延迟、流量、错误率、饱和度这四大黄金信号是SRE的最佳实践,可用来帮助SRE团队快速评估系统状态,在异常情况下及时介入,保证系统始终工作在健康状态。原文: Four Golden Signals Of Monitoring: Site Reliability Engineering (SRE) Metrics[1]
黄金信号(Golden Signals)最初是谷歌在站点可靠性工程(SRE)实践的背景下引入的,由谷歌软件工程师Dave Rensin和Kevin Smathers在2016年O 'Reilly Velocity Conference上的一次演讲中提出,其背后的想法是提供一组关键性能指标(KPI),用于测量和监控复杂分布式系统的运行状况。
引入黄金信号是为了帮助SRE团队关注系统可靠性和性能方面真正重要的东西。黄金信号不依赖于难以解释的大量指标和告警,而是提供一组简单且易于理解的指标,用于快速评估系统健康状况。
自从这一概念提出以来,黄金信号已在SRE社区中得到广泛采用,并被认为是监控和管理分布式系统运行状况的最佳实践。虽然最初黄金信号专注于延迟、流量、错误和饱和指标,但一些组织已经调整了这个概念,引入了特定于其系统和用例的附加指标。不过,通过一组KPI来度量和监控系统健康的核心思想仍然是黄金信号概念的核心。
什么是黄金信号?
黄金信号是SRE用来衡量其系统健康状况的一组四个关键指标,包括:
-
延迟(Latency) —— 延迟用来度量系统响应请求所需的时间,延迟高表明系统可能过载或遇到其他性能问题。
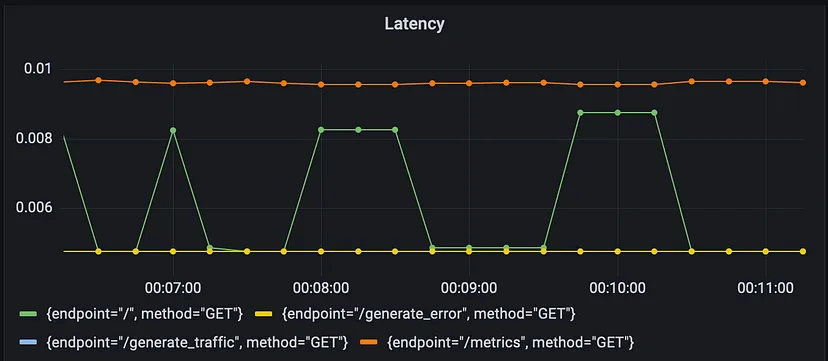
Prometheus查询histogram_quantile(0.95, sum(rate(http_request_duration_seconds_bucket{job="fastapi-app"}[5m])) by (le, method, endpoint))通过直方图指标(histogram metric)度量来检测FastAPI应用程序HTTP请求的P95延迟。
该查询计算过去5分钟内http_request_duration_seconds_bucket度量值(表示落入特定延迟桶的请求数量)的速率总和,并按延迟(le)、HTTP方法和端点分组。然后,histogram_quantile函数使用这些值计算每个HTTP方法和端点组合的P95延迟。
-
流量(Traffic) —— 流量衡量流经系统的数据或请求的数量,流量高表明系统可能正在处理大量请求,或者系统容量存在问题。

Prometheus查询rate(http_requests_total{job="fastapi-app"}[$__rate_interval])通过计数器指标(counter metric)度量FastAPI应用程序每秒HTTP请求的速率。
