重新整理成文档。需要具有最基本的 CNN 深度学习基础,我的上一篇文章就够了。主要是为了做毕设。
数据工具和框架
数据建模
- 数据:经过基础的讲解,我们已经知道所有的深度学习任务的数据输入和输出都可以降维到一维,只不过这个降维和恢复的过程我们另外再决定怎么解释他就行了。(考虑为做一次 reinterpret_cast)
- 模型、训练和推理:经过训练获得一个网络中的各个参数,打包成一个模型,用这个模型(一个函数)去做推理从输入到输出结果。
- Python list:CPython 的实现中 list 是 array of pointer
- ndarray:numpy 的数据结构是一个 value semantic 的一维数组,因为具有 shape 属性(决定怎么 interpret)所以可以做做 reshape 和切片。
- tensor:tensor 是比 ndarray 更高级的深度学习框架中对数据矩阵的抽象(tensorflow 中提出的)。tensor 在 tensorflow 中是 immutable 的(在 pytorch 中是 mutable 的,具体实现是),他是一种抽象,具体的数据不一定在内存中,而是可以部署到 TPU/GPU 中,他同样可以做 reshape(shape 只是决定怎么解释一维数组而已)。

深度学习库与框架
- 优化器:优化器是为了加速模型的训练/推理,人们提出一些算法比如 SGD 等数学上对模型的训练/推理过程做一定的优化,pytorch 中也支持这一部分,使得优化也是即插即用的。
- 模型:pth 模型的具体内容就是吧 pytorch 里面的数据序列化存起来,里面有模型结构(有向图)及其参数、有优化器参数等东西。
- numpy 和 pytorch:numpy/eigen 是矩阵运算库,一般是纯 CPU 的,会用 CPU 的 SIMD 加速。而 cuda 则是 Compute Unified Device Architecture ,NV 的一种运算架构,NV 提供了 cuda C API(只是用 C 语言作为前端,比如 CPU 的 C 语言程序会被编译特定CPU架构的二进制代码),实际是编译成调用 NV 驱动的某种中间表示,需要用 nvcc 编译。GPU 加速的矩阵运算有 cupy。
- Tensorflow 和 pytorch:Tensorflow 是一开始 Google 开源的基于概念 tensor 和 flow,Pytorch 是后来 facebook 开源的。模型的表示方式都是 DAG 。
- TensorRT 是对 DAG 进行类似 spark 的一些优化,然后可以有损或者无损地精简模型。
数据相关
Embedding
一种信息的编码方案,一般来说,我们知道所有数据都可以用一向箔来降维,高维原始数据(图像,句子)映射到低维流形,使得高维的原始数据被映射到低维流形之后变得可分,而这个映射就叫嵌入(Embedding)。比如Word Embedding,就是把单词组成的句子映射到一个表征向量。现在 embedding 变成一个物品名词,指代特征向量(知乎)
batch、epoch、iteration
- epoch:一代
- iteration:用一个batch 来对模型更新一次参数是一个 iteration。
- batch:一批数据
基本计算机数学方法
自动求导 AD
自动求导是区别于数值求导(lim,一般来说是一种不断近似的)的一种求导方式,AD 是基于链式法则的符号求导,通过把所有的函数抽象为一个算子(operator)和链式法则,就能适用程序构建 DAG 分解出函数链条以及链条的结合方式来应用不同的法则。每个 OP 在加入模型的 DAG 的时候,同时注册一下自己的 gradient op(如:加入一个 op1 为 identical mapping,其 gradient op 为 1),然后做 AD 的时候查表应用法则就行了。
优化方法和优化器
一般来说,训练开始的时候:
- 所有参数各自初始化选一个垃圾参数。
- 输入所有的训练数据算出结果,然后利用这些结果去做 BP,使得整体的 Σ |yi - ri|
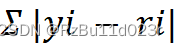 (lost 的一个直觉比喻)达到一个下降的效果的那个方向根据一定的步长(学习率)去变化参数。
(lost 的一个直觉比喻)达到一个下降的效果的那个方向根据一定的步长(学习率)去变化参数。
上面说的这种是 Batch Gradient Descent,这里的 batch 是全部一批而不是分批的意思。但是如果我们一次要走完所有的数据,梯度下降的速度会很慢,因此有 SGD 算法来说每次随机选一个来做 BP( CNN 中的比喻) 更新参数。
- SGD(Stochastic Gradient Descent):随机梯度下降是区别于理论中求导家 BP 的机械思路,通过用随机一个数据来做梯度下降,而不是每次跑一整个 dataset 来做 BP。
- Mini-batch:选一个子集来做梯度下降。
但是 SGD/mini-batch 这种还有一个问题的局部性太强了,因此又提出能不能结合以前的,加权一下?
