1.WebCollector简介
WebCollector也是一个基于Java的开源网络爬虫框架,其支持多线程、深度采集、URL维护及结构化数据抽取等。WebCollector项目的源码可以在GitHub上进行下载。相比于Crawler4j,WebCollector的可扩展性和适用性更强,如可以实现多代理的切换、断点采集和大规模数据采集。
WebCollector的依赖jar包有OkHttp(网页请求开源库)、Jsoup(HTML/XML类型的网页解析)、Gson(JSON数据解析)、slf4j/log4j(配置日志)、rocksdbjni(RocksDB数据存储)等。
2.依赖
GitHub - CrawlScript/WebCollector:WebCollector是一个基于 Java.It 的开源Web爬虫框架,它提供了一些简单的Web抓取接口,您可以在不到5分钟的时间内设置一个多线程Web爬虫。
<dependency>
<groupId>cn.edu.hfut.dmic.webcollector</groupId>
<artifactId>WebCollector</artifactId>
<version>2.73-alpha</version>
</dependency>3.入门案列
package com.example.jsoup;
import cn.edu.hfut.dmic.webcollector.model.CrawlDatums;
import cn.edu.hfut.dmic.webcollector.model.Page;
import cn.edu.hfut.dmic.webcollector.plugin.rocks.BreadthCrawler;
import java.io.*;
public class RediffCrawler extends BreadthCrawler {
private static StringBuilder sb = new StringBuilder();
private static String fileName;
private static String code;
public RediffCrawler(String crawlPath, boolean autoParse, String filenName, String cod) {
super(crawlPath, autoParse);
//添加种子URL
this.addSeed("https://www.*****.com");
this.addSeed("https://www.*****.com/business");
/**
* URL访问规则添加
* 以“https://www.xxxxxx.com/为前缀 ,以tml为后缀
*/
this.addRegex("^(https://www.*****.com/).*(\\.tml)$");
this.addSeed("-.*\\.(jpg|png|gif|css|js|mid|mp4|wav|mpeg|ram|m4v|pdf)$");
/**
* 输出文件配置
* 文件名及文件编码
*/
fileName = filenName;
code = cod;
}
@Override
public void visit(Page page, CrawlDatums next) {
String url = page.url();
//种子URL不符合条件 这里过滤掉
if(page.matchUrl("^(https://www.*****.com/).*(\\.tml)$")){
/**
* 使用jsoup解析数据
*/
String title =page.select("#leftcontainer>h1").text();
String content=page.select("#arti_cintent_n").text();
sb.append("URL:\t"+url+"\n"+"title:\t"+title+"\ncontent:\t"+content+"\n\n");
}
try {
writeFile(fileName, sb.toString(), code);
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 数据写人指定文档
* @param file 文件名
* @param content (需要写入的内容)
* @param code (文件编码)
*/
private void writeFile(String file, String content, String code) throws IOException {
final File result = new File(file);
final FileOutputStream out = new FileOutputStream(result, false);
final BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(out, code));
bw.write(content);
bw.close();
out.close();
}
public static void main(String[] args) throws Exception {
final RediffCrawler crawler = new RediffCrawler("rediffNewCrawler",
true, "data/rediffNews.txt", "uft-8");
//设置线程数目
crawler.setThreads(5);
//设置每一层最多采集的页面数
crawler.getConf().setTopN(300);
//开始采集数据,设置采集的深度
crawler.start(3);
}
}
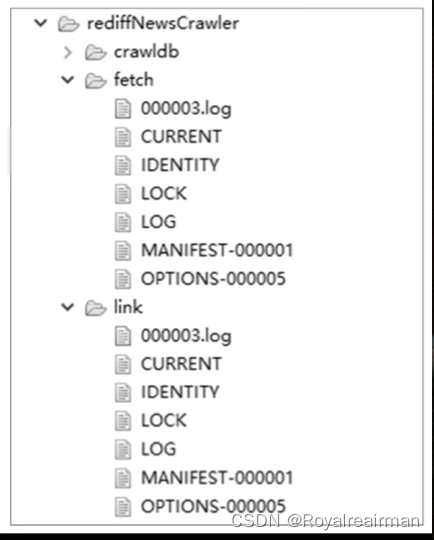
在控制台会输出一系列日志信息。整个程序的执行时间为28秒,共采集271条新闻,采集到数据写入了项目“data/”目录下的文件“rediffNews.txt”,其内容如图9-9所示。相比Crawler4j,WebCollector采集数据的速度更快、效率更高。在执行的过程中,在项目的根目录下会自动创建文件夹“rediffNewsCrawler”,同时在该文件夹下还包含三个文件,分别是“crawldb”、“fetch”和“link”。这三个文件夹下存放的都是RocksDB数据库对应的文件,如图9.10所示。RocksDB是一种嵌入式的支持持久化的key-value存储系统,可以在控制台输出每个数据库中存储的key-value数据。其中,key为访问的URL;value为包含5个字段的JSON数据,即URL、状态status(三种取值为0、1、5,默认为0)、执行时间executeTime(UNIX时间戳-毫秒)、执行次数executeCount(默认值为0)、HTTP状态码(默认值为-1,表示未获取到状态码)和重定向地址(默认值为null,如果有重定向则保存重定向地址)。WebCollector的数据去重,依据的是RocksDB数据库中的key,如果没有设置key,程序会将URL当成key。
