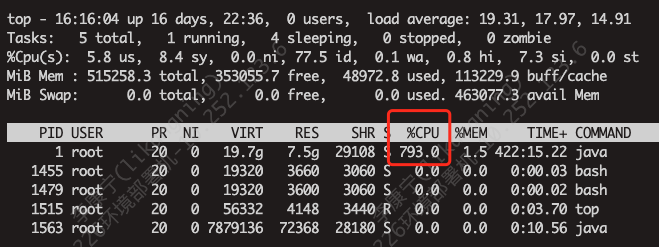
数据挖掘
v3
UIM:无标注数据挖掘方案
UIM(Unlabeled Images Mining)是一种非常简单的无标注数据挖掘方案。核心思想是利用高精度的文本识别大模型对无标注数据进行预测,获取伪标签,并且选择预测置信度高的样本作为训练数据,用于训练小模型。使用该策略,识别模型的准确率进一步提升到79.4%(+1%)。实际操作中,我们使用全量数据集训练高精度SVTR-Tiny模型(acc=82.5%)进行数据挖掘,点击获取模型下载地址和使用教程。
v4
DF:数据挖掘方案
DF(Data Filter) 是一种简单有效的数据挖掘方案。核心思想是利用已有模型预测训练数据,通过置信度和预测结果等信息,对全量的训练数据进行筛选。具体的:首先使用少量数据快速训练得到一个低精度模型,使用该低精度模型对千万级的数据进行预测,去除置信度大于0.95的样本,该部分被认为是对提升模型精度无效的冗余样本。其次使用PP-OCRv3作为高精度模型,对剩余数据进行预测,去除置信度小于0.15的样本,该部分被认为是难以识别或质量很差的样本。 使用该策略,千万级别训练数据被精简至百万级,模型训练时间从2周减少到5天,显著提升了训练效率,同时精度提升至72.7%(正负1.2%)。
数据增强
TIA是一种针对场景文字的数据增强方法,它在图像中设置了多个基准点,然后随机移动点, 通过几何变换生成新图像,这样大大提升了数据的多样性以及模型的泛化能力.

TextConAug:挖掘文字上下文信息的数据增广策略
TextConAug是一种挖掘文字上下文信息的数据增广策略,主要思想来源于论文ConCLR,作者提出ConAug数据增广,在一个batch内对2张不同的图像进行联结,组成新的图像并进行自监督对比学习。PP-OCRv3将此方法应用到有监督的学习任务中,设计了TextConAug数据增强方法,可以丰富训练数据上下文信息,提升训练数据多样性。使用该策略,识别模型的准确率进一步提升到76.3%(+0.5%)。TextConAug示意图如下所示:
超参数
v1
学习率策略:在识别模型训练中,学习率下降策略与文本检测相同,也使用了Cosine+Warmup的学习率策略。
v3
TextConAug:挖掘文字上下文信息的数据增广策略
TextConAug是一种挖掘文字上下文信息的数据增广策略,主要思想来源于论文ConCLR,作者提出ConAug数据增广,在一个batch内对2张不同的图像进行联结,组成新的图像并进行自监督对比学习。PP-OCRv3将此方法应用到有监督的学习任务中,设计了TextConAug数据增强方法,可以丰富训练数据上下文信息,提升训练数据多样性。使用该策略,识别模型的准确率进一步提升到76.3%(+0.5%)。
预训练
v3
TextRotNet:自监督的预训练模型
TextRotNet是使用大量无标注的文本行数据,通过自监督方式训练的预训练模型,参考于论文STR-Fewer-Labels。该模型可以初始化SVTR_LCNet的初始权重,从而帮助文本识别模型收敛到更佳位置。使用该策略,识别模型的准确率进一步提升到76.9%(+0.6%)。
