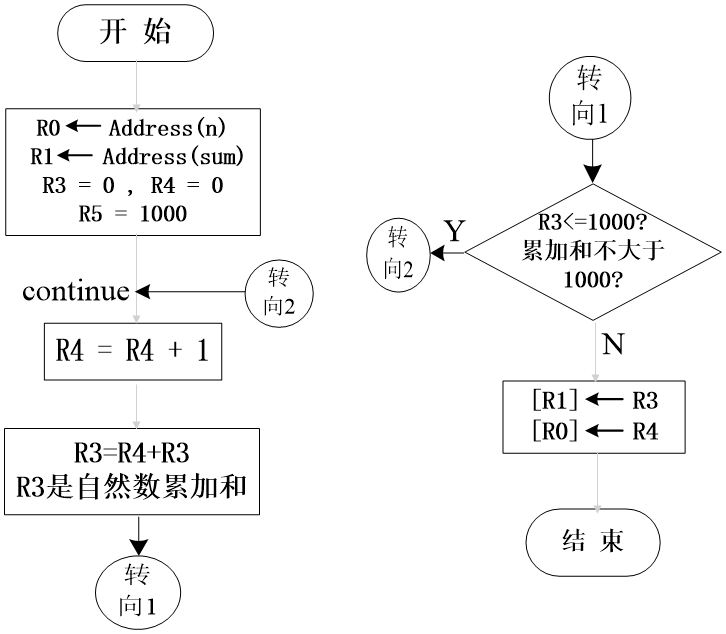
博客转自于: Labelme分割标注软件使用
1. Labelme的使用
这里建议大家按照我提供的目录格式事先准备好数据,然后在该根目录下启动labelme(注意启动目录位子,因为标注json文件中存储的图片路径都是以该目录作为相对路径的)
├── img_data: 存放你要标注的所有图片
├── data_annotated: 存放后续标注好的所有json文件
└── label.txt: 所有类别信息
1.1 创建label标签文件
虽然在labelme中能够在标注时添加标签,但我个人强烈建议事先创建一个label.txt标签(放在上述位置中),然后启动labelme时直接读取。标签格式如下:
__ignore__
_background_
dog
cat
每一行代表一个类型的名称,前两行是固定格式__ignore__和_background_都加上,否则后续使用作者提供的转换脚本(转换成PASCAL VOC格式和MS COCO格式)时会报错。也就是从第三行开始就是我们需要分割的目标类别。这里以分割猫狗为例。
1.2 启动labelme