package com.example.jsoup;
import org.rocksdb.Options;
import org.rocksdb.RocksDB;
import org.rocksdb.RocksIterator;
public class RocksDBOpen {
static {
RocksDB.loadLibrary();
}
static RocksDB rocksDB;
static String path="rediffNewsCrawler/crawldb";
public static void main(String[] args) throws Exception {
final Options options = new Options();
options.setCreateIfMissing(true);
//打开RocksDB
rocksDB=RocksDB.open(options,path);
RocksIterator iter = rocksDB.newIterator();
for( iter.seekToFirst();iter.isValid();iter.next()){
System.out.println("key:"+new String(iter.key())+",value:"+new String(iter.value()));
}
}
}
4.相关配置
1.User-Agent
在cn.edu.hfut.dmic.webcollector.util包的Config类中,给出了User-Agent的默认值,即:
String user_agent = "\"Mozilla/5.0 (Windows NT 10.0; Win64; x64\" + \"AppleWebKit/537.36(KHTML, like chrome/\" +\n" +
" \"63.0.3239.108 Safari/537.36\"";
crawler.getConf().setDefaultUserAgent(user_agent);2. 请求时间间隔
为了礼貌地采集网站数据,Configuration类提供了setExecuteInterval ()方法来设置任意线程URL请求之间的时间间隔(默认值为0)。以下为配置程序。
crawler.getConf().setExecuteInterval(1000);3.超时时间
WebCollector提供了连接超时时间和获取数据超时时间的配置。在Config类中,连接超时时间的默认值为3秒,获取数据超时时间的默认值为10秒。配置这两种超时时间,可以使用Configuration类中的setConnectTimeout()和setReadTimeout()方法。
crawler.getConf().setConnectTimeout(10000);//连接超时
crawler.getConf().setReadTimeout(200000);//获取数据超时4.最大重定向次数
在WebCollector中,最大重定向次数默认设置为2次。但使用者可以使用Configuration类中的setMaxRedirect()重新配置。
crawler.getConf().setMaxRedirect(5);5.最大执行次数
使用Crawler类中setMaxExecuteCount()可以设置爬虫任务的最大执行次数。在数据采集任务中,请求URL和解析数据出错都有可能导致任务失败。当某个任务执行失败时,如果设置的最大执行次数超过1,那么该任务还会重新执行,直到达到最大执行次数。setMaxExecuteCount()方法的默认设置为-1,即任务失败不会重新执行,以下为该方法的使用方式。
crawler.setMaxExecuteCount(2);6.断点爬取
WebCollector的一个重要特性便是支持断点采集。针对耗时较长和大规模数据采集的任务,经常会遇到一些意外情况(如断网、死机和断电等),导致程序中断。为了保证数据采集任务不受这些因素的影响,WebCollector框架中提供了断点配置方法——setResumable()方法,该方法的参数类型为boolean类型。默认情况下,setResumable()方法输入参数设置为false,即每次采集清空历史数据,不执行断点爬取。没有设置断点爬取,则每次启动任务“crawldb”、“fetch”和“link”三个数据库中的数据都会被清空。但如果程序的start()方法之前进行如下配置:
crawler.setResumable(true);再次执行程序后,同时使用后面的程序打开“crawldb”数据库,则会发现其原有的key-value数据依旧还在,并且添加了新的key-value数据。
5 .HTTP请求扩展
WebCollector 2.7版本默认使用cn.edu.hfut.dmic.webcollector.plugin.net包中的OkHttpRequester作为HTTP请求插件,但其提供的功能有限,为进一步扩展HTTP请求的功能(如设置HTTP请求头信息、设置代理、设置请求方法等),可继承OkHttpRequester类,复写其中的createRequestBuilder()方法。采集的数据仍是rediff.com中的新闻。相比入门案例,这里自定义了请求插件,即MyRequester,其继承了OkHttpRequester。并且,在复写的createRequestBuilder()方法中使用了addHeader()方法添加请求头信息。在构造方法HeaderAdd ()中,只要使用setRequester()方法配置自定义的MyRequester,便可以利用自定义的请求插件请求URL。
package com.example.jsoup.crawler;
import cn.edu.hfut.dmic.webcollector.model.CrawlDatum;
import cn.edu.hfut.dmic.webcollector.model.CrawlDatums;
import cn.edu.hfut.dmic.webcollector.model.Page;
import cn.edu.hfut.dmic.webcollector.plugin.net.OkHttpRequester;
import cn.edu.hfut.dmic.webcollector.plugin.rocks.BreadthCrawler;
import okhttp3.Request;
import java.io.*;
public class HeaderAdd extends BreadthCrawler {
private static StringBuilder sb = new StringBuilder();
private static String fileName;
private static String code;
//自定义请求头
public static class MyRequester extends OkHttpRequester{
//每次发送请求前都会使用这个方法来构建请求
@Override
