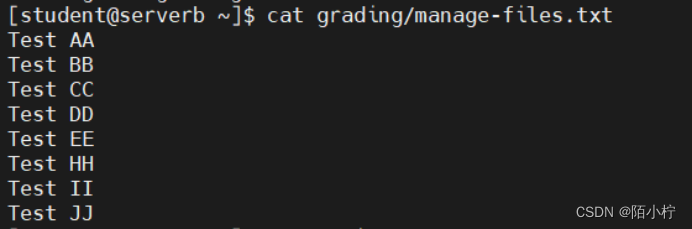
【前置目的】
识别视频中是否包含目标元素;
抽象自动化,就是处理一段含有时间戳的视频;
再核心就是对视频进行图片裁减,识别出图片中的数字,做数学计算延时。
【学习地址】
环境:mac、python3、pytesseract库
关键语句:pytesseract.image_to_string 基本语言库,可支持汉子和数字的识别
后续就是OCR流程
-
机器学习
-
图像预处理:去噪、灰度化、图像增强等
-
文本检测: 滑动窗口算法遍历整张图片
-
字符分类: 划分单个字符,识别单字
【图片例子】
time1.png
 time2.png
time2.png

time3.png time4.png
time4.png

eng.png

【代码实现】
import pytesseract
def seek_num():
text1 = pytesseract.image_to_string(Image.open("time1.png"), lang='eng')
print(text1)
识别结果:
['ITE AY (8)\n\nbe\n\n20224712 A308\n\n']
['14:08:01\n']
['14:19:17\n\nFriday, 30 December 2022\n']
['14:56:10\n']
['nn BWNY\n\nWriting a Closing\n\nWrapping Up\n\nSummarize\n\nCheck for agreement\n\nReminders\n\nThank You / congratulations/ personal messages\n\nFollow Ups\n']
查看本地语言库支持的类型目录
cd /opt/homebrew/share/tessdata/
本地支持更高低点语言库,比如lang='chi_sim’等
https://github.com/tesseract-ocr/tessdata
【延伸问题】
- pytesseract对代测图片的内容要求很高,一般带有点文字内容会识别出数字!!!
- 视频每帧输出成图片
ffmpeg -i input.mp4 -r 1 -s 1280,720 -ss 00:00:00 %d.png
- 需要用ffmpeg对图片大小进行裁剪,才难识别出具体的数字
ffmpeg -i input.png -vf crop=600:170:330:570 outpit.png
crop=W:H:X:Y参数说明
W:输出视频的宽度
H:输出视频的高度
X:开始裁剪的水平位置,从左边开始(绝对左距为0)。默认为中心(iw-ow)/2
Y:开始裁剪的垂直位置,从视频的顶部开始(绝对顶部为0)。默认为中心(ih-oh)/2
(也可以在视频剪切成每张图片之前先对视频进行裁剪)
- 对输出的内容进行替换,可能存在标点符号的问题
(勉强可用,支持了我的诉求~)



![[极客大挑战 2019]Buy Flag1(BUUCTF)](https://img-blog.csdnimg.cn/e4c32cee534e4932816d3ba0912fcc53.png)




![[虚幻引擎][UE][UE5]在UE5中使用线条画一颗简单的三维圣诞树(练习向)](https://img-blog.csdnimg.cn/68e7e5daf50a498cb07f0ef1edc6eef5.png)