在创建好标签后,启动labelme并读取标签文件(注意启动根目录),其中--labels指定了标签文件的路径
labelme --labels label.txt
读取标签后,我们在界面右侧能够看到Label List中已经载入了刚刚我们自己创建的标签文件,并且不同类别用不同的颜色表示。
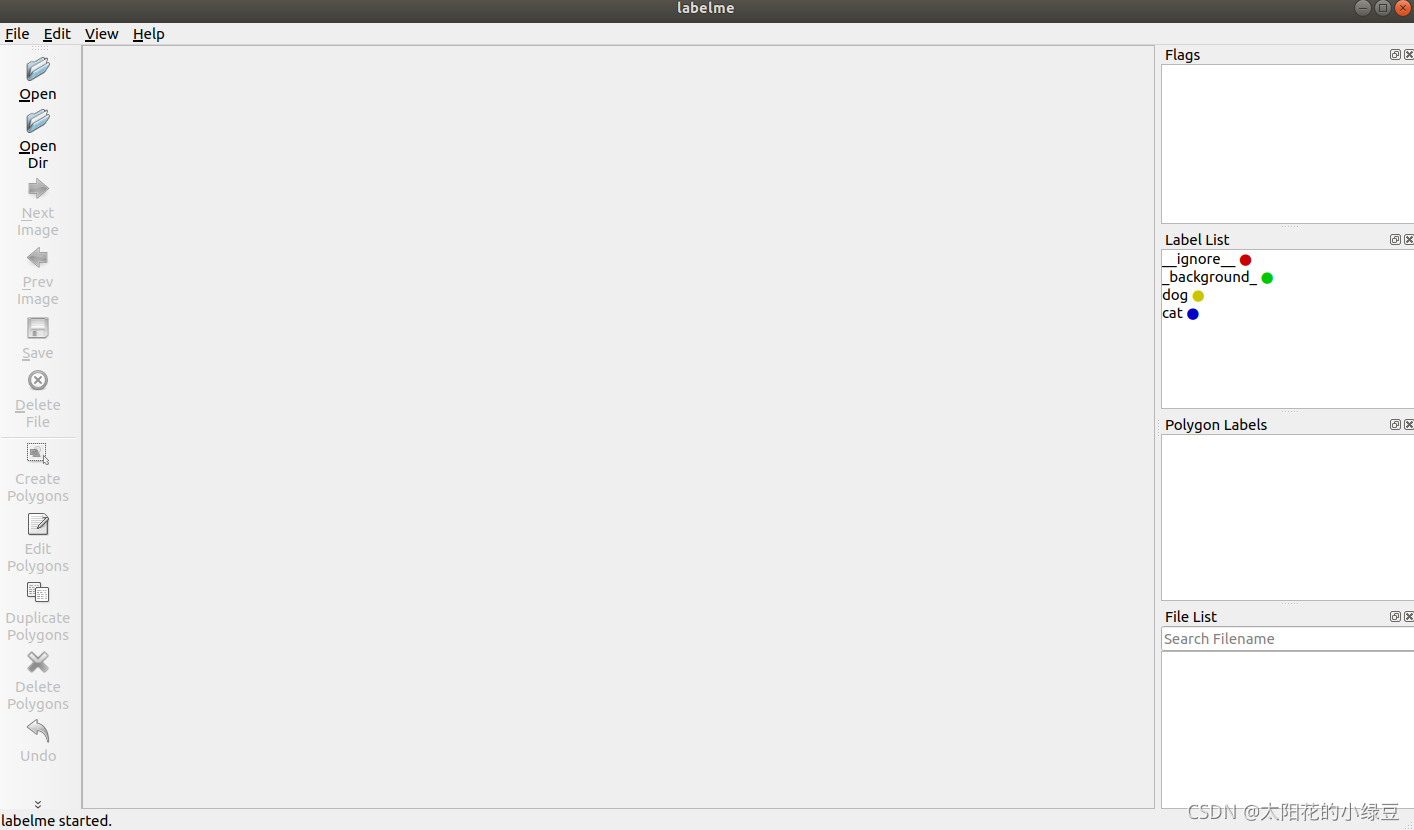
1.3 打开文件/文件夹
点击界面左侧的Open或OpenDir打开文件或文件夹,这里就选择我们刚刚说好的img_data(该文件夹中存储了所有后续需要标注的图片):

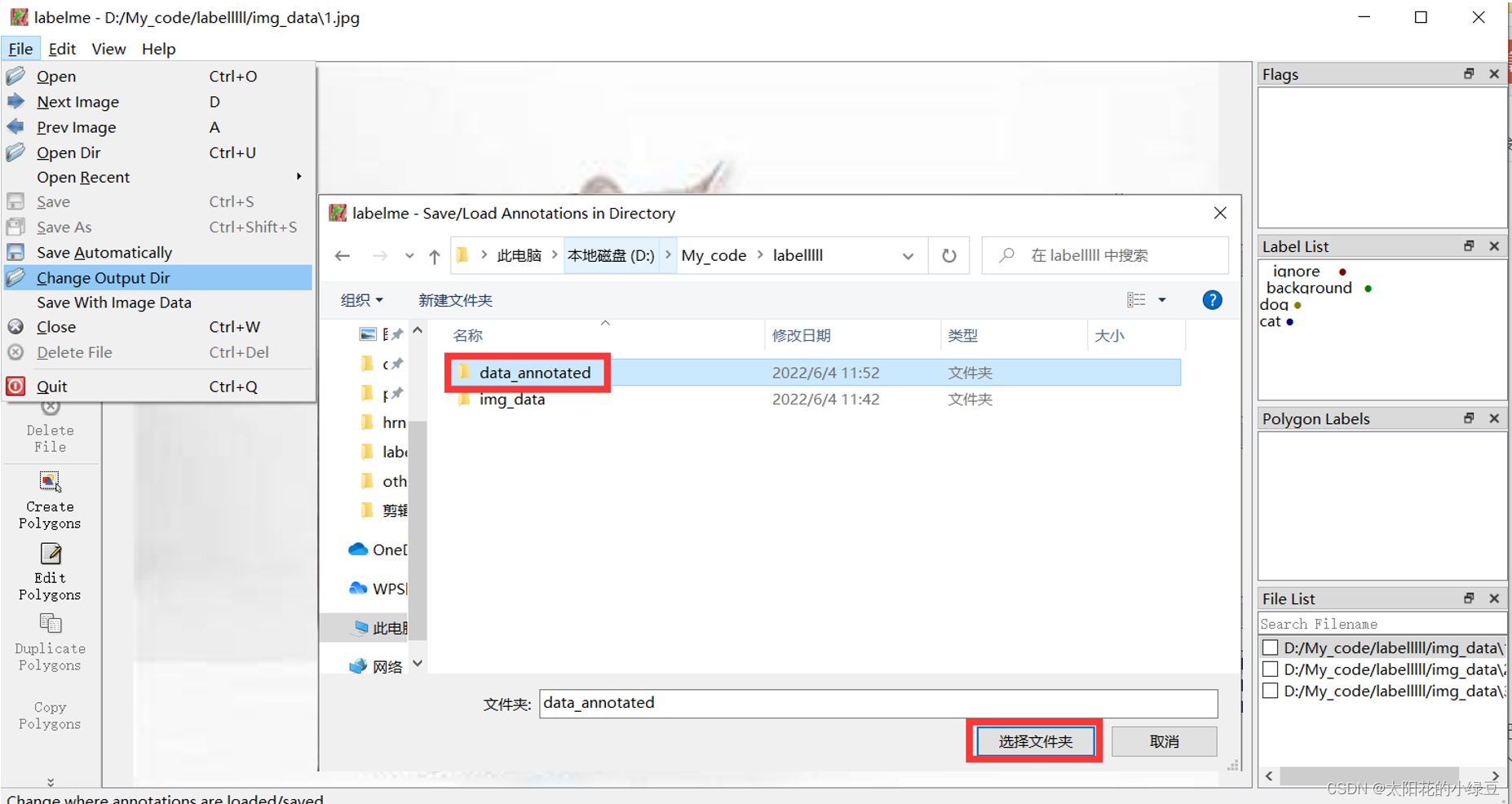
1.4 设置保存结果路径
养成良好习惯,先将保存路径设置好。
先点击左上角File,Change Output Dir设置标注结果的保存目录,这里就设置成前面说好的data_annotated。
建议将Save With Image Data取消掉,默认是选中的。如果选中,会在保存的标注结果中将图像数据也保存在.json文件中(个人觉得没必要,还占空间)。
1.5 标注目标
