【Math】高斯分布的乘积 Product of Guassian Distribution【附带Python实现】
文章目录
- 【Math】高斯分布的乘积 Product of Guassian Distribution【附带Python实现】
- 1.推导
- 2. Code
- Reference
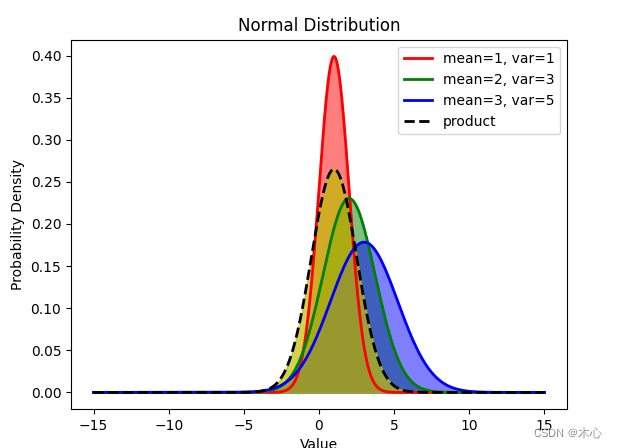
结果先放在前面
1.推导
在学习PEARL算法的时候,encoder的设计涉及到了高斯分布的乘积,对此有点疑问,进行推导补票。
首先高斯分布(Guassian Distribution)的概率密度函数为
f ( x ) = 1 2 π σ exp ( − ( x − μ ) 2 2 σ 2 ) f(x) = \frac{1}{\sqrt{2\pi} \sigma} \exp({-\frac{(x-\mu)^2}{2\sigma^2}}) f(x)=2πσ1exp(−2σ2(x−μ)2)
通常将单位高斯分布记为 N ∼ ( 0 , 1 ) \mathcal{N}\sim(0,1) N∼(0,1),一般的高斯分布记为 N ∼ ( μ , σ ) \mathcal{N}\sim(\mu,\sigma) N∼(μ,σ),其中 μ \mu μ是高斯分布的均值(mean), σ \sigma σ是高斯分布的标准差(standard variance), σ 2 \sigma^2 σ2是高斯分布的方差(variance)。
接下来推导高斯分布的乘积,假设有两个高斯分布,分别为
N
1
∼
(
μ
1
,
σ
1
)
,
N
2
∼
(
μ
2
,
σ
2
)
\mathcal{N}_1\sim(\mu_1,\sigma_1),\mathcal{N}_2\sim(\mu_2,\sigma_2)
N1∼(μ1,σ1),N2∼(μ2,σ2),那么其概率密度函数的乘积为
f 1 ( x ) f 2 ( x ) = 1 2 π σ 1 exp ( − ( x − μ 1 ) 2 2 σ 1 2 ) × 1 2 π σ 2 exp ( − ( x − μ 2 ) 2 2 σ 2 2 ) = 1 2 π σ 1 σ 2 exp ( − ( x − μ 1 ) 2 2 σ 1 2 − ( x − μ 2 ) 2 2 σ 2 2 ) \begin{align} f_1(x)f_2(x) & = \frac{1}{\sqrt{2\pi}\sigma_1}\exp(-\frac{(x-\mu_1)^2}{2\sigma_1^2}) \times \frac{1}{\sqrt{2\pi}\sigma_2}\exp(-\frac{(x-\mu_2)^2}{2\sigma_2^2}) \\ & = \frac{1}{2\pi\sigma_1\sigma_2}\exp(-\frac{(x-\mu_1)^2}{2\sigma_1^2} - \frac{(x-\mu_2)^2}{2\sigma_2^2} ) \end{align} f1(x)f2(x)=2πσ11exp(−2σ12(x−μ1)2)×2πσ21exp(−2σ22(x−μ2)2)=2πσ1σ21exp(−2σ12(x−μ1)2−2σ22(x−μ2)2)
我们单独分析指数部分,
( x − μ 1 ) 2 2 σ 1 2 + ( x − μ 2 ) 2 2 σ 2 2 = ( σ 1 2 + σ 2 2 ) x 2 − 2 x ( μ 2 σ 1 2 + μ 1 σ 2 2 ) + ( μ 1 2 σ 2 2 + μ 2 2 σ 1 2 ) 2 σ 1 2 σ 2 2 = x 2 − 2 x μ 2 σ 1 2 + μ 1 σ 2 2 σ 1 2 + σ 2 2 + μ 1 2 σ 2 2 + μ 2 2 σ 1 2 σ 1 2 + σ 2 2 2 σ 1 2 σ 2 2 σ 1 2 + σ 2 2 = ( x − μ 2 σ 1 2 + μ 1 σ 2 2 σ 1 2 + σ 2 2 ) 2 + μ 1 2 σ 2 2 + μ 2 2 σ 1 2 σ 1 2 + σ 2 2 − ( μ 2 σ 1 2 + μ 1 σ 2 2 σ 1 2 + σ 2 2 ) 2 2 σ 1 2 σ 2 2 σ 1 2 + σ 2 2 = ( x − μ 2 σ 1 2 + μ 1 σ 2 2 σ 1 2 + σ 2 2 ) 2 2 σ 1 2 σ 2 2 σ 1 2 + σ 2 2 + μ 1 2 σ 2 2 + μ 2 2 σ 1 2 σ 1 2 + σ 2 2 − ( μ 2 σ 1 2 + μ 1 σ 2 2 