主干
v1
图像提取部分是MobileNetv3
特征图降采样策略
骨干网络一般都是使用的图像分类任务中的骨干网络,它的 输入分辨率一般设置为224x224,降采样时,一般宽度和高度会同时降采样。 但是对于文本识别任务来说,由于输入图像一般是32x100,长宽比非常不平衡,此时对宽度和高度同时降采样,会导致特征损失严重,因此图像分类任务中的骨干网络应用到文本识别任务中需要进行特征图降采样方面的适配。
基于 CTC(Connectionist Temporal Classification) 最典型的算法是CRNN (Convolutional Recurrent Neural Network),它的特征提取部分使用主流的卷 积结构,常用的有ResNet、MobileNet、VGG等。由于文本识别任务的特殊性,输入数据中存在大量的上下文信 息,卷积神经网络的卷积核特性使其更关注于局部信息,缺乏长依赖的建模能力,因此仅使用卷积网络很难 挖掘到文本之间的上下文联系。为了解决这一问题,CRNN文本识别算法引入了双向 LSTM(Long Short-Term Memory) 用来增强上下文建模,通过实验证明双向LSTM模块可以有效的提取出图片中的上下文信息。最终 将输出的特征序列输入到CTC模块,直接解码序列结果。该结构被验证有效,并广泛应用在文本识别任务中。
v2
PP-LCNet轻量级骨干网络
PP-LCNet了一种基于 MKLDNN 加速策略的轻量级 CPU 主干网络,大幅提高了轻量级模型在 图像分类任务上的性能,对于计算机视觉的下游任务,如文本识别、目标检测、语义分割等,有很好的表现。 这里需要注意的是,PP-LCNet是针对 CPU+MKLDNN 这个场景进行定制优化,在分类任务上的速度和精度 都远远优于其他模型.
v3
SVTR_LCNet:轻量级文本识别网络
SVTR_LCNet是针对文本识别任务,将基于Transformer的SVTR网络和轻量级CNN网络PP-LCNet 融合的一种轻量级文本识别网络。使用该网络,预测速度优于PP-OCRv2的识别模型20%,但是由于没有采用蒸馏策略,该识别模型效果略差。此外,进一步将输入图片规范化高度从32提升到48,预测速度稍微变慢,但是模型效果大幅提升,识别准确率达到73.98%(+2.08%),接近PP-OCRv2采用蒸馏策略的识别模型效果。
GTC:Attention指导CTC训练策略
GTC(Guided Training of Connectionist Temporal Classification),利用Attention模块CTC训练,融合多种文本特征的表达,是一种有效的提升文本识别的策略。使用该策略,预测时完全去除 Attention 模块,在推理阶段不增加任何耗时,识别模型的准确率进一步提升到75.8%(+1.82%)。
v4
Multi-Scale:多尺度训练策略
动态尺度训练策略,是在训练过程中随机resize输入图片的高度,以增强识别模型在端到端串联使用时的鲁棒性。在训练时,每个iter从(32,48,64)三种高度中随机选择一种高度进行resize。实验证明,使用该策略,尽管在识别测试集上准确率没有提升,但在端到端串联评估时,指标提升0.5%。