- Momentum:动量的比喻,保留上一 batch GD 的运动趋势来走这一次的 GD。下图展示一个效果:
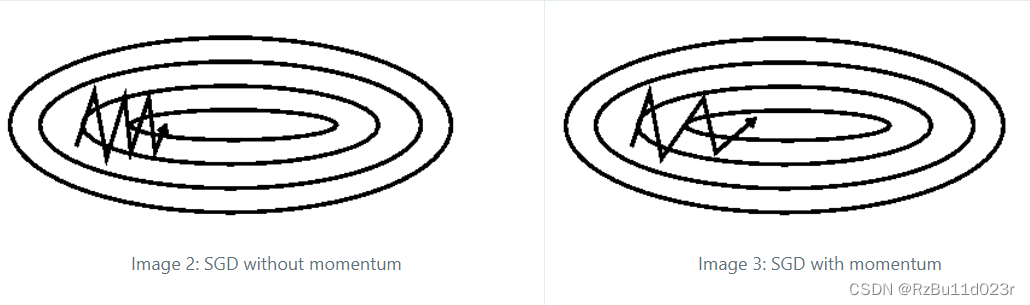
https://ruder.io/optimizing-gradient-descent/index.html#momentum
还有很多其他的优化地方,其他的优化方法,但是我就只讲到这里了,你只需要知道这些东西就是各种 play 的试炼场,缺什么补什么,哪个好用哪个。
Softmax
Softmax是一种激活函数,它可以将一个数值向量归一化为一个概率分布向量,且各个概率 之和为1。Softmax可以用来作为神经网络的最后一层,用于多分类问题的输出。
以深度学习鼻祖mnist 手写数字识别为粒子,最后网络训出来的输出值可能是些臭鱼烂虾(别忘了 ReLU 的输出是什么臭鱼烂虾数据,虽然现在基本都用 relu sigmoid 这些),所以最后一层我们可以加一个 softmax,当然如果全部用 Softmax,又卡死你:

经典模型结构
经典模型我这里从 CNN 开始。理论则是基本原理一文中只涉及到最基本的 build from scratch 的理论,而这里加入一些深度学习工业化火热后领域内的常识。
CNN (分类器、图像生成)
通过卷积对图片的 channels 做特征提取,参数随机初始化后,前向计算出预测结果,结合实际标注算 cost,然后反向传播修正参数。可解释性:卷积就像人眼从图片提取特征,然后用 ReLU 这些激活函数构建一个特征的过滤器。
CNN 除了用于分类,还有图像生成中的风格迁移、滤镜化等也很有效,这种由原图生成近似图像的时候,CNN 本身卷积生成结果的过程其实可以认为是一种滤波,只要参数够多,网络够大,一个 CNN 看作一种滤波器就能理解了。
第二个就是对于比如从无到有的生成,CNN 的训练过程中有大量的卷积从训练集中提取了海量特征,只要参数足够多,这些特征都能用于生成以假乱真图片。
RNN Recurrent NNs (seq2seq、标注、时序生成)
CNN 没有时序。RNN 的后来改进者是 LSTM Long short-term memory。主要是加入一个前后相关内容的传播链条。以一个 NLP 翻译为例,我涂鸦了一下知友的图,其中(a,b,c,d) 是词向量:

LSTM神经网络输入输出究竟是怎样的?