首先点击左侧的CreatePolygons按钮开始绘制多边形,然后用鼠标标记一个一个点把目标边界给标注出来(鼠标放置在第一个点上,点击一下会自动闭合边界)。标注后会弹出一个选择类别的选择框,选择对应类别即可。
如果标注完一个目标后想修改目标边界,可以点击工具左侧的EditPolygons按钮,然后选中要修改的目标,拖拉边界点即可进行微调。如果要在边界上新增点,把鼠标放在边界上点击鼠标右键选择Add Point to Edge即可新增边界点。如果要删除点,把鼠标放在边界点上点击鼠标右键选择Remove Selected Point即可删除边界点。
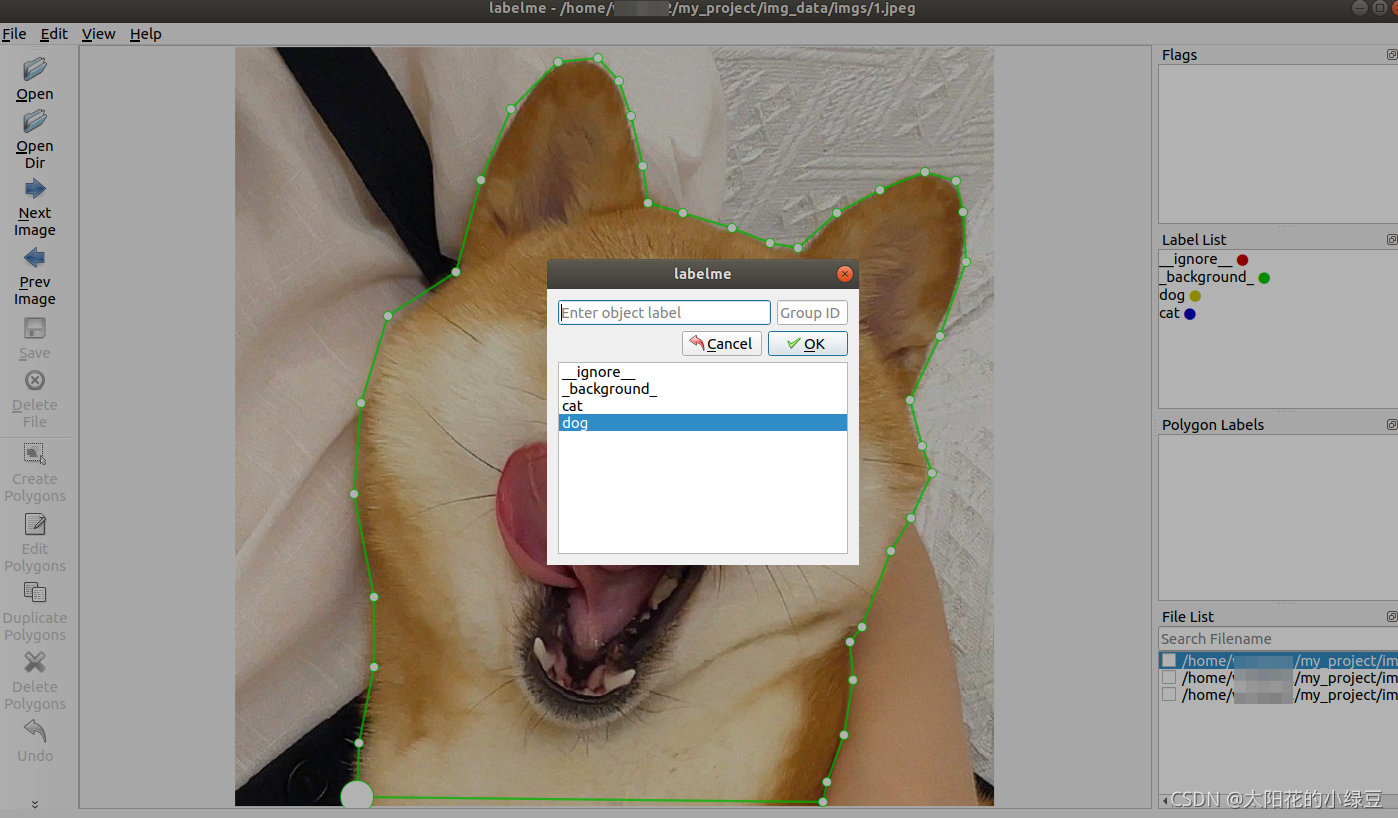
也可以直接在图片上反键选择其他的标注图形,除多边形Polygons外还有矩形Retangle、Circle圆形、Point点等。
标注完一张图片后,点击界面左侧的Save按钮即可保存标注结果,默认每张图片的标注信息都用一个json文件存储。
1.6 保存json文件格式
标注得到的json文件格式如下,将一张图片中的所有目标的坐标都保存在shapes列表中,列表中每个元素对应一个目标,其中label记录了该目标的类别名称。points记录了一个目标的左右坐标信息。其他信息不在赘述。根据以下信息,其实自己就可以写个脚本取读取目标信息了。
{
"version": "4.5.9",
"flags": {},
"shapes": [
{
"label": "dog",
"points": [
[
108.09090909090907,
687.1818181818181
],
....
[
538.090909090909,
668.090909090909
],
[
534.4545454545454,
689.0
]
],
"group_id": null,
"shape_type": "polygon",
"flags": {}
}
],
"imagePath": "../img_data/1.jpg",
"imageData": null,
"imageHeight": 690,
"imageWidth": 690
}
2 格式转换
2.1 转换语义分割标签
原作者为了方便,也提供了一个脚本,帮我们方便的将json文件转换成PASCAL VOC的语义分割标签格式。示例项目链接:https://github.com/wkentaro/labelme/tree/master/examples/semantic_segmentation.