该查询使用rate函数来计算http_requests_total计数器指标的每秒增长率,计算向FastAPI应用程序发出的HTTP请求总数。job="fastapi-app"标签选择器过滤度量数据,使其只包含来自FastAPI的数据。
$__rate_interval变量是模板变量,表示计算速率的持续时间,该变量值由用户在Prometheus查询界面中设置,用于确定计算速率的时间范围。
例如,如果用户将$__rate_interval设置为5m,查询将计算过去5分钟内HTTP请求的每秒速率。此查询可用于监控FastAPI应用程序的流量,并识别请求量随时间变化的模式或异常情况。
-
错误(Errors) —— 错误度量系统中发生的错误数量,错误率高表明系统中可能存在bug或其他问题。
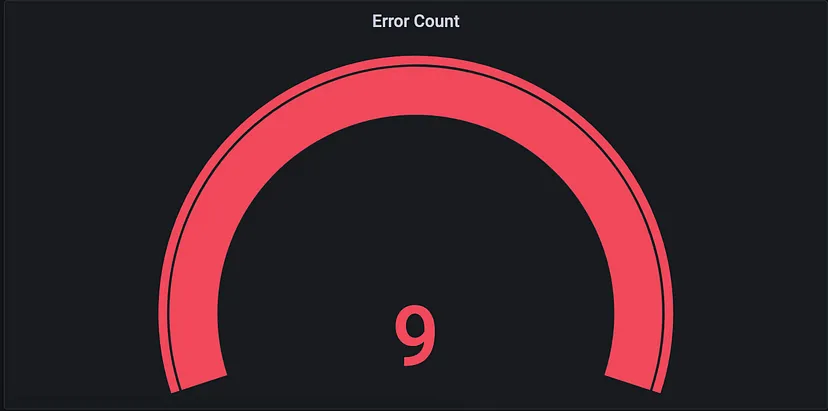
Prometheus查询http_requests_total {endpoint="/generate_error", http_status="500"}检索web应用程序的"/generate_error"端点的HTTP请求并且HTTP状态码为500(内部服务器错误)的数量。
该查询使用http_requests_total计数器指标,计算向web应用程序发出的HTTP请求总数。查询通过指定endpoint="/generate_error"标签选择器过滤度量数据,使其只包括对"/generate_error"端点的请求。此外,查询通过指定http_status="500"标签选择器过滤数据,只包括HTTP状态码为500的请求。
通过运行这个查询,可以深入了解web应用中错误发生率,以及哪些端点容易出错。这些信息可以帮助识别和修复应用中的问题,提高可靠性,并确保为用户提供更好的体验。
-
饱和度(Saturation) —— 饱和度衡量系统的资源利用率,饱和度高表明系统资源(例如CPU或内存)可能正在被耗尽。
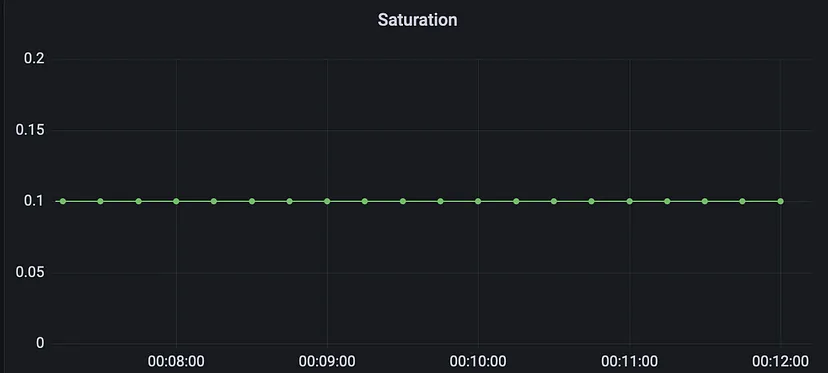
Prometheus查询clamp_max(active_requests{job="fastapi-app"} / 10, 1)用于计算活动请求与最大并发请求数的比率,并将该比率的值限制为不超过1。
该查询使用active_requests度量(gauge)指标检索FastAPI应用程序中的当前活动请求数。job="fastapi-app"标签选择器过滤度量数据,使其只包含来自FastAPI的数据。
然后,查询将活动请求数除以10,表示系统可以处理的最大并发请求数。然后使用clamp_max函数将该比率的值限制为不超过1。这意味着,如果活动请求与最大并发请求数之比大于1,则查询将返回值1。
通过这个查询,可以监控系统饱和情况,并确定系统何时因请求而过载。如果活动请求与最大并发请求数之比接近1,可能需要扩容系统以处理增加的请求。此查询可以帮助我们确保系统在高负载下仍可保持可靠和高性能。
为什么黄金信号很重要?