public Request.Builder createRequestBuilder(CrawlDatum crawlDatum) {
//使用的是OkHttp中的Request.Builder
return super.createRequestBuilder(crawlDatum)
.addHeader("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64" + "AppleWebKit/537.36(KHTML, like chrome/" +
"63.0.3239.108 Safari/537.36");
}
}
public HeaderAdd(String crawlPath, boolean autoParse,String filename,String cod) {
super(crawlPath, autoParse);
setRequester(new MyRequester());
//添加种子URL
this.addSeed("https://www.*****.com");
this.addSeed("https://www.*****.com/business");
/**
* URL访问规则添加
* 以“https://www.xxxxxx.com/为前缀 ,以tml为后缀
*/
this.addRegex("^(https://www.*****.com/).*(\\.tml)$");
this.addSeed("-.*\\.(jpg|png|gif|css|js|mid|mp4|wav|mpeg|ram|m4v|pdf)$");
/**
* 输出文件配置
* 文件名及文件编码
*/
fileName = filename;
code = cod;
}
@Override
public void visit(Page page, CrawlDatums crawlDatums) {
String url = page.url();
//种子URL不符合条件 这里过滤掉
if (page.matchUrl("^(https://www.*****.com/).*(\\.tml)$")) {
/**
* 使用jsoup解析数据
*/
String title = page.select("#leftcontainer>h1").text();
String content = page.select("#arti_cintent_n").text();
sb.append("URL:\t" + url + "\n" + "title:\t" + title + "\ncontent:\t" + content + "\n\n");
}
try {
writeFile(fileName, sb.toString(), code);
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 数据写人指定文档
*
* @param file 文件名
* @param content (需要写入的内容)
* @param code (文件编码)
*/
private void writeFile(String file, String content, String code) throws IOException {
final File result = new File(file);
final FileOutputStream out = new FileOutputStream(result, false);
final BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(out, code));
bw.write(content);
bw.close();
out.close();
}
public static void main(String[] args) throws Exception {
final HeaderAdd crawler = new HeaderAdd("rediffNewCrawler_head",
true, "data/rediffNews.txt", "uft-8");
//设置线程数目
crawler.setThreads(10);
//设置每一层最多采集的页面数
crawler.getConf().setTopN(300);
crawler.getConf().setExecuteInterval(1000);
//开始采集数据,设置采集的深度
crawler.start(3);
}
}
另外,通过复写createRequestBuilder()方法,也可以实现表单数据的提交。
package com.example.jsoup.crawler;
import cn.edu.hfut.dmic.webcollector.model.CrawlDatum;
import cn.edu.hfut.dmic.webcollector.model.CrawlDatums;
import cn.edu.hfut.dmic.webcollector.model.Page;
import cn.edu.hfut.dmic.webcollector.plugin.net.OkHttpRequester;
import cn.edu.hfut.dmic.webcollector.plugin.rocks.BreadthCrawler;
import okhttp3.MultipartBody;
import okhttp3.Request;
import okhttp3.RequestBody;
/**
* 提交表单数据
*/
public class PostRequestTest extends BreadthCrawler {
/**
* 构造一个基于RocksDB的爬虫
* RocksDB文件夹为crawlPath,crawlPath中维护了历史URL等信息
* 不同任务不要使用相同的crawlPath
* 两个使用相同crawlPath的爬虫并行爬取会产生错误
*
* @param crawlPath RocksDB使用的文件夹
* @param autoParse 是否根据设置的正则自动探测新URL
*/
public PostRequestTest(String crawlPath, boolean autoParse) {
super(crawlPath, autoParse);
addSeed(new CrawlDatum("https://www.xxxx.com")
.meta("username","张三")
.meta("password","123456"));
setRequester(new OkHttpRequester(){
@Override
public Request.Builder createRequestBuilder(CrawlDatum crawlDatum) {
Request.Builder requestBuilder= super.createRequestBuilder(crawlDatum);
RequestBody requestBody;
String username = crawlDatum.meta("username");