σ 1 2 + σ 2 2 ) 2 2 σ 1 2 σ 2 2 σ 1 2 + σ 2 2 \begin{align} \frac{(x-\mu_1)^2}{2\sigma_1^2} + \frac{(x-\mu_2)^2}{2\sigma_2^2} & = \frac{(\sigma_1^2 + \sigma_2^2)x^2 - 2x(\mu_2\sigma_1^2 + \mu_1\sigma_2^2) + (\mu_1^2\sigma_2^2 + \mu_2^2\sigma_1^2) }{2\sigma_1^2\sigma_2^2} \\ & = \frac{ x^2 - 2x\frac{\mu_2\sigma_1^2 + \mu_1\sigma_2^2}{\sigma_1^2+\sigma_2^2} + \frac{\mu_1^2\sigma_2^2 + \mu_2^2\sigma_1^2}{\sigma_1^2+\sigma_2^2} }{ \frac{2\sigma_1^2\sigma_2^2}{\sigma_1^2+\sigma_2^2}} \\ & = \frac{ (x-\frac{\mu_2\sigma_1^2 + \mu_1\sigma_2^2}{\sigma_1^2+\sigma_2^2})^2 + \frac{\mu_1^2\sigma_2^2 + \mu_2^2\sigma_1^2}{\sigma_1^2+\sigma_2^2} - (\frac{\mu_2\sigma_1^2 + \mu_1\sigma_2^2}{\sigma_1^2+\sigma_2^2})^2 }{ \frac{2\sigma_1^2\sigma_2^2}{\sigma_1^2+\sigma_2^2} } \\ & = \frac{(x-\frac{\mu_2\sigma_1^2 + \mu_1\sigma_2^2}{\sigma_1^2+\sigma_2^2})^2}{\frac{2\sigma_1^2\sigma_2^2}{\sigma_1^2+\sigma_2^2}} + \frac{\frac{\mu_1^2\sigma_2^2 + \mu_2^2\sigma_1^2}{\sigma_1^2+\sigma_2^2} - (\frac{\mu_2\sigma_1^2 + \mu_1\sigma_2^2}{\sigma_1^2+\sigma_2^2})^2}{\frac{2\sigma_1^2\sigma_2^2}{\sigma_1^2+\sigma_2^2}} \end{align} 2σ12(x−μ1)2+2σ22(x−μ2)2=2σ12σ22(σ12+σ22)x2−2x(μ2σ12+μ1σ22)+(μ12σ22+μ22σ12)=σ12+σ222σ12σ22x2−2xσ12+σ22μ2σ12+μ1σ22+σ12+σ22μ12σ22+μ22σ12=σ12+σ222σ12σ22(x−σ12+σ22μ2σ12+μ1σ22)2+σ12+σ22μ12σ22+μ22σ12−(σ12+σ22μ2σ12+μ1σ22)2=σ12+σ222σ12σ22(x−σ12+σ22μ2σ12+μ1σ22)2+σ12+σ222σ12σ22σ12+σ22μ12σ22+μ22σ12−(σ12+σ22μ2σ12+μ1σ22)2
继续化简上面的常数部分
μ 1 2 σ 2 2 + μ 2 2 σ 1 2 σ 1 2 + σ 2 2 − ( μ 2 σ 1 2 + μ 1 σ 2 2 σ 1 2 + σ 2 2 ) 2 2 σ 1 2 σ 2 2 σ 1 2 + σ 2 2 = ( μ 1 2 σ 2 2 + μ 2 2 σ 1 2 ) ( σ 1 2 + σ 2 2 ) + ( μ 2 σ 1 2 + μ 1 σ 2 2 ) 2 2 σ 1 2 σ 2 2 ( σ 1 2 + σ 2 2 ) = ( μ 1 − μ 2 ) 2 2 ( σ 1 2 + σ 2 2 ) \begin{align} \frac{\frac{\mu_1^2\sigma_2^2 + \mu_2^2\sigma_1^2}{\sigma_1^2+\sigma_2^2} - (\frac{\mu_2\sigma_1^2 + \mu_1\sigma_2^2}{\sigma_1^2+\sigma_2^2})^2}{\frac{2\sigma_1^2\sigma_2^2}{\sigma_1^2+\sigma_2^2}} & = \frac{(\mu_1^2\sigma_2^2 + \mu_2^2\sigma_1^2)(\sigma_1^2 + \sigma_2^2) + (\mu_2\sigma_1^2 + \mu_1\sigma_2^2)^2}{2\sigma_1^2\sigma_2^2(\sigma_1^2+\sigma_2^2)} \\ & = \frac{(\mu_1 - \mu_2)^2}{2(\sigma_1^2 + \sigma_2^2)} \end{align} σ12+σ222σ12σ22σ12+σ22μ12σ22+μ22σ12−(σ12+σ22μ2σ12+μ1σ22)2=2σ12σ22(σ12+σ22)(μ12σ22+μ22σ12)(σ12+σ22)+(μ2σ12+μ1σ22)2=2(σ12+σ22)(μ1−μ2)2