在该链接中有个labelme2voc.py脚本,将该脚本下载下来后,放在上述项目根目录下,执行以下指令即可(注意,执行脚本的根目录必须和刚刚启动labelme的根目录相同,否则会出现找不到图片的错误)。其中data_annotated是刚刚标注保存的json标签文件夹,data_dataset_voc是输出的PASCAL VOC`格式数据的目录。
python labelme2voc.py data_annotated data_dataset_voc --labels label.txt
执行后会生成如下目录:
- data_dataset_voc/JPEGImages
- data_dataset_voc/SegmentationClass
- data_dataset_voc/SegmentationClassPNG
- data_dataset_voc/SegmentationClassVisualization
- data_dataset_voc/class_names.txt
其中JPEGImages就和之前PASCAL VOC数据讲解中说的一样,就是存储原图像文件。而SegmentationClassPNG就是语义分割需要使用的PNG标签图片。
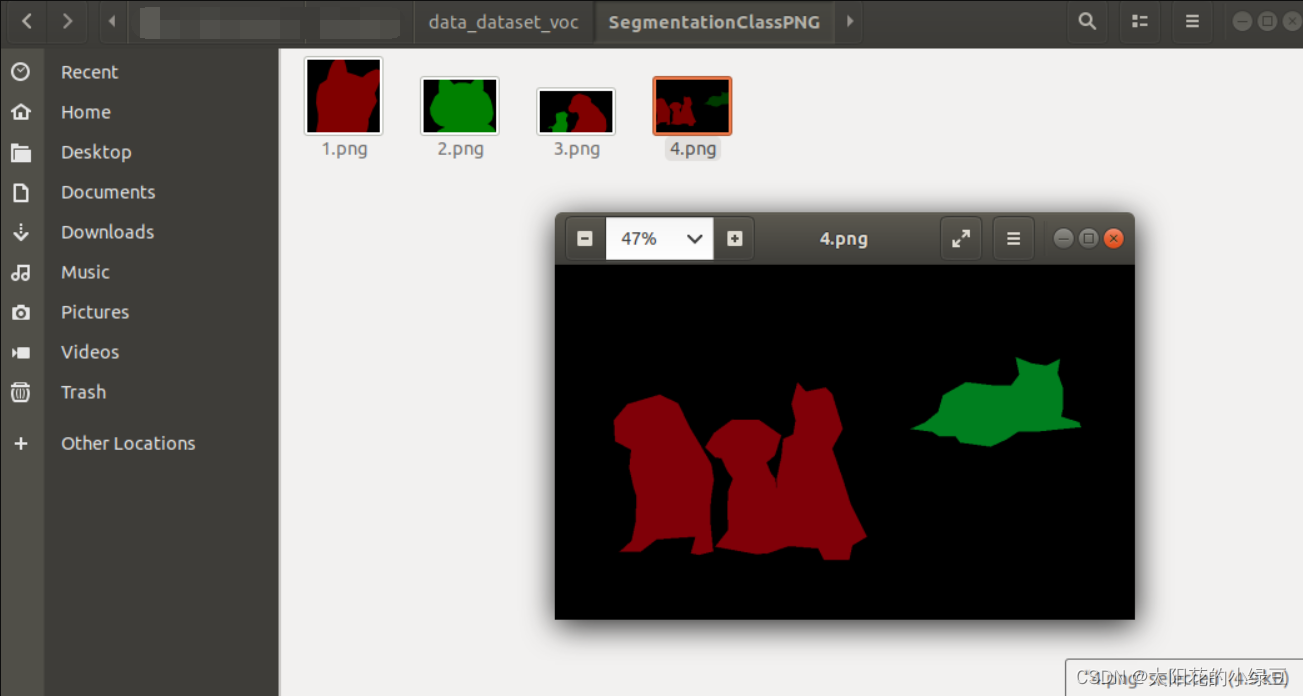
2.2 转换实例分割标签
原作者为了方便,这里提供了两个脚本,帮我们方便的将json文件转换成PASCAL VOC的实例分割标签格式以及MS COCO的实例分割标签格式。示例项目链接:https://github.com/wkentaro/labelme/tree/master/examples/instance_segmentation.