//如果没有表单数据
if(username==null){
requestBody=RequestBody.create(null,new byte[]{});
}else {
//根据meta创建请求体
requestBody=new MultipartBody.Builder()
.setType(MultipartBody.FORM)
.addFormDataPart("username",username)
.addFormDataPart("password",crawlDatum.meta("password")).build();
}
return requestBuilder.post(requestBody).header("Connection", "keep-alive");
}
});
}
@Override
public void visit(Page page, CrawlDatums next) {
String html= page.html();
System.out.println("快递信息"+html);
}
public static void main(String[] args) throws Exception {
final PostRequestTest crawler = new PostRequestTest("post_crawler", true);
crawler.start(1);
}
}
构建HTTP请求插件使用的是OkHttp jar包中的Request类的内部类Builder。但这个Builder类只能用于配置请求方法(GET/POST)、请求头(添加/删除)和请求体等。如果要配置代理和超时时间等内容,则需要使用OkHttpClient类中的内部类Builder。下面简绍实现了HTTP请求的多代理随机切换模式。MyRequester类继承了OkHttpRequester类,但复写的是createOkHttpClientBuilder()方法。在该方法中,使用了OkHttpClient.Builder类中的proxySelector()添加代理。在采集的过程中,一些代理可能失效,导致URL请求失败,为此,在主方法中,设置了断点采集。
package com.example.jsoup.crawler;
import cn.edu.hfut.dmic.webcollector.model.CrawlDatum;
import cn.edu.hfut.dmic.webcollector.model.CrawlDatums;
import cn.edu.hfut.dmic.webcollector.model.Page;
import cn.edu.hfut.dmic.webcollector.net.Proxies;
import cn.edu.hfut.dmic.webcollector.plugin.net.OkHttpRequester;
import cn.edu.hfut.dmic.webcollector.plugin.rocks.BreadthCrawler;
import okhttp3.OkHttpClient;
import java.io.IOException;
import java.net.Proxy;
import java.net.ProxySelector;
import java.net.SocketAddress;
import java.net.URI;
import java.util.ArrayList;
import java.util.List;
//设置代理
public class ProxyUseTest extends BreadthCrawler {
public static class MyRequester extends OkHttpRequester {
Proxies proxies;
public MyRequester() {
proxies = new Proxies();
proxies.addSocksProxy("127.0.0.1", 1080); //本机
proxies.addSocksProxy("183.161.29.127", 8071);
proxies.addSocksProxy("183.161.29.125", 8071);
//直接连接,不使用代理
proxies.add(null);
}
@Override
public OkHttpClient.Builder createOkHttpClientBuilder() {
return super.createOkHttpClientBuilder()
//设置一个代理选择器
.proxySelector(new ProxySelector() {
@Override
public List<Proxy> select(URI uri) {
//随机选择一个代理
Proxy randomProxy = proxies.randomProxy();
//放回值类型 需要为List
List<Proxy> randomProxies = new ArrayList<>();
//如果随机到Null ,即不要代理 返回空的list 即可
if (randomProxy != null) {
randomProxies.add(randomProxy);
}
System.out.println("使用的代理为:" + randomProxies);
return randomProxies;
}
@Override
public void connectFailed(URI uri, SocketAddress sa, IOException ioe) {
}
});
}
}
/**
* 构造一个基于RocksDB的爬虫
* RocksDB文件夹为crawlPath,crawlPath中维护了历史URL等信息
* 不同任务不要使用相同的crawlPath
* 两个使用相同crawlPath的爬虫并行爬取会产生错误
*
* @param crawlPath RocksDB使用的文件夹
*
*/
public ProxyUseTest(String crawlPath) {
super(crawlPath, true);
//设置请求插件
setRequester(new HeaderAdd.MyRequester());
this.addSeed("https://www.xxxx.com");
this.addRegex("^(https://www.*****.com/).*(\\.tml)$");
}
/**
* @param page 当前访问页面的信息
*/
@Override
public void visit(Page page, CrawlDatums crawlDatums) {
if(page.matchUrl("^(https://www.xxxx.com/).*(\\.htm)$")){
String title = page.select("#leftcontainer>h1").text();
}
}
public static void main(String[] args) throws Exception {
