本文主要参考:Domain Generalization: A Survey
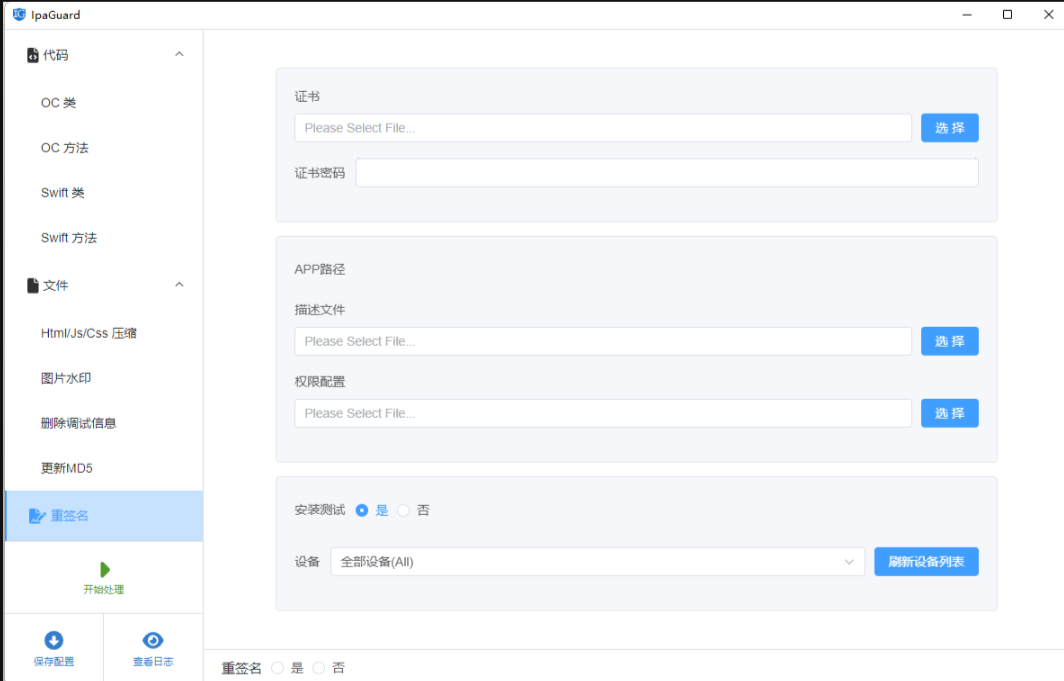
Problem Definition
在DG的setting中,我们通常能拿到 K ( K ≥ 1 ) K(K\ge 1) K(K≥1)个source domain的数据,这几个source domain相似但并不相同,记为 S = { S k = { ( x ( k ) , y ( k ) } } k = 1 K ) \mathcal{S}=\{S_k=\{(x^{(k)},y^{(k)}\}\}_{k=1}^K) S={Sk={(x(k),y(k)}}k=1K),每个source domain对应一个数据联合分布 P X Y ( k ) P_{XY}^{(k)} PXY(k),注意各个source domain的这个联合分布是不相同的。而DG的任务则是通过学习这几个source domain S \mathcal{S} S的数据,得到模型 f : X → Y f:\mathcal{X}\rarr\mathcal{Y} f:X→Y,使得模型在target domain T = { x T } \mathcal{T}=\{x^{\mathcal{T}}\} T={xT}上的loss最小。同样地, T \mathcal{T} T中数据的联合分布 P X Y T ≠ P X Y ( k ) , ∀ k ∈ { 1 , ⋯ , K } P_{XY}^{\mathcal{T}}\neq P_{XY}^{(k)}, \forall k\in \{1,\cdots, K\} PXYT=PXY(k),∀k∈{1,⋯,K}。
Methodology
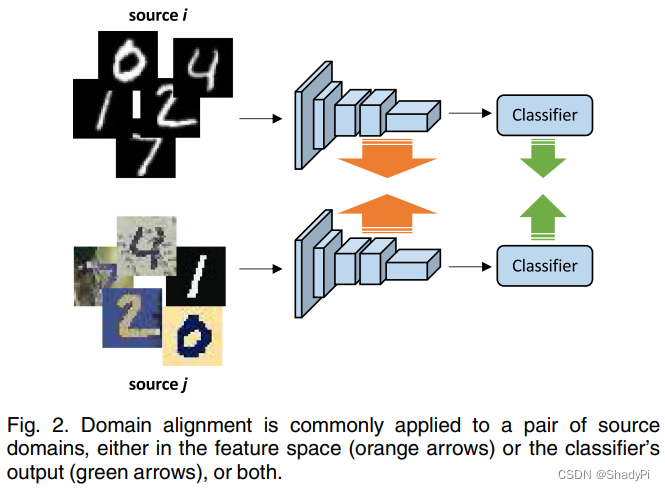
Domian Alignment
大部分DG算法都属于这个分支,domain alignment的目的是最小化不同source domain之间的区别,让模型学习到不随domain变化的表征,并假设不随source domain变化的特征也应当在target domain里保持不变。
为了衡量分布之间的差异性,有很多定量算法被提出,比如 l 2 l_2 l2 distance、 f − d i v e r g e n c e s f-divergences f−divergences和Wasserstein distance等,但domain alignment需要先确定两个核心问题,对齐什么(What to Align)以及怎么对齐(How to Align)。