则我们可以将概率密度函数的乘积写为
f 1 ( x ) f 2 ( x ) = 1 2 π σ 1 σ 2 exp ( − ( x − μ 1 ) 2 2 σ 1 2 − ( x − μ 2 ) 2 2 σ 2 2 ) = 1 2 π σ 1 σ 2 exp ( − ( x − μ 2 σ 1 2 + μ 1 σ 2 2 σ 1 2 + σ 2 2 ) 2 2 σ 1 2 σ 2 2 σ 1 2 + σ 2 2 − ( μ 1 − μ 2 ) 2 2 ( σ 1 2 + σ 2 2 ) ) = 1 2 π ( σ 1 2 + σ 2 2 ) exp ( − ( μ 1 − μ 2 ) 2 2 ( σ 1 2 + σ 2 2 ) ) ⏟ S g × 1 2 π σ 1 2 σ 2 2 σ 1 2 + σ 2 2 exp ( − ( x − μ 2 σ 1 2 + μ 1 σ 2 2 σ 1 2 + σ 2 2 ) 2 2 σ 1 2 σ 2 2 σ 1 2 + σ 2 2 ) = S g × 1 2 π μ exp ( − ( x − μ ) 2 2 σ ) \begin{align} f_1(x)f_2(x) & =\frac{1}{2\pi\sigma_1\sigma_2}\exp(-\frac{(x-\mu_1)^2}{2\sigma_1^2} - \frac{(x-\mu_2)^2}{2\sigma_2^2} ) \\ & = \frac{1}{2\pi\sigma_1\sigma_2} \exp( - \frac{(x-\frac{\mu_2\sigma_1^2 + \mu_1\sigma_2^2}{\sigma_1^2+\sigma_2^2})^2}{\frac{2\sigma_1^2\sigma_2^2}{\sigma_1^2+\sigma_2^2}} - \frac{(\mu_1 - \mu_2)^2}{2(\sigma_1^2 + \sigma_2^2)} ) \\ & = \underbrace{\frac{1}{\sqrt{2\pi(\sigma_1^2+\sigma_2^2)}}\exp(-\frac{(\mu_1 - \mu_2)^2}{2(\sigma_1^2 + \sigma_2^2)})}_{S_g} \times \frac{1}{\sqrt{2\pi \frac{\sigma_1^2\sigma_2^2}{\sigma_1^2+\sigma_2^2} }}\exp(- \frac{(x-\frac{\mu_2\sigma_1^2 + \mu_1\sigma_2^2}{\sigma_1^2+\sigma_2^2})^2}{\frac{2\sigma_1^2\sigma_2^2}{\sigma_1^2+\sigma_2^2}}) \\ & = S_g\times \frac{1}{\sqrt{2\pi \mu}} \exp(-\frac{(x-\mu)^2}{2\sigma}) \end{align} f1(x)f2(x)=2πσ1σ21exp(−2σ12(x−μ1)2−2σ22(x−μ2)2)=2πσ1σ21exp(−σ12+σ222σ12σ22(x−σ12+σ22μ2σ12+μ1σ22)2−2(σ12+σ22)(μ1−μ2)2)=Sg 2π(σ12+σ22)1exp(−2(σ12+σ22)(μ1−μ2)2)×2πσ12+σ22σ12σ221exp(−σ12+σ222σ12σ22(x−σ12+σ22μ2σ12+μ1σ22)2)=Sg×2πμ1exp(−2σ(x−μ)2)
其中
μ = μ 2 σ 1 2 + μ 1 σ 2 2 σ 1 2 + σ 2 2 , σ 2 = σ 1 2 σ 2 2 σ 1 2 + σ 2 2 \mu = \frac{\mu_2\sigma_1^2 + \mu_1\sigma_2^2}{\sigma_1^2+\sigma_2^2}, \sigma^2 =\frac{\sigma_1^2\sigma_2^2}{\sigma_1^2+\sigma_2^2} μ=σ12+σ22μ2σ12+μ1σ22,σ2=σ12+σ22σ12σ22