很显然,RNN 的处理并行度(推理和训练都)会相对 CNN 有显著下降,因此需要更高性能。
当然,一开始 RNN 是考虑时序数据这种,但是实际对 NLP,也无法避免倒装,语句排列循序并不一定是因果的。简单的想法是再倒着做一次 RNN,但是实际不行,因为我们希望一致的结果,所以实际我们需要做一些改善,其实有正的,也就可以有反的。实际我们对于翻译的,把隐状态的单向剪头改成双向(bidirectional RNN)的就行了。
LSTM 就是通过加入一些复杂的输出、加入遗忘机制等方法支持长时间和短时间并存。
GAN (生成)
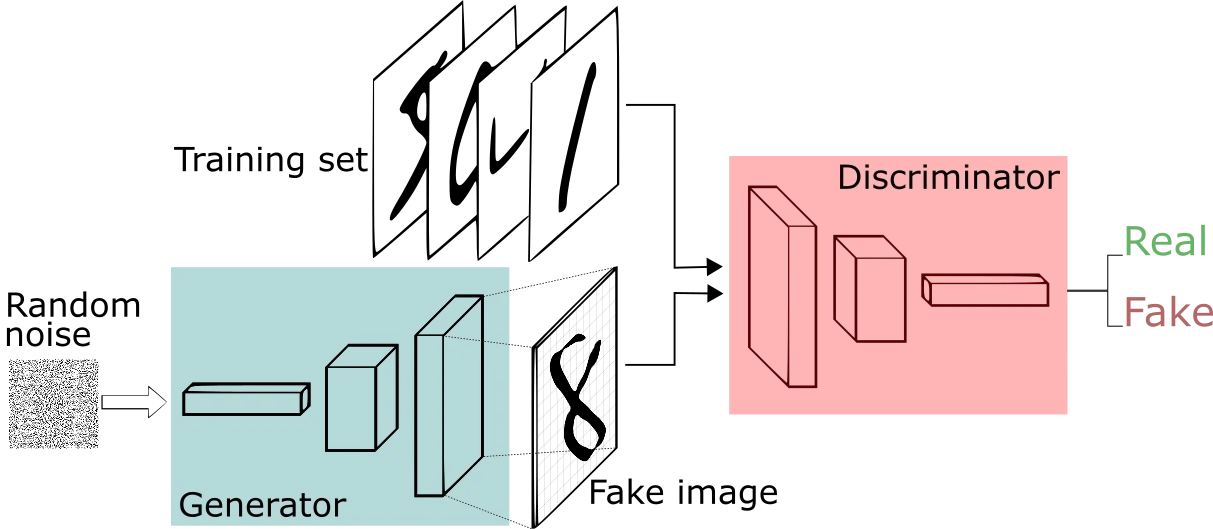
GAN 是一种网络结构,通过同时训练一个 Discriminator 和 Generator 然后让他们对抗(固定一个去训练另一个)。其中 Discriminator 和 Generator 可以用传统的 CNN、RNN 及其各种改进品,毕竟都是输入某些东西然后输出某些东西。
Transformer/attention(seq2seq)
Transformer 是 Google 发布的论文《Attention is All you Need》 中的模型,主要服务 NLP。还记得前面 RNN 的问题吗,他并行度很低,而 transformer 试图解决 RNN 的其他问题的同时,顺便解决这一性能问题。
这里复习编译原理的一般编译过程:SRC--encode-->IR--decode--->DST。这里 encode 和 decode 只是区分两个环节。
有大佬写了文章(英语):The Illustrated Transformer。但是我觉得还是难读懂。我依然涂鸦一下他的图片。好帮助我们一眼看出发生了什么。
首先是理解 RNN 为什么并行度慢?