因为黄金信号使SRE们可以清楚了解系统的运行情况,因此非常重要。通过测量和监控这些关键指标,SRE可以快速识别问题,并在问题变得严重之前采取纠正措施,即使这么做增加了系统复杂性,也可以有助于确保系统的可靠性、可伸缩性和高性能。
如何使用黄金信号来提高系统可靠性?
黄金信号可以通过几种方式来提高系统可靠性:
-
主动监控(Proactive Monitoring) —— 通过持续监控黄金信号,SRE可以在问题变得严重之前识别问题,从而能够采取主动措施来防止停机或其他性能问题。 -
容量规划(Capacity Planning) —— 黄金信号可用于识别系统何时达到其容量限制。通过监控流量和饱和度指标,SRE可以做出明智决定,决定何时升级或扩容系统以满足需求。 -
根因分析(Root Cause Analysis) —— 当系统出现问题时,SRE可以使用黄金信号来帮助确定问题的根本原因。通过查看延迟、流量、错误和饱和度指标,SRE可以深入了解出了什么问题,并采取措施防止将来发生类似问题。
了解如何在实践中实现这些指标也很重要。实现黄金信号的一种方法是使用内置对其支持的监控工具和库,比如Prometheus。在下面代码示例中,Python FastAPI应用程序通过Prometheus来实现黄金信号。
from fastapi import FastAPI, Request, HTTPException, Response
from prometheus_client import Counter, Gauge, Histogram, generate_latest, CONTENT_TYPE_LATEST
from starlette.responses import StreamingResponse
import time
app = FastAPI()
# Define Prometheus metrics
http_requests_total = Counter(
"http_requests_total",
"Total number of HTTP requests",
["method", "endpoint", "http_status"]
)
http_request_duration_seconds = Histogram(
"http_request_duration_seconds",
"HTTP request duration in seconds",
["method", "endpoint"]
)
http_request_size_bytes = Histogram(
"http_request_size_bytes",
"HTTP request size in bytes",
["method", "endpoint"]
)
http_response_size_bytes = Histogram(
"http_response_size_bytes",
"HTTP response size in bytes",
["method", "endpoint"]
)
active_requests = Gauge(
"active_requests",
"Number of active requests"
)
error_counter = Counter(
"error_counter",
"Total number of HTTP errors",
["method", "endpoint", "http_status"]
)
@app.middleware("http")
async def record_request_start_time(request: Request, call_next):
request.state.start_time = time.time()
response = await call_next(request)
return response
@app.middleware("http")
async def record_request_end_time(request: Request, call_next):
response = await call_next(request)
latency = time.time() - request.state.start_time
http_request_duration_seconds.labels(
request.method, request.url.path
).observe(latency)
http_request_size_bytes.labels(
request.method, request.url.path
).observe(request.headers.get("Content-Length", 0))
if isinstance(response, StreamingResponse):
response_size = 0
else:
response_size = len(response.content)
http_response_size_bytes.labels(
request.method, request.url.path
).observe(response_size)
http_requests_total.labels(
request.method, request.url.path, response.status_code
).inc()
return response
@app.middleware("http")
async def increment_counter(request: Request, call_next):
active_requests.inc()
response = await call_next(request)
active_requests.dec()
return response
@app.middleware("http")
async def log_saturation(request: Request, call_next):
max_concurrent_requests = 10 # set the maximum number of concurrent requests
saturation_ratio = active_requests._value._value / max_concurrent_requests
print(f"Saturation: {saturation_ratio}")
return await call_next(request)
@app.middleware("http")
async def increment_error_counter(request: Request, call_next):
try:
response = await call_next(request)
return response
except HTTPException as e:
error_counter.labels(
request.method, request.url.path, e.status_code
).inc()
print(f"Incremented error counter for {request.method} {request.url.path} {e.status_code}")
raise e
@app.get("/")
async def root():
return {"message": "Hello, World!"}
@app.get("/generate_traffic")
async def generate_traffic():
for i in range(100):
response = await root()
print(response)
return {"message": "Generated traffic successfully."}
@app.get("/generate_error")
async def generate_error():
raise HTTPException(status_code=500, detail="Generated an error.")