在该链接中有个labelme2voc.py脚本,将该脚本下载下来后,执行以下指令即可(注意,执行脚本的根目录必须和刚刚启动labelme的根目录相同,否则会出现找不到图片的错误)。其中data_annotated是刚刚标注保存的json标签文件夹,data_dataset_voc是生成PASCAL VOC数据的目录。
python labelme2voc.py data_annotated data_dataset_voc --labels label.txt
执行后会生成如下目录:
- data_dataset_voc/JPEGImages
- data_dataset_voc/SegmentationClass
- data_dataset_voc/SegmentationClassPNG
- data_dataset_voc/SegmentationClassVisualization
- data_dataset_voc/SegmentationObject
- data_dataset_voc/SegmentationObjectPNG
- data_dataset_voc/SegmentationObjectVisualization
- data_dataset_voc/class_names.txt
除了刚刚讲的语义分割文件夹外,还生成了针对实例分割的标签文件,主要就是SegmentationObjectPNG目录:
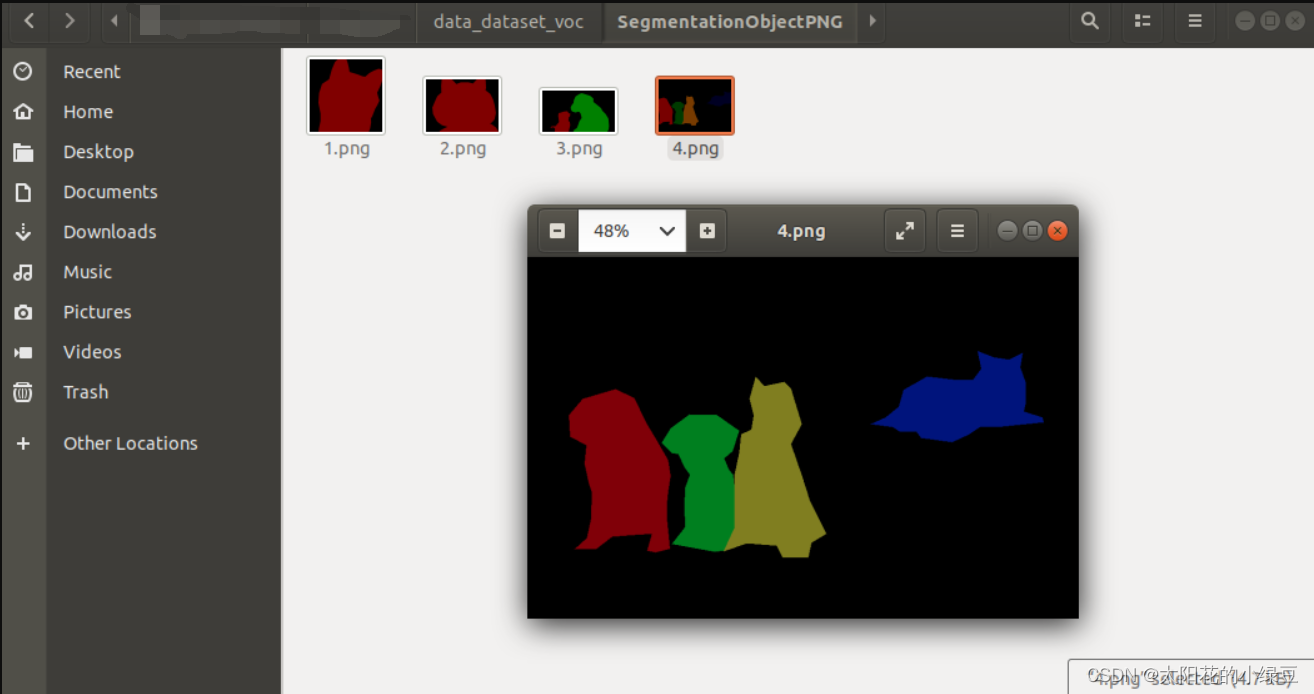
在该链接中有个labelme2coco.py脚本,将该脚本下载下来后,执行以下指令即可(注意,执行脚本的根目录必须和刚刚启动labelme的根目录相同,否则会出现找不到图片的错误)。其中data_annotated是刚刚标注保存的json标签文件夹,data_dataset_coco是生成MS COCO数据类型的目录。
python labelme2coco.py data_annotated data_dataset_coco --labels label.txt
如果执行中提示安装pycocotools包那么就pip安装下就行了。
Linux系统直接:
pip install pycocotools
Windows系统使用:
pip install pycocotools-windows
执行后会生成如下目录:
- data_dataset_coco/JPEGImages
- data_dataset_coco/annotations.json
其中annotations.json就是MS COCO的标签数据文件,如果不了解可以看下原作者之前写的MS COCO介绍