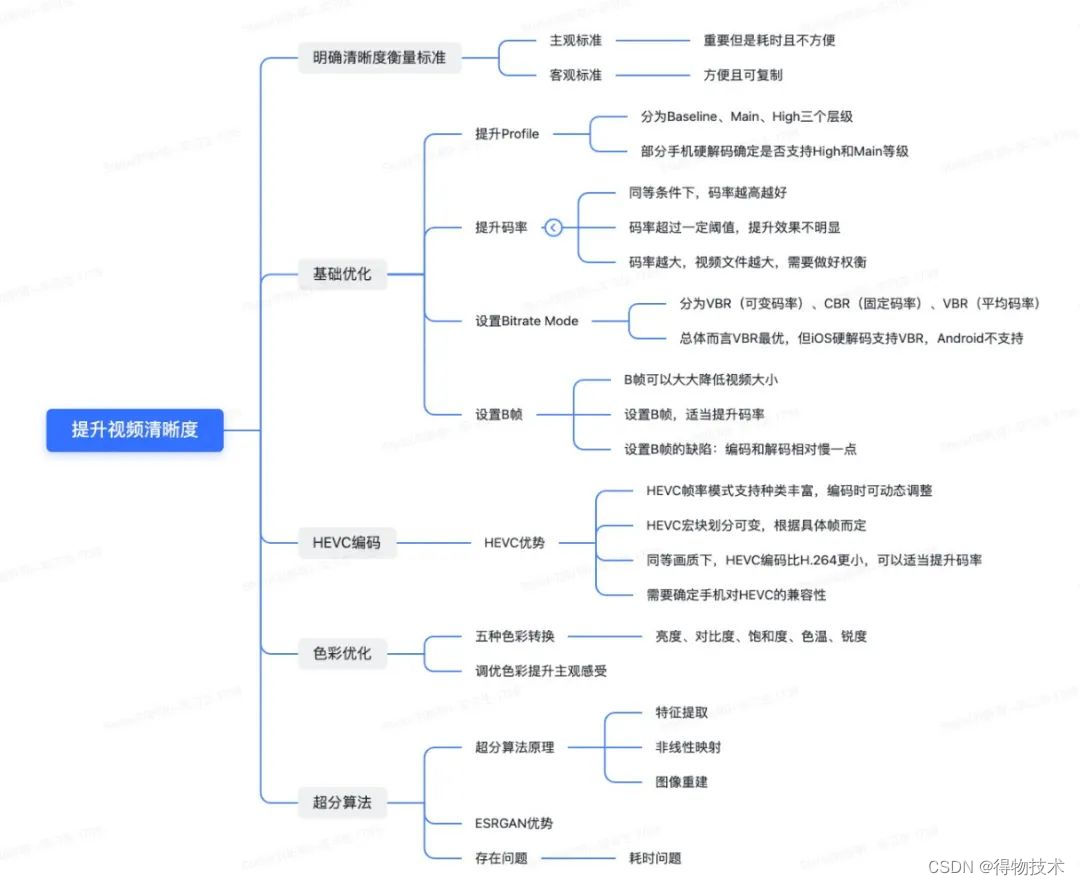
比赛背景
2021年第十六届全国人机语音通讯学术会议(National Conference on Man-Machine Speech Communication,NCMMSC2021)将于2021年10月15-18日在江苏徐州举行。本次会议由中国中文信息学会和中国计算机学会联合主办。
针对本次会议,由腾讯科技 ASR&OCR oteam联合发起围绕时下在工业界最为关注的三类媒体形式---长视频、短视频、直播场景进行比赛。
长期以来,语音关键词检测竞赛都是NIST国际评测中的经典项目,OPENKWS系列比赛 (https://www.nist.gov/itl/iad/mig/open-keyword-search-evaluation) 连续举办四届,旨在解决电话PSTN信道里,对于低资源小语种的关键词定位和识别能力。该比赛在Babel IARPA项目下,吸引了国内外30多个知名研究机构的参与和竞争,极大地促进了低资源语音内容识别的技术发展。
近年来,随着短视频、直播等应用的迅速崛起,带来了长短视频、直播音视频等新兴互联网媒介的百花齐放。各类创作模式层出不穷、创作门槛日趋平民化,导致各类长短音视频、直播流中声学场景更加复杂多变,多语种、多方言问题日益突出。围绕各类长短音视频的语音识别和内容理解任务一直以来都备受工业界关注,如何对各类视频内容进行准确转写和内容理解,成为了字幕内容创作、兴趣内容推荐、数字媒介归档等下游应用中不可或缺的利器。
因此,腾讯ASR-OCR oteam发布长短视频多语种多模态识别挑战赛,本次比赛将重点关注长短视频下的内容理解与识别,围绕时下在工业界最为关注的三类媒体形式---长视频、短视频、直播流进行。

本次比赛由易到难:
-
第一期任务将关注模型场景失配下长短视频及直播流中汉语关键词的检测问题;
-
任务二则扩展到任务一的多语种和多方言关键词检测场景;
-
任务三则会根据视频画面里的字幕OCR和语音ASR等信息,共同打造SOTA的长短视频、直播场景的多模态视频内容识别解决方案。
这里我们首先发布任务一的具体任务和比赛要求。
比赛任务
Task1,汉语长短视频直播语音关键词
(Video Keyword Wakeup Competition, VKW)
可自定义关键词唤醒能够快速检测出音视频和智能设备中的关键词(唤醒词),广泛应用在设备自定义解锁和唤醒、各类救护、火灾等紧急事件报警、命令识别、语音内容的检索和分类等任务中。
第一届 VKW(Video Keyword Wakeup Competition)任务旨在检验业界利用朗读数据等常规数据公司可获取的大规模数据构建任意自定义关键词检测系统的能力;比赛由腾讯提供少量可供微调的真实长短视频及直播数据,检验场景失配下自定义关键词检测系统的鲁棒性和泛化性。在比赛中,组委会提供1505小时普通话朗读数据(由数据堂公司提供),并提供长视频、短视频、直播场景各50小时有标注数据供场景微调,各5小时有标注数据用于在开发集关键词列表上进行系统优化和调参,各20小时有标注数据用于评价提交系统。赛后,组委会可提供原始数据、标注及关键词列表。
该比赛力求接近工业界实际场景和问题在海量大数据标注下的解决方案,同时为避免学术界和工业界因为数据量级失衡导致无法在一个起跑线进行,比赛设置了受限和非受限两个赛道。受限赛道中,只允许使用提供的1505h普通话朗读数据及各50h的长短视频、直播数据作为有监督语音训练数据,外部数据可使用开源发布的预训练模型及开源语言模型、网络爬取的文本等。可使用外部数据进行数据扩充和预训练,但不得使用外部数据的标注脚本。非受限赛道鼓励参赛队伍使用任意可公开获取的标注数据、无标注数据进一步提升系统性能,但需要在最终提交系统说明里提供数据来源(如可使用http://www.openslr.org/中的开源数据并注明数据来源)。