这里,我给实际运行的时候的顺序加了需要,不一定是真实模型的效果。注意这里 1-2-3 中实际是有很多层的神经连接的。然后 5-6-7 中,由于 7 依赖 6, 6依赖 4,4 依赖 1-2,所以 1-2-3 和 5-6-7 很明显是需要有先后顺序的。
然后我们看 Transformer 中的主体模型,encoder 和 decoder 的圈圈是分别的内部详细图,我把他们贴到一起了,这里照搬大佬的图,示例为 NLP 中的机器语言翻译,经典 seq2seq:
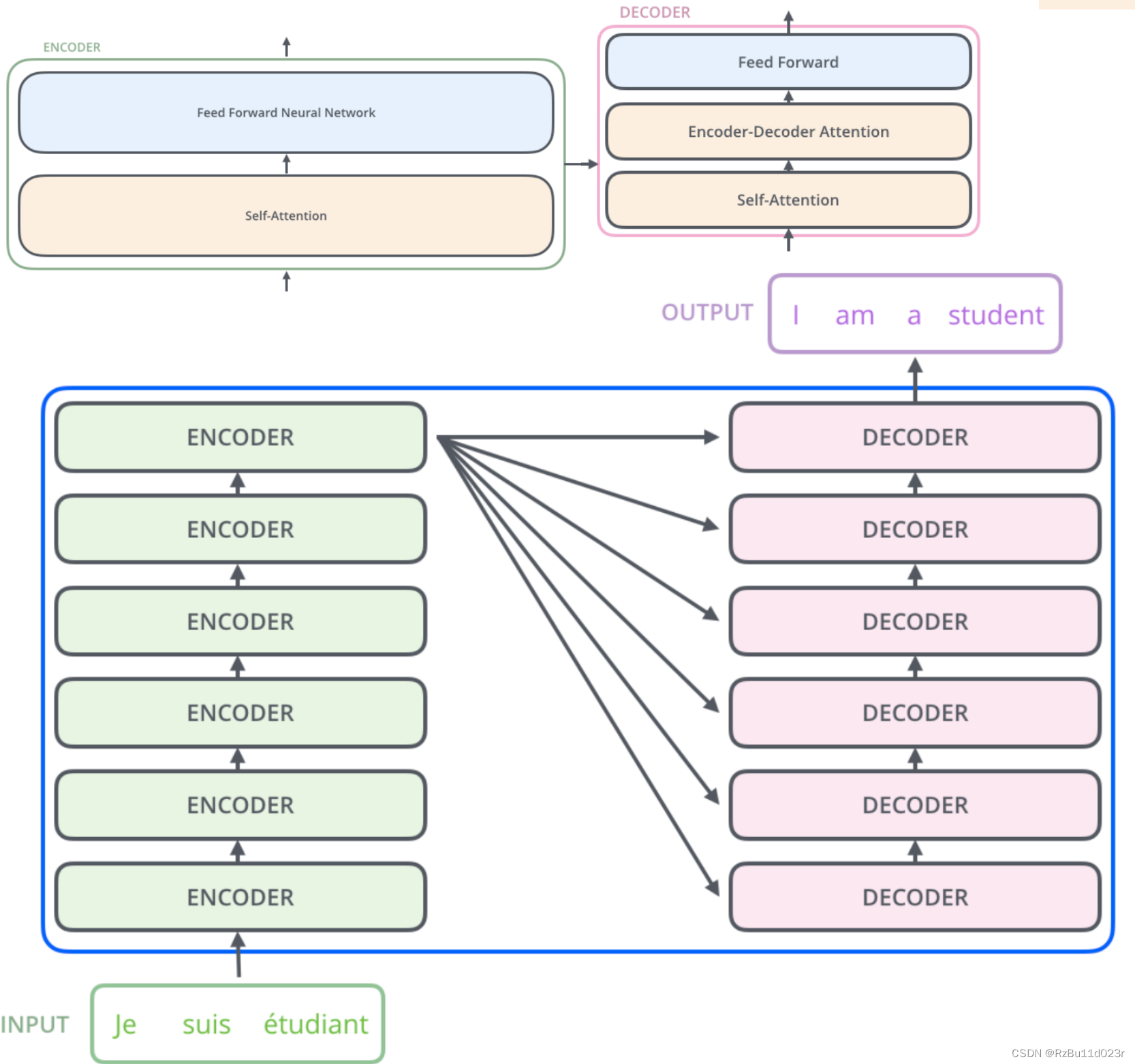
我们需要关注 encoder 的细节中,有一个 self-attention 和 feed forward neural net,这里 feed forward neural net 就是把一部分 NN 的运算拆开了,然后我们就会明白这样做的好处——提高很多并行度。

此时再复习 RNN 中的依赖,一种直接的思路是,由于依赖都是隐状态引发的,我们是不是就是提前把隐状态相关的东西都算出来,然后再并行话其他的神经连接运算。
为了直觉理解,我这里先画一个极其简化的 transformer:
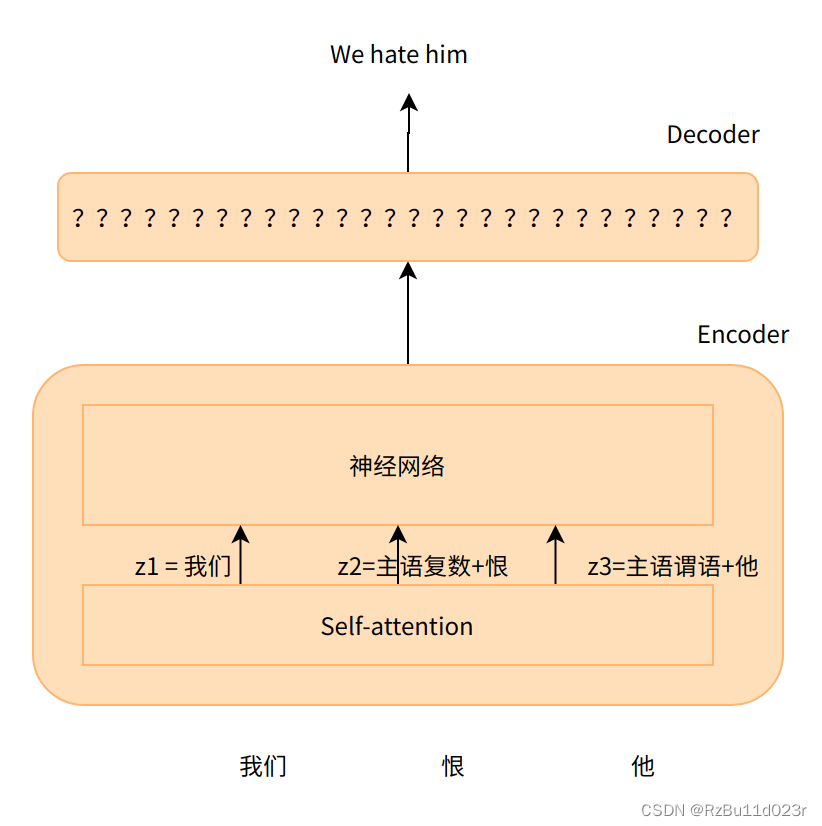
然后还有作者帮助理解的一个图片,我把修改了一点,图中的 Z对应上面 Encoder 中 self-attention 的输出 Z 向量:

至于这里的 self attention 是怎么运算的?我们以思想实验带过就行了:构建一种数学过程,其中有很多的参数待填入,这个数学过程能够完成我们的目标,然后我们梯度下降训练出所有的参数。所以懂了吗?因此如果你需要给你的模型加入一种 Attention 机制,你只需要知道你在哪里加(热插),至于 Attention 从”直观可理解性“上来说到底要注意些啥,怎么注意,各个注意的权重,完全是训练出来的。