What to Align
一个source domain数据的联合分布
P
(
X
,
Y
)
P(X,Y)
P(X,Y)可以如下表示
P
(
X
,
Y
)
=
P
(
Y
∣
X
)
P
(
X
)
=
P
(
X
∣
Y
)
P
(
Y
)
\begin{aligned} P(X,Y)=P(Y|X)P(X)\\ =P(X|Y)P(Y) \end{aligned}
P(X,Y)=P(Y∣X)P(X)=P(X∣Y)P(Y)由于很多工作都假设分布偏移发生在边缘分布
P
(
X
)
P(X)
P(X),而先验概率
P
(
Y
∣
X
)
P(Y|X)
P(Y∣X)是不变的,因此他们都专注于对齐source domain的边缘分布
P
(
X
)
P(X)
P(X)。
这样的做法在 X X X为因, Y Y Y为果的情况下基本是正确的, P ( Y ∣ X ) P(Y|X) P(Y∣X)不会因 P ( X ) P(X) P(X)的改变而改变。但有时候可能 Y Y Y为因, X X X才是果,那么 P ( X ) P(X) P(X)的偏移也会影响 P ( Y ∣ X ) P(Y|X) P(Y∣X)。所以一些算法会假设 P ( Y ) P(Y) P(Y)不变,去对齐 P ( X ∣ Y ) P(X|Y) P(X∣Y)。而由于我们实际上测试的时候需要的是 P ( Y ∣ X ) P(Y|X) P(Y∣X),所以也有算法直接对齐每个类的 P ( Y ∣ X ) P(Y|X) P(Y∣X)的。
How to Align
- 最小化分布的矩,一般就考虑一阶矩(均值)和二阶矩,有只最小化其中一个的,也有两个都尝试最小化的。
- 对比学习,将数据分为锚点组(anchor group),正样本组和负样本组,要求最小化正样本和锚点的距离,同时最大化负样本和锚点的距离,这个距离是自行定义的,可以采用 l 2 l_2 l2 loss或者softmax等。
- 最小化KL散度,KL散度是一个衡量两个分布相似性的常用指标,最小化该指标使得目标分布更相似。
- 最小化 Maximum Mean Discrepancy (MMD) ,MMD也是一个散度指标,对其方法与KL散度类似,只是换了一个指标。
- 对抗学习,与GAN的思路类似。有两个模型,一个模型负责从不同的domain中提取feature,而另一个模型负责对这个feature进行分类,试图辨别出该feature原本属于哪个domain,提取模型则要想方设法骗过分类器。
- 多任务学习,直接用多个task的数据去训练,得到的模型自然也比较general。