所以两个高斯分布的乘积仍然为高斯分布,且均值为 μ \mu μ,方差为 σ 2 \sigma^2 σ2, S g S_g Sg被称为缩放因子,即相乘后的分布函数为一个被压缩或者放大的高斯分布,相乘后的概率密度的积分不等于1,但其方差和均值性质不变,仍然符合高斯分布。
拓展到多个高斯分布相乘的结果,可以得到
μ = μ 1 σ 2 2 σ 3 2 + μ 2 σ 1 2 σ 3 2 + μ 3 σ 1 2 σ 2 2 σ 1 2 σ 2 2 + σ 1 2 σ 3 2 + σ 2 2 σ 3 2 , σ 2 = σ 1 2 σ 2 2 σ 3 2 σ 1 2 σ 2 2 + σ 1 2 σ 3 2 + σ 2 2 σ 3 2 \mu = \frac{\mu_1\sigma_2^2\sigma_3^2 + \mu_2\sigma_1^2\sigma_3^2 + \mu_3\sigma_1^2\sigma_2^2 }{\sigma_1^2\sigma_2^2 + \sigma_1^2\sigma_3^2 + \sigma_2^2\sigma_3^2}, \sigma^2 = \frac{\sigma_1^2\sigma_2^2\sigma_3^2}{\sigma_1^2\sigma_2^2 + \sigma_1^2\sigma_3^2 + \sigma_2^2\sigma_3^2} μ=σ12σ22+σ12σ32+σ22σ32μ1σ22σ32+μ2σ12σ32+μ3σ12σ22,σ2=σ12σ22+σ12σ32+σ22σ32σ12σ22σ32
2. Code
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import norm
# 设定均值和标准差
mean = np.array([1, 2, 3])
var = np.array([1, 3, 5])
x = np.linspace(-15, 15, 1000)
pdfs = []
# 计算高斯分布的概率密度函数(Probability Density Function, PDF)
for mu, sigma in zip(mean, var):
pdfs.append(norm.pdf(x, mu, np.sqrt(sigma)))
# 绘制高斯分布曲线
plt.plot(x, pdfs[0], 'r-', linewidth=2, label='mean=1, var=1')
plt.fill_between(x, pdfs[0], color='red', alpha=0.5)
plt.plot(x, pdfs[1], 'g-', linewidth=2, label='mean=2, var=3')
plt.fill_between(x, pdfs[1], color='g', alpha=0.5)
plt.plot(x, pdfs[2], 'b-', linewidth=2, label='mean=3, var=5')
plt.fill_between(x, pdfs[2], color='b', alpha=0.5)
# 计算三个高斯分布的乘积
prod_mean = 1.0 / np.sum(np.reciprocal(mean), axis=0)
prod_var = prod_mean * np.sum(mean / var, axis=0)
pdf = norm.pdf(x, prod_mean, np.sqrt(prod_var))
plt.plot(x, pdf, 'k--', linewidth=2, label='product')
plt.fill_between(x, pdf, color='y', alpha=0.7)
# 添加标签和标题
plt.xlabel('Value')
plt.ylabel('Probability Density')
plt.title('Normal Distribution')
plt.legend()
# 显示图形
plt.show()
Reference
https://blog.csdn.net/chaosir1991/article/details/106910668
![读书笔记-《数据结构与算法》-摘要3[选择排序]](https://img-blog.csdnimg.cn/direct/a00880defd4a4a93bd54bd041ff14cdb.gif)