当然,这样并不是 transformer 完整的可解释性,因为我们知道 Transformer 中的这个无论是 encoder 还是 decoder 都是一叠上去的:

不过这些从简单的可解释小 Op /模型结构到复杂堆叠结构丢失一些“人类直觉理解”他学会的是什么,他注意到的是什么这种“直觉”解释性的丢失,我们已经在 CNN 、RNN及他们的一系列变种中领悟过了。至于这里的 Attention 操作本身是怎么运算的,已经不属于这篇速览名词解释的部分了。所幸现在有了框架,这些东西不过是一个 Python 语句的热插拔而已......
预训练模型和 BERT Bidirectional Encoder Representations from Transformers
预训练是指预先训练的一个模型或者指预先训练模型的过程,微调是指将预训练过的模型作用于自己的数据集,并参数适应自己数据集的过程。最经典的比如你用 ImageNet 训练的一个很大的多物品分类模型来微调做一个适合自己只需要分类猫狗的分类器。
Bert 是一个 Google 多层 Transformer 堆叠的一个预训练模型。在谷歌的基础上,很容易微调在各种任务上达到一些非常好的效果。
结尾
还剩下的内容有目标检测的 Yolo。以及最近大火的语言大模型(GPT)、Diffusion 生成模型。还有就是多模态相关的内容。这些我认为已经不适合放在基础篇了,之后会各自开专题。
当然,我短时间内也不会写和数学有关的内容的,一旦扯上数学这种人类创建的形式系统游戏,再多的时间也会被消耗殆尽,所以在这些基础系列中我坚定地一个数学公式也不会推的。
至于如果理解和应用的过程中,如果实在需要具体的数学细节的时候,我会出新的系列把相关的数学内容也全部理解 from scratch。