@app.get("/metrics")
async def metrics():
return Response(content=generate_latest(), media_type=CONTENT_TYPE_LATEST)
requirements.txt:
anyio==3.6.2
click==8.1.3
fastapi==0.92.0
h11==0.14.0
idna==3.4
prometheus-client==0.16.0
pydantic==1.10.5
sniffio==1.3.0
starlette==0.25.0
typing_extensions==4.5.0
uvicorn==0.20.0
在K8S上部署
使用Prometheus在FastAPI应用程序中实现了黄金信号后,可能希望将其部署到Kubernetes集群中,以确保可伸缩性和高可用性。下面的Kubernetes清单文件可以用来部署FastAPI应用程序和Grafana仪表板:
fastapi-app.yaml
# @format
apiVersion: apps/v1
kind: Deployment
metadata:
name: fastapi-app
spec:
selector:
matchLabels:
app: fastapi-app
replicas: 2
template:
metadata:
labels:
app: fastapi-app
annotations:
prometheus.io/scrape: "true"
prometheus.io/path: "/"
prometheus.io/port: "80"
spec:
containers:
- name: fastapi-app
image: rtiwariops/fastapi-app:v1
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: fastapi-app
spec:
selector:
app: fastapi-app
ports:
- name: http
protocol: TCP
port: 80
targetPort: 80
grafana.yaml
# @format
apiVersion: apps/v1
kind: Deployment
metadata:
name: grafana
spec:
selector:
matchLabels:
app: grafana
replicas: 1
template:
metadata:
labels:
app: grafana
spec:
containers:
- name: grafana
image: grafana/grafana:latest
ports:
- containerPort: 3000
---
apiVersion: v1
kind: Service
metadata:
name: grafana
spec:
selector:
app: grafana
ports:
- name: http
protocol: TCP
port: 3000
targetPort: 3000
prometheus.yaml
apiVersion: v1
kind: Service
metadata:
name: prometheus
spec:
selector:
app: prometheus
ports:
- name: web
port: 9090
targetPort: 9090
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: prometheus
spec:
selector:
matchLabels:
app: prometheus
replicas: 1
template:
metadata:
labels:
app: prometheus
spec:
containers:
- name: prometheus
image: prom/prometheus:v2.28.1
ports:
- name: web
containerPort: 9090
command:
- "/bin/prometheus"
args:
- "--config.file=/etc/prometheus/prometheus.yml"
volumeMounts:
- name: config-volume
mountPath: /etc/prometheus
volumes:
- name: config-volume
configMap:
name: prometheus-config
总之,黄金信号是SRE工具箱中的关键工具。通过测量和监控延迟、流量、错误和饱和度指标,即使面对日益增加的复杂性和需求,SRE也可以确保其系统保持可靠、可扩展和高性能。
完整代码示例: https://github.com/PolyCloudNative/Golden-Rule-Demo
你好,我是俞凡,在Motorola做过研发,现在在Mavenir做技术工作,对通信、网络、后端架构、云原生、DevOps、CICD、区块链、AI等技术始终保持着浓厚的兴趣,平时喜欢阅读、思考,相信持续学习、终身成长,欢迎一起交流学习。
微信公众号:DeepNoMind
参考资料
Four Golden Signals Of Monitoring: Site Reliability Engineering (SRE) Metrics: https://umeey.medium.com/four-golden-signals-of-monitoring-site-reliability-engineering-sre-metrics-64031dbe268
本文由 mdnice 多平台发布