final ProxyUseTest crawler = new ProxyUseTest("crawl_proxy_rediff");
//设置线程数
crawler.setThreads(3);
//防止有些代理不可用,下次启动可以使用其他代理继续请求
crawler.setResumable(false);
//请求间隔时间
crawler.getConf().setExecuteInterval(10000);
//设置每一层最多采集的页面数
crawler.getConf().setTopN(100);
crawler.start(3);
}
}
6.翻页数据采集
在对有分页的网页,进行操作
package com.example.jsoup.crawler;
import cn.edu.hfut.dmic.webcollector.model.CrawlDatum;
import cn.edu.hfut.dmic.webcollector.model.CrawlDatums;
import cn.edu.hfut.dmic.webcollector.model.Page;
import cn.edu.hfut.dmic.webcollector.plugin.ram.RamCrawler;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.*;
/**
* 基于内存的Crawler插件,适合一次性爬取,并不具有断点爬取功能
* 长期任务请使用BreadthCrawler
* 你也可以继续使用前面的BreadthCrawler爬虫
*
* @author hu
*/
public class HFUTNewsCrawler extends RamCrawler {
String fileFirstLayerOutPut = "data/hfut_newUrl.txt";
String contentOutPut = "data/hfut_newsContent.txt";
String code = "utf-8";
StringBuilder sb_first = new StringBuilder();
StringBuilder sb_content = new StringBuilder();
public HFUTNewsCrawler(int pageNum) throws Exception {
//添加多页
for (int pageIndex=1; pageIndex<=pageNum;pageIndex++){
String url = "www.adffsafa.com";
final CrawlDatum datums = new CrawlDatum(url)
.type("firstLayer") //第一层
.meta("pageIndex", pageIndex) //页面保护
.meta("depth", 1); //深度为第一层
this.addSeed(datums);
}
}
@Override
public void visit(Page page, CrawlDatums next) {
int pageIndex = page.metaAsInt("pageIndex");
int depth = page.metaAsInt("depth");
if(page.matchType("firstLayer")){
//解析新闻标题页
Elements results= page.select("div.col-lg-8 >u1").select("li");
for (int rank=0;rank<results.size();rank++){
final Element result = results.get(rank);
String href = "https://www.xxxx.com" + result.select("a").attr("href");
String title=result.select("span[class=rt]").text();
if(title.length()!=0){
//输出第一层信息
sb_first.append("url:"+href);
try {
writeFile(fileFirstLayerOutPut, sb_first.toString(), code);
} catch (Exception e) {
e.printStackTrace();
}
/**
* 添加需要访问的新闻连接 ,类型为content
* 用于爬取新闻的详细内容
*/
//将该URL添加到CrawlDatum做为要采集的URL
next.addAndReturn(href)
.type("content") //页面内容
.meta("pageIndex",pageIndex) //第几页的新闻
.meta("rank",rank); //这条新闻的序号
}
}
}
//新闻详情页
if(page.matchType("content")){
//输出结果
String url= page.url();
int index = page.metaAsInt("pageIndex");//新闻在第几页
int rank = page.metaAsInt("rank"); //新闻在页面的序号
String content=page.select("div[id=artibody]").text();
//输出第二层信息
sb_content.append("url:" + url);
try {
writeFile(contentOutPut,sb_content.toString(),code);
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 页面的深度 +1
* 新闻的详情页
*/
next.meta("depth",depth+1);
}
/**
* 数据写人指定文档
*
* @param file 文件名
* @param content (需要写入的内容)
* @param code (文件编码)
*/
private void writeFile(String file, String content, String code) throws IOException {
final File result = new File(file);
final FileOutputStream out = new FileOutputStream(result, false);
final BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(out, code));
bw.write(content);
bw.close();
out.close();
}
public static void main(String[] args) throws Exception {
final HFUTNewsCrawler crawler = new HFUTNewsCrawler(3);
crawler.setThreads(10);
crawler.start(); //启动程序
}
}