SVTR_LCNetV3:精度更高的骨干网络
PP-LCNetV3系列模型是PP-LCNet系列模型的延续,覆盖了更大的精度范围,能够适应不同下游任务的需要。PP-LCNetV3系列模型从多个方面进行了优化,提出了可学习仿射变换模块,对重参数化策略、激活函数进行了改进,同时调整了网络深度与宽度。最终,PP-LCNetV3系列模型能够在性能与效率之间达到最佳的平衡,在不同精度范围内取得极致的推理速度。
GTC-NRTR:稳定的Attention指导分支
GTC(Guided Training of CTC),是PP-OCRv3识别模型的最有效的策略之一,融合多种文本特征的表达,有效的提升文本识别精度。在PP-OCRv4中使用训练更稳定的Transformer模型NRTR作为指导分支,相比V3版本中的SAR基于循环神经网络的结构,NRTR基于Transformer实现解码过程泛化能力更强,能有效指导CTC分支学习,解决简单场景下快速过拟合的问题。使用Lite-Neck和GTC-NRTR两个策略,识别精度提升至73.21%(+0.5%)。
head+FPN
v1:
轻量级头部结构
CRNN中,用于解码的轻量级头(head)是一个全连接层,用于将序列特征解码为普通的预测字符。序列特征的 维数对文本识别器的模型大小影响非常大,特别是对于6000多个字符的中文识别场景(序列特征维度若设置 为256,则仅仅是head部分的模型大小就为 6.7M)。在PP-OCR中,针对序列特征的维度展开实验,最终 将其设置为48,平衡了精度与效率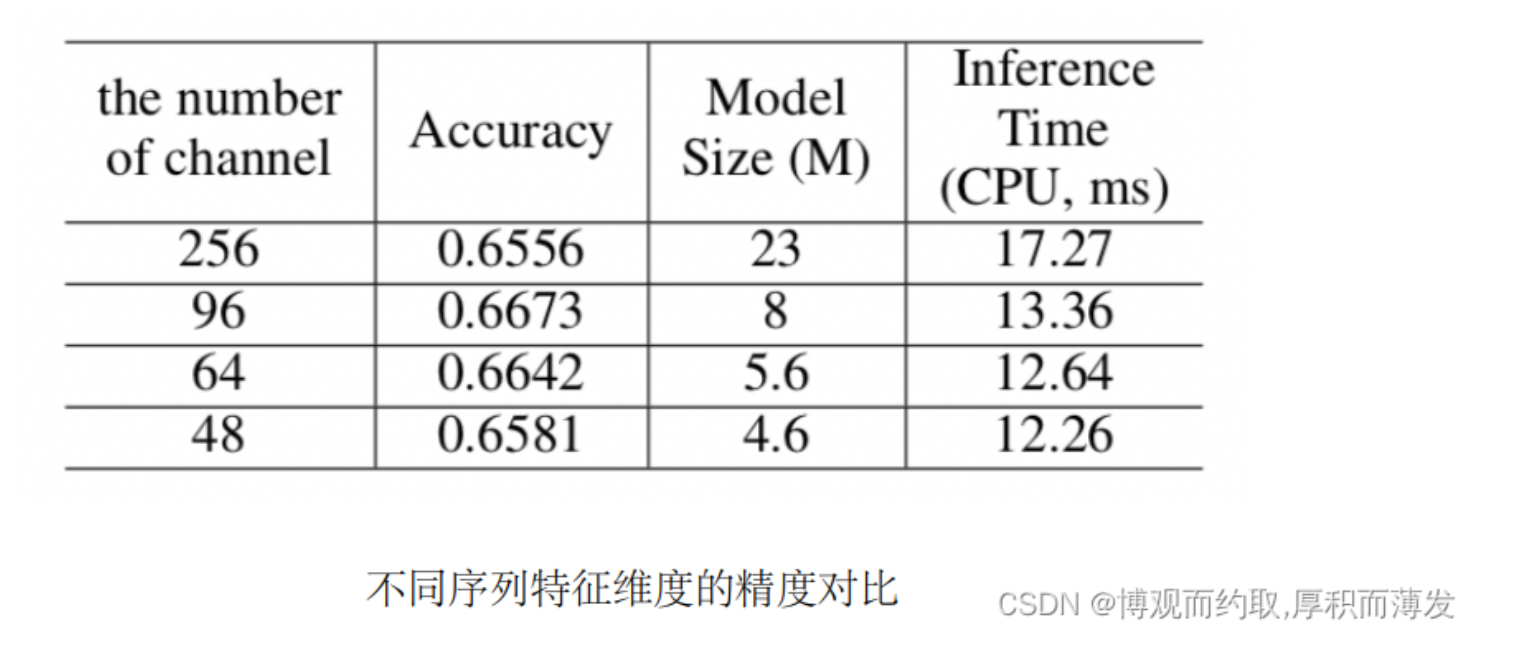
v4:
Lite-Neck:精简的Neck结构
Lite-Neck整体结构沿用PP-OCRv3版本的结构,在参数上稍作精简,识别模型整体的模型大小可从12M降低到8.5M,而精度不变;在CTCHead中,将Neck输出特征的维度从64提升到120,此时模型大小从8.5M提升到9.6M。
损失函数
v1
损失函数:正则化是一种广泛使用的避免过度拟合的方法,一般包含L1正则化和L2正则化。在大多数使用场景中,都使用L2正则化。它主要的原理就是计算网络中权重的L2范数,添加到损失函数中。在L2正则化的帮助下, 网络的权重趋向于选择一个较小的值,最终整个网络中的参数趋向于0,从而缓解模型的过拟合问题,提高 了模型的泛化性能。
v2
Enhanced CTC loss 改进
中文 OCR 任务经常遇到的识别难点是相似字符数太多,容易误识。借鉴 Metric Learning 中的想法,引入 Center loss,进一步增大类间距离,核心公式如下所示。
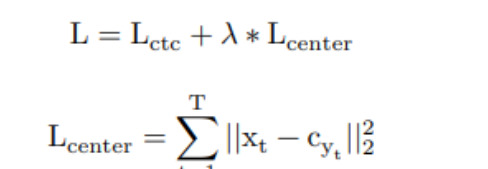
这里 xt 表示时间步长 t 处的标签,cyt 表示标签 yt 对应的 center。
Enhance CTC 中,center 的初始化对结果也有较大影响,在 PP-OCRv2 中,center 初始化的具体步骤如下所示。
1. 基于标准的 CTC loss,训练一个网络;
2. 提取出训练集合中识别正确的图像集合,记为 G ;