其次,比赛主要评价指标和国际接轨,采用了通用的NIST OPENKWS关键词评价指标ATWV。同时我们也力求该指标在工业界的可解释性,采用 Precision/Recall 和ATWV两套指标并行评价,评价公式及工具见随后发布的基线系统及具体评测计划。
比赛最终评测结果和排名,将由专家结合两者得分进行评价。最终结果宣布和排名将在ncmmsc 2021会议上公布。作为国内语音领域最大规模的盛会,2021年第十六届全国人机语音通讯学术会议(National Conference on Man-Machine Speech Communication,NCMMSC2021)将于2021年10月15-18日在江苏徐州举行,由中国中文信息学会和中国计算机学会联合主办。
Task 2: 语种多方言长短视频可自定义关键词唤醒(建设中,敬请关注)
(Low-resouce Video Keyword Wakeup Competition, LVKW)
我国是一个多语言、多方言的国家,在长视频,短视频和直播流中,下沉场景时语言的本地化现象非常明显。而通用的设备关键词唤醒往往只支持汉语。如何在多语言,多汉语方言场景下,唤醒出上述三大场景中的各类自定义关键词,是本任务的研究方向。本任务主要包括蒙、藏、维、哈、朝、彝、壮等少数民族语言,西南,中原等各类官话,晋语,吴语,徽语,湘语,粤语,赣语,闽南语,客家话等汉语方言。
比赛详细信息稍后发布,敬请期待......
Task 3: 音视频多模态文字内容识别(建设中,敬请关注)
(Video ASR OCR Competition, VAO)
在长短视频,直播等视频场景中,通常会伴有已经制作好的视频字幕,人脸存在时的唇语等辅助信息。如何利用其他模态的辅助信息提升ASR识别率,尤其是背景音乐、嘈杂噪声等低信噪比情况下,提升ASR的性能是本任务的关注点;另一方面,尽管OCR通常比ASR识别更加准确,但OCR由于画面复杂、冗余信息多(标题,台标等),对于字幕部分的提取和识别也存在较大的困难。如何利用ASR等语音信息,指导OCR进行更好的输出,使得用户“看到”真正重要的口语内容信息,使得多模态内容文字识别率互相促进并最终提升,是本任务的研究方向。
比赛详细信息稍后发布,敬请期待......
比赛算力
比赛首次引入了腾讯云进行推理,参赛者可以通过腾讯云账户进行申请,在统一申请的算力推理机器上进行推理解码,由腾讯云负责统一收集比赛结果和自动排名,保证比赛的公平性。目前,大赛报名通道已开启,本次大赛任务一的报名截至时间为9月6日,比赛结果公布时间为9月24日。参赛提交系统描述有机会收录进入人机语音通讯学术会议的论文集,对于优秀论文有机会选送到国内知名EI检索核心期刊进行发表。
腾讯云计算将作为本次竞赛独家算力支持平台,为参赛队伍提供免费的高性能云服务器资源供竞赛的数据建模与学习推理。
比赛报名及结果发布
比赛首次引入了腾讯云进行推理,参赛者可以通过腾讯云账户进行申请,在统一申请的算力推理机器上进行推理解码,由腾讯云负责统一收集比赛结果和自动排名,保证比赛的公平性。目前,大赛报名通道已开启,本次大赛任务一的报名截至时间为9月6日,比赛结果公布时间为9月24日。参赛提交系统描述有机会收录进入人机语音通讯学术会议的论文集,对于优秀论文有机会选送到国内知名EI检索核心期刊进行发表。
此次比赛每个注册成功的参赛团队可选任何一个任务参加,或同时注册两个任务。腾讯科技为比赛两个赛道获奖前三名的团队提供了数额丰富的奖金,具体金额待训练集发布时公布。
关于比赛的详细信息,报名表,请参阅网站: https://datatang.com/VMR.