3. 将 G 中的图片依次输入网络,提取head输出时序特征的 xt 和 yt 的对应关系,其中 yt 计算方式如下:
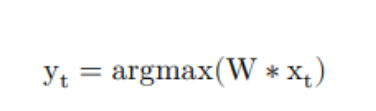
4.将相同 yt 对应的 xt 聚合在一起,取其平均值,作为初始 center
模型调整(剪枝、量化、知识蒸馏)
v1
PACT 在线量化策略
采用与方向分类器量化类似的方案来减小文本识别器的模型大小。由于LSTM量化的复杂性,PP-OCR中 没有对LSTM进行量化。使用该量化策略之后,模型大小减小 67.4%、预测速度加速 8%、准确率提升 1.6%, 量化可以减少模型冗余,增强模型的表达能力。
v2
U-DML 知识蒸馏策略
对于标准的 DML 策略,蒸馏的损失函数仅包括最后输出层监督,然而对于 2 个结构完全相同的模型来说,对 于完全相同的输入,它们的中间特征输出期望也完全相同,因此在最后输出层监督的监督上,可以进一步添 加中间输出的特征图的监督信号,作为损失函数,即 PP-OCRv2 中的 U-DML (Unified-Deep Mutual Learning) 知识蒸馏方法。 U-DML 知识蒸馏的算法流程图如下所示。Teacher 模型与 Student 模型的网络结构完全相同,初始化参数不 同,此外,在新增在标准的 DML 知识蒸馏的基础上,新增引入了对于 Feature Map 的监督机制,新增 Feature Loss。
v3
UDML:联合互学习策略
UDML(Unified-Deep Mutual Learning)联合互学习是PP-OCRv2中就采用的对于文本识别非常有效的提升模型效果的策略。在PP-OCRv3中,针对两个不同的SVTR_LCNet和Attention结构,对他们之间的PP-LCNet的特征图、SVTR模块的输出和Attention模块的输出同时进行监督训练。使用该策略,识别模型的准确率进一步提升到78.4%(+1.5%)。
v4
DKD :DKD蒸馏策略
识别模型的蒸馏包含两个部分,NRTRhead蒸馏和CTCHead蒸馏;
对于NRTR head,使用了DKD loss蒸馏,拉近学生模型和教师模型的NRTR head logits。最终NRTR head的loss是学生与教师间的DKD loss和与ground truth的cross entropy loss的加权和,用于监督学生模型的backbone训练。通过实验,我们发现加入DKD loss后,计算与ground truth的cross entropy loss时去除label smoothing可以进一步提高精度,因此我们在这里使用的是不带label smoothing的cross entropy loss。
对于CTCHead,由于CTC的输出中存在Blank位,即使教师模型和学生模型的预测结果一样,二者的输出的logits分布也会存在差异,影响教师模型向学生模型的知识传递。PP-OCRv4识别模型蒸馏策略中,将CTC输出logits沿着文本长度维度计算均值,将多字符识别问题转换为多字符分类问题,用于监督CTC Head的训练。使用该策略融合NRTRhead DKD蒸馏策略,指标从74.72%提升到75.45%